- 来自 Facebook AI Research、University College London 和 New York University 的 Lewis 等人的论文介绍了检索增强生成(Retrieval-Augmented Generation,RAG)模型,该模型结合了预训练的参数化和非参数化记忆,用于语言生成任务。
- 为了解决大型预训练语言模型的局限性,如难以访问和精确操作知识,RAG 模型将预训练的序列到序列(seq2seq)模型与维基百科的密集向量索引合并,通过神经检索器访问。
- RAG 框架包括两个模型:RAG-Sequence,对整个序列使用相同的检索文档;RAG-Token,允许每个令牌使用不同的段落。
- 检索组件 Dense Passage Retriever(DPR)使用基于 BERT 的文档和查询编码器的双编码器架构。生成器组件使用 BART-large,这是一个具有 4 亿个参数的预训练 seq2seq transformer。
- RAG 模型在检索器和生成器组件上进行了联合训练,没有直接监督要检索哪些文档,使用带有 Adam 的随机梯度下降。训练使用维基百科转储作为非参数知识源,分割成 2100 万个 100 个单词的块。
- 以下是用于查询/文档嵌入和检索的方法和模型摘要,以及 RAG 框架的端到端结构:
- 查询/文档嵌入:
- 检索组件 Dense Passage Retriever(DPR)遵循双编码器架构。
- DPR 使用 BERTBASE 作为文档和查询编码器的基础。
- 对于文档 z,文档编码器 BERTd 会生成密集表示 d(z)。
- 对于查询 x,查询编码器 BERTq 会生成查询表示 q(x)。
- 嵌入的创建使得给定查询的相关文档在嵌入空间中接近,从而实现有效的检索。
- 检索过程:
- 检索过程涉及计算具有最高先验概率的 top-k 文档,这本质上是一个最大内积搜索(MIPS)问题。
- MIPS 问题以亚线性时间近似求解,以有效地检索相关文档。
- 端到端结构:
- RAG 模型使用输入序列 x 检索文本文档 z,然后将其用作生成目标序列 y 的附加上下文。
- 生成器组件使用 BART-large 建模,这是一个具有 4 亿个参数的预训练 seq2seq transformer。BART-large 将输入 x 与检索到的内容 z 结合起来进行生成。
- RAG-Sequence 模型使用相同的检索文档生成完整序列,而 RAG-Token 模型可以对每个令牌使用不同的段落。
- 训练过程涉及在没有直接监督应该检索哪个文档的情况下对检索器和生成器组件进行联合训练。训练使用随机梯度下降和 Adam 最小化每个目标的负边际对数似然。
- 值得注意的是,文档编码器 BERTd 在训练期间保持固定,避免了定期更新文档索引的需要。
- 查询/文档嵌入:
- 论文中的下图展示了所提出方法的概述。他们将预训练的检索器(查询编码器+文档索引)与预训练的 seq2seq 模型(生成器)结合,并进行端到端微调。对于查询 x,他们使用最大内积搜索(MIPS)找到 top-K 个文档 zi。对于最终预测 y,他们将 z 视为潜变量,并在给定不同文档的情况下对 seq2seq 预测进行边缘化。
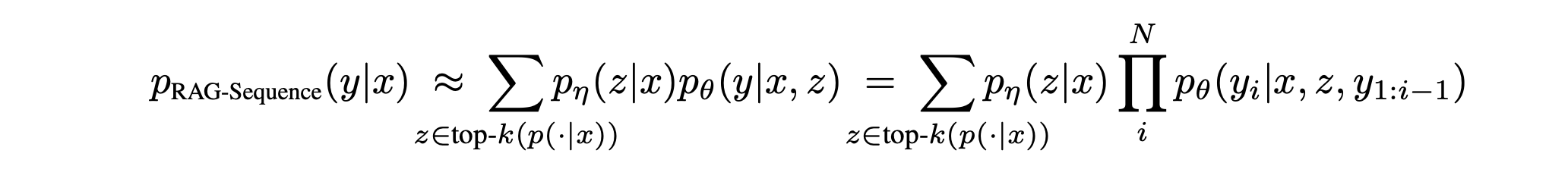
- 在开放域问答任务中,RAG 建立了新的最先进结果,优于参数化 seq2seq 模型和特定任务的检索提取架构。RAG 模型表现出即使在检索到的文档中没有正确答案的情况下也能生成正确答案的能力。
- RAG-Sequence 在 Open MS-MARCO NLG 中超过了 BART,表明更少的幻觉和更多事实正确的文本生成。RAG-Token 在 Jeopardy 问题生成中优于 RAG-Sequence,展示了更高的事实性和特异性。
- 在 FEVER 事实验证任务中,RAG 模型取得了接近最先进模型的结果,而这些模型需要更复杂的架构和中间检索监督。
- 这项研究展示了混合生成模型的有效性,结合了参数化和非参数化记忆,为将这些组件结合用于一系列 NLP 任务提供了新的方向。