本文来自2024 OceanBase开发者大会,清华大学教授、蚂蚁技术研究院院长陈文光的演讲实录—《AI 时代的数据处理技术》。完整视频回看,请点击这里>>

大家好,我是清华大学、蚂蚁技术研究院陈文光,今天为大家带来《AI 时代的数据处理技术》主题分享。
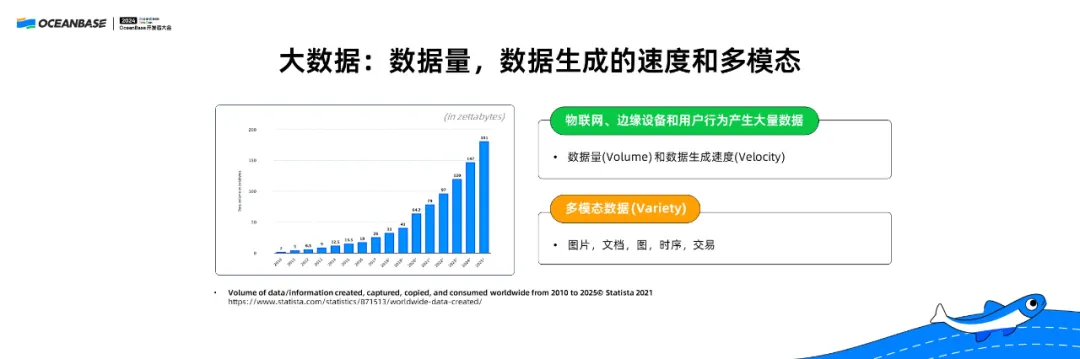
我们身处一个以信息技术为核心驱动力的大数据时代。从下面这张图,我们可以看出,数据量和数据生成的速度在飞速增长。与此同时,新的产生数据的形式在产生,数据模态也在不断增长,不仅包括自然语言,还有声音、图像、视频等等多种形式。最近非常流行的多模态大模型包括具身智能、触觉等新的数据形态。
丰富的数据形态要求我们要对数据做有效处理。模仿“马斯洛需求层次理论”,数据处理也有一个层次,从最底下的收集数据、存储数据到做一般的数据查询处理,更上面的层次是现在越来越接近于用 AI 方式处理数据,甚至最后还能生成很多内容。
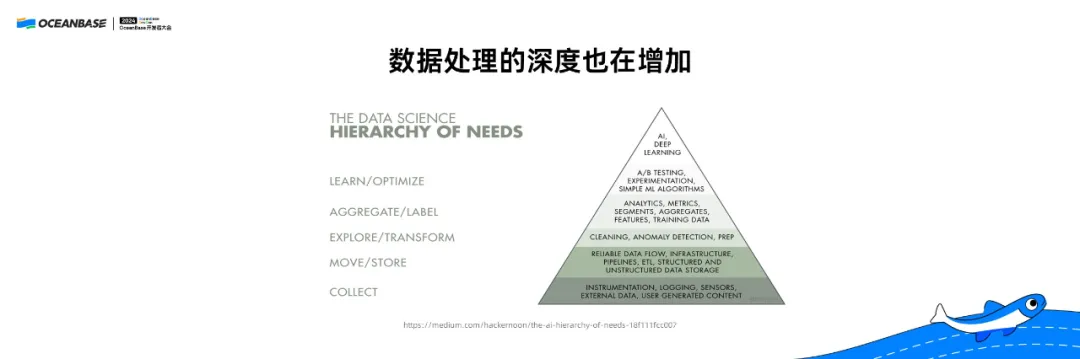
一、AI 时代数据处理新需求
这样的大模型崛起的时代也引发了对数据处理的新需求。最近,Meta 出了一个新模型 LLaMA-3,效果非常好,它实现了在十几万亿的 Token 上面做的训练,而我们之前很多模型可能只是在 4T 的或者几个 T 的 Token上面做训练。
那么,如何获得增加的这部分 Token?实际上,这需要从很多网上低质量的数据中做大量的数据处理,清洗出来可用的高质量数据,如果想让大模型的能力进一步增长,实际上需要数据处理做很多的工作。
另一方面,大模型直接应用在生产服务场景下,本身还存在很多缺陷,比如幻觉问题、上下文长度的问题。目前的多数超长上下文大模型并不能完整记录真正领域的知识。为了满足需求,向量数据库和大语言模型结合起来,提供高质量的服务。
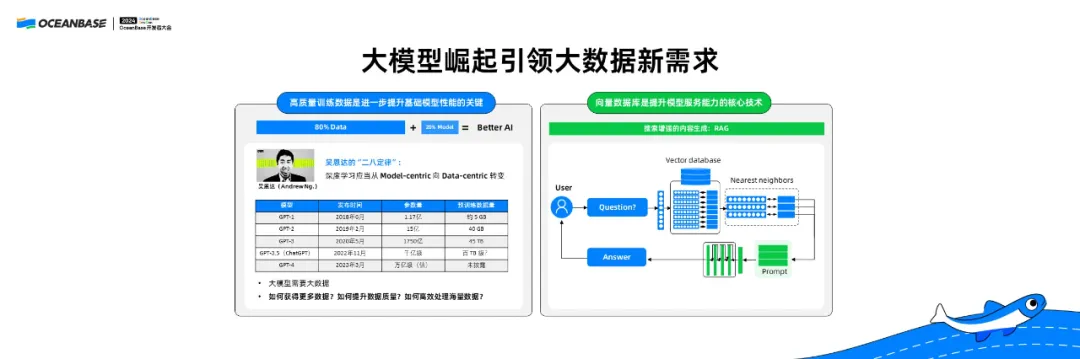
