随着云时代的到来,越来越多企业开始在公有云、私有云乃至 K8s 容器平台构建实时数据平台。云计算基础设施的革新,促使着数据仓库朝着云原生的方向发展。而用户日益复杂的业务负载和降本增效的需求,对于系统资源的精细化管理和成本效益等方面提出了更高的要求。
基于 Apache Doris 的现代化实时数据仓库 SelectDB
面向企业灵活弹性的系统需求,飞轮科技基于 Apache Doris 打造了现代化实时数据仓库 SelectDB,通过实时、统一、弹性、开放的核心能力,为企业提供高性价比、简单易用、安全稳定、低成本的实时大数据分析体验。其中,SelectDB Cloud 是为深度适配云基础设施、兼顾高效与弹性需求而设计的云原生版本,其延续了 Apache Doris 的极致性能,凭借其强大的数据分析能力、存算分离的云原生架构、多云一致的服务体验,助力企业在应对不断变化的业务需求与技术创新的同时,实现高效的数据处理与分析效能。
本文将深入探讨 SelectDB Cloud 的弹性能力,包括弹性计算资源、灵活缓存配置、按需存储以及混合计费策略等方面能力优势,帮助所有用户更好应对复杂工作负载和降本增效趋势所带来的挑战。
弹性计算资源:灵活应对查询业务负载波动
为了应对不断变化的工作负载,SelectDB Cloud 支持计算资源的弹性伸缩,可以根据工作负载的高低峰运行时段、作业执行规律,以配置不同规模的计算资源。例如在业务高峰期进行快速扩容以应对大规模并发查询需求,在低负载时期快速缩容以节省资源开销,在集群空置时还支持集群自动挂起资源以节省成本。
