之前随手一写,没想到做预测的同学还挺多,但是之前那个效果并不好,于是在之前的基础上重新修改完善,到了现在这一步才感觉预测算是初步能应用。
上文地址:LSTM模型预测时间序列:根据历史销量数据预测商品未来销量:
https://blog.csdn.net/MacWx/article/details/134548578
有兴趣的话可以先拿上文练练手,再来看这篇。
(PS:着急的话可以直接看第3章代码实现部分)
————————————————————————————————————————————————————————
1、循环神经网络RNN
循环神经网络(Recurrent Neural Network, RNN)是一种人工神经网络,是基于序列数据(如语言、语音、时间序列)的递归性质而设计的,是一种反馈类型的神经网络,其结构包含环和自重复,因此被称为“循环”。特别设计用于处理序列数据,即那些具有时间顺序或者内在顺序依赖关系的数据类型,如逐字生成文本或预测时间序列数据(例如未来销量)。
在时间序列预测场景中,RNN因其独特的循环结构和记忆机制,能够有效地捕获数据的时间动态特性,从而成为一种强大的预测工具。以下是关于循环神经网络及其在时间序列预测中应用的详细解释:
1.1 RNN 基本原理
传统神经网络的结构比较简单:输入层 – 隐藏层 – 输出层。
RNN 跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。如下图所示:
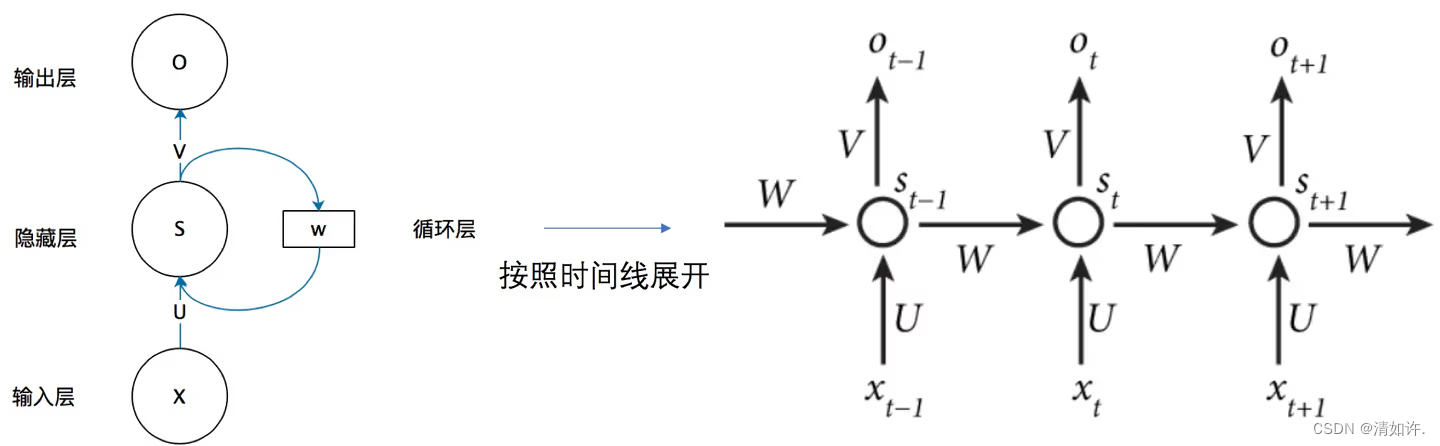

RNN原理部分具体请参考:史上最详细循环神经网络讲解(RNN/LSTM/GRU)https://zhuanlan.zhihu.com/p/123211148,感觉这篇文章写的不错
1.2 RNN在时间序列预测中的应用
循环神经网络在时间序列预测中的应用主要基于其对序列数据的建模能力和记忆能力。以下是 RNN 在时间序列预测中的优势:
- 处理不定长序列:RNN 能够处理不定长的时间序列,因此适用于各种长度的时间序列预测任务。
- 捕捉长期依赖关系:RNN 的循环结构使其能够捕捉序列数据中的长期依赖关系,因此能够更好地预测未来的数据点。
- 参数共享:RNN 在每个时间步都使用相同的参数,因此参数共享使得模型的训练更加高效,尤其是对于长序列而言。
- 动态适应性:RNN 能够根据序列中的不同时间步自动调整隐藏状态,从而动态适应序列数据的特征变化。
- 端到端训练:RNN 可以直接从原始数据中学习特征表示,而不需要手工设计特征,从而实现端到端的训练。
- 多种结构变体:RNN 的结构可以灵活变化,例如长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)等变体,可以进一步提升模型的性能。
循环神经网络凭借其循环结构、记忆机制以及对非线性关系的学习能力,非常适合处理时间序列预测任务。虽然存在一些挑战,但通过使用变种如LSTM和GRU,以及先进的优化技巧和模型结构改进,RNN及其衍生模型在许多实际应用中展现出强大的预测性能。
2、销量预测训练步骤
以下列出了销量预测所主要需要的一些步骤和方法,后面会写具体代码实现
2.1 数据处理与预处理:
-
数据读取:使用pandas库从CSV文件中读取数据,通过pd.read_csv()函数实现,支持GBK编码和指定分隔符。
-
数据筛选:检查数据量是否达到阈值
cfg.n_min_samples,若不足则跳过该数据集,不进行建模。 -
特征缩放:使用
sklearn.preprocessing.MinMaxScaler对销售数据(df['amount'])进行极差标准化(归一化),以减小数据尺度差异并稳定训练过程。 -
数据准备:调用
creat_dataset()函数生成适合模型训练的数据集。根据time_step(连续时间步长)和n_next(预测周期数),将原始数据转化为形如[[x1, x2, x3, …, x_time_step], [y]]的序列-标签对,其中x是过去time_step个时间点的数据,y是未来n_next个时间点的数据。
2.2 模型构建与配置:
-
模型定义:自定义Net类作为预测模型,该类应包含循环神经网络结构(如LSTM、GRU等)。由于您没有提供Net类的具体实现,我假设它已经正确定义了RNN模型。
-
设备选择:使用torch.device指定计算设备,根据GPU可用性选择CPU或GPU(CUDA)进行训练。
-
数据封装:将预处理后的数据转化为
torch.Tensor,并使用TensorDataset和DataLoader构建数据加载器,便于在训练过程中批量提取数据及自动进行批次划分。
2.3 训练流程与优化策略:
-
模型初始化:创建Net实例,并根据是否存在预训练模型决定是否加载预训练权重。预训练模型路径存储在
path_pre_model中。 -
超参数设置:指定学习率
(lr)、最大训练轮数(epochs)、优化器(Adam)、损失函数(均方误差MSE)。 -