从数据服务的角度来讲,向量数据库是一种使用嵌入的方式表达知识,再用另外索引的方式快速找到相应知识的方式,它和大模型配合才能获得很好的效果。所以大模型的发展和崛起,对数据库领域也提出了很多新需求。
二、AI 时代数据库发展趋势
在这样的趋势下,我今天想分享三个观点,也是未来的数据库面临的三个比较重要的发展趋势:
(一)在线离线一体化
这张图是企业常见的在线、离线两个链路。
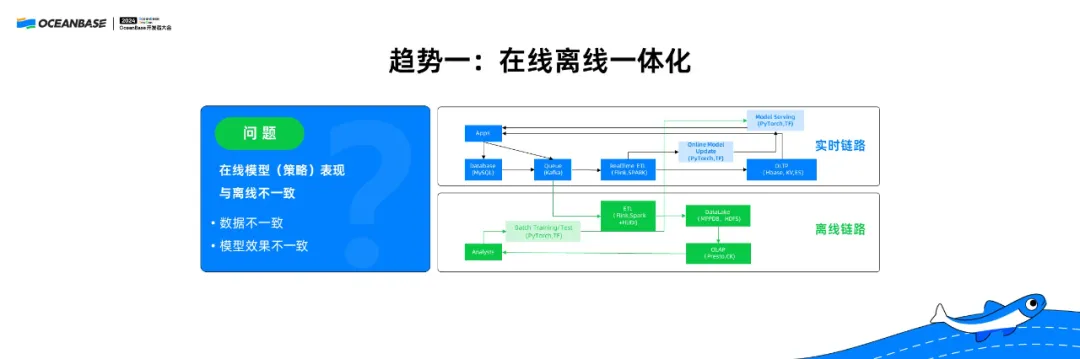
○ 上面是在线链路,一个数据请求会先经过预处理,再通过训练好的模型做推理,比如风控、分类等等,再把结果反馈到 KV 里,直接服务用户的请求。
○ 下面是离线链路,收到数据请求后,我们要想办法处理,去更新模型。经过一段时间后再把模型更新到在线链路上。
在线、离线两个链路分开,在生产中会遇到一些比较严重的问题,主要就是在线、离线不一致。
比如在离线链路上做了各种仿真模拟,但是当把策略、模型上传到在线链路时,会出现与离线链路仿真效果不一样的情况。造成这种现象的根本原因,就是我们通过不同的数据链路把新数据接入进来,离线链路处理的数据与在线链路不一致。
怎么解决这个问题?最好的解决方案,就是只有一套数据。如果能够做到一个系统既能够做事务处理,可以支持事务在数据上面原子化地做更新,同时还可以在这一批数据上做后续分析型的业务。也就是说用一份数据给在线离线链路的一致性打下基础。

这里面也有非常多的技术问题。一般来说,事务处理行存会比较好,分析一般是列存比较好,当一套系统需要同时支持行存和列存的时候,需要什么样的存储结构?另外,事务处理对于优先级、延迟/尾延迟、吞吐率要求比较高。那么在系统里如何调度不同优先级的请求,这里涉及到很多相关技术。
在蚂蚁的图风控中,也有另外一个场景。刚才我们讲到,可以通过数据库本身的 HTAP 引擎解决在线/离线一致性的问题,如果没有这样的混合系统,应该如何实现两份数据达到在线离线一致性?下面以图风控方案中的在线离线一体化为例,给大家介绍。