在弹性伸缩模式上,SelectDB Cloud 提供手动弹性伸缩和分时弹性伸缩两种模式,兼顾手动与自动化调节,灵活满足自定义算力的需求。SelectDB Cloud 也支持自动启停能力,在闲置时释放集群节省计算成本,在请求到达时拉起集群。
与此同时,SelectDB Cloud 支持多集群特性(类计算组、计算队列概念),多集群共享底层数据存储。在一份数据存储之上,用户可以根据不同业务负载特性,采用不同的集群。在提供计算资源物理隔离能力的同时,避免存储冗余。
借助 SelectDB Cloud 的弹性计算能力,企业能够实现分钟级别的 vCPU 快速伸缩,显著减少资源冗余与浪费,降低成本投入,确保 IT 资源精准适配业务发展,助力企业在竞争激烈的市场环境中实现更加敏捷、高效的数字化运营。
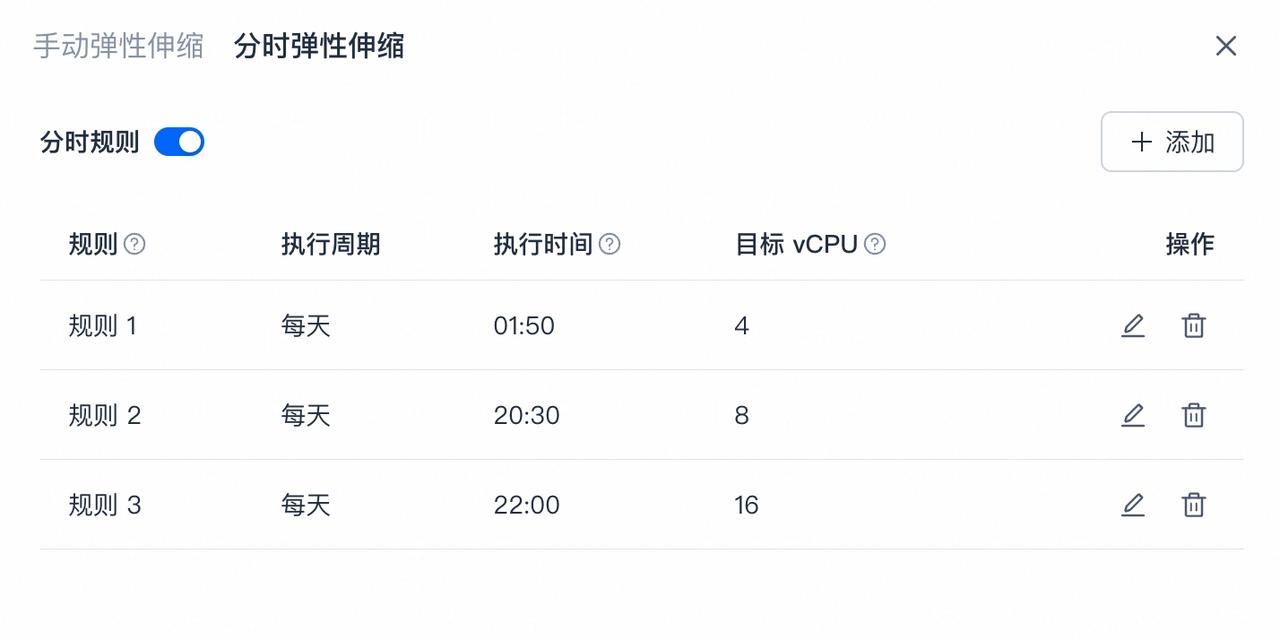
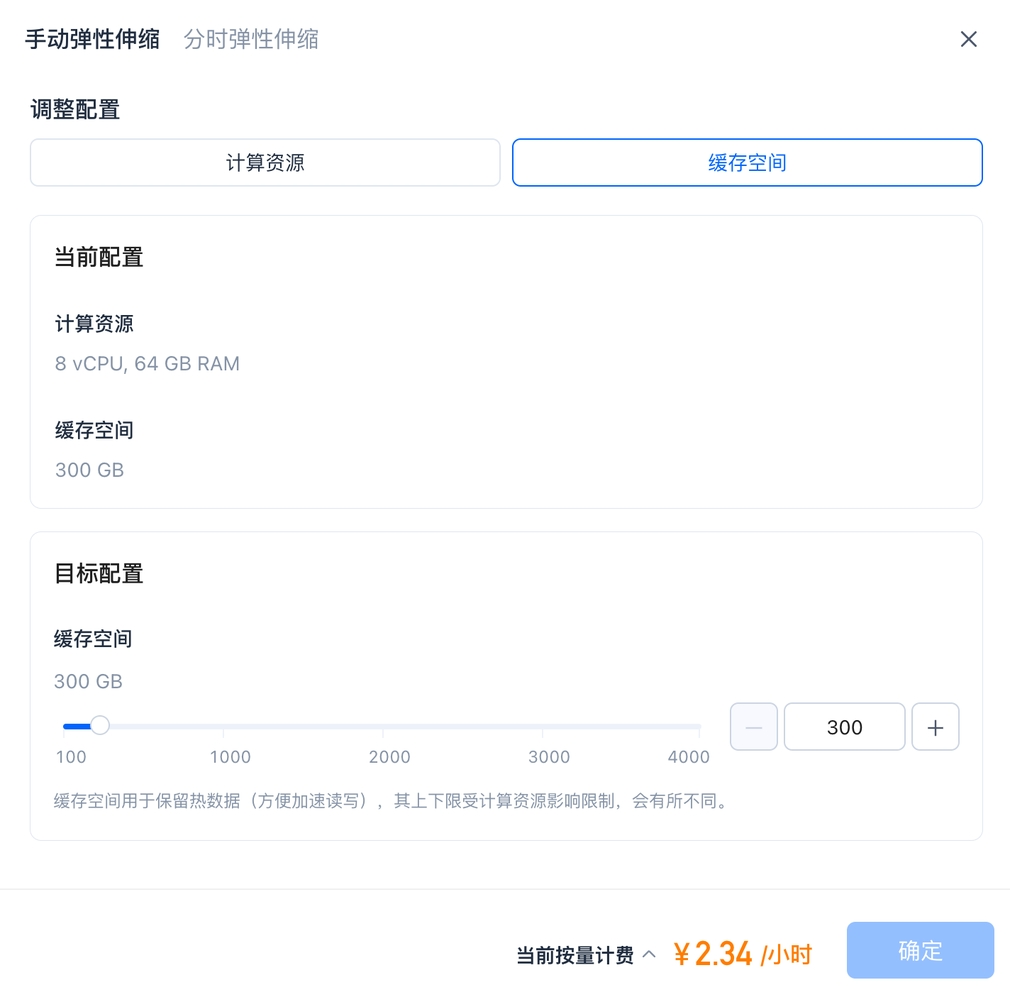
灵活配置缓存:加速数据查询分析
在云原生架构中,高速缓存扮演着至关重要的角色,可以大大提高数据查询和分析的速度。 云原生实时数仓 SelectDB Cloud 允许用户根据实际需求自定义缓存大小,从而实现更高效、更灵活的数据处理。
在 SelectDB Cloud 中,支持分钟级的缓存大小调整,用户可以在一定的缓存区间内,按照 100GB 的步长细粒度调整缓存,从而提高数据分析性能。
