题目: Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
作者:Kexin Zhang, Qingsong Wen(文青松), Chaoli Zhang, Rongyao Cai, Ming Jin(金明), Yong Liu(刘勇), James Zhang, Yuxuan Liang(梁宇轩), Guansong Pang(庞观松), Dongjin Song(宋东进), Shirui Pan(潘世瑞)
机构:浙江大学,松鼠AI,浙江师范大学,莫纳什大学(Monash),蚂蚁集团,香港科技大学(广州),新加坡管理大学(SMU),康涅狄格大学(Connecticut),格里菲斯大学(Griffith)
arXiv网址:https://arxiv.org/abs/2404.01340
IEEE网址:https://ieeexplore.ieee.org/abstract/document/10496248/
Cool Paper:https://papers.cool/arxiv/2404.01340
项目地址:https://github.com/qingsongedu/Awesome-SSL4TS
关键词:自监督学习,时间序列分析。
TL, DR: 本文全面回顾了自监督学习(SSL)在时间序列分析中的最新进展,提出了一个包含生成式、对比式和对抗式三种主要方法的新分类体系,并对这些方法的关键思想、主要框架、优缺点进行了深入分析。此外,文章还总结了在时间序列预测、分类、异常检测和聚类任务中常用的数据集,并探讨了时间序列SSL未来的研究方向。


该综述23年6月上线arXiv,24年4月初被接受,目前已经有32个引用。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
摘要