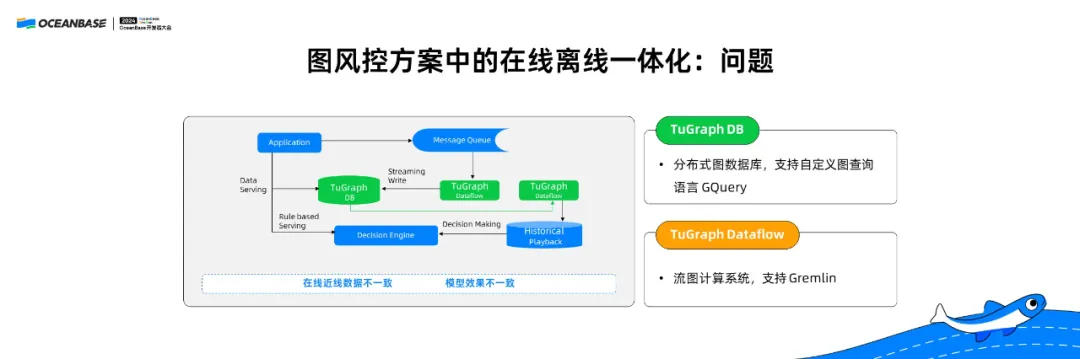
TuGraph DB(分布式图数据库),是一个支持 事物处理 的图数据库。TuGraph Dataflow (流图计算系统),可以看作是一个支持图语义的 Flink。
在我们原来的方案中,这两个系统采用不同的查询语言,一个是我们自定义的 GQuery 语言,另外一个是基于 Java 的支持 Gremlin 语言。这两个系统的数据通过 TuGraph Dataflow 处理完成后,一条线通过 TuGraph DB 去做在线链路,另外一个经过存储去完成后续的离线分析,这时就会出现数据不一致的情况。
这个问题如何解决呢?首先需要让数据保持一致性。数据虽然是两份,但是在TuGraph DB 和存储之间新增了一条数据同步链路,就是通过从 Binlog 中读取数据,保证两份数据的一致性,防止出现两边写,一边写成功、一边写失败,而导致的数据不一致。当把在线数据里已经处理完成的数据同步至离线数据,这时数据的一致性是有保证的。
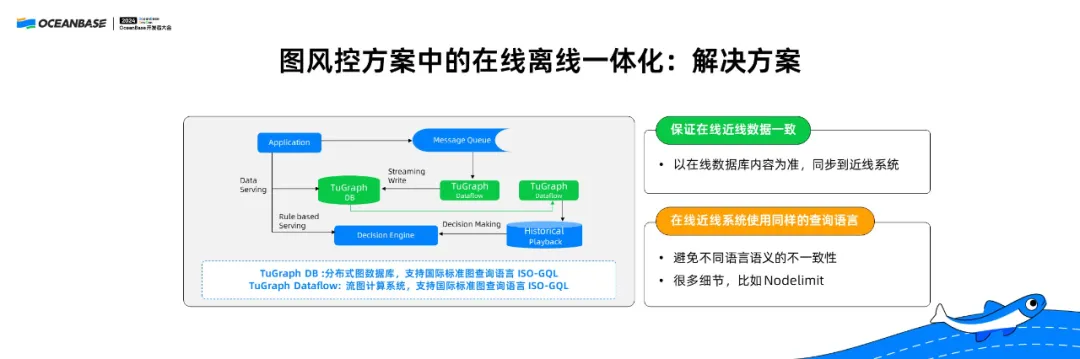
另外,我们把这两个系统的查询语言和语义都统一起来,都使用国际标准图查询语言 ISO-GQL,同样一套查询语言在两个系统上用同一个语义支持,在进行后续的策略分析时,数据和查询语言的语义是一致的,可以达到更好的一致性。
这里也存在非常复杂的情况。图数据库的基本功能是从一个点扩出去很多点,但是有些点的邻居非常多,可能有几十万、上百万个,所以我们会限制每个点扩展的点数,比如只扩两百个。但同时还需要在两个系统中保证不仅只扩两百个点,这两百个点都是一样的,才能保证数据一致性。所以想要在两个系统中要保证数据一致性,需要花费相当大的精力。
(二)向量数据库和关系型数据库一体化