训练循环:
-
- 前向传播与损失计算:通过模型的
forward()方法计算预测值,使用nn.MSELoss()计算预测值与真实标签之间的均方误差。
- 前向传播与损失计算:通过模型的
-
- 反向传播与参数更新:执行反向传播以计算梯度,使用optimizer.step()更新模型参数,并使用
optimizer.zero_grad()清空梯度,准备下一轮迭代。
- 反向传播与参数更新:执行反向传播以计算梯度,使用optimizer.step()更新模型参数,并使用
-
- 动态调整学习率:根据设定的周期数
epoch_step_adujst_lr,每隔一定轮数按系数coef_lr_attenuation降低学习率,以促进模型收敛。
- 动态调整学习率:根据设定的周期数
-
- 早停条件:根据最近若干轮
(loss_window_terminate)的损失均值判断是否满足提前停止训练的条件(如损失低于某个阈值min_loss)。
- 早停条件:根据最近若干轮
-
模型保存:训练完成后,将模型状态(包括结构和权重)分别保存到预训练模型目录path_pre_model和当前模型目录
path_model中。
2.4 多任务并行训练:
- 多线程训练:通过
multiprocessing.Pool实现并行训练多个模型,每个模型对应不同的预测周期数(1至19)。启用并行训练由配置项cfg.is_parallel_training控制。
2.5 日志记录与性能监控:
-
日志输出:使用logger记录关键信息,如模型训练终止条件、模型保存情况等。
-
训练时间统计:计算训练总耗时,并使用
seconds2hours函数将其转换为小时、分钟、秒的格式进行显示。
3 代码实现
主要过程如下:
1、首先读取数据集csv文件,读取每天每个地区的销量数据,整理为按照地区分类的销量数据csv文件,并且将每天的销量数据合并为以周(星期)为单位的销量汇总数据。以下代码实现都是按照周进行预测的,比如说可以预测未来1周,2周,3周…等某地的销量数据。
2、数据整理好之后,执行train.py文件开始训练模型,模型生成的文件会保存至models文件夹下。
3、待训练完成之后执行predict.py文件,修改文件中的开始日期进行预测未来几周的销量数据。
4、观察模型训练效果,如果结构不理想,调整config.py参数,比如调大模型迭代次数等,重新训练模型
5、待模型符合预期效果之后,执行predictTest.py,将模型预测的结果按周和地区导出到Excel中,目标完成。模型部署的话可以执行解决
3.1 模型训练文件:train.py
以下代码就是上文第2章节的具体代码实现,补充有详细注释,可以结合第二部分说明具体理解代码意图。
如果有GPU的话,在第71行打开这行注释,并且注释掉72行注释,使用GPU进行训练
#!/usr/bin/env python
# coding: utf-8#导入相应的库
import os
import time
import config as cfg
import joblib
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import TensorDataset, DataLoader
from common import logger,Net,creat_dataset
from multiprocessing.pool import Pooldef train(n_next): #n_next: 预测N+n_next周期的数据time_step=cfg.time_step #连续time_step个数据,在Net类中,creat_dataset函数中,train函数中都要使用root = os.path.abspath(os.path.dirname(__file__)) + '/'path_csv=root+'csv_for_training/'file_list=os.listdir(path_csv)# 创建保存预训练min_max_scaler的模型文件夹path_pre_mms = root + 'pre_train/min_max_scalers/next_' + str(n_next).zfill(2) + '/'if not os.path.exists(path_pre_mms):os.makedirs(path_pre_mms)# 创建保存预训练预测模型的文件夹path_pre_model = root + 'pre_train/models/next_' + str(n_next).zfill(2) + '/'if not os.path.exists(path_pre_model):os.makedirs(path_pre_model)#创建保存当次min_max_scaler的模型文件夹path_mms=root+'models/min_max_scalers/next_'+str(n_next).zfill(2)+'/'if not