自监督学习(SSL)最近在各种时间序列任务上取得了令人印象深刻的表现。 SSL最突出的优点是减少了对标记数据的依赖。 基于预训练和微调策略,即使少量的标记数据也能实现高性能。 与许多已发表的关于计算机视觉和自然语言处理的自监督综述相比,仍然缺少针对时间序列 SSL 的全面综述。 为了填补这一空白,我们在本文中回顾了当前最先进的时间序列数据 SSL 方法。 为此,本文首先全面回顾与 SSL 和时间序列相关的现有综述,然后从基于生成、基于对比和基于对抗性三个角度进行总结,为现有时间序列 SSL 方法提供新的分类。 这些方法进一步分为十个子类别,并对它们的关键直觉、主要框架、优点和缺点进
行了详细的回顾和讨论。 为了方便时间序列 SSL 方法的实验和验证,还总结了时间序列预测、分类、异常检测和聚类任务中常用的数据集。 最后,提出了 SSL 时间序列分析的未来方向。
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在时间序列数据分析中应用自监督学习(Self-Supervised Learning, SSL)以减少对标记数据的依赖。时间序列数据在许多实际场景中非常普遍,例如人类活动识别、工业故障诊断、智能建筑管理和医疗保健等。然而,获取大量标记数据往往是耗时且困难的。自监督学习通过使用预训练和微调策略,即使只有少量标记数据也能达到高性能,从而减少了对标记数据的依赖。
论文的主要贡献包括:
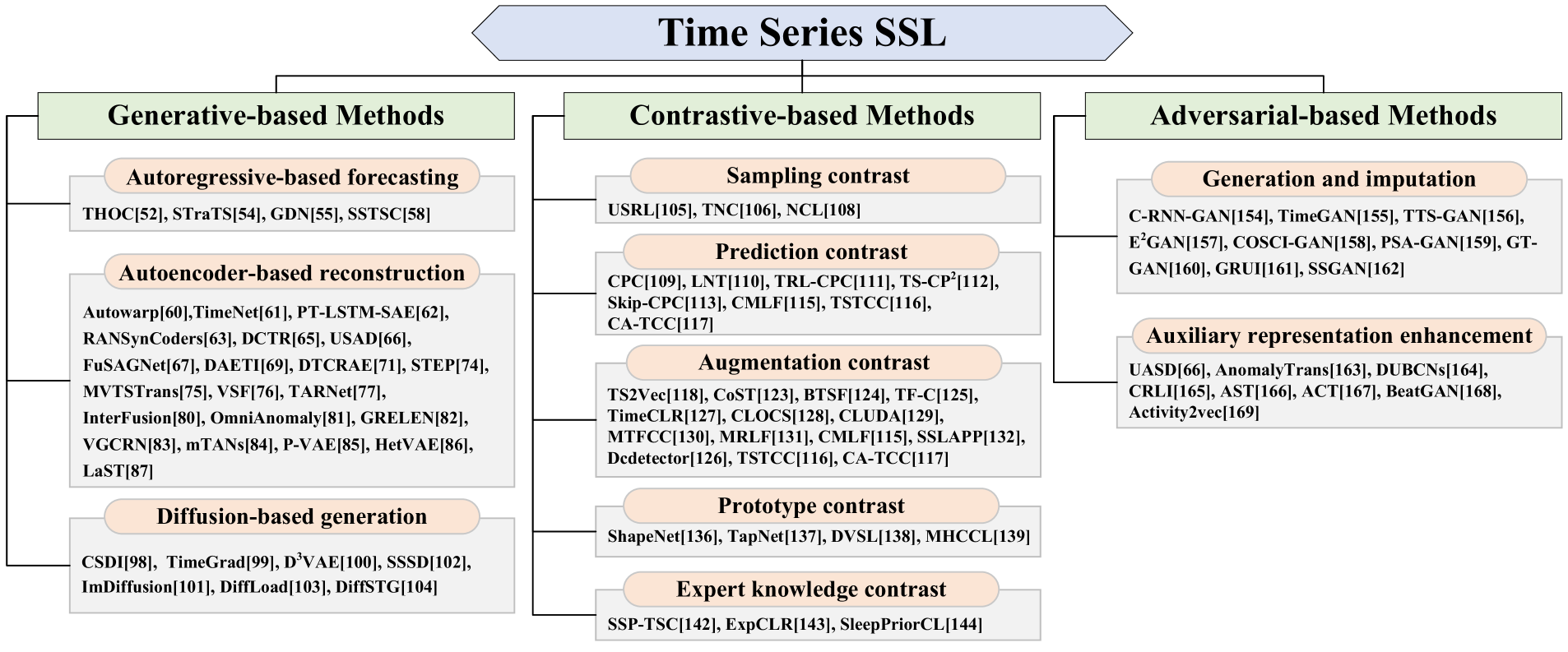
- 提出了一个新的分类法,将现有的时间序列SSL方法分为三类:基于生成的(Generative-based)、基于对比的(Contrastive-based)和基于对抗的(Adversarial-based)。
- 对每个子类别进行了详细回顾和讨论,包括它们的关键直觉、主要框架、优缺点。
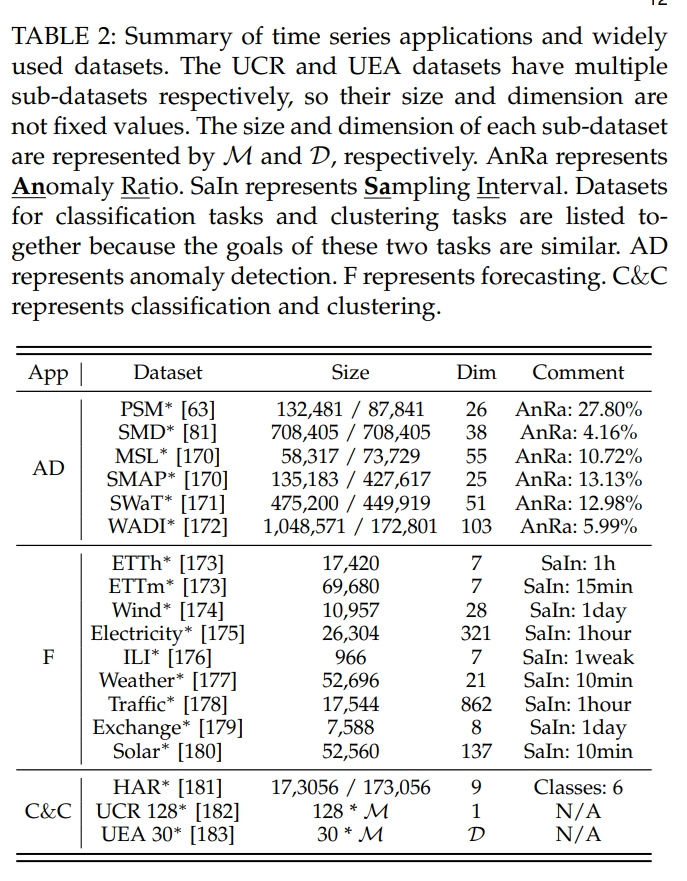
- 总结了在时间序列预测、分类、异常检测和聚类任务中常用的数据集。
- 讨论了时间序列SSL的未来方向,包括数据增强的选择与组合、正负样本的选择、时间序列SSL的归纳偏差、理论分析、对抗性攻击和稳健性分析、时间序列领域适应、预训练和大型模型、协作系统中的时间序列SSL以及时间序列SSL的基准评估等。
通过这项工作,作者希望能够激发对时间序列SSL领域的进一步研究兴趣。
Q: 有哪些相关研究?
