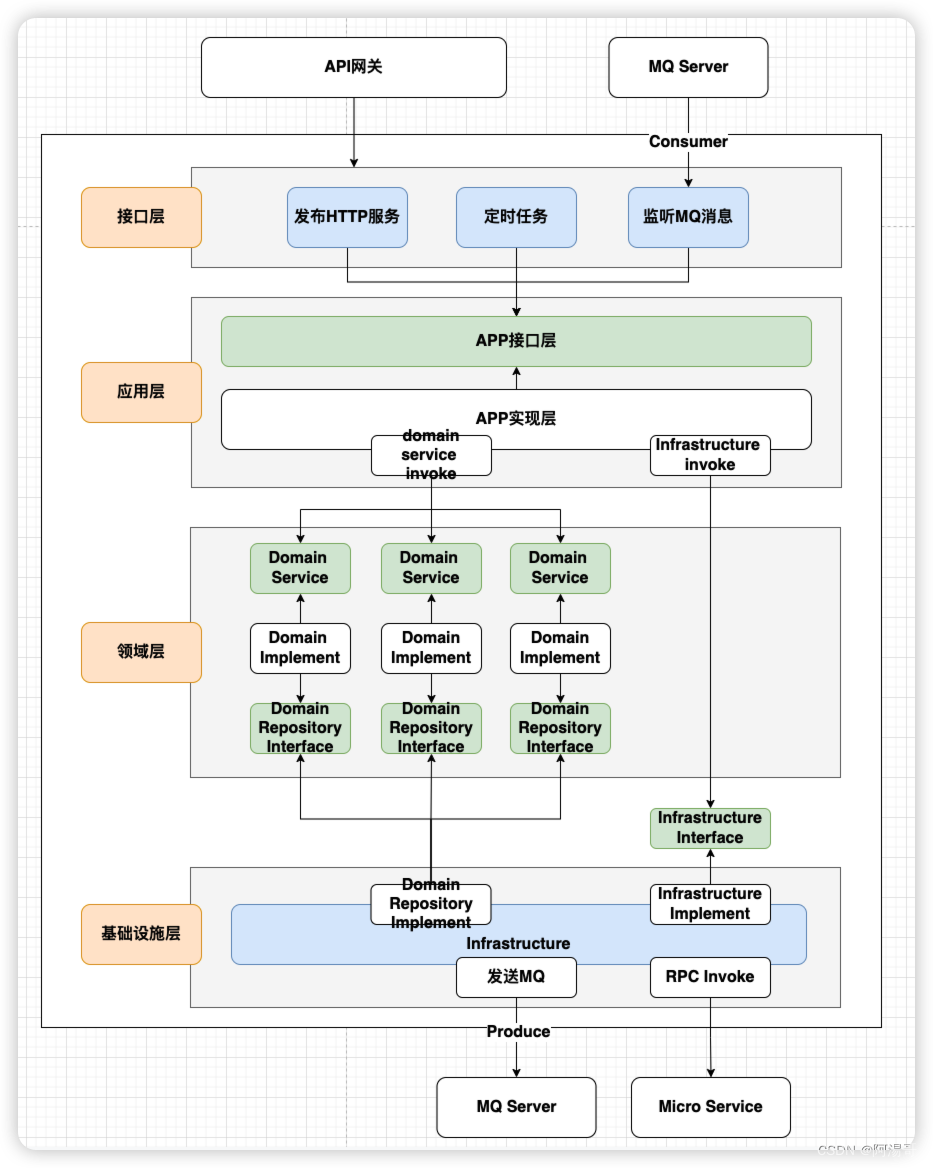
本文将会被汇总至 【记录】Python3|2024年 PDF 转 XML 或 HTML 的第三方库的使用方式、测评过程以及对比结果(汇总),更多其他工具请访问该文章查看。
文章目录
html" title=pdf>pdf2htmlEX__9">html" title=pdf>pdf2htmlEX 使用体验与评估
Github 阅读:https://github.com/shandianchengzi/PDF2HTML_Samples/blob/main/results/html" title=pdf>pdf2htmlEX.md
CSDN 阅读:【记录】Python3| 将 PDF 转换成 HTML/XML(✅⭐⭐⭐⭐html" title=pdf>pdf2htmlEX)
PDF2HTMLEX 是一款功能强大的 PDF 转 HTML 工具,尽管它并不通过 Python 的包管理工具 pip 进行安装,但其易用性和转换效果仍然备受赞誉。下面,我们将详细介绍如何安装 PDF2HTMLEX,并通过一个测试案例来展示其使用方法和效果。
1 安装指南