向量数据库和大语言模型的结合有非常重要的作用,如果一个企业要用大语言模型做服务,既要部署语言模型又要部署向量数据库,同时企业的很多数据又保存在关系型数据库中。
这样一个多系统复杂混合的部署,开发、部署、维护非常困难。因为涉及到多个系统之间的依赖性,软件版本、系统之间的交互也会存在很多的问题。如果能够把这些功能做到一起,就能够实现一致性的管理。
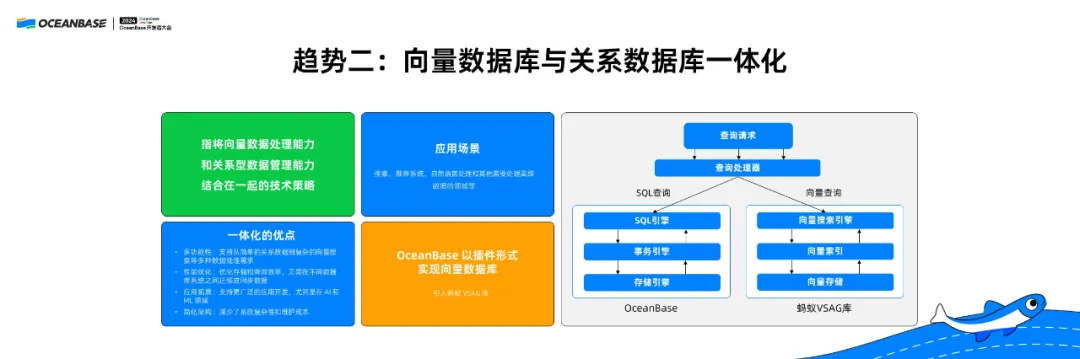
在关系型数据库中,可以通过一些插件支持向量数据库的语义,同时在调用查询引擎的时候,将数据分到不同的链路上执行,从用户的角度就可以实现只部署一个系统,使用一套语言,完成相关工作。
蚂蚁集团有一套内部的 VSAG 的向量库,实现了主流向量数据库的相关功能,而且在实际生产中已经得到应用。向量数据库最有名的是 FaceBook 开源的 FAISS 系统。
VSAG 和 FAISS 之间有什么区别?FAISS 功能非常强大、性能非常好,对 GPU 也做了很多优化,但是相对来说提供了很多底层功能,这就需要通过调整各种参数、配置,从中得到一个对应用比较合适的配置。
而蚂蚁集团的 VSAG 库更多从开发者和产品应用性的角度出发,默认把很多基础配置的事情都做好了,而且在 CPU 上也实现了很多优化,提供了近似于开箱即用的功能。

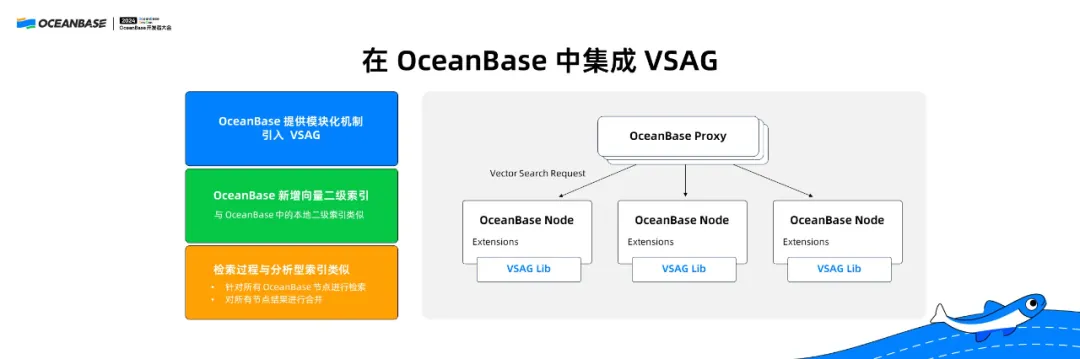
在 OceanBase 里,以插件的方式集成了 VSAG 功能,可以在 OceanBase 里使用 VSAG 向量化的功能,用一套系统达到这样的效果。
(三)数据处理与 AI 计算一体化
有人可能会问,数据处理不就是 SQL 吗?AI 是神经网络层面的东西,AI 与 SQL 为什么会结合到一起?我举一个例子。大家知道世界上有很多的网页,网页上面有很多内容,内容量非常大,远超几十 T、几百 T。但是在这些海量内容中,很多内容质量很低,如何从中提取出高质量的内容?FaceBook 提出了一套 CCNet 的流程,下图的 CCNet 流程展示了数据处理和 AI 的模型在这一过程中的融合试用。