A: 这篇论文提到了与时间序列自监督学习(SSL)相关的多个研究领域和具体工作,可以概括如下:
- 自监督学习(SSL): 论文提到了在计算机视觉(CV)和自然语言处理(NLP)领域中SSL的成功应用,并探讨了将SSL扩展到时间序列数据的潜力和挑战。
- 时间序列分析: 论文讨论了时间序列数据的独特属性,如季节性、趋势和频域信息,并指出直接将为图像或语言数据设计的SSL技术应用到时间序列数据上通常不可行。
- 生成模型: 论文中提到了使用生成模型进行时间序列分析的方法,包括自回归模型、自编码器重建和扩散模型。
- 对比学习: 论文探讨了基于对比的学习策略,包括通过数据增强或上下文采样生成正负样本的方法。
- 对抗生成网络(GANs): 论文中提到了使用GANs进行时间序列数据的生成和插补,以及作为辅助表示增强的策略。
- 时间序列数据集: 论文总结了在时间序列预测、分类、异常检测和聚类任务中常用的数据集。
- 时间序列SSL的未来方向: 论文提出了多个未来研究方向,包括数据增强的选择与组合、正负样本的选择、时间序列SSL的归纳偏差、理论分析、对抗性攻击和稳健性分析、时间序列领域适应、预训练和大型模型、协作系统中的时间序列SSL以及时间序列SSL的基准评估等。
具体到文献,论文中引用了大量的相关工作,包括但不限于以下几篇:
- [17] A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, and F. Makedon, “A survey on contrastive self-supervised learning,” Technologies, vol. 9, no. 1, 2021.
- [18] L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 4037–4058, 2021.
- [19] E. Eldele, M. Ragab, Z. Chen, M. Wu, C.-K. Kwoh, and X. Li, “Label-efficient time series representation learning: A review,” 2023.
- [20] S. Deldari, H. Xue, A. Saeed, J. He, D. V. Smith, and F. D. Salim, “Beyond just vision: A review on self-supervised representation learning on multimodal and temporal data,” CoRR, vol. abs/2206.02353, 2022.
这些相关工作为论文提供了理论基础和方法论支持,并且论文在这些研究的基础上进行了扩展和深化,特别是在时间序列数据的自监督学习方面。

Q: 论文如何解决这个问题?
