机器学习模型类型
有监督学习KNN(重点)
1. 基本思路:
如果⼀个待分类样本在特征空间中的 k k k个最相似(即特征空间中 K K K近邻)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。简单来说,就是近朱者赤,近墨者黑。
下图举例简单说明一下KNN的思路:

2. KNN需要样本标签的⽀持,是⼀种有监督学习算法。
- 数据集:即必须存在⼀个样本数据集,也称作训练集,样本数据集中每个样本是有标签的,即我们知道样本数据集中每⼀个样本的标签。
- 样本的向量表示:即不管是当前已知的样本数据集,还是将来可能出现的待分类样本,都必须可以⽤向量的形式加以表征。向量的每⼀个维度,刻画样本的⼀个特征,必须是量化的,可⽐较的。
- 样本间距离的计算方法:欧式距离、余弦距离、海明距离、曼哈顿距离等等。
3. k k k值的选取
- k k k的取值会影响待分类样本的分类结果,不能过大也不能过小。
- k k k值较小: K K K值的减小就意味着更复杂的决策边界,每个训练样本都会形成⼀个决策模型,容易发生过拟合。
- k k k值较大: K K K值的增大就意味着整体的模型变得简单,会导致偏差变大。
比如 k k k为总的训练样本数量,那么每次投票肯定都是训练数据中多的类别获胜
4.KNN的优缺点
- 优点
- 简单,易于理解,易于实现,⽆需参数估计,⽆需训练
- 对异常值不敏感(个别噪⾳数据对结果的影响不是很⼤)
- 适合对稀有事件进⾏分类
- 适合于多分类问题
- 缺点
- 计算量⼤,内存开销⼤
- 可解释性差。⽆法告诉你哪个样本更重要
- K K K值的选择。当样本不平衡时会导致错误
- KNN是⼀种消极学习⽅法、懒惰算法
无监督学习K均值聚类 (重点)
1. 基本概念
- “类”指的是具有相似性的集合。聚类是指将数据集划分为若干类,使得类内之间的数据最为相似,各类之间的数据相似度差别尽可能大。
- k − m e a n k-mean k−mean算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的 K K K个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。
聚类优化目标函数:
J = ∑ k = 1 K ∑ i = 1 n k ∥ x i − u k ∥ 2 J = \sum_{k=1}^{K} \sum_{i=1}^{n_k} \| x_i - u_k \|^2 J=∑k=1K∑i=1nk∥xi−uk∥2
其中 K K K 为类别总数量, x i x_i xi 为当前类别中的第 i i i 个样本, u k u_k uk 为第 k k k 个类的均值, n k n_k nk 为第 k k k 个类内的样本数量
2. k-means聚类的算法步骤
- 选取数据空间中的K个对象作为初始中心,每个对象代表⼀个聚类中心;
- 对于样本中的数据对象,根据它们与这些聚类中心的欧式距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
- 更新聚类中⼼:将每个类别中所有对象所对应的均值作为该类别的聚类中⼼,计算⽬标函数的值;
- 判断聚类中⼼和⽬标函数的值是否发⽣改变,若不变,则输出结果,若改变,则返回2。

半监督学习
1. 只有少量样本带标签
2. 更符合实际需求
强化学习
1. 特点
- 单步没有标签
- 流程走完时有标签
- 常用于游戏等人工智能应用中
2. 强化学习的基本模式

注意,上述的 reward 不只有奖励,还有惩罚。


自监督学习
简单来说,就是自我打标签,自我分类。

补充
课件上的内容好像就这么多,但是老师在课上也是补充了一些内容的,下面我展示一部分,因为我搜集的也不是很全: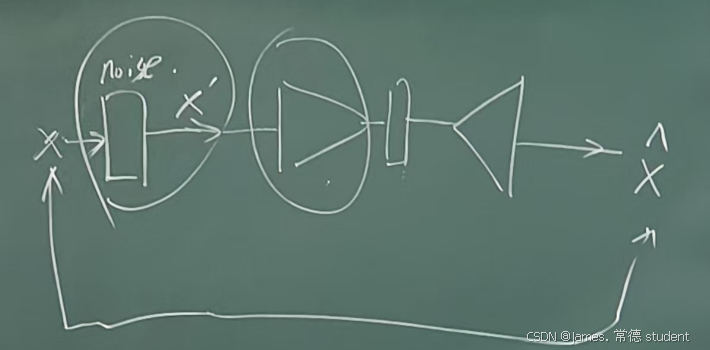
好像问的是:
Q1.为啥自编码器需要向上图这样设计,也就是我有一个encoder后,为啥后面还需要一个decoder将其解码,并比较这两个结果的误差?
A1. 实际上述是一个自编码器(Autoencoder),其设计核心思想是通过一个“编码-解码”的过程来学习数据的高效表示。
自编码器的主要目标是学习数据的低维表示(即隐空间表示)。为了实现这一目标,需要以下几个步骤:
- 编码器(Encoder):将高维输入数据映射到低维的隐空间表示。这个低维表示是对原始数据的一种压缩形式,它捕捉了数据的关键特征。
- 解码器(Decoder):从隐空间表示中重构出原始输入数据。解码器的作用是验证编码器是否学到了有意义的低维表示。
通过这种方式,自编码器能够学习到一种既能有效压缩数据、又能保留重要信息的表示方法。
解码器的作用不仅是帮助训练,还可以验证编码器是否学到了有意义的特征:
- 如果解码器能够从隐空间表示中准确地重建输入数据,说明编码器成功地提取了数据的关键特征。
- 如果重建误差较大,说明隐空间表示可能丢失了重要的信息,或者模型的容量不足。
通过这种方式,解码器实际上充当了一个“质量检查器”,确保编码器学到的表示是有效的。
三点概括,就是:
- 1.编码器负责压缩数据,提取关键特征。
- 2.解码器负责验证隐空间表示的有效性,并生成监督信号(重建误差)。
- 3.通过最小化重建误差,模型能够学习到数据的低维表示,同时满足特定任务的需求。
Q2. 有的时候在自编码器前面加入了一个noise这有啥用,为啥需要加入呢?
A2.
这种模型被称为去噪自编码器(Denoising Autoencoder, DAE)。
在自编码器中加入噪声的核心目的是让模型更具鲁棒性、防止过拟合,并提升其特征学习能力。这种方法不仅能够帮助模型更好地适应真实场景中的噪声数据,还能增强隐空间的稳定性和表达能力。此外,去噪自编码器还可以直接用于去噪任务,具有广泛的应用价值。因此,加入噪声不仅是对自编码器的一种改进,也是为了让模型更贴近实际需求的一种策略。







