参考本篇->LOWORD和HIWORD函数_hidword-CSDN博客
一,如何获取一个64位整数的高32位和低32位
原理其实很简单:
解释一些概念
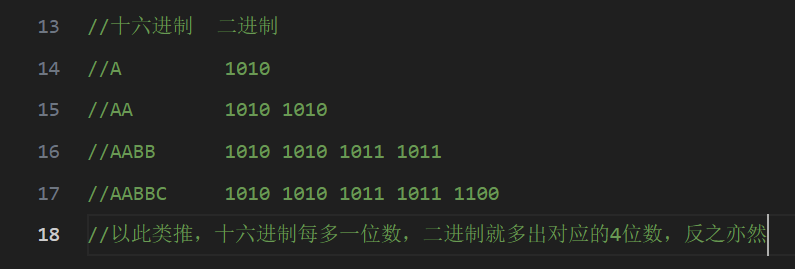
①十六进制和二进制直接挂钩
一个十六位的十六进制数【0XAABBCCDD12345678】转为二进制的过程是把其中的每个数转为对应的二进制,如下图所示:
②字的概念
字的英文是word,
一个字是2个字节,在【#include <windows.h>】库中有相应的数据类型是WORD
两个字是4个字节,在【#include <windows.h>】库中有相应的数据类型是DWORD,加个D就是double的意思
没有操作四个字的数据类型(也可能是博主孤陋寡闻了,有错恳请指出)
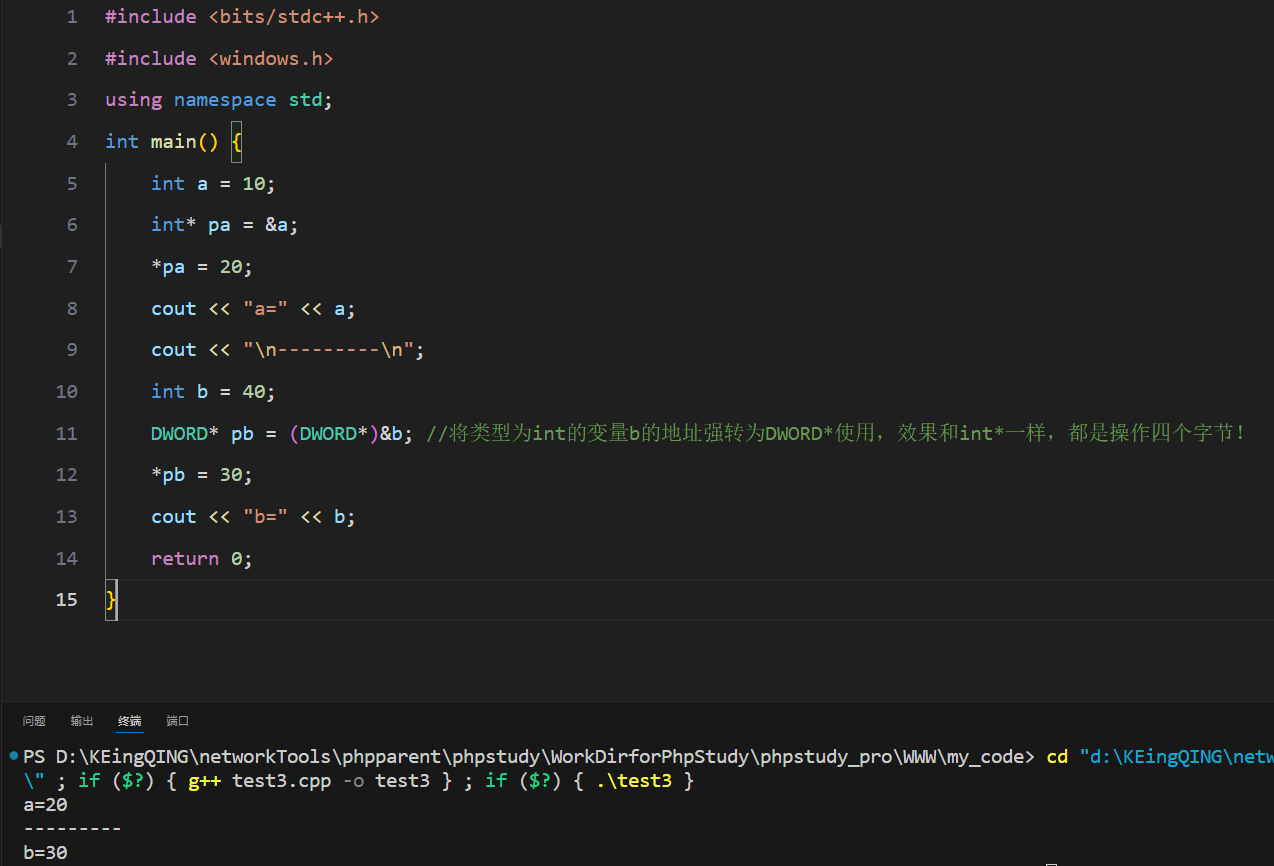
使用字类型来操作数据和使用基本数据类型操作数据本质是相同的,例如下图,DWORD操作4个字节,int也操作4个字节,因此它们的指针都能对整数变量的地址进行正确操作(这也是为什么逆向分析过程中工具的反汇编代码大都不用int*来表示4字节指针而是用DWORD*)
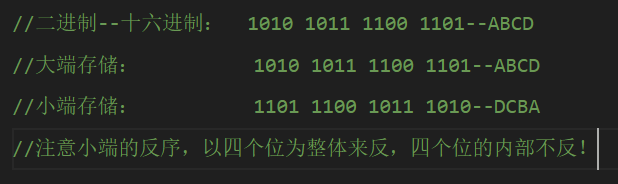
③大、小端存储
“计算机只存储二进制数据”算是个只要看到这篇博客的人就肯定清楚的概念,但存放的顺序并不统一,高前低后为大端(高低指数据的高位地位,前后指内存地址前后,较小的地址在前),因此大端模式是按数据的正序来存储的,小端则反之
另外,存储时是以字节(4个bit位,即4个二进制数或者说1个十六进制数)为一个单位来存储的,因此所说的大、小端正反排序针对的是每个字节,具体到每个字节对应的二进制bit位则都是正序的,如下图所示!