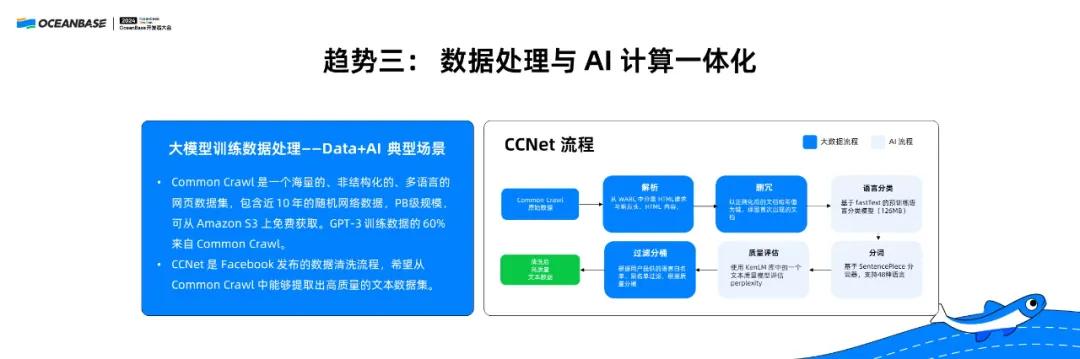
第一步, CCNet 对网页的原始数据进行解析,在 HTML 的网页中抓取内容,这里涉及到解析等工作。
第二步是删冗,删冗也可以被认为是一个 JOIN,因为抓取网页内容中可能用到了别的网页内容,语料里面有冗余不利于最后的训练,即对每段话都做一个哈希,和过去已有的内容对比,是相同还是不相同。解析与删冗是非常典型的数据处理过程。
第三步,做语言分类,需要经过神经网络模型判断网页的语言。
接下来,通过一些 AI 模型对数据做分词、质量评估,后面的过滤、分桶工作,又回到数据处理。
在这个应用里,数据处理和 AI 计算处于交叠的状态,不是一次数据处理之后都交给AI 完成后续的处理,这是一个复杂的来回交互的链路。
那这种情况下,什么样的系统可以支撑这样复杂交互的服务?现在的 AI 和大数据生态基本是割裂的生态:
○ AI 用 Python,主要用 GPU ;
○ 大数据基本上是用 CPU ,用基于 Java 的 Spark 实现。
另一方面,在很多小数据的处理上,Python 已经展现出非常强大的性能,像 Pandas 这样的系统,在单机数据的处理上提供了非常方便的接口。
当 AI 逐渐成为主流计算形态的时候,数据应该如何与 AI 融合?
由于 Spark 是基于 Java 的生态,当我们如果把大模型处理交给 Spark 去做,它产出的结果要通过文件系统、或者其他传输方式交给 AI 的 Python 程序,Python 处理完之后可能还有一些后续处理。在刚才的例子里面,数据处理和 AI 计算之间会有多次的交互,对整个系统的开发、调试、部署、维护带来非常大的问题。
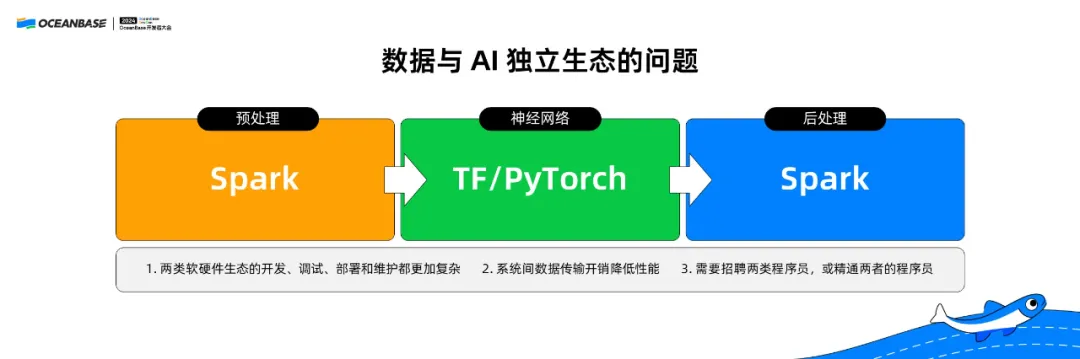