os.path.exists(path_mms):os.makedirs(path_mms)#remove_files(path_mms)#创建保存当次预测模型的文件夹path_model=root+'models/models/next_'+str(n_next).zfill(2)+'/'if not os.path.exists(path_model):os.makedirs(path_model)#remove_files(path_model)model_list=os.listdir(path_pre_model) #如果已有预训练模型,获取模型列表#创建保存损失曲线的文件夹path_loss=root+'loss_fig/next_'+str(n_next).zfill(2)+'/'if not os.path.exists(path_loss):os.makedirs(path_loss)print('模型批量训练开始...')for idx,file in enumerate(file_list):print('-'*70)print('{} next_{} 第{}/{} 模型 {} 训练中...'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),n_next,idx+1,len(file_list),file.split('.')[0]))full_name=path_csv+file# print(full_name)#观察统计报表数据 gbk, utf-8, ANSIdf = pd.read_csv(full_name,sep=',',encoding='gbk',engine='python')if len(df['amount'])<cfg.n_min_samples: #数据量小,不建模continue#销售数据极差标准化min_max_scaler = MinMaxScaler()min_max_scaler = min_max_scaler.fit(df['amount'].values.reshape(-1,1))joblib.dump(min_max_scaler, path_pre_mms + file.split('.')[0] + '.m') # 保存模型joblib.dump(min_max_scaler,path_mms+file.split('.')[0]+'.m')#保存模型X=min_max_scaler.transform(df['amount'].values.reshape(-1,1))#生成类似[[x1,x2,x3,x4,x5],[x6]]的数据集dataX, dataY = creat_dataset(X,time_step,n_next=n_next)#print('dataX',dataX.shape,'dataY',dataY.shape)#生成训练数据集# cuda# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")device = torch.device('cpu')print('device',device)# 转化成 tensor->(batch_size, seq_len, feature_size)X = torch.tensor(dataX.reshape(-1, time_step, 1), dtype=torch.float).to(device)Y = torch.tensor(dataY.reshape(-1, 1, 1), dtype=torch.float).to(device)# 划分数据split_ratio = 1 # 0.8len_train = int(X.shape[0] * split_ratio)X_train, Y_train = X[:len_train, :, :], Y[:len_train, :, :]# print(x_train.shape,y_train.shape)# 构建迭代器batch_size = 10ds = TensorDataset(X, Y)dl = DataLoader(ds, batch_size=batch_size, num_workers=0)ds_train = TensorDataset(X_train, Y_train)dl_train = DataLoader(ds_train, batch_size=batch_size, num_workers=0)# 自定义训练方式# model = Net().to(device)# loss_function = nn.MSELoss()# optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)mynet = Net().to(device)if file.split('.')[0]+'.pth' in model_list: #如果已有预训练模型print('加载预训练模型继续训练...')full_model_name=path_pre_model+file.split('.')