1.用例的设计原则
用Pytest写用例时候,一定要按照下面的规则去写,否则不符合规则的测试用例是不会执行的
1、文件名以 test_.py 文件和test.py
2、以 test 开头的函数
3、以 Test 开头的类,不能包含__init__方法
4、以 test_ 开头的类里面的方法
5、所有的包 pakege 必须要有__init__.py 文件
2.pycharm执行用例配置

pytest_10">3.常用pytest执行用例命令
1.查看pytest命令行参数,可以用pytest -h 或pytest --help
2.执行当前文件夹下面的所有文件
pytest 文件名/
3.执行具体的某一测试文件
pytest 脚本名称.py
4.-k 匹配用例名称
执行测试用例名称包含qq的所有用例:
pytest -k qq test_1.py
根据用例名称排除某些用例
pytest -k "not qq" test_1.py
同时匹配不同的用例名称
pytest -k "wechat or webo" test_1.py
5.按节点运行
每个收集的测试都分配了一个唯一的nodeid,它由模块文件名和 :: 组成 来自参数化的类名,函数名和参数,由:: characters分隔
运行.py模块里面的某个函数:
pytest test_mod.py::test_func
运行.py模块里面,测试类里面的某个方法
pytest test_mod.py::TestClass::test_method
6.-x 遇到错误时停止测试
pytest -x test_class.py
7.–maxfail=num 当用例错误个数达到指定数量时,停止测试
pytest --maxfail=1
8.-q 简单打印,只打印测试用例的执行结果
pytest -q test_1.py
9.-s 详细打印,-v 更加详细的打印,通过的.用pass表示
pytest -s test_1.py
pytest -v test_1.py
4.用例执行状态
用例执行完成后,每条用例都有自己的状态,常见的状态有:
passed:测试通过
failed:断言失败
error:用例本身写的质量不行,本身代码报错(譬如:fixture不存在,fixture里面有报错)
xfail:预期失败,加了 @pytest.mark.xfail()
5.常用断言
pytest 里面断言实际上就是 python 里面的 assert 断言方法,常用的有以下几种:
assert xx :判断 xx 为真
assert not xx :判断 xx 不为真
assert a in b :判断 b 包含 a
assert a == b :判断 a 等于 b
assert a != b :判断 a 不等于 b
6.setup和teardown
按照范围的不同,一共有以下十种:
- 模块级别:setup_module、teardown_module
setup_module:在每个模块执行前执行
teardown_module:在每个模块执行后执行
有几个模块就有几对 - 函数级别:setup_function、teardown_function,不在类中的方法
setup_function:在每个函数执行前执行
teardown_function:在每个函数执行后执行
有几个函数就有几对 - 类级别:setup_class、teardown_class
setup_class:在每个类执行前执行
teardown_class:在每个类执行后执行
有几个类就有几对 - 方法级别:setup_method、teardown_method
setup_method:在类里面的每个方法执行前执行
teardown_method:在类里面每个方法执行后执行 - 方法细化级别:setup、teardown
跟上面的方法级别的含义一致,两种写法都可以
注意:函数级别和方法级别的区别在于:函数级别的前置后置是针对不在类中的方法,而不是测试用例
7.跳过测试用例
pytestmarkskip_111">7.1 @pytest.mark.skip
跳过执行测试用例,有可选参数reason:跳过的原因,会在执行结果中打印
@pytest.mark.skip
def test_wechat():
print('此测试用例不会被执行')
pytestmarkskipifcondition_reason_119">7.1 @pytest.mark.skipif(condition, reason=“”)
作用:希望有条件地跳过某些测试用例
注意:condition需要返回True才会跳过
@pytest.mark.skipif(sys.platform == 'win32', reason="does not run on windows")
def test_function(self):
print("不能在window上运行")
8.参数化
8.1语法
@pytest.mark.parametrize(argnames, argvalues, indirect=False, ids=None, scope=None)
1.argnames
含义:参数名字
格式:字符串"arg1,arg2,arg3"【需要用逗号分隔】
2.argvalues
含义:参数值列表
格式:必须是列表,如:[ val1,val2,val3 ]
如果只有一个参数,里面则是值的列表
@pytest.mark.parametrize(“username”, [“yy”, “yy2”,“yy3”])
如果有多个参数例,则需要用元组来存放值,一个元组对应一组参数的值,如:
@pytest.mark.parametrize(“name,pwd”, [(“yy1”, “123”), (“yy2”, “123”), (“yy3”, “123”)]),
也可以用字典保存
@pytest.mark.parametrize(“name,pwd”,[{‘name’:‘yy1’,‘pwd’:‘123’},
{‘name’:‘yy2’,‘pwd’:‘123’},{‘name’:‘yy3’,‘pwd’:‘123’}])
3.ids
含义:用例的ID
格式:传一个列表,[“”,“”,“”]
作用:可以标识每一个测试用例,自定义测试数据结果的显示,为了增加可读性
强调:ids的长度需要与测试数据列表的长度一致
场景:只有测试数据和期望结果不一样,但操作步骤是一样的测试用例可以用上参数化;
示例:
#未参数化
def test_1():
assert 3 + 5 == 9
def test_2():
assert 2 + 4 == 6
def test_3():
assert 6 * 9 == 42
#参数化
@pytest.mark.parametrize("test_input,expected", [("3+5", 8),("2+4", 6), ("6*9",42)])
def test_eval(test_input, expected):
print(f"测试数据{test_input},期望结果{expected}")
assert eval(test_input) == expected
8.2 参数化之数据格式
1.[(),(),()…] 列表嵌套元组
@pytest.mark.parametrize("test_input,expected", [("3+5", 8),("2+4", 6), ("6*9",42)])
def test_eval(test_input, expected):
print(f"测试数据{test_input},期望结果{expected}")
assert eval(test_input) == expected

