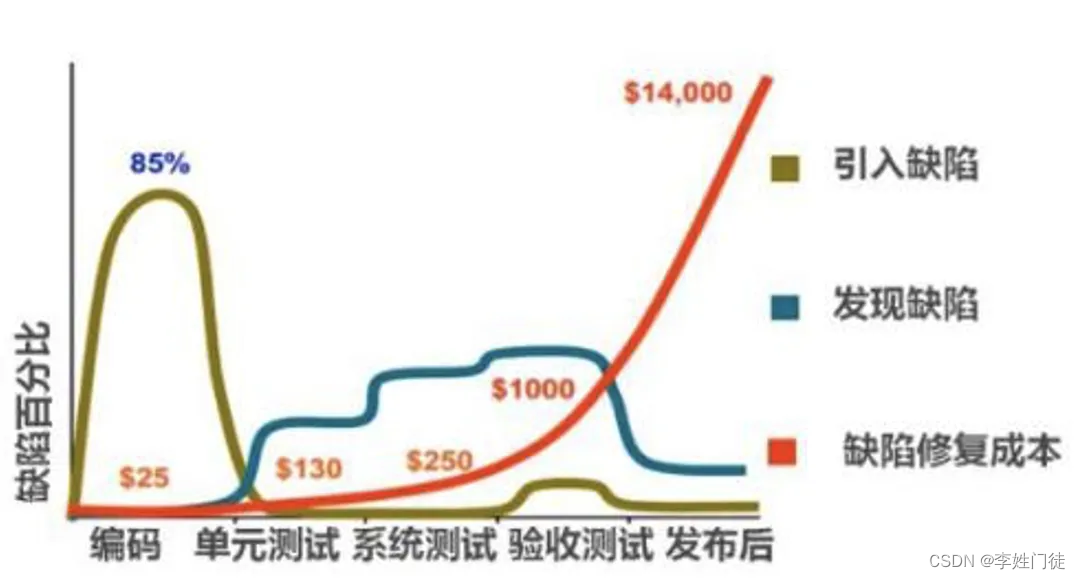
22年11月,Berkeley 和MIT联合发布Planning with Diffusion for Flexible Behavior Synthesis,作者在文中把轨迹扩散概率模型称为Diffuser。
Diffusion Model 具有更强的建模复杂分布的能力,能够更好地建模表征数据的各种特性,但是决策类问题除了需要处理表征建模的挑战,更注重于学习智能体策略的有效性和多样性。一种可行的思路是选择模仿学习方法,使用扩散模型来更好地“模仿”,“拟合”专家策略的数据分布:另一种思路就是选择强化学习,但强化学习方法和训练流程的复杂性和不稳定性很大程度上制约了扩散模型的使用。
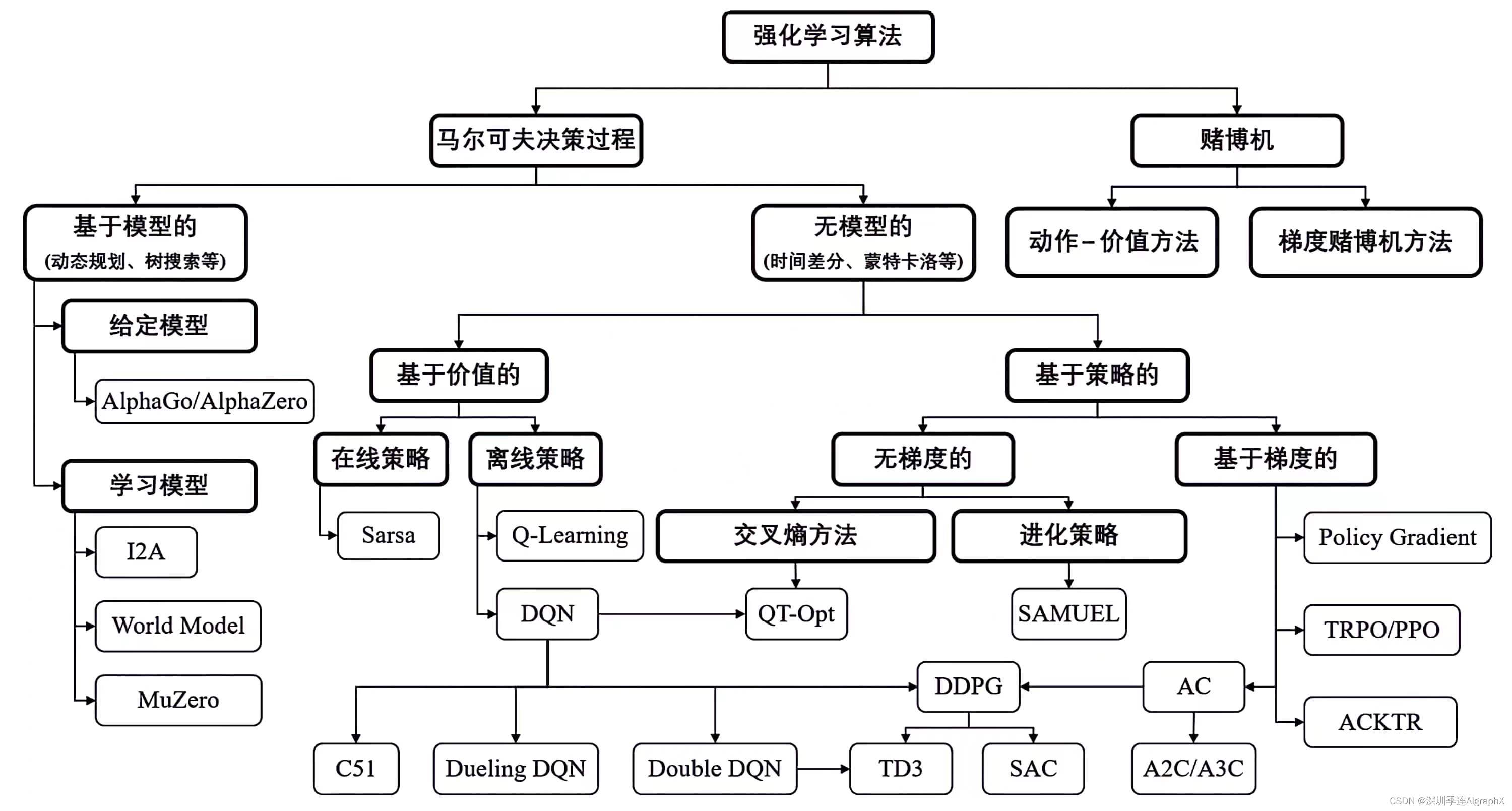
图 1:经典强化学习分类
早期无论是基于价值、基于策略还是基于模型的强化学习,都是将每一条轨迹分割成数个动作—状态对片段,并将每一个片段作为一个独立的样本点(datapoint)进行后续训练。与之相反,本文作者换个角度来看待这个数据集中的轨迹,即把每条轨迹视为一个样本点,从而将研究目标转变为建模全部轨迹的分布,而将轨迹的最优性作为条件变量从分布中采样轨迹。这样可以很好地利用 Diffusion Model 建模决策轨迹分布。
Abstract
基于模型的强化学习方法通常使用学习来估计近似动力学模型,将其余的决策工作交给经典的轨迹优化器。虽然在概念上很简单,但这种组合有许多经验上的缺点,这表明学习模型可能不太适合标准轨迹优化。在本文中,我们考虑将尽可能多的轨迹优化管道折叠到建模问题中会是什么样子,从而使模型的采样和规划变得几乎相同。我们方法的核心在于扩散概率模型,通过迭代去噪轨迹来规划。我们展示了分类引导采样和图像修复image inpainting如何重新解释为连贯的规划策略,探索基于扩散规划方法的不同寻常和有用的特性,并展示了我们的框架在强调长期决策和测试时间灵活性的控制设置中的有效性。
1 Introduction
使用学习模型进行规划是一个概念上简单的强化学习和数据驱动决策框架。它的吸引力来自于使用它们最成熟和最有效的学习技术:对于近似未知环境动态,这相当于监督学习问题。之后,学习模型可以插入到经典的轨迹优化流程中,这些可在原始上下文中类似地被很好地理解。
然而,这种组合很少能像所描述的那样工作。由于强大的轨迹优化器利用学习模型,因此该过程生成的规划通常看起来更像对抗性示例,而不是最优轨迹。因此,与轨迹优化工具箱相比,当代基于模型的强化学习算法往往更多地继承了model-free方法,如值函数和策略梯度。那些依赖在线规划的方法倾向于使用简单的无梯度轨迹优化例程,如random shooting或交叉熵方法,以避免上述问题。
### 看起来蒙圈,不着急,参见图 1,应该马上明白作者在说啥。
在这项工作中,我们提出了一种数据驱动的轨迹优化的替代方法。核心思想是训练一个直接适用于轨迹优化的模型,从这个意义上说,从模型中采样和使用它进行规划变得几乎相同。
