一、拼音分词器:
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
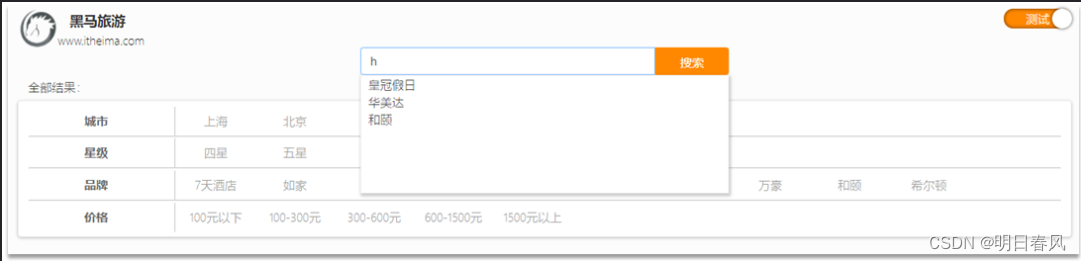
这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
GET /_analyze
{"text":"我爱螺蛳粉","analyzer": "pinyin"
} 这个错误表明 Elasticsearch 在使用全局分析器 pinyin 时遇到了问题,因为它无法找到这个全局分析器。可能是由于缺少配置或插件问题导致的。你需要确保已正确配置了 pinyin 分析器,并且相关的插件已经正确安装和配置:

正确结果会是这样的:
1.1、在线安装拼音分词器:
# 进入容器内部
docker exec -it es /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.12.1/elasticsearch-analysis-pinyin-7.12.1.zip#退出
exit
#重启容器
docker restart es
说明:安装的链接怎么获得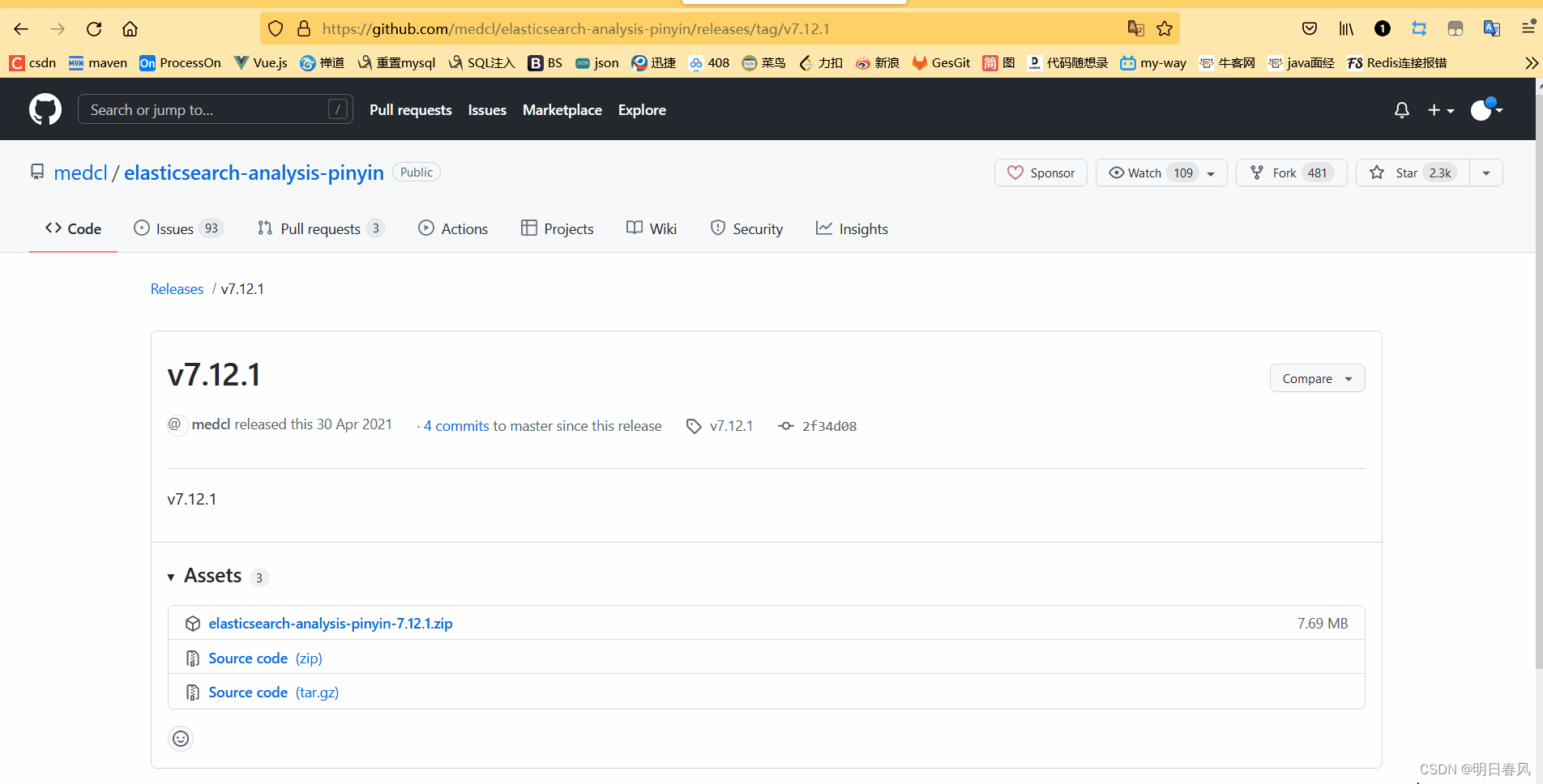
[root@db301601 ~]# docker exec -it es bash
[root@877298bbcfdf elasticsearch]# cd /usr/share/elasticsearch/bin
[root@877298bbcfdf bin]# ls
elasticsearch elasticsearch-cli elasticsearch-env-from-file elasticsearch-node elasticsearch-setup-passwords elasticsearch-sql-cli-7.12.1.jar x-pack-env
elasticsearch-certgen elasticsearch-croneval elasticsearch-keystore elasticsearch-plugin elasticsearch-shard elasticsearch-syskeygen x-pack-security-env
elasticsearch-certutil elasticsearch-env elasticsearch-migrate elasticsearch-saml-metadata elasticsearch-sql-cli elasticsearch-users x-pack-watcher-env
[root@877298bbcfdf bin]# cd /usr/share/elasticsearch
[root@877298bbcfdf elasticsearch]# ls
LICENSE.txt NOTICE.txt README.asciidoc bin config data jdk lib logs modules plugins
[root@877298bbcfdf elasticsearch]# cd /usr/share/elasticsearch/plugins
[root@877298bbcfdf plugins]# ls
analysis-ik[root@db301601 ~]# docker exec -it es /bin/bash