2.[{},{},{}…] 列表嵌套字典
data = [
{'test_input':"3+5",'expected':8},
{'test_input':"6+5",'expected':11},
{'test_input':"3*5",'expected':15},
]
@pytest.mark.parametrize('dic',data)
def test_eval(dic):
assert eval(dic['test_input']) == dic['expected']
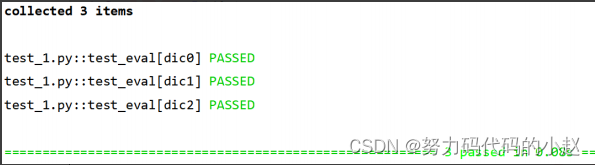
只有一条用例,但是利用参数化输入三组不同的测试数据和期望结果,最终执行的测试用例数=3,可以节省很多代码
8.3参数化之“笛卡尔积”
# 笛卡尔积,组合数据
data_1 = [1, 2, 3]
data_2 = ['x', 'y']
@pytest.mark.parametrize('a', data_1)
@pytest.mark.parametrize('b', data_2)
def test_parametrize_1(a, b):
print(f'笛卡尔积 测试数据为 : {a},{b}')
运行结果如下:

备注:
一个函数或一个类可以装饰多个 @pytest.mark.parametrize,最终生成的用例数是nm,比如上面的代码就是:参数a的数据有3个,参数b的数据有2个,所以最终的用例数有32=6条。当参数化装饰器有很多个的时候,用例数都等于nnnn…
8.4参数化之标记数据
# 标记参数化
@pytest.mark.parametrize("test_input,expected", [
("3+5", 8),
("2+4", 6),
pytest.param("6*9", 42, marks=pytest.mark.xfail),# 预期失败
pytest.param("6*6", 42, marks=pytest.mark.skip) # 跳过
])
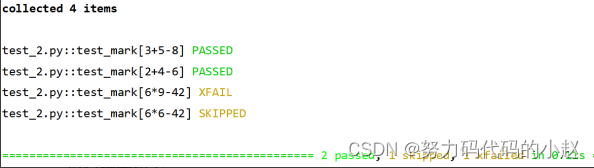
def test_mark(test_input, expected):
assert eval(test_input) == expected
运行结果如下:
8.5参数化之增加可读性
ids传递的数据:
import pytest
data = [
{'test_input':"3+5",'expected':8},
{'test_input':"6+5",'expected':11},
{'test_input':"3*5",'expected':15},
]
ids = [f"test_input的值是{dic['test_input']},expected的值是{dic['expected']}"for
dic in data]
@pytest.mark.parametrize('dic',data,ids=ids)
def test_eval(dic):
assert eval(dic['test_input']) == dic['expected']
9.conftest.py
conftest.py配置fixture注意事项
pytest会默认读取conftest.py里面的所有fixture。conftest.py 文件名称是固定的,不能改动
不同目录可以有自己的conftest.py,一个项目中可以有多个conftest.py。测试用例文件中不需要手动import conftest.py,pytest会自动查找
10. fixture
10.1 fixture的优势
- 命名方式灵活,不局限于 setup 和teardown 这几个命名
- conftest.py 配置里可以实现数据共享,不需要 import 就能自动找到fixture
- scope=“module” 可以实现多个.py 跨文件共享前置
- scope=“session” 以实现多个.py 跨文件使用一个 session 来完成多个用例
- 如果fixture使用了yield返回值,则不能在用例中显示调用fixture
10.2定义
语法:
@pytest.fixture(scope="function", params=None, autouse=False, ids=None,
name=None)
def fixture_name():
print("fixture初始化的参数列表")
参数含义:
scope:可以理解成fixture的作用域,默认:function,还有class、module、package、session
四个【常用】
function(默认):每个测试函数都会得到一个新的 fixture 实例。这是最常见的用法,适用于大多数情况。
class:每个测试类会得到一个新的 fixture 实例,该实例在类中的所有测试方法之间共享。这在你需要在类的多个测试方法之间共享状态时非常有用。
module:整个测试模块只创建一个 fixture 实例,并在该模块的所有测试函数之间共享。这适用于模块级别的设置和清理。
session:整个测试会话只创建一个 fixture 实例,并在所有测试模块和函数之间共享。这通常用于设置和清理那些非常昂贵或耗时的资源,如数据库连接。
package:在一个包中,该fixture只会被执行一次
autouse:默认:False,需要用例手动调用该fixture;如果是True,所有作用域内的测试用例都
会自动调用该fixture
name:默认:装饰器的名称,同一模块的fixture相互调用建议写个不同的name
10.3调用
调用方法:
只需要在引用fixture函数的测试用例里面传入被@pytest.fixture这个装饰器装饰的函数的名字即可,就
会调用fixture函数中定义的功能,用yield关键字去划分是setup还是teardown,yield前面实现的功能是
setup初始化功能,yield后面实现的功能是teardown清场功能。