目录
大纲
一条指令的执行
取指令
执行指令
数据传送类(mov、load、store)
运算类指令(加、减、乘、除、移位、与、或)
转移类指令(jmp、jxxx)
如何看懂注释
袁版注释⻛格(16年以后的真题)
唐版注释⻛格(16年以前的真题)
【※】CPU图示
编辑 【※】五段式流水线
数据冒险
控制冒险 —— 会改变PC值的
MIPS架构流水线结构
常⻅硬件
操作元件(组合逻辑元件)
存储元件(时序逻辑元件)
数据通路
微程序控制器
对应关系
工作过程
编码方式/控制方式
地址形成方式
微指令的格式
高级流水线技术
多处理器概念
常考点
SISD,SIMD,MIMD的基本概念
其他相关概念(了解即可,重要的考点都列在上面的常考点表格中)
大纲
| CPU的功能和基本结构 |
| ||||||
| 指令执⾏过程 |
| ||||||
| 控制器的功能和⼯作原理 |
| ||||||
| 异常和中断机制 |
| ||||||
| 指令流⽔线 |
| ||||||
| 多处理器基本概念 |
|
一条指令的执行
取指令
- 即,将PC所指的指令取出来到IR的过程
- PC->MAR
M(MAR)->MDR->IR
PC+"1"->PC
- "1"为下一条指令(注意指令的字长)
- +“1”的实现方式:
- 有加法功能的ALU
- 加法器
- 有自增功能的寄存器(PC)
执行指令
数据传送类(mov、load、store)
- 寄存器->寄存器
- 寄存器->主存
- 主存->寄存器
- 立即数->寄存器
- 立即数->主存
- 寄存器->暂存寄存器
PS:
- 关注读/写主存:
- 读:
地址->MAR
M(MAR)->MDR
MDR->目的地
- 写:
地址->MAR
数据->MDR
MDR->M(MAR)
- 关注总线的占用来安排控制信号(总线是临界资源)
运算类指令(加、减、乘、除、移位、与、或)
转移类指令(jmp、jxxx)
如何看懂注释
袁版注释⻛格(16年以后的真题)
| 数据在通⽤寄存器组 |
|
| 数据在某个特殊名字的寄存器 |
|
| 数据在主存 |
|
| 特点总结 |
|