A: 论文通过以下几个步骤来解决时间序列数据分析中的自监督学习问题:
- 新分类法提出:论文首先提出了一个新的分类法,将现有的时间序列自监督学习(SSL)方法分为三个主要类别:基于生成的(Generative-based)、基于对比的(Contrastive-based)和基于对抗的(Adversarial-based)。这种分类有助于系统地理解和比较不同的SSL方法。
- 详细回顾和讨论:对于每个SSL子类别,论文详细回顾了相关方法,并讨论了它们的关键直觉、主要框架、优势和劣势。这为选择合适的SSL方法提供了理论基础和实践指导。
- 数据集总结:论文总结了在时间序列预测、分类、异常检测和聚类任务中常用的数据集。这有助于研究者在实验和验证SSL方法时有一个共同的基准。
- 未来方向探讨:论文讨论了时间序列SSL的未来研究方向,包括数据增强的选择与组合、正负样本的选择、时间序列SSL的归纳偏差、理论分析、对抗性攻击和稳健性分析、时间序列领域适应、预训练和大型模型、协作系统中的时间序列SSL以及时间序列SSL的基准评估等。这些方向为未来的研究提供了可能的探索路径。
- 实验和验证:虽然论文没有提供具体的实验结果,但它为如何进行实验和验证SSL方法提供了指导。研究者可以根据论文中的分类和讨论设计实验,验证不同SSL方法在时间序列数据上的有效性。
通过这些步骤,论文旨在为时间序列数据分析中的自监督学习提供一个全面的框架,并推动该领域的研究进展。
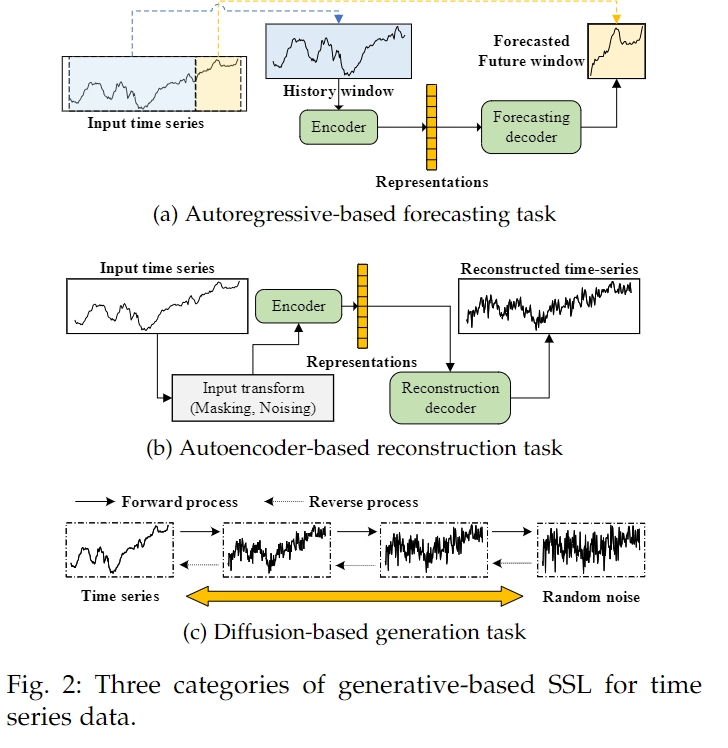
- 自回归预测(Autoregressive-based forecasting):使用过去的时间序列数据来预测未来的值。
- 自编码器重建(Autoencoder-based reconstruction):通过编码器和解码器重建输入的时间序列数据。
- 扩散生成(Diffusion-based generation):使用逐步添加噪声的过程来生成新的数据样本。