这个目标需要改变模型的设计方式。由于学习的动力学模型通常是环境动力学的代理,因此通常通过根据潜在的因果过程构建模型来实现改进。相反,我们考虑如何设计一个模型与将使用它的规划问题一致。例如,由于模型最终将用于规划,动作分布与状态动力学一样重要,Long-horizon精度比单步误差更重要。另一方面,模型应该对奖励函数保持不可知,以便可以使用它在多个任务中,包括那些在训练期间看不到的任务。最后,该模型的设计应使其用于规划,而不仅仅是预测,随着经验的进步而改进,并能抵抗standard shooting规划划算法失败模式。
我们将此想法实例化为轨迹扩散概率模型,称为 Diffuser,如图 2 所示。
虽然标准的基于模型model-based规划技术自回归预测时间,但 Diffuser 同时预测规划的所有时间步长。扩散模型的迭代采样过程导致灵活的条件,允许辅助引导修改采样过程以恢复具有高回报或满足一组约束的轨迹。这种数据驱动的轨迹优化公式有几个吸引人的特性:
Long-horizon scalability
Diffuser 被训练以其生成轨迹的准确性而不是其单步误差,因此它不会受到单步动力学模型的复合误差的影响,并且在长规划范围内更优雅地扩展。
Task compositionality
奖励函数提供了在对规划进行采样时使用的辅助梯度,通过将多个奖励的梯度相加,可以直接进行规划。
Temporal compositionality
Diffuser通过迭代改进局部一致性来生成全局相干轨迹,允许它通过拼接分布内子序列来推广到新的轨迹。
Effective non-greedy planning
通过模糊模型和规划器之间的界限,改进模型预测的训练过程也有助于提高其规划能力。这种设计产生了一个学习规划器,可以解决许多传统规划方法难以解决的Long-horizon、稀疏奖励问题。
这项工作的核心贡献是为轨迹数据设计的去噪扩散模型和用于行为合成的相关概率框架。
虽然与深度模型强化学习中常用的模型类型相比显得非常规,我们证明 Diffuser 具有许多有用的属性,并且在需要Long-horizon推理和测试时间灵活性的离线控制设置中特别有效。
2 Background
我们的规划方法是基于学习的模拟过去使用轨迹优化的行为合成工作。在本节中,我们将简要介绍轨迹优化考虑的问题设置和我们为此问题使用的生成模型类别。
2.1 Problem Setting

2.2 Diffusion Probabilistic Models
参见VAE、VQ-VAE、DDPM、LDM的介绍
51-33 LDM 潜在扩散模型论文精读 + DDPM 扩散模型代码实现
3 Planning with Diffusion
使用轨迹优化技术的一个主要障碍是它们需要环境动力学的知识。大多数基于学习的方法试图通过训练近似动力学模型并将其插入到传统的规划流程来克服这一障碍。然而,学习模型通常不太适合考虑使用真实模型设计的规划算法类型,从而导致规划者通过找到对抗性示例来利用学习模型。我们提出了建模和规划之间的紧密耦合。我们没有在经典规划器的上下文中使用学习模型,而是将尽可能多的规划过程包含在生成建模框架中,以便规划与采样几乎相同。我们使用轨迹的扩散模型 pθ (τ ) 来做到这一点。扩散模型的迭代去噪过程有助于通过从形式的扰动分布中采样来灵活调节:
![]()
函数 h(τ ) 可以包含有关先验证据信息(例如观察历史)、期望结果(例如达到目标)或优化函数(例如奖励或成本)。在这个扰动分布中执行推理可以看作是与第 2.1 节中介绍的轨迹优化问题的概率模拟,因为它需要在 h(τ ) 下找到在 pθ (τ ) 和高奖励(或满足约束)下物理上逼真的轨迹。因为动态信息与扰动分布h(τ)分离,所以单个扩散模型pθ (τ)可以在同一环境中的多个任务重用。
在本节中,我们描述了Diffuser,这是一种为学习轨迹优化设计的扩散模型。然后,我们讨论了 Diffuser 规划的两个具体实例,实现为分类引导采样和图像修复的强化学习对应物。
3.1 A Generative Model for Trajectory Planning
Temporal ordering
从轨迹模型中采样与其规划之间的界限模糊会产生不寻常的约束:我们不能再以时间顺序自回归预测状态。考虑目标条件推理 p(s1 | s0, sT);下一个状态 s1 取决于未来状态以及先验状态。这个例子是一个更普遍的原则的例子:虽然动态预测是因果的,因为现在是由过去决定的,但决策和控制可能是反因果的,因为现在的决定取决于未来。由于我们不能使用时间自回归排序,我们设计了Diffuser来同时预测规划的所有时间步长。
Temporal locality
尽管不是自回归或者马尔可夫,但 Diffuser 具有宽松的时间局部性形式。在图 2 中,我们描述了由单个时间卷积组成的扩散模型的依赖图。给定预测的感受野仅包含附近的时间步长,包括过去和未来。因此,去噪过程的每个步骤只能根据轨迹的局部一致性进行预测。然而,通过将许多这些去噪步骤组合在一起,局部一致性可以驱动全局一致性。
Trajectory representation
Diffuser 是为规划而设计的轨迹模型,这意味着从模型导出的控制器的有效性与状态预测的质量同样重要。因此,轨迹中的状态和动作是联合预测的;为了预测的目的,动作只是状态的附加维度。具体来说,我们将Diffuser的输入(和输出)表示为二维数组 :
![]()
### 作者将数据集轨迹中状态和动作信息拼接在一起,表达为一个二维数组,作为轨迹表示Trajectory representation。实际操作时,选取某个固定长度轨迹作为 Diffuser 的输入输出,即将轨迹作为 Diffuser 加噪去噪的对象。
Architecture
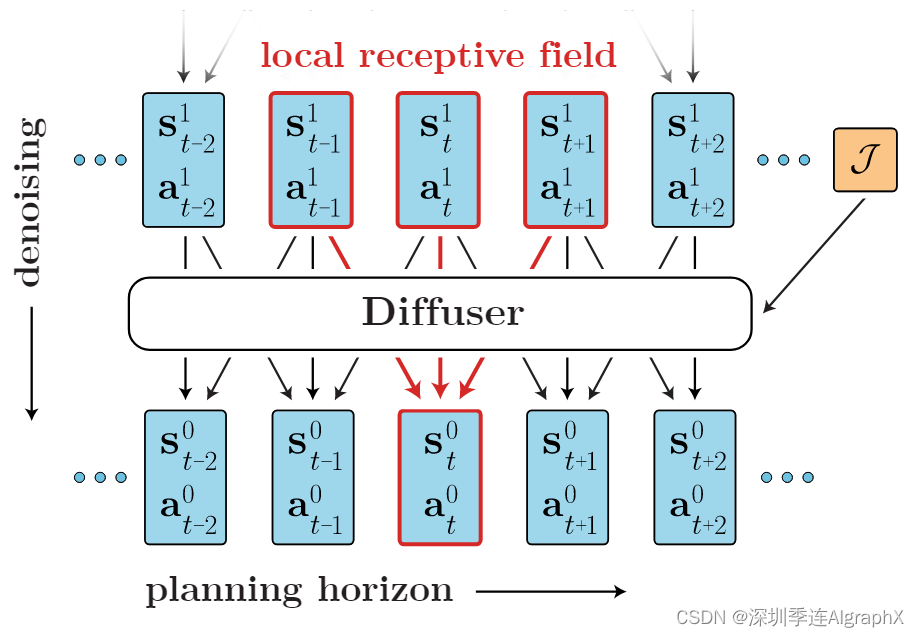
图 2: Diffuser 迭代地采样轨迹示意图。Diffuer 通过迭代去噪由可变数量的状态-动作对state-action pairs组成的二维阵列来对规划进行采样。小的感受野约束模型在单个去噪步骤期间仅强制执行局部一致性。通过将多个去噪步骤组合在一起,局部一致性可以驱动采样规划的全局一致性。可选的引导函数 J 可用于使规划偏向于那些优化测试时间目标或满足一组约束的规划。