[0]+'.pth'# mynet=torch.load(full_model_name).to(device) # 加载预测模型的结构以及参数mynet = torch.load(full_model_name) # 加载预测模型的结构以及参数#参数寻优,计算损失函数lr=cfg.learning_rate0optimizer = torch.optim.Adam(mynet.parameters(),lr = lr)loss_func = nn.MSELoss()#训练模型losses=[]# for i in range(200):lr=cfg.learning_rate0epochs=cfg.n_max_train_epochesfor epoch in range(1, epochs + 1):list_loss = []for features, labels in dl_train:predictions = mynet.forward(features)loss_func = nn.MSELoss()loss = loss_func(predictions, labels)# 反向传播求梯度loss.backward()# 参数更新optimizer.step()optimizer.zero_grad()list_loss.append(loss.item())loss = np.mean(np.array(list_loss))#losses.append(loss)if epoch % 500 == 0:print('epoch={} | loss={:.6f} '.format(epoch, loss))# if (epoch+1)%500==0:# print('Epoch:{}, Loss:{:.5f}'.format(epoch+1, loss.item()))losses.append(loss.item())#print(losses)epoch+=1if epoch%cfg.epoch_step_adujst_lr==0: #动态修改学习率lr *= cfg.coef_lr_attenuationprint('Current learning rate:{:.6f}'.format(lr))optimizer = torch.optim.Adam(mynet.parameters(), lr=lr)#if epoch>50000 or loss<=0.0002: #迭代终止条件if np.median(losses[-cfg.loss_window_terminate:]) <= cfg.min_loss: # 迭代终止条件info='训练终止时的迭代次数为:{},loss为:{:.5f}.'.format(epoch+1,loss)print(info)logger.info(info)breaktorch.save(mynet, path_pre_model + file.split('.')[0] + '.pth')torch.save(mynet, path_model+file.split('.')[0]+'.pth')info=path_model+file.split('.')[0]+'.pth 模型文件已保存!'print(info)logger.info(info)print('next_',n_next,'模型全部训练完毕!')def seconds2hours(s): #将秒转换为小时、分钟、秒h = s // 3600 #小时数m = (s - h * 3600) // 60s = s - h * 3600 - m * 60return h,m,sdef train_model():start_time = time.time()# 串行逐次训练预测模型if cfg.is_parallel_training:# 并行多线程训练模型,似乎不同线程间有干扰pool = Pool()pool.map(train, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18])# train_threads=[]# for i in range(1,13):# train_threads.append(Thread(target=train,args=(i,)))# for thread in train_threads:# thread.start()# for thread in train_threads:# thread.join()else: # 串行训练 13 改为 19for i in range(1, 19):train(n_next=i)end_time = time.time()h, m, s = seconds2hours(end_time - start_time)print('*' * 60)print('模型训练总用时:{:.0f}小时{:.0f}分{:.0f}秒'.format(h, m, s))print('*' * 60)if __name__ == '__main__':train_model()3.2 模型配置文件:config.py