[root@877298bbcfdf elasticsearch]# ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.12.1/elasticsearch-analysis-pinyin-7.12.1.zip[root@877298bbcfdf elasticsearch]# ls
LICENSE.txt NOTICE.txt README.asciidoc bin config data jdk lib logs modules plugins
[root@877298bbcfdf elasticsearch]# cd plugins
[root@877298bbcfdf plugins]# ls
analysis-ik analysis-pinyin./是指当前目录的简写。在Linux和类Unix系统中,.表示当前目录,..表示上一级目录。因此,./表示当前目录下的文件或目录。在你的命令中,./elasticsearch-plugin意味着你希望在当前目录中执行名为elasticsearch-plugin的可执行文件。- 使用正确的命令来删除 Elasticsearch 中的插件。正确的命令是
elasticsearch-plugin remove analysis-ik。这个命令会将名为analysis-ik的插件从 Elasticsearch 中移除。 elasticsearch-plugin命令会将插件安装到 Elasticsearch 的插件目录中。通常情况下,插件目录位于 Elasticsearch 安装目录的plugins文件夹下。具体位置可能因操作系统和安装方式而异,但通常在/usr/share/elasticsearch/plugins或/opt/elasticsearch/plugins等位置。
1.2、离线安装拼音分词器:
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看数据卷目录:
docker volume inspect es-plugins
[root@db301601 ~]# docker restart es
es
[root@db301601 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
877298bbcfdf elasticsearch:7.12.1 "/bin/tini -- /usr/l…" 41 hours ago Up 2 seconds 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp es
881f28a337e6 kibana:7.12.1 "/bin/tini -- /usr/l…" 42 hours ago Up 42 hours 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
[root@db301601 ~]# docker volume ls
DRIVER VOLUME NAME
local 03b04390f4eefc2da60368f67dbc266b76ccb710fe4275535f77a2067204da11
local 7df7ad63d90a9a6c2e3440b37e261039402950dd96f11677c8936dacd2c03210