- 采样对比(Sampling contrast):通过随机采样来构建正负样本对。
- 预测对比(Prediction contrast):使用预测任务来构建正负样本对。
- 增强对比(Augmentation contrast):通过数据增强技术来生成不同的数据视图。
- 原型对比(Prototype contrast):使用原型(如聚类中心)来构建样本对。
- 专家知识对比(Expert knowledge contrast):利用领域知识来指导样本对的构建。
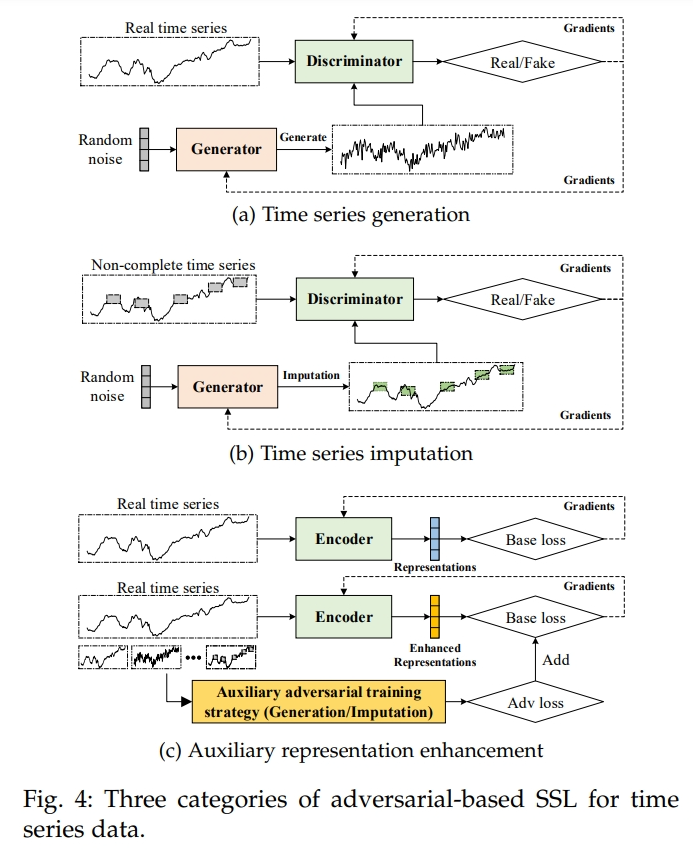
- 时间序列生成和插补(Time series generation and imputation):使用GANs生成新的时间序列或填补缺失值。
- 辅助表示增强(Auxiliary representation enhancement):将对抗信号作为正则化项,以提高模型的稳健性。
Q: 论文做了哪些实验?
A: 论文本身并没有进行特定的实验来验证提出的分类法或方法,而是提供了一个全面的文献回顾和分析。具体来说,论文的主要贡献集中在以下几个方面:
- 提出新的分类法:论文提出了一个新的分类法,将时间序列自监督学习方法分为生成基(Generative-based)、对比基(Contrastive-based)和对抗基(Adversarial-based)三个主要类别,并进一步细分为十个子类别。
- 详细回顾和讨论:对于每个子类别,论文详细回顾了相关的方法,并讨论了它们的关键直觉、主要框架、优势和劣势。
- 数据集总结:论文总结了在时间序列预测、分类、异常检测和聚类任务中常用的数据集,为实验和验证SSL方法提供了基准。
- 未来方向的讨论:论文讨论了时间序列SSL的未来研究方向,为未来的研究提供了可能的探索路径。