唐版注释⻛格(16年以前的真题)
| 数据在通⽤寄存器组 | ⾥的值;箭头右边表示存⼊某个寄存器不加⼩括 eg:(R6)×(R3)→R2。将寄存器R6×R3的内容写⼊R2
|
| 数据在某个特殊名字的寄存器 |
|
| 数据在主存 |
|
| 特点总结 |
|
【※】CPU图示
 【※】五段式流水线
【※】五段式流水线
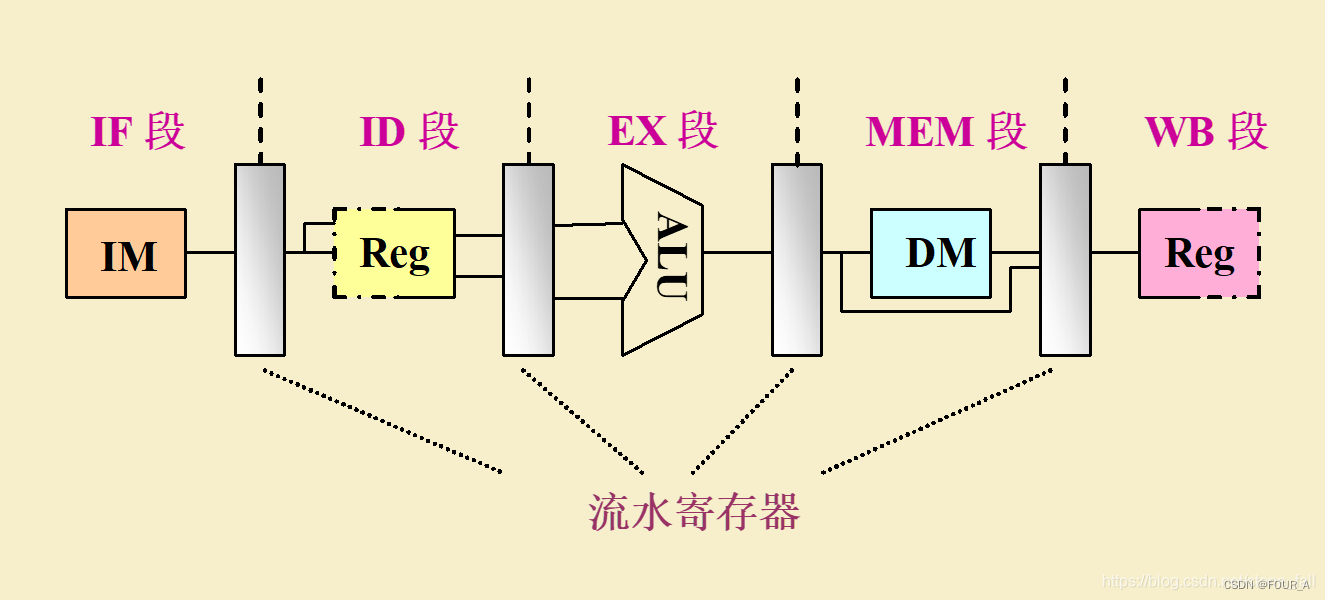
- CPU根据指令周期的不同阶段来区分是指令还是数据
数据冒险
- 什么指令会导致数据冒险?
- 前面的指令:写某个寄存器 —— 【WB 第五个段】
- 后面的指令:读(同一个)寄存器 —— 【ID 第二个段】
- 分析思路
- 一条一条指令从前往后分析,如果一条指令写了某个寄存器,则观察与之相邻的3条指令中,有没有哪条指令需要读同一个寄存器。
- 当后面的指令和前面的指令中间,还有其他三条指令时,才不会发生数据冒险
控制冒险 —— 会改变PC值的
- 指令格式:jxxx(X86) / bxx(MIPS)
- 无条件转移(call和ret属于无条件转移)
- 【EX 第三个段改变PC】
- 停两个周期,再取下一条指令(IF段),就不会发生控制冒险
- 有条件转移
- 【在EX段设置条件码,Mem 第四个段确定是否将PC值更新为转移目标地址】
- 停四个周期,再取下一条指令(IF段),就不会发生控制冒险
MIPS架构流水线结构
- IF:取指令阶段:取出指令放到IR
- ID:对指令进行译码,并用IR中的寄存器地址去访问通用寄存器组,读出所需的操作数。
- EX:执行/计算地址:ALU运算结果放入锁存器
- MEM:访存:
- 该周期处理的指令只有load、store和分支指令
- 其它类型的指令在此周期不做任何操作
- 写回DataCache,运算形指令为空
- WB:写回:若需写回寄存器则写回
常⻅硬件
操作元件(组合逻辑元件)
![]() 没有存储功能的元件
没有存储功能的元件
| 三态⻔ |
|
| 加法器(Adder) |
|
| 算术逻辑单元(ALU) |
|
| 多路选择器(MUX) |
|
| 译码器(Decoder) |