local ece02e3c8db3e86860f63fcc1fe9eb0a7c6f42a2b10d7a6c93d7172017886f40
local ef6b9cdbe2110ec4802b5941d87d83250d1eb12a547a61ed342a59776fa94184
local es-data
local es-logs
local es-plugins
local root_data01
local root_data02
local root_data03
[root@db301601 ~]# docker volume inspect es-plugins
[{"CreatedAt": "2024-04-26T16:46:19+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
[root@db301601 ~]# cd /var/lib/docker/volumes/es-plugins/_data
[root@db301601 _data]# ls
py
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
解压缩分词器安装包:把下载好的ik分词器解压缩,重命名为ik:

 上传到
上传到es容器的插件数据卷中:
重启容器: docker restart es(容器名字)
二、自定义分词器
注意事项:
pinyin分词器默认时有很多缺点,比如每个字都拆分变成拼音,不符合一般需求,并且如果使用pinyin分词器,默认的中文索引就没了,只剩下pinyin索引了。所以,需要完善以下几点:
- 分词时不仅包含汉字,还需包含拼音
- 分词时按词分,不是字
- 使用汉字查询时,不会查询到同音词条目docs
如果只是单独使用拼音分词器,是没办法满足具体业务使用场景的,这时候就需要自定义分词器, 通过自定义分词器,将ik分词器与拼音分词器整合起来,来保证我们的搜索既满足汉字也满足拼音: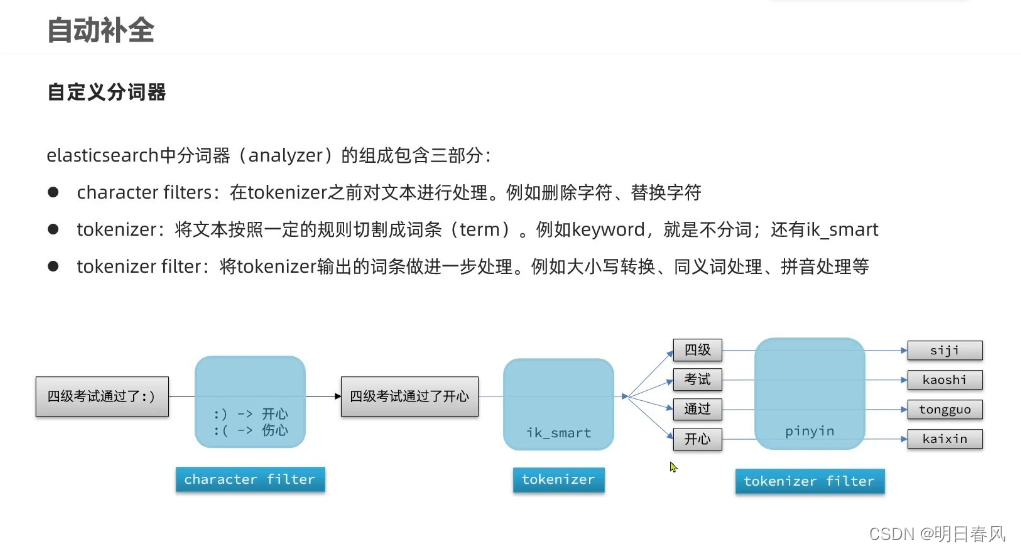
自定义分词器一定是在创建索引库的时候去设置,它只对你所指定的索引库test有效,settings是索引库配置,我们自定义了三步之中的tokenizer和filter:

不完善的错误写法:
PUT /test
{"settings": {"analysis": {"analyzer": {"my_analyzer":{//自定义分词器名称//先分词,分好词后交给filter去处理:"tokenizer":"ik_max_word","filter":"py"}},"filter": {"py":{"type":"pinyin","keep_full_pinyin":false,//单个字的拼音"keep_joined_full_pinyin":true,//全拼"keep_original":true, //保留中文"limit_first_letter_length":16,"remove_duplicated_term":true,"none_chinese_pinyin_tokenize":false}}}},"mappings": {"properties": {"name":{"type": "text","analyzer": "my_analyzer" //用my_analyzer分词器}}}