尽管论文没有进行实验验证,但它为如何进行实验和验证SSL方法提供了指导。研究者可以根据论文中的分类和讨论设计实验,验证不同SSL方法在时间序列数据上的有效性。此外,论文中引用了大量的相关工作,这些工作可能包含了使用类似方法的实验结果和验证。
如果需要查看具体的实验结果和验证,可以参考论文中引用的相关文献,这些文献可能提供了具体的实验设置、结果和分析。
Q: 有什么可以进一步探索的点?
A: 论文提出了时间序列自监督学习(SSL)的多个未来研究方向,可以进一步探索的点包括:
- 数据增强的选择与组合:探索不同的数据增强方法对时间序列SSL性能的影响,并研究如何选择或组合这些方法以获得最佳效果。
- 正负样本的选择:研究如何更准确地选择正负样本对,以提高对比学习等SSL方法的性能。
- 时间序列SSL的归纳偏差:分析时间序列数据的特性,探索如何引入归纳偏差来指导模型学习,从而提高SSL的效果。
- 理论分析:对SSL方法进行理论分析,包括理解其学习机制、优化目标和表示能力等。
- 对抗性攻击和稳健性分析:研究时间序列模型在对抗性攻击下的脆弱性,并探索提高模型稳健性的策略。
- 时间序列领域适应:探索如何将在一个领域预训练的模型有效地迁移到另一个领域,以及如何利用领域知识来提高SSL的性能。
- 预训练和大型模型:研究预训练模型在大规模时间序列数据集上的表现,以及如何利用大型模型来提高SSL的性能。
- 协作系统中的时间序列SSL:探索在分布式系统或协作系统中部署时间序列SSL的方法,以及如何保护用户隐私。
- 时间序列SSL的基准评估:建立和完善时间序列SSL的评估基准,包括标准化的数据集、评估协议和比较分析。
- 混合SSL策略:研究如何结合多种SSL策略来提高时间序列分析的性能。
这些方向不仅涉及方法论的改进,也包括对现有理论的深化和新应用领域的探索。研究者可以根据具体的研究兴趣和实际问题选择适合的研究方向进行深入探索。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