### 对于轨迹中转换间的时间依赖关系,Diffuser 没有强调自回归或马尔可夫性,而对时间局部性作出了更宽松的假设(结合了计算机视觉任务中常见的感受野的概念)。如图 2 所示,Diffuser 通过迭代地对包含可变数量的状态-动作对去噪采样规划中的轨迹。在一步去噪过程中,较小的感受野,即图中红色表示部分,会约束(可选引导函数 J )模型依据轨迹中相邻帧来推断去噪结果。
通过多步的去噪,这种局部相关性可以逐渐拓展到全局相关性。因此不同于马尔可夫性,Diffuser 中当前帧的去噪结果不仅依赖于过去,也取决于未来,这就是 Diffuser 设计的重点之一:时间局部性 (temporal locality) 。
鉴于前面架构的设计,Diffuser所需组件:
- 应该非自回归地预测整个轨迹;
- 去噪过程的每个步骤应该是时间局部的;
- 轨迹表示应该允许沿一维(planning horizon)的等方差,而不是二维(the state and action features)的等方差。
我们使用由重复(时间)卷积残差块组成的模型来满足这些标准。整体架构类似于在基于图像的扩散模型中发现的 U-Nets 网络,但二维空间卷积替换为一维时间卷积(图 A1)。由于模型是完全卷积的,预测的视野horizon不是由模型架构决定的,而是由输入维度决定;如果需要,视野可以在规划期间动态变化。
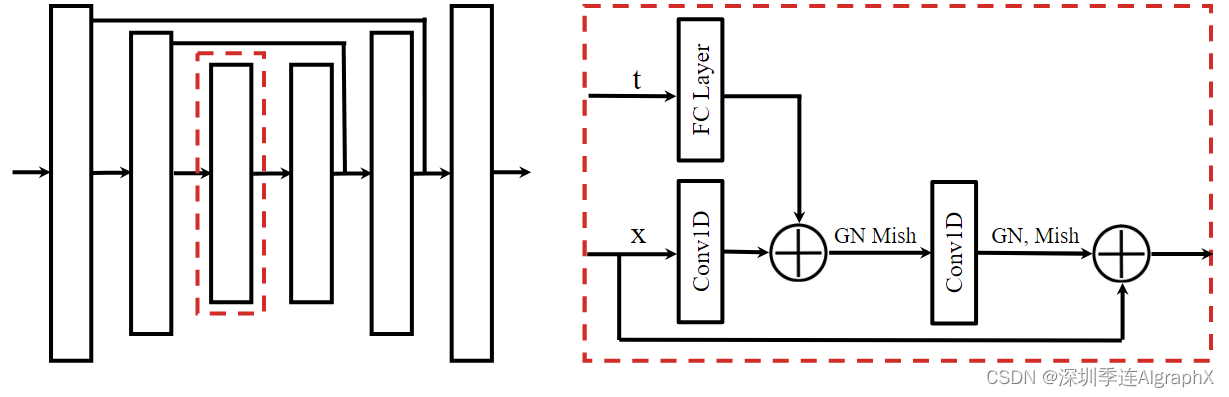
图 A1。Diffuser有一个U-Net架构,残差块由时间卷积、组归一化和Mish非线性组成。
### Diffuser 使用由堆叠(时序)卷积残差块组成的模型来满足这些条件。
Training
我们使用Diffuser来参数化轨迹去噪过程的学习梯度 ,平均μθ可以用闭合形式求解。我们使用简化目标来训练模型,由下式给出:
![]()
其中 i ∼ U{1, 2,., N } 是扩散时间步长, ∼ N (0, I) 是噪声目标,
是加噪
的轨迹
。反向过程协方差 Σi 遵循 cosine schedule。
### 有了上述模型结构设计,此时就可以将模型形式化为函数 。有两个"时间",扩散过程的时间步和轨迹规划中的时间步。文中用上标 i 来表示扩散时间步长,用下标 t 来表示轨迹规划时间步。
3.2 Reinforcement Learning as Guided Sampling
为了解决 Diffuser 的强化学习问题,必须引入奖励的概念。我们求助于控制推理图模型 [Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review] 来做到这一点。

### 前面作者提出了Diffuser的假设和思想、具体函数构造。 然而数据集中不仅包含了达成任务目标的高质量轨迹,还充斥着未达成目标的低质量轨迹。因此,这里还需要建模数据集的条件概率分布 ,这样便可以轨迹最优性为条件,采样出最优轨迹。这里本来应用条件采样conditional sampling,根据以前的工作,引入高斯分布来近似,更容易获得结果。这就于扩散模型中的经典方法分类引导采样classifier-guided sampling一致。而对于轨迹最优性,Diffuser 借助控制推断图模型来获得相应的定义。
这种关系在分类引导采样之间提供了直接的转换,用于生成类条件图像和强化学习问题设置。