time_step=24 #从时间序列创建N,N+X的特征、目标数据集的连续样本数量N. 如修改此数据,需删除全部预训练模型文件。
n_min_samples=60 #保存为周报表的最小周记录数量
n_max_train_epoches=10000 #模型训练的最大迭代次数
min_loss=0.001 #终止迭代的最小损失值
loss_window_terminate=10 #终止模型训练迭代的loss采用窗口,要求连续多个loss小于min_loss才终止迭代
learning_rate0=0.01 #训练模型的初始学习率
coef_lr_attenuation=0.6 #学习率衰减系数
epoch_step_adujst_lr=1000 #调整学习率的epoch步长
is_parallel_training=True #并行多线程训练模型
is_draw_loss=False #训练模型时是否保存损失曲线,默认为否。如果保存损失曲线,将消耗较大的内存资源。
n_linear_neuron=6 #网络线性层的神经元数量
n_lstm=3 #lstm单元串联的数量
3.3 模型预测文件:predict.py
以下代码是根据上文训练出来的模型文件,进行销量预测
#!/usr/bin/env python
# coding: utf-8
import datetime
import time
import joblib
import numpy as np
import pandas as pd
import torch
import os
import config as cfg
from torch.autograd import Variable# 获取当前日期 上周日的日期
def get_last_sunday():# 获取现在时间the_day = (datetime.datetime.today() - datetime.timedelta(days=time.localtime().tm_wday + 1)).strftime("%Y-%m-%d")the_day = '2023-08-06'# the_day = '2023-09-10'print("the_day==="+the_day)return the_daydef predict(n_next, region, product, day, time_step=cfg.time_step):root = os.path.abspath(os.path.dirname(__file__)) + '/'#min_max_scaler列表path_mms =root + 'models/min_max_scalers/next_' + str(n_next).zfill(2) + '/'#销售量预测模型列表path_model= root + 'models/models/next_' +str(n_next).zfill(2)+'/'#模型训练数据文件列表path_csv = root + 'csv_for_training/'file_name = region + '_item_' + str(product)full_mms_name = path_mms + file_name + '.m'full_model_name = path_model + file_name + '.pth'full_csv_name = path_csv + file_name + '.csv'model_name = file_name + '.pth'model_list = os.listdir(path_model)# 可先判断模型是否存在if not (model_name in model_list):print('注意预测模型文件', full_model_name, '缺失!', file_name, '跳过,不预测!')return# 加载预测模型的结构以及参数model = torch.load(full_model_name)# 加载极差标准化模型min_max_scaler = joblib.load(full_mms_name)# 加载原有数据集df = pd.read_csv(full_csv_name, sep=',', encoding='gbk', engine='python')X = min_max_scaler.transform(df['amount'].values.reshape(-1, 1))# 预测日期大于训练数据最大日期,取已有训练的最大日期作为预测输入# 预测日期小于训练数据最小日期,数据补0作为输入# 预测日期,训练数据中无该日期,选取最近的小于该日期的数据作为输入# 获取给定日期,往前24个数据,用于模型输入index = get_index(df, day)# print(index)#进一步判断日期超出范围,无给定日期 的情况#取其24周内容。