采用按需存储:经济可靠的存储管理
云原生实时数仓 SelectDB Cloud 采用存算分离架构,底层存储使用更加稳定可靠、低成本的对象存储服务,使得 SelectDB Cloud 具有如下优势:按实际存储使用量付费,不会因使用率低导致存储浪费;依赖对象存储本身的高可用保障,数仓层无需使用 3 副本;相较于云硬盘类存储,单位存储资源的成本降低一个量级。
基于对象存储,SelectDB Cloud 为企业提供了更加经济、可靠的解决方案。
混合计费策略:兼顾成本与弹性
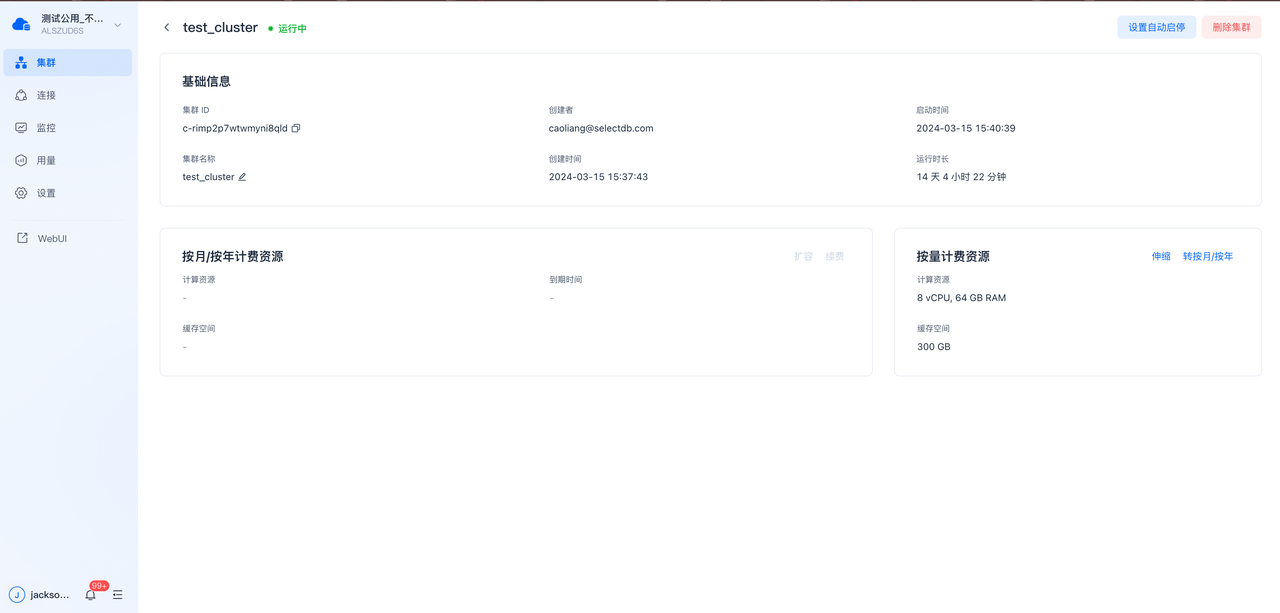
为了满足不同企业的需求和预算,云原生实时数仓 SelectDB Cloud 提供多种计费选项,包括包月计费和按量计费,以满足不同企业的需求和预算。支持单集群内混合包月资源和按量资源,包月资源降低成本,按量资源支撑业务波峰。
用户可以根据实际使用情况选择最合适的计费模式,实现成本的精准控制和优化。如下图所示:
结语
云原生实时数仓 SelectDB Cloud 面向云上基础设施进行深度适配,凭借出色的弹性能力,为企业提供了高效、灵活、经济的实时数据分析解决方案。无论是资源弹性伸缩、高效的缓存配置,还是按需存储、混合计费策略,都致力于帮助企业实现实时数据分析的最佳实践和成本优化。
后续 SelectDB Cloud 将实现更加 Serverless 化的能力,达到秒级弹性伸缩,为客户带来更加极致性价比的操作体验,进一步提升平台的灵活性和效率,满足企业不断变化的业务需求。