有了上面的概念就能解释清楚下面的代码了——
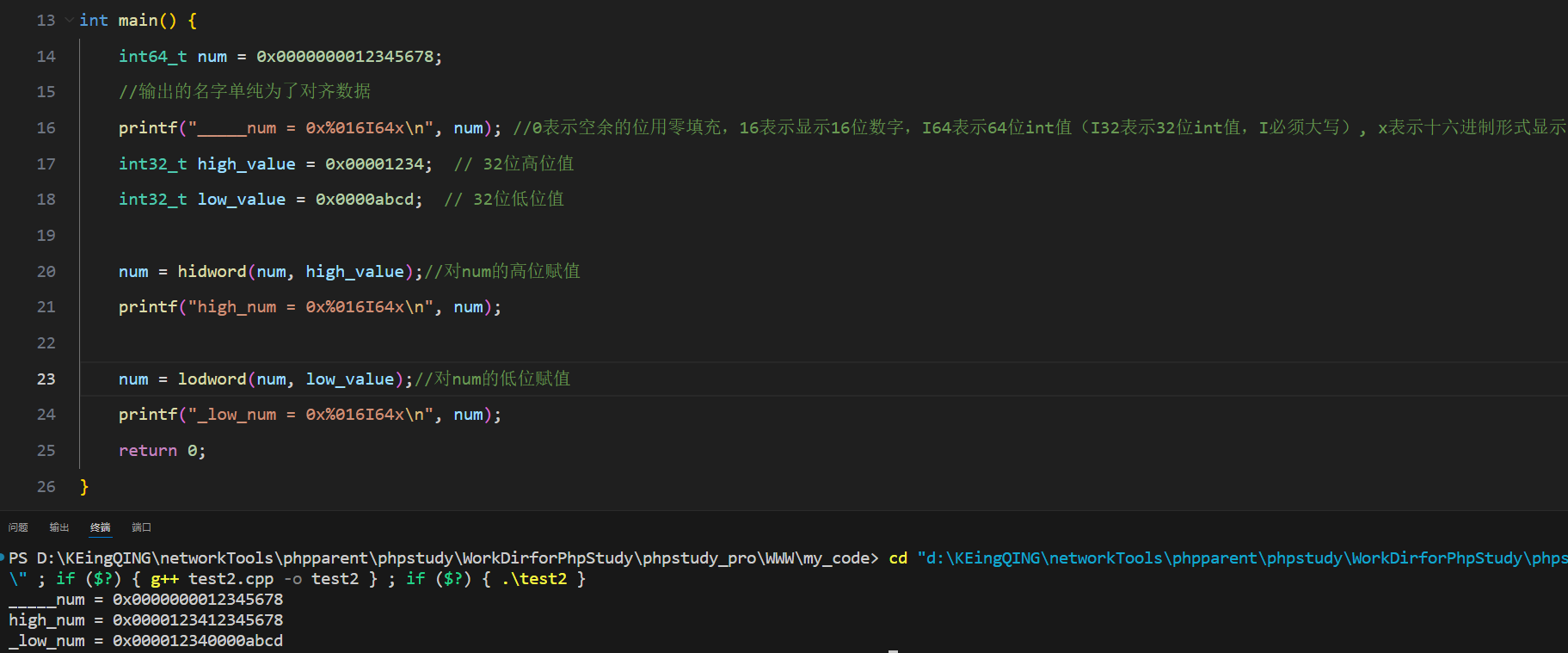
HIDWORD(x):将x的地址强转为双字指针(DWORD*)后加一,等于跳过一个字指向高位(小端存储,高位在后),最后解引用获得高位的双字(DWORD)数据即高32位
LODWORD(x):将x的地址强转为双字指针(DWORD*),原本指向“四字”数据的地址强转为双字指针(DWORD*),相当于保留低位双字舍弃高位双字
#include <bits/stdc++.h> #include <windows.h> //字类型在这里面,但万能头文件里没有windows.h所以单独引入 //定义两个宏,分别用于截取高位和地位 #define HIDWORD(x) (*((DWORD*)&(x) + 1)) #define LODWORD(x) (*((DWORD*)&(x))) int main() {int64_t dwValue; //dwValue = 0XAABBCCDD12345678;int32_t high = HIDWORD(dwValue);int32_t low = LODWORD(dwValue);printf("high = 0x%x, low = 0x%x", high, low); //输出high = 0xaabbccdd, low = 0x12345678return 0; }
二,如何对一个64位整数的高/低位赋值
标题【一】所探讨的仅是如何获取高/低位的数据,如何对一个64位整数的高/低位赋值呢?