不足按0补充if index >= time_step - 1:current = np.array(X[index+1 - time_step : index+1])else:a = np.zeros((time_step - index - 1, 1))b = np.array(X[0: index + 1])current = np.concatenate((a, b), axis=0)# 根据当前的前time_step个数据,预测未来current = current.reshape(-1, time_step, 1)current = torch.from_numpy(current)current = Variable(current).type(torch.FloatTensor)# 预测pred_future = model(current)pred_future = pred_future.detach().numpy()pred_future = min_max_scaler.inverse_transform(pred_future[:, -1, 0:1])pred_future[np.where(pred_future[:, 0] < 0)] = 0 # 预测为负值的修改为0result = pred_future[0][0]print(result)return result"""
传入日期比最小日期还小,赋值0
传入日期比最大日期还大,赋值最大日期索引
传入日期在 最小日期 与 最大日期之间,赋值与之相同或小于该日期的索引
"""
def get_index(df, day):index = 0max_day = df.at[len(df)-1 , 'date']min_day = df.at[0, 'date']if (day<=max_day and day>=min_day):for i in range(len(df) - 1, 1, -1):if day >= df.at[i , 'date']:index = ibreakelif day < min_day:index = 0else:index = len(df) - 1return indexdef output_tianjin(region, product):data_list = [](num7, num15, num30, num45, num60, num90,week1, week2, week3, week4, week5, week6, week7, week8, week9, week10, week11, week12,week13, week14, week15, week16, week17, week18) = get_day_predict(region, product)data_line = (num7, num15, num30, num45, num60, num90, week1, week2,week3, week4, week5, week6, week7, week8, week9, week10, week11, week12, week13, week14, week15, week16, week17,week18)data_list.append(data_line)def get_day_predict(region, product):data = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]day = get_last_sunday()# 预测周数for i in range(1, 13):result = predict(i, region, product, day)if result is not None:data[i - 1] = resultreturn int(data[0]), int(data[1]), int(data[2]), int(data[3]), int(data[4]), int(data[5]), int(data[6]), int(data[7]), int(data[8]), int(data[9]), int(data[10]), int(data[11])if __name__ == '__main__':# get_day_predict( '郑州', 'XX牌雨伞')get_day_predict( 'A', 'GOODS')4、结果展示
以上就是代码预测部分的代码实现了,到这里应该可以算是一个完整的项目了。模型训练过程如下图所示:
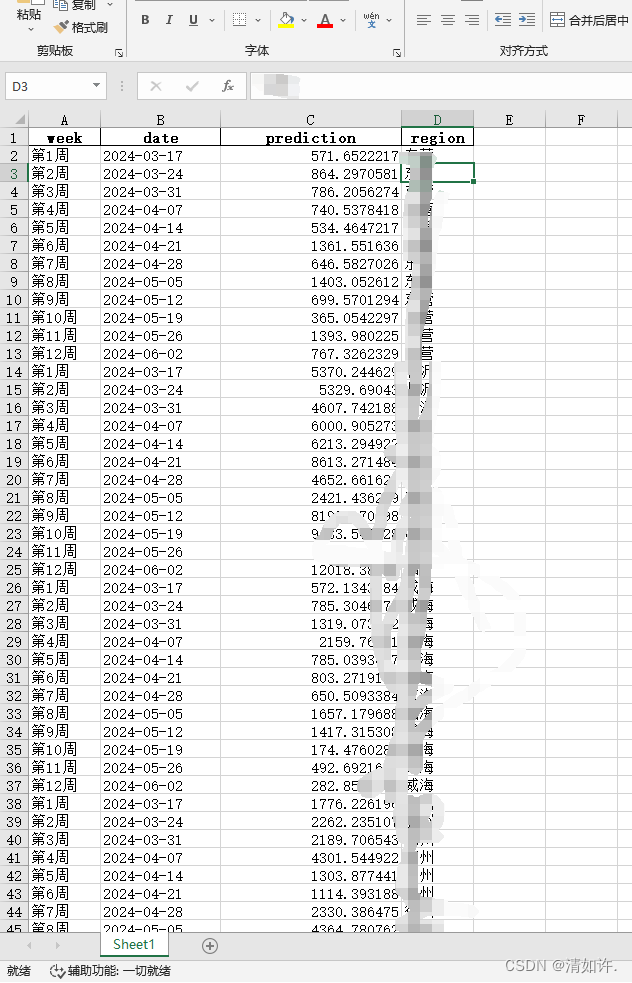
预测结果如下图所示:
代码下载
完整代码和数据集下载地址:https://download.csdn.net/download/MacWx/89226062