我们首先在所有可用轨迹数据的状态和动作上训练一个扩散模型 pθ (τ)。然后我们训练一个单独的模型Jφ来预测轨迹样本Ti的累积奖励。Jφ的梯度用于通过根据方程式(3)修改反向过程的均值μ来指导轨迹采样过程。采样出的轨迹 的第一个动作会被用于在环境中执行,执行后再一次采样新的轨迹。算法 1 给出了引导规划方法的伪代码。

### 训练一个扩散模型 pθ (τ)和一个单独的模型Jφ,然后结合两者进行采样,具体来说,就是利用Jφ 的梯度来修正期望 μ 以引导轨迹采样过程。
3.3 Goal-Conditioned RL as Inpainting
一些规划问题比奖励最大化更自然地被提出作为约束满意度。在这些设置中,目标是产生任何满足一组约束的可行轨迹,例如终止目标位置。处理方程式(2)描述的轨迹的二维数组表示,此设置可以转化为修复问题inpainting problem,其中状态和动作约束的行为类似于图像中的观察像素。矩阵中的所有未观察到的位置都必须由扩散模型填充,其方式与观察到的约束一致。
该任务所需的扰动函数是观测值的狄拉克增量,在其他地方是恒定的。具体来说,如果 ct 是时间步 t 的状态约束,则
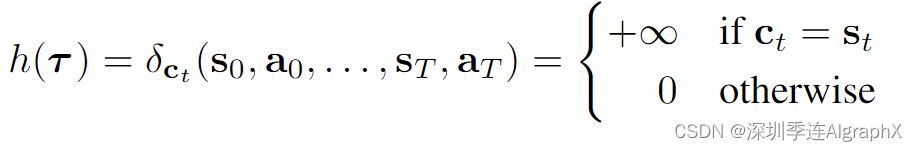
动作约束的定义是相同的。在实践中,这可以通过从无扰动的反向过程中采样并在所有扩散时间步之后用条件值替换采样值来实现。
即使奖励最大化问题也需要按条件修复,因为所有采样的轨迹都应该从当前状态开始。这种调节在算法 1 中由第 10 行描述。
### 更进一步地,Diffuser 还适用于 goal-conditioned RL,这种基于目标的强化学习范式通常被自然地被建模为约束满足问题 (constraint satisfaction) 而不是奖励最大化问题 (reward maximization)。其核心目标在于给出任何满足约束的轨迹,比如要求轨迹终止于某个目标位置 (goal location) 。根据轨迹表示,goal-conditioned RL 可以很自然地被转换为 inpainting 问题。轨迹中被限定的状态和动作可以类比于图像修复问题中已经被观察到的、填充完成的像素点。具体应用时,如 Algorithm 1 第 10 行所示,在采样时将执行后观察到的状态替换到采样轨迹中即可。
4 Properties of Diffusion Planners
我们讨论了一些Diffuser的重要属性,重点关注与标准动力学模型不同或非自回归轨迹预测不寻常的属性。
### 如图3 所示,Diffuser 的重要特性包括长视野规划 long-horizon planning、时序组合性 Temporal compositionality、可变长规划 Variable-length plans 和任务组合 Task compositionality。
Learned long-horizon planning