PDF2HTMLEX 提供了 Windows 版本的 EXE 文件供用户下载和使用。您可以通过点击以下链接下载最新版本的 PDF2HTMLEX:html" title=pdf>pdf2htmlEX Windows Version | RubyPdf Technologies。
下载完成后,您可以直接运行 EXE 文件进行使用。安装过程简单明了,按照提示完成即可,如下图所示。

2 测试代码
为了更好地帮助您理解 PDF2HTMLEX 的用法,我们提供了一个测试代码示例。您可以在以下 GitHub 仓库中找到相关代码和样本文件:https://github.com/shandianchengzi/PDF2HTML_Samples/tree/main/python_samples/test_html" title=pdf>pdf2htmlEX。
请注意,该测试代码示例使用了相对路径来指定文件路径。这是因为 PDF2HTMLEX 在处理文件路径时存在一个已知的 bug。当使用绝对路径时,它会在输出文件的路径前自动添加 ./,导致绝对路径不可用并报错。
例如如下报错:
`Error: Cannot open ./D:\Github\PDF2HTML_Samples\python_samples\test_html" title=pdf>pdf2htmlEX\outputs\to_html_table_test.html for writing`
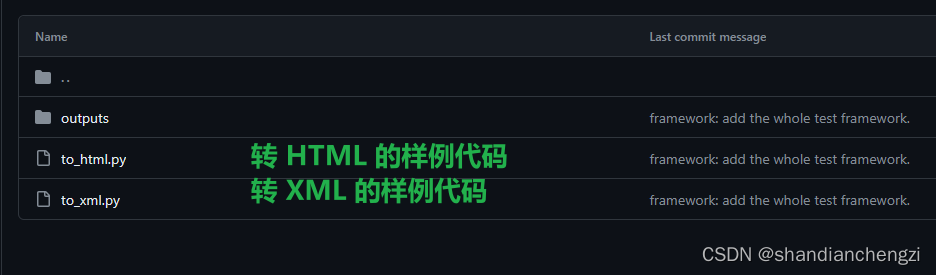
以下是测试代码示例的目录结构:
3 测试结果
3.1 转 HTML 的结果
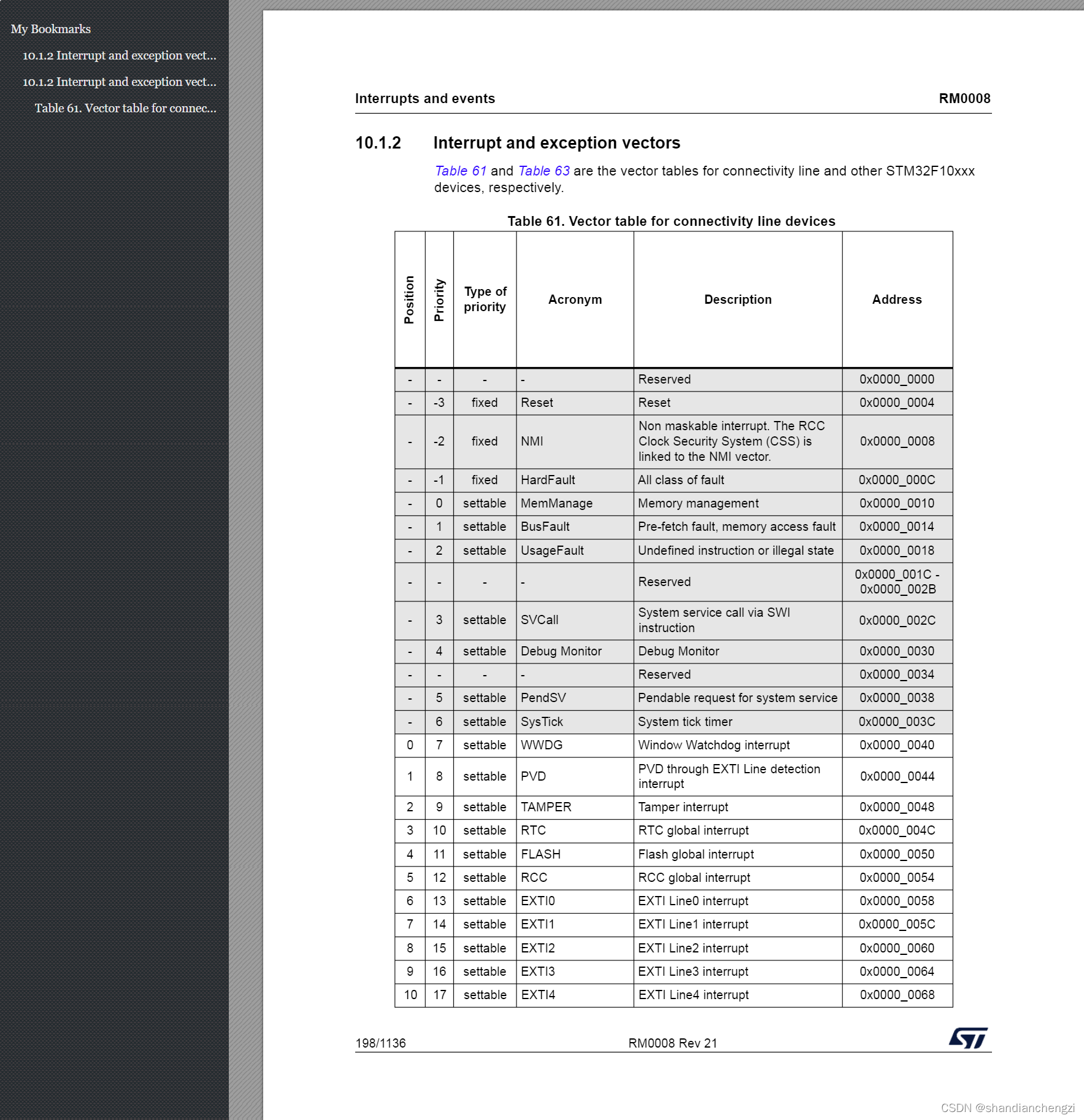
经过测试,PDF2HTMLEX 在将 PDF 转换为 HTML 的过程中表现出色。转换后的 HTML 页面保留了原始 PDF 的格式和布局,使得阅读体验得以延续。然而,需要注意的是,在某些情况下,转换后的大纲可能会出现问题,例如出现重复的章节标题(如下重复出现 10.12)。
以下是转换后的 HTML 页面示例:
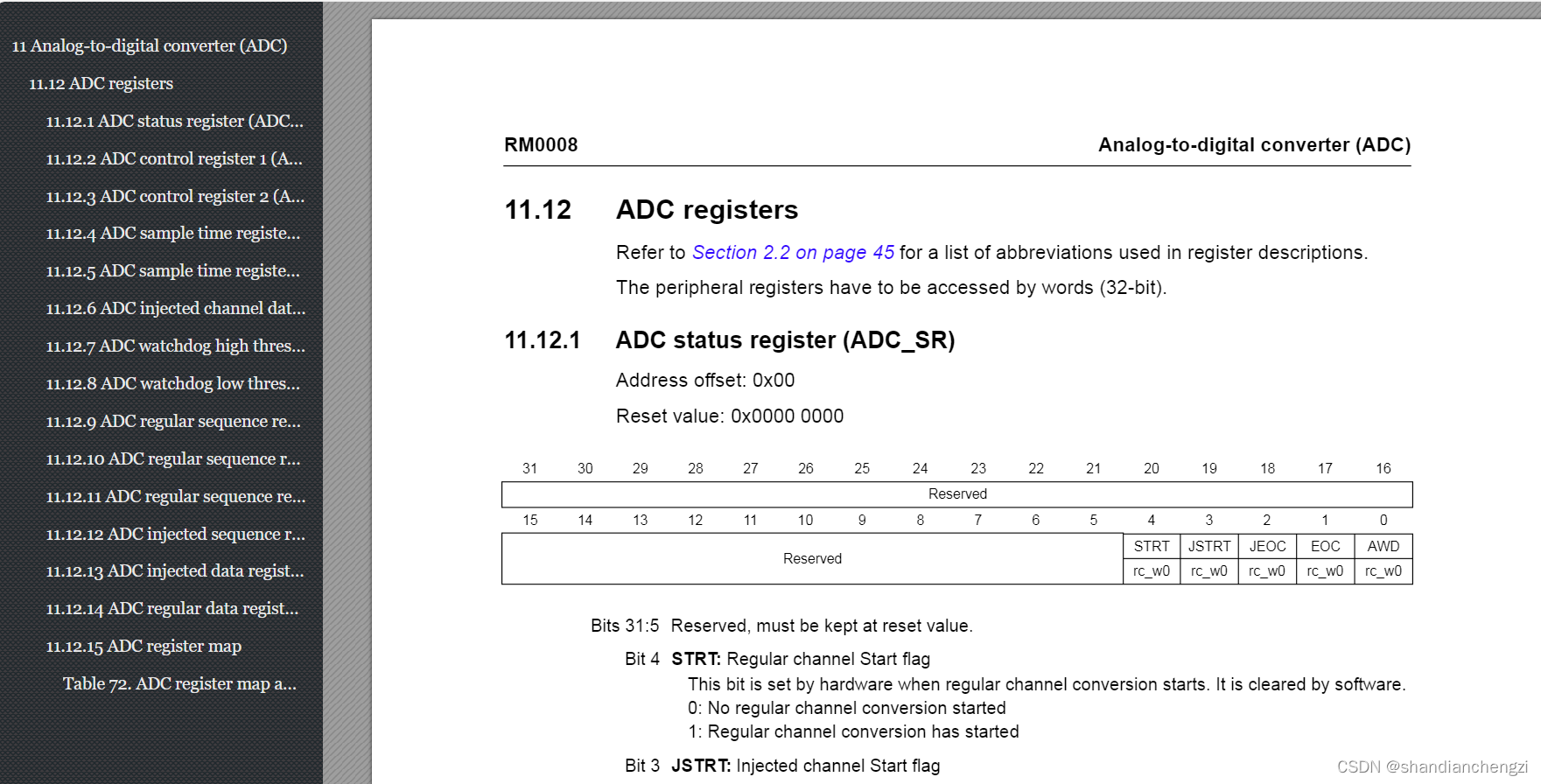
3.2 转 XML 的结果
需要注意的是,PDF2HTMLEX 目前并不支持将 PDF 直接转换为 XML 格式。因此,在测试过程中,我们无法提供相关的转换结果。
4 总体评价:✅⭐⭐⭐⭐
总体来说,PDF2HTMLEX 是一款非常优秀的 PDF 转 HTML 工具。尽管在处理文件路径时存在一些小问题,但这并不影响其出色的转换效果。
它支持多种转换参数,并且能够在保留原始 PDF 格式的基础上,生成易于阅读和编辑的 HTML 页面。参数详情可以点此跳转。
5 补充说明
在转换过程中,PDF2HTMLEX 转换的时候能够保留格式,不过不会自动设置成 DOM 树节点。用户可以用不同的 className 来获得章节,挺方便的!
此外,PDF2HTMLEX 还具备一些特殊功能,例如根据数字区分的书签功能,使得用户在阅读时能够快速定位到所需的章节。如上11.2会被识别成一个小章。
本文将会被汇总至 【记录】Python3|2024年 PDF 转 XML 或 HTML 的第三方库的使用方式、测评过程以及对比结果(汇总),更多其他工具请访问该文章查看。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/138356607。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。