} 
测试1:这个没问题
GET /test/_analyze
{"text":"我爱螺蛳粉","analyzer": "my_analyzer"
}GET /test/_analyze
{"text":"如家酒店还不错","analyzer": "my_analyzer"
}会生成中文、全拼音、词的缩写



测试2:同音词问题
拼音分词器适合在创建倒排索引的时候使用,但不能在搜索中使用,否则会出现同音词问题
POST /test/_doc/1
{"id":1,"name":"狮子"
}POST /test/_doc/2
{"id":2,"name":"虱子"
}GET /test/_search
{"query":{"match":{"name":"掉入狮子笼怎么办"}}
} 
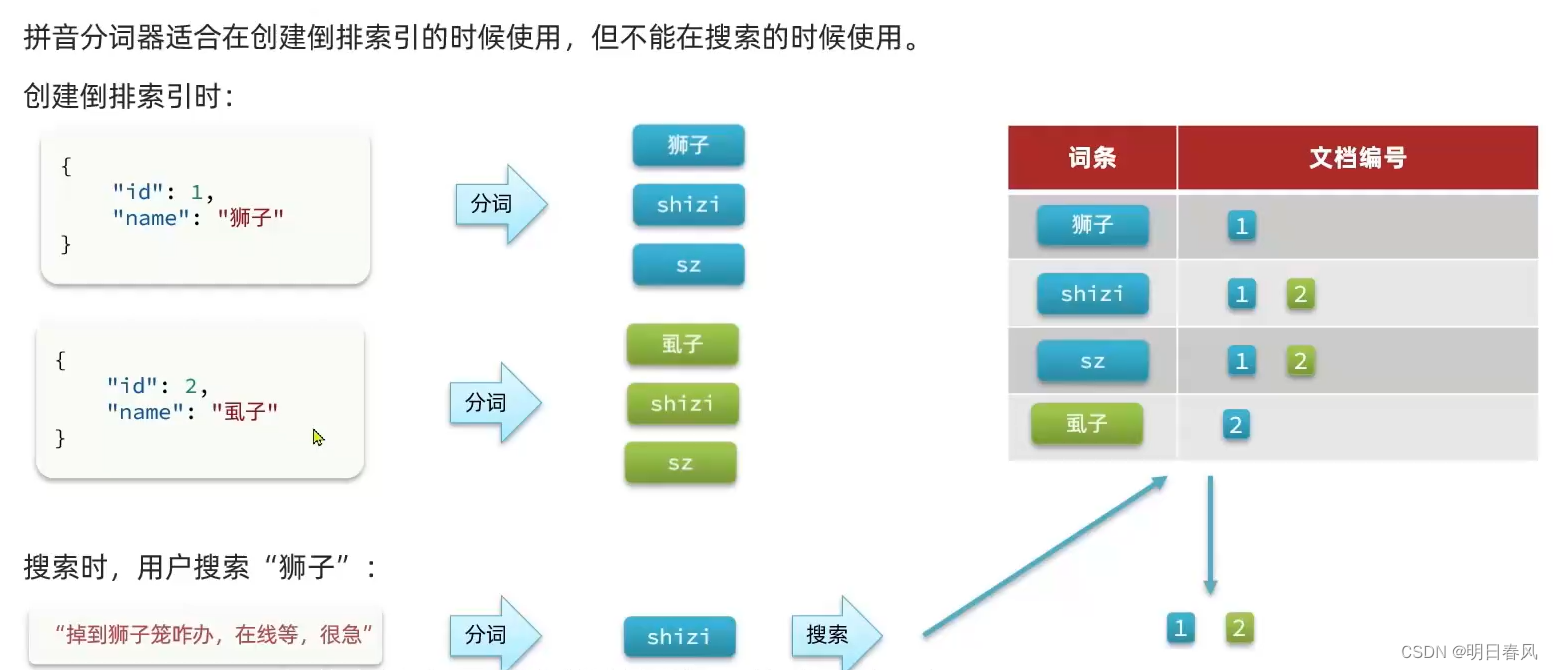
为了避免出现同音词问题,拼音分词器适合在创建倒排索引的时候使用,不在搜索中使用
解决方法:
在做mapping映射时,指定两个:analyzer是创建索引时用的,search_analyzer是在搜索时需要的,用户搜的是中文,就拿中文去搜,搜的是英文,才拿英文去搜:
PUT /test
{"settings": {"analysis": {"analyzer": {"my_analyzer":{"tokenizer":"ik_max_word","filter":"py"}},"filter": {"py":{"type":"pinyin","keep_full_pinyin":false,"keep_joined_full_pinyin":true,"keep_original":true,"limit_first_letter_length":16,"remove_duplicated_term":true,"none_chinese_pinyin_tokenize":false}}}},"mappings": {"properties": {"name":{"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
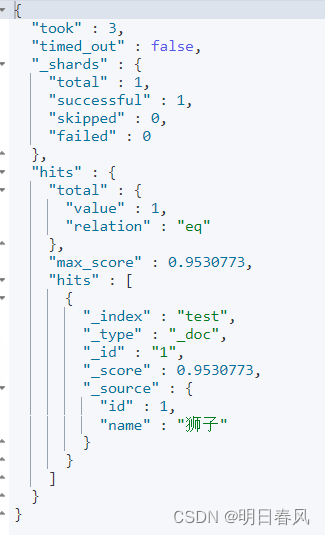
这样才能正确搜出:
POST /test/_doc/1
{"id":1,"name":"狮子"
}POST /test/_doc/2
{"id":2,"name":"虱子"
}GET /test/_search
{"query":{"match":{"name":"掉入狮子笼怎么办"}}
}
总结:

三、自动补全:
刚才我们已经学习了拼音分词器的详细用法,已经能够实现基于拼音去做数据搜索了。接下来我们就来看一下自动补全的基本语法,将来我们就能够实现基于拼音去做自动补全了。
在ES当中自动补全功能是基于completion suggester功能来实现的。这个功能可以在用户输入任意关键字时去索引库中,根据指定字段去匹配,以”用户输入关键字”为前缀的所有词条,并且返回,这就是自动补全 。
自动补全功能对于要查询的字段,会有两个特殊的要求。
- 第一要求:参与自动补全查询的字段必须得是completion类型。 咱们以前学习字段的数据类型的时候,我们学过有字符串:text、keyword、数值类型、日期类型,这里又多了一种类型叫completion,它就是专门用来做自动补全查询的;