- 背景与动机:论文讨论了自监督学习(SSL)在时间序列分析中的重要性,特别是在减少对标记数据依赖方面的优势。时间序列数据在多个领域中普遍存在,但获取标记数据往往是困难和耗时的。
- 新分类法:论文提出了一个新的分类法,将时间序列SSL方法分为三个主要类别:基于生成的(Generative-based)、基于对比的(Contrastive-based)和基于对抗的(Adversarial-based)方法,并进一步细分为十个子类别。
- 详细回顾:对于每个SSL子类别,论文提供了详细的回顾和讨论,包括它们的关键直觉、主要框架、优势和劣势。
- 数据集总结:论文总结了在时间序列预测、分类、异常检测和聚类任务中常用的数据集,为实验和验证SSL方法提供了基准。
- 未来方向:论文讨论了时间序列SSL的未来研究方向,包括数据增强的选择与组合、正负样本的选择、时间序列SSL的归纳偏差、理论分析、对抗性攻击和稳健性分析、时间序列领域适应、预训练和大型模型、协作系统中的时间序列SSL以及时间序列SSL的基准评估等。
- 贡献:论文的主要贡献在于提供了一个全面的时间序列SSL方法的分类和回顾,以及对未来研究方向的展望,旨在推动该领域的研究进展。
论文没有进行特定的实验验证,但通过广泛的文献回顾和分析,为时间序列数据分析中的自监督学习提供了一个结构化的视角,并为未来的研究工作指明了方向。
附录
本文的附录有很多关于自监督学习的讨论值得一看
根据您提供的论文内容,本文的附录(Appendix)部分包含了以下内容:
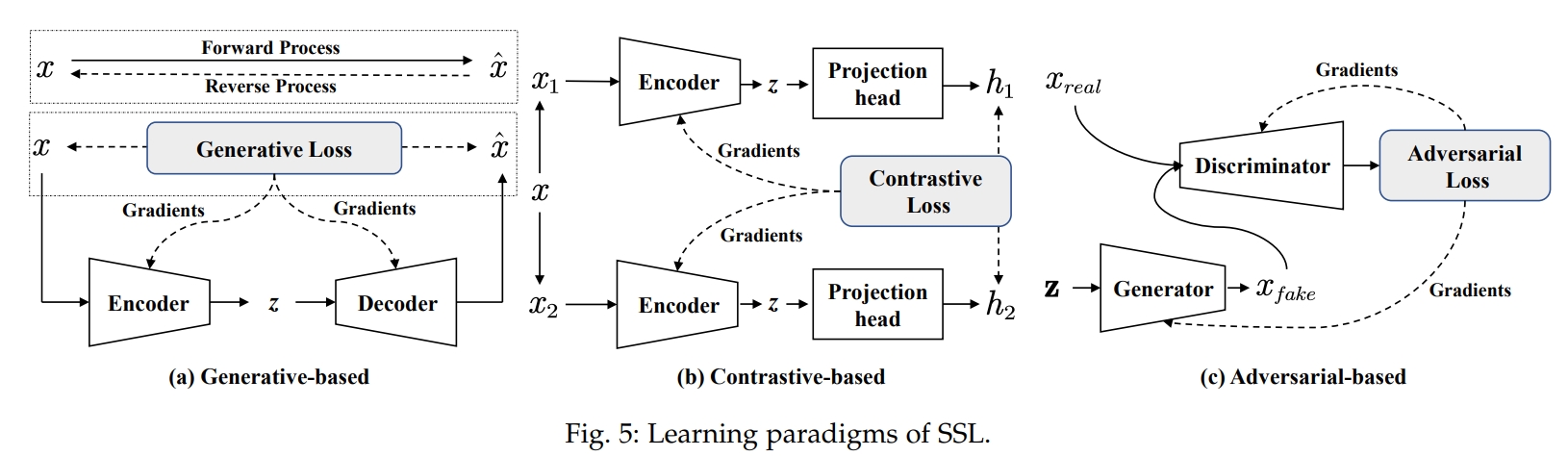
A. 自监督学习范式
介绍了生成式(Generative-based)、对比式(Contrastive-based)和对抗式(Adversarial-based)三种自监督学习(SSL)方法的模型架构。
B. SSL四个主要流程的进一步描述和总结