单步模型通常用作真实环境动态 f 的代理,因此与特定的任何规划算法无关。相比之下,算法 1 中的规划例程与扩散模型的特定可供性密切相关。由于我们的规划方法与采样几乎相同(唯一的区别是扰动函数 h(τ ) 的指导),因此Diffuser作为长期预测器的有效性直接转化为有效的长期规划。我们在图 3a 中展示了在达到目标设置中学习规划的好处,表明 Diffuser 能够在已知shooting-based的方法难以解决的稀疏奖励设置类型中生成可行的轨迹。在第 5.1 节中探索了这个问题设置的更加定量版本。
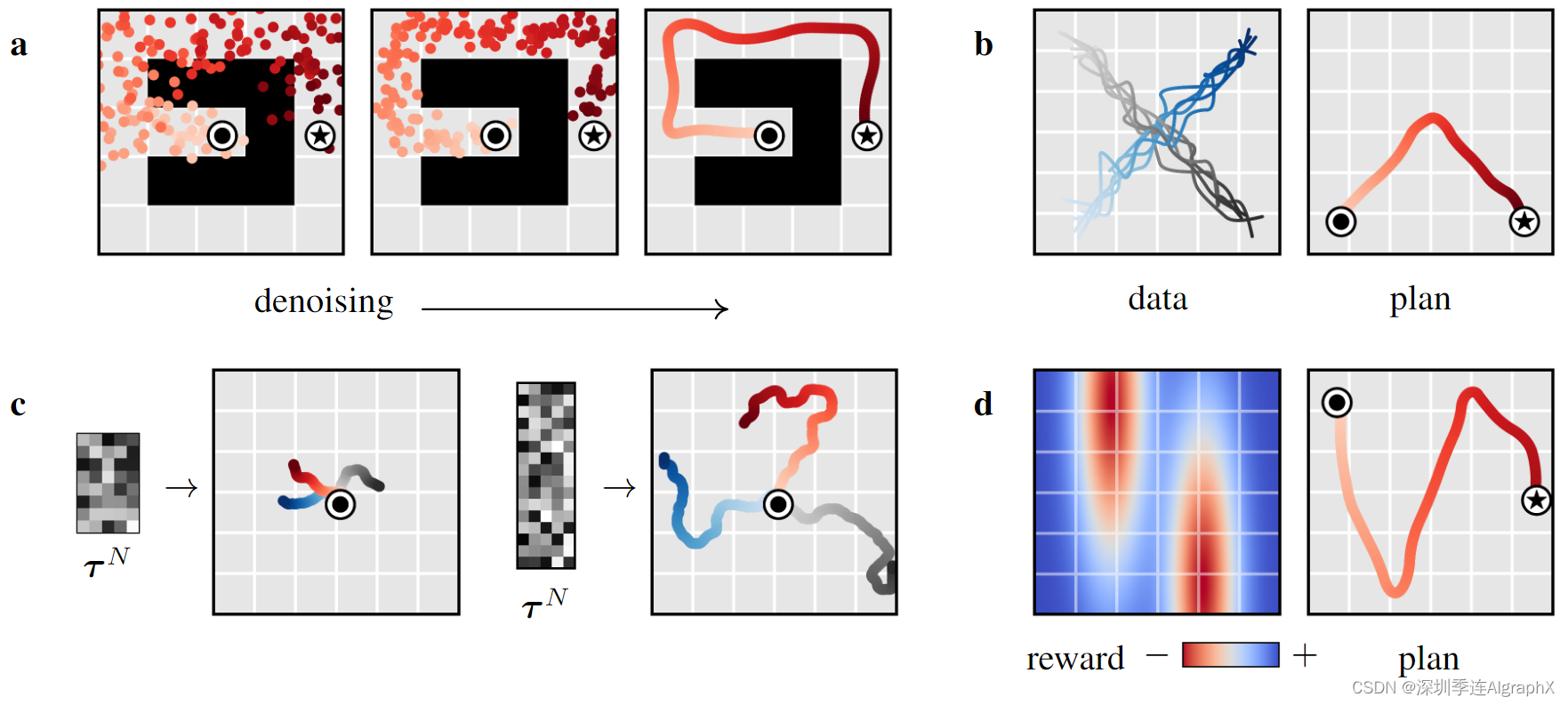
图 3。扩散规划器特性(a)学习长期规划:Diffuser学习规划程序不受shooting算法常见失败模式的影响,并且能够以稀疏的回报在long horizons进行规划。(b) 时间合成性:即使模型不是马尔可夫模型,它也会通过迭代细化来生成轨迹,以达到局部一致性。因此,它展示了通常与马尔可夫模型相关的泛化类型,能够将训练数据中的轨迹片段拼接在一起,以生成新的规划。(c) 可变长度规划:尽管Diffuser是一个轨迹级模型,但其规划范围并不是由其架构决定的。在训练之后,可以通过改变输入噪声的维度来更新。(d) 任务组合性:扩散器可以与新的奖励函数组合,以规划训练中看不见的任务。在所有子图中,表示开始状态和目标状态。
Temporal compositionality
单步模型通常的动机是使用马尔可夫属性,允许它们组成分布内转换以推广到分布外轨迹。由于Diffuser通过迭代改进局部一致性来生成全局相干轨迹(第3.1节),它还可以以新颖的方式拼接熟悉的子序列。在图 3b 中,我们在只有直线行驶的轨迹上训练 Diffuser,并表明它可以通过组合它们在交点处的轨迹来推广到 v 形轨迹。
Variable-length plans
因为我们的模型在其预测的horizon维度上是完全卷积的,所以它的规划horizon不是由体系结构选择指定的。相反,它由初始化去噪过程的输入噪声 τ N ∼ N (0, I) 的大小决定,允许可变长度规划(图 3c)。
Task compositionality
虽然 Diffuser 包含有关环境动态和行为的信息,但它独立于奖励函数。由于该模型作为可能的未来的先验,因此规划可以由对应于不同奖励的相对轻量级扰动函数h(τ)(甚至多重扰动的组合)来指导。我们通过规划扩散模型训练期间看不到的新奖励函数来证明这一点(图 3d)。
5 Experimental Evaluation
我们实验的重点是评估 Diffuser 与来自数据驱动规划器的能力。特别是,我们评估了(1)没有手动设计奖励的情况下long horizon规划能力,(2)泛化到训练期间未曾见过的目标的新配置能力,以及(3)从不同质量的异构数据中构建一个有效控制器的能力。
最后,我们通过研究基于扩散规划的实际运行时考虑,包括加快规划过程最有效的方法,同时在性能上受到最低限度的影响。
5.1 Long Horizon Multi-Task Planning
我们在Maze2D环境中评估长期规划,这需要遍历一个目标位置,其中给出了1的奖励。任何其他位置都没有提供奖励塑造(其他情形奖励都为 0 )。因为它可能需要数百个步骤才能达到目标位置,即使是最好的无模型算法也很难充分执行信用分配并可靠地达到目标(表 1)。