有人尝试把数据处理和 AI 结合起来。2019 年,英特尔出了一个系统“BigDL”,在 Spark 里面把神经网络的描述、优化器、训练方式把这些东西加进去。当时只支持了 CPU,而且是基于 Java 的。我们可以认为,这种方式是试图把 AI 融入到大数据的生态里面。
我们反过来看,如何把大数据的生态往 AI 的方向牵引?这其实是 Spark 的 Python 化。
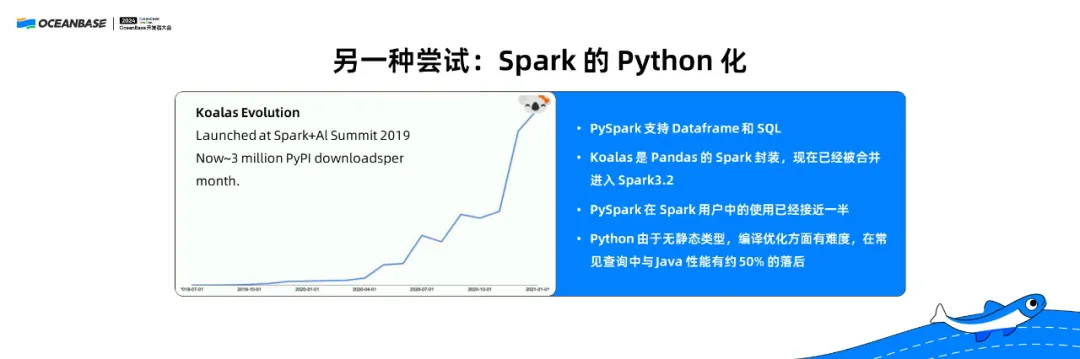
上图是 2022 年在DataBricks Summit上讲的。这是一个分布式的 PySpark,就是 Python 接口的 Spark系统。当时 PySpark 的使用率已经达到了整个 Spark 使用率的近 50%,很多人已经愿意用 PySpark 了。但是 PySpark 还存在一个问题:它的性能很差。
Python 是一个动态语言,在编译时不知道它的类型,动态时才知道,所以它的性能很差,比 Java 的 Spark 还要慢一半。所以虽然 PySpark 对编程非常友好,很多人也习惯用,但是性能不太好。因此我们在处理大量数据的时候,希望能够避免这一问题。
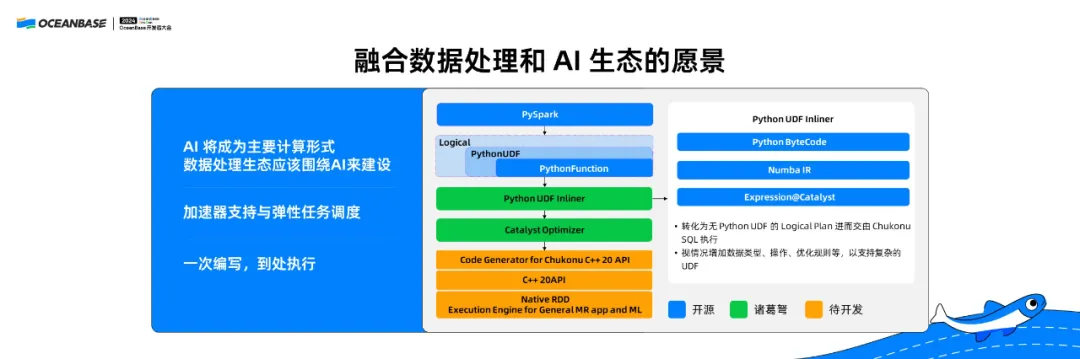
我认为还是要基于 Python,因为 AI 是主要的计算形式,所以整个数据处理应该围绕 AI 建设。从编译优化的角度来讲,我们希望把 PySpark 做很多的优化。这件事是可以做的,我们最近也有了一些成果。在删冗部分,通过把 PySpark 做相关优化,基本上性能可以提升一倍多,可以达到我们的性能预期。
未来,这个生态不只是编程要融合,底层的硬件也要融合,数据和 AI 结合以后,底层的硬件生态也要支持 GPU、弹性任务调度,最后可以达到“一次编写到处执行”的效果。
更多2024开发者大会的资料回顾,请访问这里>>