对SSL的四个主要流程:正负样本的构建、预文本任务的进一步分类、SSL模型架构的特点、以及SSL损失函数的目标进行了详细描述和总结。
C. 3种生成式的优缺点
对生成式方法中的三种子方法(自回归预测、自编码器重建和扩散生成)的优点和缺点进行了总结。

D. RNN, CNN和GNN的优缺点
对时间序列分析中常用的三种神经网络模型(循环神经网络RNN、卷积神经网络CNN和图神经网络GNN)的优点和缺点进行了讨论。
E. 5种对比式的优缺点
对对比式方法中的五种子方法(采样对比、预测对比、增强对比、原型对比和专家知识对比)的优点和缺点进行了总结。
F. 2种对抗式的优缺点
对对抗式方法中的两种子方法(时间序列生成和插补、辅助表示增强)的优点和缺点进行了总结。
G. 3种SSL方法的特点和局限性
总结了三种SSL方法(生成式、对比式和对抗式)的特点和局限性。

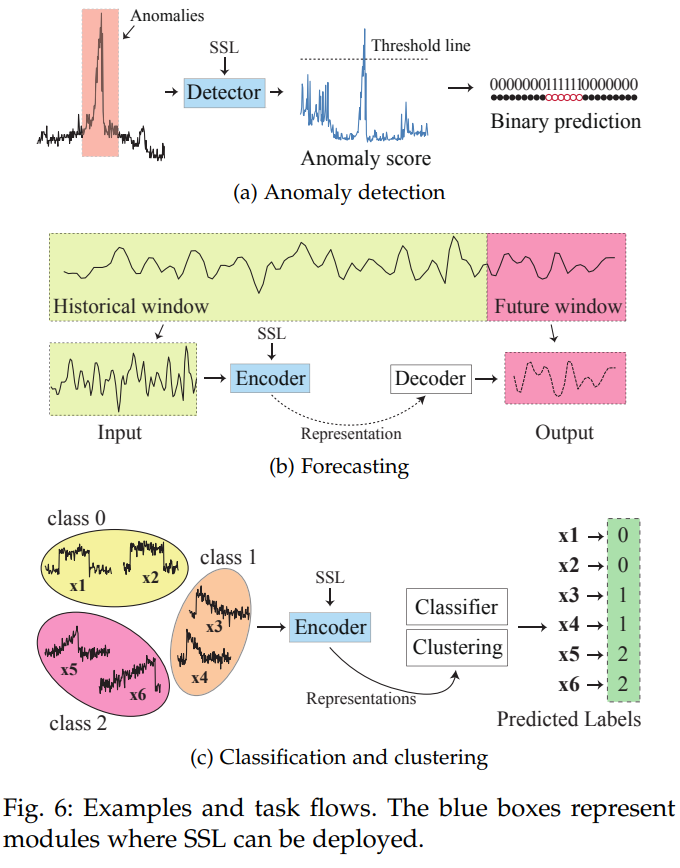
H. 任务流程,评价指标和示例
描述了异常检测、预测、分类和聚类任务的评估指标、示例和任务流程。
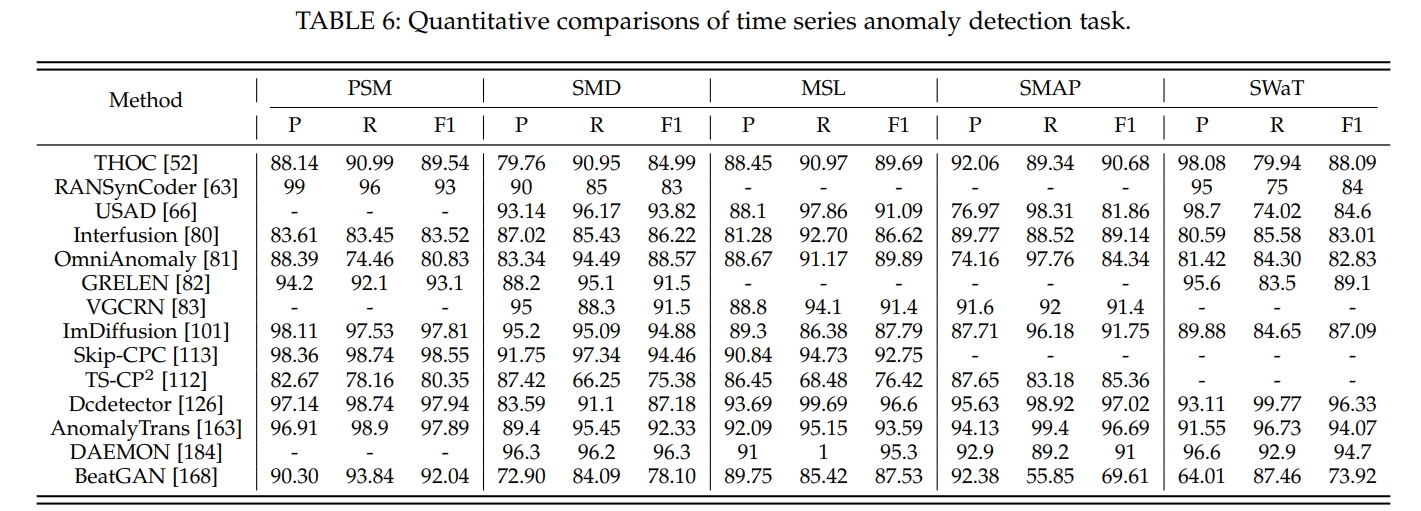
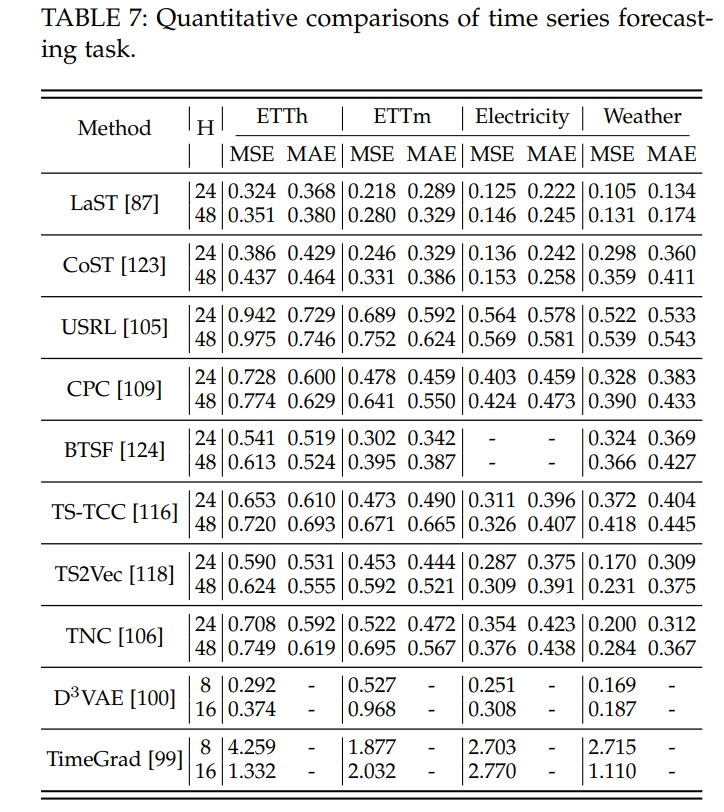
I. 不同方法的定量比较
对不同方法的性能进行了定量比较,并分析了方法与任务之间的相关性。
标、示例和任务流程。
[外链图片转存中…(img-Yzb1abKH-1713851408832)]
I. 不同方法的定量比较
对不同方法的性能进行了定量比较,并分析了方法与任务之间的相关性。
[外链图片转存中…(img-7HY8pU7j-1713851408832)][外链图片转存中…(img-NaFnCewA-1713851408832)]

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