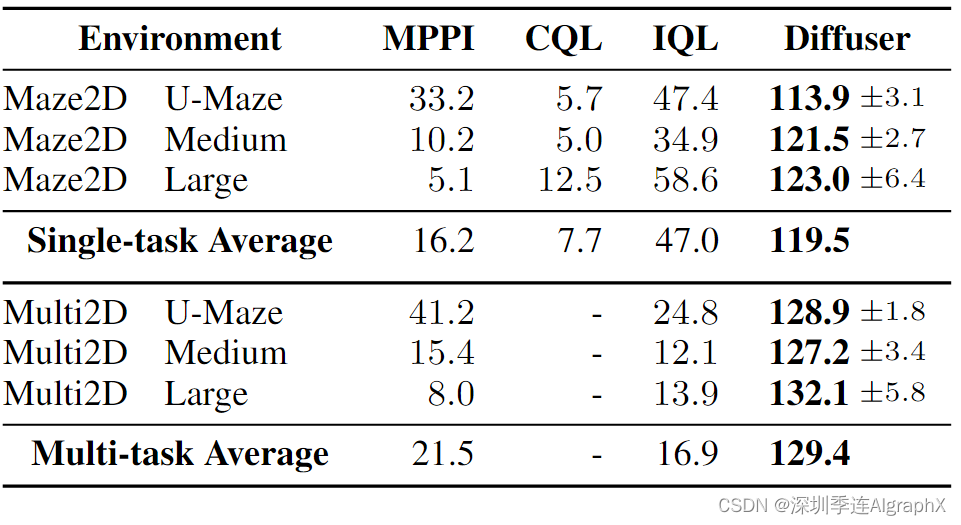
我们使用修复策略规划 Diffuser,以开始和结束位置为条件。(目标位置也可用于无模型方法;它可以通过是具有非零奖励的数据集的唯一状态来识别。)然后我们使用采样的轨迹作为开环规划。Diffuser 在所有迷宫大小中实现了超过 100 的分数,表明它优于参考专家策略。我们在图 4 中可视化了生成 Diffuser 规划的反向扩散过程。

而在Maze2D的训练数据是无向的由一个控制器导航到和从随机选择的位置——评估是单任务的,因为目标总是相同的。为了测试多任务灵活性,我们修改了环境以随机化每一集开始时的目标位置。此设置在表 1 中表示为 Multi2D。Diffuser 自然是一个多任务规划器;我们不需要从单任务实验中重新训练模型,并简单地改变条件目标。因此,Diffuser 在多任务设置中的性能与单任务设置一样好。相比之下,在适应多任务设置时,单任务设置中的最佳无模型算法IQL的性能大幅下降。MPPI 使用真实动态;与 Diffuser 的学习规划算法相比,它的性能很差,突出了Long-horizon规划带来的困难,即使没有预测不准确。
5.2 Test-time Flexibility
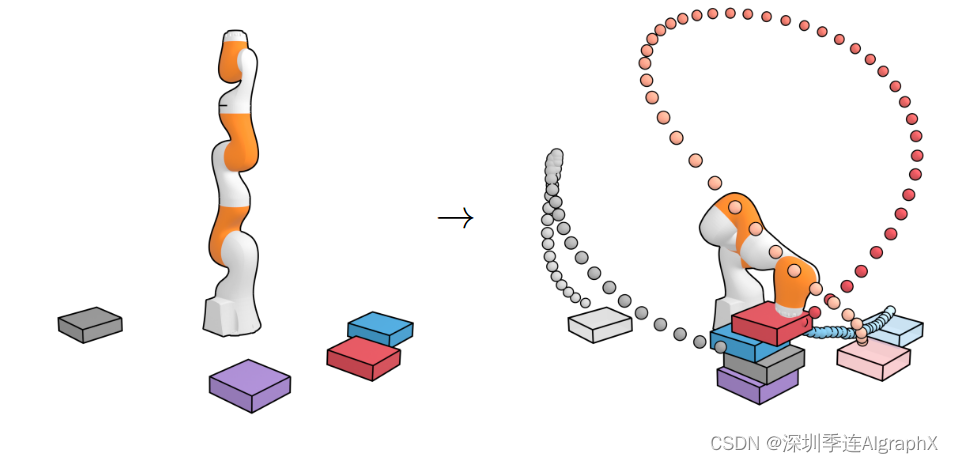
为了评估对新测试时间目标的泛化能力,我们构建了一套具有三种设置的块堆叠任务:
- 无条件堆叠,其任务是建造尽可能高的方块;
- 条件堆叠,任务是用指定顺序构建一个方块;
- 重排,任务是训练时未曾见过的排列顺序堆叠方块。
我们从PDDLStream生成的演示中训练10000个轨迹上的所有方法;成功放置堆叠时奖励等于1,否则为0。
这些块堆叠对测试时间灵活性的诊断具有挑战性;在为随机化目标执行部分堆栈的过程中,控制器将冒险进入训练配置中不包括的新状态。
我们对所有块堆叠任务使用一个训练好的扩散器,仅在设置之间修改扰动函数h(τ)。在无条件叠加任务中,我们直接从无扰动去噪过程pθ (τ)中采样来模拟PDDLStream控制器。在条件叠加和重排任务中,我们构建了两个扰动函数h(τ)来对采样轨迹进行偏置:第一个函数最大化轨迹最终状态与目标构型匹配的可能性,第二个函数在叠加运动期间强制末端执行器与立方体之间的接触约束。
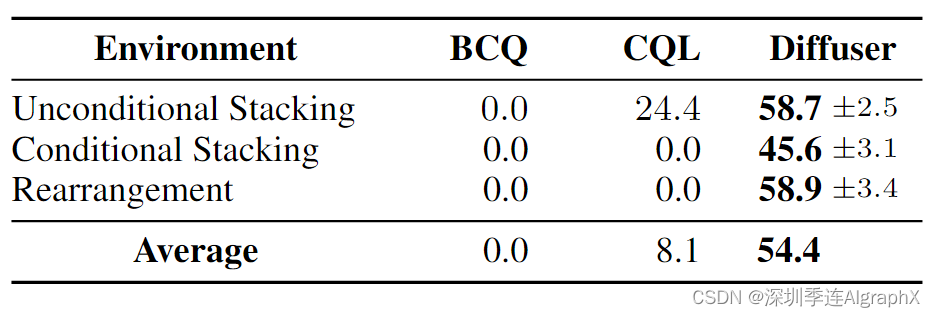
我们比较了两种先前的无模型离线强化学习model-free reinforcement learning算法:BCQ 和CQL,训练无条件堆叠的标准变体和条件堆叠和重排的目标条件变体。定量结果上表3所示,其中得分为100分对应于任务的完美执行。Diffuser在很大程度上优于之前的两种方法,因为条件设置需要灵活的行为生成,这对无模型算法来说尤其困难。
图5提供了Diffuser执行的可视化描述。
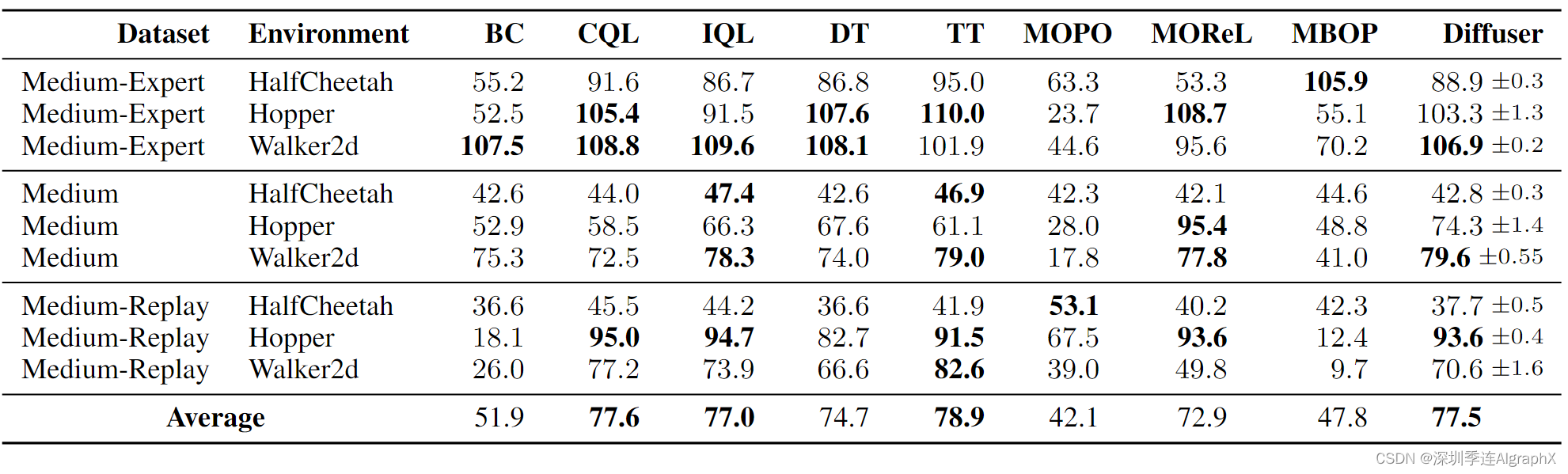
5.3 Offline Reinforcement Learning
