目录
一、Mysql索引
1、索引的概念
2、索引的特点
3、索引使用场景
4、Mysql有关索引的操作
(1)查询表具有的索引
(2)增加索引
(3)删除索引
5、索引实现原理
(1)B树
(2)B+树
(3)数据库选择B+树的原因
二、Mysql事务
1、事务的概念
2、事务的特点
3、事务的隔离等级
4、数据库操作事务
一、Mysql索引
1、索引的概念
索引是通过额外的数据结构,针对表里的数据进行重新组织,加快查询速度。
2、索引的特点
(1)加快查询的速度;
(2)索引自身也是一种数据结构,会占据存储空间;
(3)当对表进行增、删、改时,对应的索引也要进行修改。
3、索引使用场景
索引适用于表查询的频率高,但是增删改的频率低。
4、Mysql有关索引的操作
先创建一个学生表:
![]()
(1)查询表具有的索引
命令:show index from 表名

Mysql中的primary key、unique、foreign key都会默认自动生成索引。
一个表可以有多个索引,索引都是根据具体的列展开的。类似于新华字典中的拼音查询和部首查询
(2)增加索引
命令:create index 索引名称 on 表名(对应索引列)

需注意:如果表中数据较多时,创建索引要慎重,创建时会扫描整个表的数据,涉及大量的读取和写入操作,导致大量的硬盘IO,数据库极容易挂。
ps:如果表中已有数据,但想加入索引的话,可以重新建立一个相同的表,对应列加上索引,然后将表中数据复制到新表中。
(3)删除索引
命令:drop index 索引名称 on 表名

5、索引实现原理
索引是如何做到对应列名快速找到相应数据的???
数据库索引采用的数据结构是B+树,它的前身是B树。
(1)B树
①概念
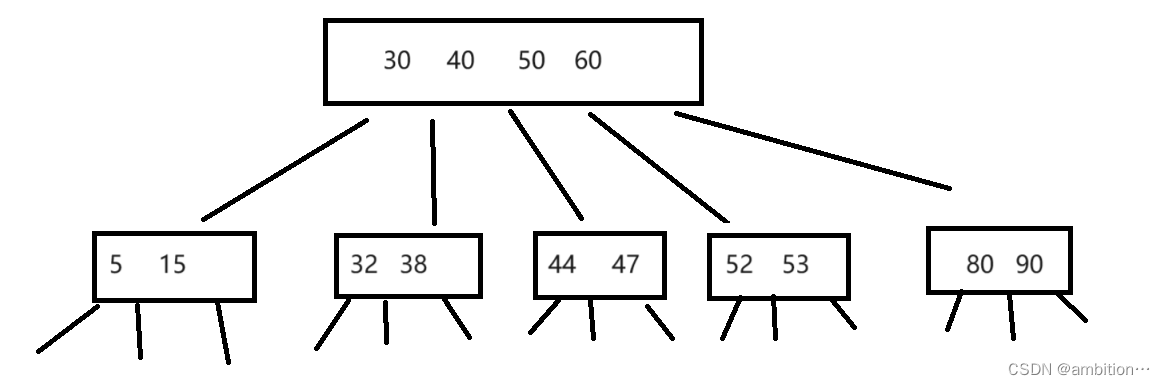
B树是一个n叉搜索树,与二叉搜索树的区别在于:二叉搜索树一个节点只有一个值,划分出了2个区间;而n叉搜索树,一个节点包含n个值,划分出了n+1个区间。若两棵树高度相同,n叉搜索树的元素更多。
例如:
②特点
数据的索引值和具体data都在每个节点上;任何一个关键字只会出现在一个节点中;每遍历一个节点,就需要进行一次硬盘IO;搜索可能会在非叶子节点结束,搜索次数具有不确定性。
(2)B+树
①概念
B+树是在B树上做了改进,B树上一个节点有n个值,会划分出n+1个区间;对于B+树,一个节点有n个值,会划分出n个区间。

②特点
每个节点的n个值中,存在一个最大值来自父节点;每个节点的值,都会在子树中重复出现;所有值最终都会出现在叶子节点,叶子节点之间使用链式结构相连;查询时间是稳定的,都需要从根结点查询到叶子结点,非叶子节点存储索引值即可,叶子节点存储索引值+数据。减少了硬盘IO次数,对于非叶子节点数据可以存储到内存中,在内存中比较即可。
(3)数据库选择B+树的原因
B+树的查询时间是稳定的,都需要从根结点到叶子结点,经过的硬盘IO次数是一样的;而B树查询时间不稳定,经过的硬盘IO次数也不一定,具有不确定性。
二、Mysql事务
1、事务的概念
对表执行的一批操作(多个操作),在同一个事务当中,这些操作要么全部成功,要么全部失败,不存在部分成功的情况。
2、事务的特点
(1)原子性
通过事务,把多个操作打包到一起,这些操作要么全部成功要么全部失败。
(2)一致性
一个事务必须使数据库从一个一致性状态(数据处于一种有意义的状态)转换到另一个一致性状态。
(3)隔离性
多个事务并发执行时,事务与事务之间应该要不受干扰。
(4)持久性
一个事务一旦提交,对数据库中数据的改变是永久性的,数据会持久化到硬盘。
3、事务的隔离等级
(1)读未提交---读写都未加锁
问题:事务1修改了某个数据,但是没有提交事务1;此时事务2读取到了同一个数据,此时事务2读到的数据是脏数据,还未修改成功(脏读+不可重复读+幻读)。
(2)读已提交---写操作加锁(写的时候不能读)
问题:事务1修改了某个数据,且提交了改事务;此时事务2读取到了正确事务;事务3也修改了某个数据,此时事务2再次读取时发现两次读到的数据内容不一样(不可重复读+幻读)。
(3)可重复读---读和写都加锁(数据库默认隔离等级)
问题:事务1修改了某个数据,且提交了改事务;此时事务2读取到了正确事务;事务3也插入了某个数据,此时事务2再次读取时发现两次读到的数据记录数不一样(幻读)。
(4)串行化
问题:数据最靠谱,但并行程度最低,效率最低。
4、数据库操作事务
(1)开启事务
命令: start transaction
(2)提交事务
命令:commit
(3)回滚事务
命令:rollback

提交后,数据库有插入的新数据。
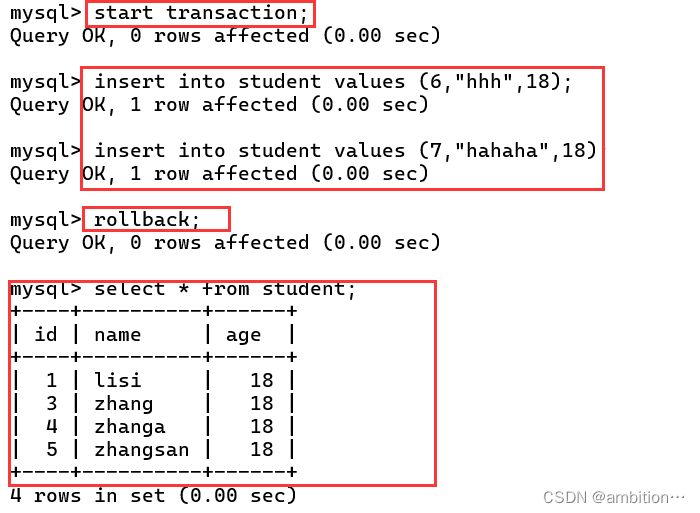
回滚后,数据库没有插入的新数据。