例如一个64位整数为【0x123456abdc654321】,对其高位赋值为a1b1c1d1后的结果为【0xa1b1c1d1dc654321】,效果为改变了原数据的前半部分,对低位赋值的效果同理,这样的效果要如何编程实现?留下博主的一些拙见——
注意这里的数据类型都要定义成无符号的,否则会出现部分数据赋值错误的情况,主要原因是对于有符号32位整数强转为64位整数后的数据前面补的是f而不是0(即int32_t num = 0xabcd1234强转为int64_t的结果是0xffffffffabcd1234而不是0x00000000abcd1234,前者会导致计算数据错误)
uint64_t hidword(uint64_t num, uint32_t high_value){ //(num:预期赋值的64位有符号整数, high_value:预赋值的32位有符号整数即高位值)return (uint64_t)LODWORD(num) + ( (uint64_t)high_value << 32 ); //注意要先将其强制转换为64位后再左移32位,得到的结果与num的低位相加(即对高位赋值=旧低位+新高位)
}
uint64_t lodword(uint64_t num, uint32_t low_value){ //同理uint64_t h = (uint64_t)HIDWORD(num) << 32;uint64_t l = (uint64_t)low_value;return h + l; //(对低位赋值=旧高位+新低位,注意HIDWORD只是获取到高位的数据,还得用左移32位让该数据到真实的高位)
}下面是运行测试结果,这里输出的名字单纯为了对齐数据