最后,我们使用 D4RL 离线运动套件评估从不同质量异构数据中恢复有效单任务控制器的能力。我们使用第 3.2 节中描述的采样过程将 Diffuser 生成的轨迹引导到高奖励区域,并使用第 3.3 节中描述的修复程序调节当前状态的轨迹。奖励预测器 Jφ 在与扩散模型pθ (τ )相同的轨迹数据上进行训练。下图可视化地展示了 Diffuser 在 Hopper 环境中的采样规划过程。
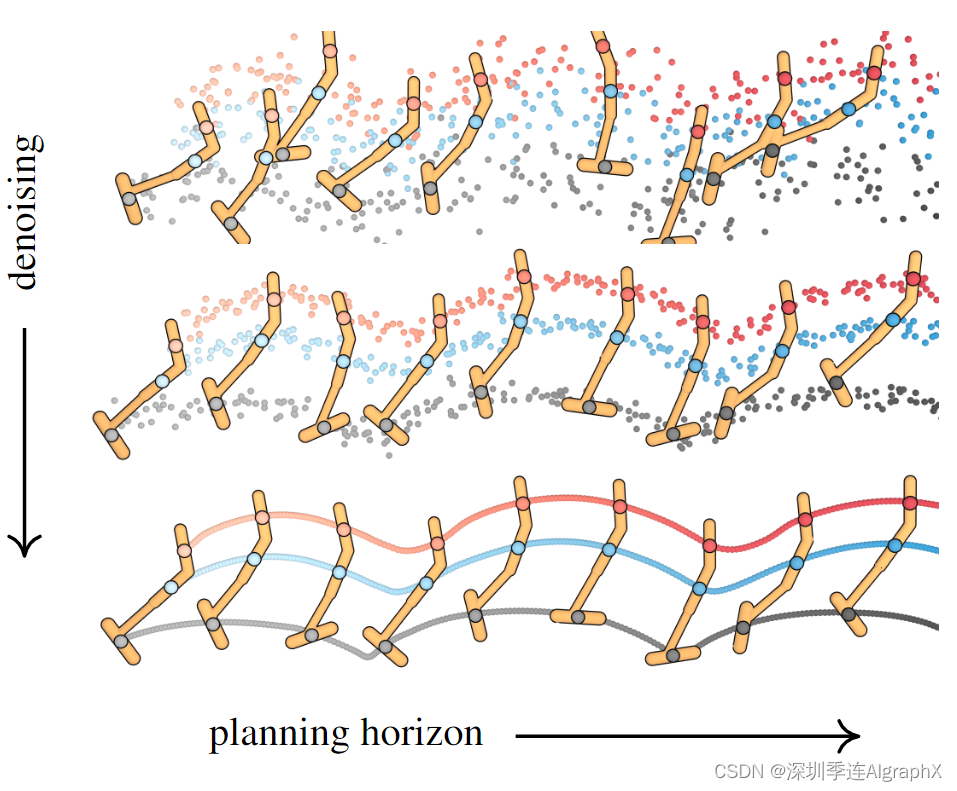
图 6:引导采样。Diffuser通过去噪过程同时生成规划的所有时间步长,而不是自回归生成。
我们比较了各种以前的算法,这些算法跨越了其他数据驱动控制方法,包括无模型强化学习算法CQL 和IQL 、返回条件反射方法、基于模型的强化学习方法,包括轨迹transformer TT、MOPO、MOReL 和MBOP 。在单任务设置中,Diffuser 的性能与先前的算法相当:优于基于模型的 MOReL 和 MBOP 和返回条件 DT,但比专门为单任务性能设计的最佳离线技术差。我们还在 MPPI 等传统轨迹优化器中研究了使用 Diffuser 作为动力学模型的变体,但发现这种组合并不比随机表现更好,这表明 Diffuser 的有效性源于耦合建模和规划,而不是提高开环预测精度。
5.4 Warm-Starting Diffusion for Faster Planning
Diffuser 的一个限制是单个规划生成速度较慢(由于迭代生成)。当我们执行规划开环时,必须在执行的每一步重新生成一个新规划。为了提高Diffuser的执行速度,我们可以进一步重用先前生成的规划来热启动后续规划的生成。为了热启动规划,我们可以从先前生成的规划中运行有限数量的前向扩散步骤,然后从该部分噪声轨迹运行相应的去噪步骤以重新生成更新的规划。在图7中,我们说明了性能和运行时预算之间的权衡,因为我们将用于重新生成每个新规划的潜在去噪步骤数量从2更改为100。我们发现,我们可以显著降低我们方法的规划预算,而性能仅略有下降。

6 Related Work
略
7 Conclusion
我们提出了Diffuser,一种用于轨迹数据的去噪扩散模型。使用 Diffuser 进行规划与从中采样几乎相同,仅在添加用于指导样本的辅助扰动函数方面有所不同。学习到的基于扩散的规划过程有许多有用的属性,包括对稀疏奖励的优雅处理、在没有再训练的情况下规划新奖励的能力以及允许它通过拼接分布内子序列来产生分布外轨迹的时间组合性。我们的结果指出了一类新的基于扩散的深度学习模型强化学习规划程序。
### 上海人工智能实验室有推出Diffusion Model + RL系列相关技术科普和研讨博客文章。Diffuser应该是该系列第一篇经典工作。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删,转发请注明出处。文中如有错误的地方,也请在留言区告知。
Diffuser-https://arxiv.org/abs/2205.09991
GitHub - opendilab-A curated list of Diffusion Model in RL resources (continually updated)