|

存储元件(时序逻辑元件)
| 普通寄存器 |
|
| 暂存寄存器 |
|
| 通⽤寄存器组 |
|
| PS:有的寄存器可能⽀持特殊功能 |
|

数据通路
- 数据通路:
- 是指令的执⾏部件,包括运算器、寄存器、数据传输的线路、异常和中断的处理逻辑、组合逻辑电路和时序逻辑电路等
- 由控制部件控制,不包含控制部件
- 实现CPU内部的运算器与寄存器及寄存器之间的数据交换
- 数据通路的基本结构:
- CPU内部单总线:
- 较多冲突
- 一个时钟内只允许传一个数据
- CPU内部多总线
- 专用数据通路:硬件量大
 PS:【内部总线是指同一个部件、系统总线是指同一台计算机的各个部件之间】
PS:【内部总线是指同一个部件、系统总线是指同一台计算机的各个部件之间】
- CPU内部单总线:
微程序控制器
对应关系
一个程序对应多条指令,一条指令对应一个微程序,一个微程序对应多条微指令,一个微指令对应一个或多个微命令,一个微命令对应一个微操作。

工作过程
- 执行取微指令公共操作
- 由机器指令的操作码字段通过微地址形成部件产生该指令所对应的微程序的入口地址,并送入CMAR【微程序入口地址是机器指令的操作码字段产生的】
- 从CM中逐条取出对应的微指令并执行
- 执行完对应于一条机器指令的一个微程序后,又回到取指微程序的入口地址,继续第一步
编码方式/控制方式
| 目的 | 保证速度的情况下尽量缩短指令字长 |
| 直接编码方式 |
|
| 字段直接编码法 |
|
地址形成方式
后继微地址的形成类型:
- 直接由微指令的下地址字段指出。格式中设置一个下地址(断定方式)。
- 根据机器指令的操作码形成。机器指令取至IR后,微指令的地址由操作码经微地址形成部件形成。
- 增量计数器法(微地址连续)。根据各种标志决定微指令分支转移的地址
- 通过测试网络形成。由硬件直接产生微程序入口地址
微指令的格式
| 水平型 | 垂直型 |
| 并行操作能力强,效率高,灵活性强 | 相反 |
| 执行一条指令的时间短 | 相反 |
| 微指令字位数较多,微程序较短 | 相反 |
| 用户难以掌握 | 与指令相似,用户好掌握 |