- 要求二:参与自动补全查询的字段值最好得是多个词条形成的数组,这样更有利于将来做自动补全。尽量把词语分成一个一个的词条放到数组当中 ,这样可以更加人性化。例如要自动补全的字段名叫title,它的字段值可以看到是个数组:耳机的产品信息,它形成了两个词条,而不是一个字符串,为什么他要分开呢?自动补全是根据词条做自动补全的,如果你把它俩合成一个字符串,那将来我们再去做自动补全时,你就只能根据s来补全。那当用户输入w的时候,它无法搜出产品索尼名称。
示例:

DSL语句:
PUT test2
{"mappings":{"properties":{"title":{"type":"completion"}}}
}// "title" 字段的数据类型是一个数组(Array)。数组可以包含多个元素,
//这里具体包含了两个字符串,如 "Sony" 和 "WH-1000XM3"
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{"title": ["Nintendo", "switch"]
}
查询语法:
将来我们去做completion suggester查询的时候,查询语法比较特殊: 它这里没有用query,因为不再是搜索了,而是去做自动补全,所以变成了suggest。

GET /test2/_search
{"suggest": {"title_suggest": { //设置这个自动查询操作的名称,名字随便"text": "s", // 关键字,用户输入的前缀,s开头的这些词条"completion": { //自动补全的类型"field": "title", // 自动补全查询的字段名"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
{"took" : 16,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"suggest" : {"title_suggest" : [{"text" : "s","offset" : 0,"length" : 1,"options" : [{"text" : "SK-II","_index" : "test2","_type" : "_doc","_id" : "_6UOJY8B5is2vprLHEOq","_score" : 1.0,"_source" : {"title" : ["SK-II","PITERA"]}},{"text" : "Sony","_index" : "test2","_type" : "_doc","_id" : "_qUOJY8B5is2vprLFUNq","_score" : 1.0,"_source" : {"title" : ["Sony","WH-1000XM3"]}},{"text" : "switch","_index" : "test2","_type" : "_doc","_id" : "AKUOJY8B5is2vprLIERe","_score" : 1.0,"_source" : {"title" : ["Nintendo","switch"]}}]}]}
}除了返回text外,还返回了文档的原始信息:
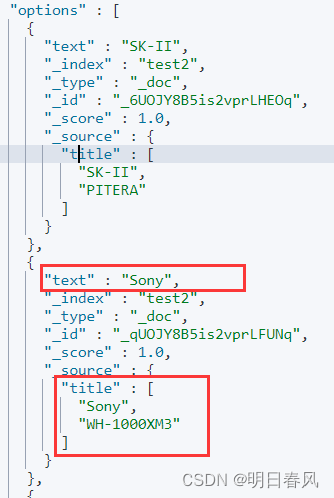
输入so就只查出来一条了:


这就是自动补全功能