- 直接由微指令的下地址字段指出。格式中设置一个下地址(断定方式)。
- 根据机器指令的操作码形成。机器指令取至IR后,微指令的地址由操作码经微地址形成部件形成。
- 增量计数器法(微地址连续)。根据各种标志决定微指令分支转移的地址
- 通过测试网络形成。由硬件直接产生微程序入口地址
- 执行取微指令公共操作
- 由机器指令的操作码字段通过微地址形成部件产生该指令所对应的微程序的入口地址,并送入CMAR【微程序入口地址是机器指令的操作码字段产生的】
- 从CM中逐条取出对应的微指令并执行
- 执行完对应于一条机器指令的一个微程序后,又回到取指微程序的入口地址,继续第一步
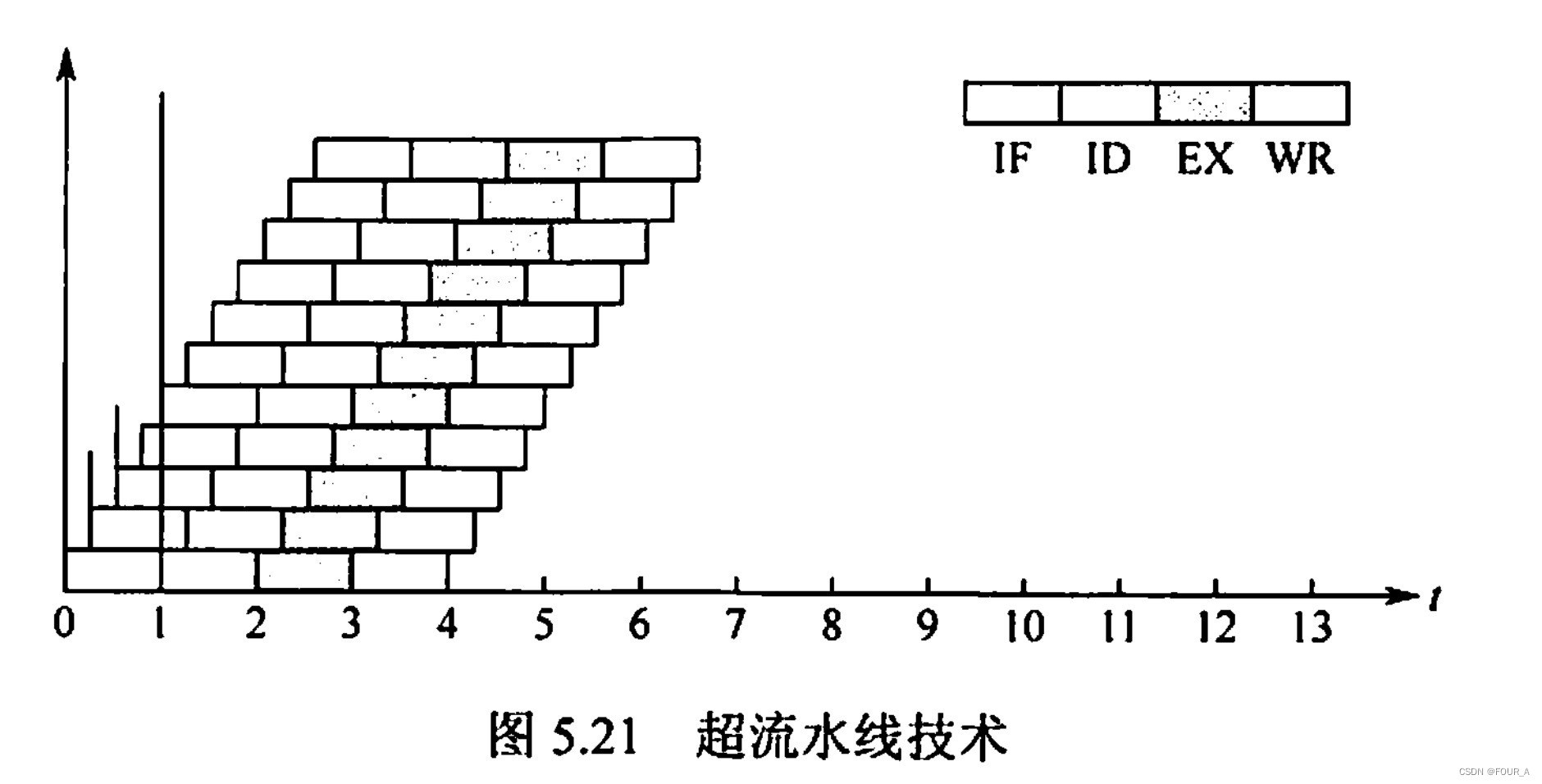
高级流水线技术
|
| 定义 | 特点 |
| 超标量流水线技术 | 动态多发射技术
|
|
| 超长指令字技术 | 静态多发射技术
|
|
| 超流水线技术 | 提高主频来提高流水线性能
|
|

多处理器概念
常考点
SISD/SIMD/MIMD的区分:
- 控制部件的多少决定是SI还是MI
- 处理数据单元的多少决定是SD还是MD
| 多处理机 |
|
| 超程序技术 |
|
| 双核技术 |
|
SISD,SIMD,MIMD的基本概念
- 基于指令流的数量和数据流的数量,将计算机体系结构分为SISD,SIMD,MISD和MIMD
| 单指令流单数据流结构(SISD) |
| ||||
| 单指令流多数据流结构(SIMD) Single instruction, multiple data |
| ||||
| 多指令流单数据流结构(MISD) Multiple instruction, single data |
| ||||
| 多指令流多数据流结构(MIMD) Multiple instruction, multiple data |
| ||||
| 联系与区别 |
|
其他相关概念(了解即可,重要的考点都列在上面的常考点表格中)
| 硬件多线程 |
| ||||||
| 多核处理器 |
| ||||||
| 共享内存多处理器 |
|