
前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!
欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!
本文目录:
- 一、WISDM数据集分析及介绍
- 二、CNN网络结构及介绍
- 1. CNN的核心组件
- 1.1 卷积层(Convolutional Layer)
- 1.2 池化层(Pooling Layer)
- 1.3 激活函数层(Activation Layer)
- 1.4 全连接层(Fully Connected Layer)
- 2. CNN的层次化特征提取
- 3. CNN的变体与扩展
- 3.1 深度可分离卷积(Depthwise Separable Convolution)
- 3.2 空洞卷积(Dilated Convolution)
- 3.3 注意力机制(Attention Mechanism)
- 4. CNN在时间序列数据中的应用
- 4.1 1D卷积
- 4.2 时序池化
- 4.3 混合架构
- 5. CNN的优化策略
- 5.1 正则化方法
- 5.2 学习率调整
- 6. 典型CNN架构示例
- 三、WISDM数据集分割及处理
- 四、CNN网络训练WISDM数据集
- 1.常用的仿真指标
- 1.1 准确率 (Accuracy)
- 1.2 精确率 (Precision)
- 1.3 召回率 (Recall)
- 1.4 F1分数 (F1-Score)
- 1.5 参数量 (Parameters)
- 1.6 推理时间 (Inference Time)
- 2.具体的训练过程
- 1.数据集加载
- 2.模型实例化
- 3.创建数据加载器
- 4.优化器和学习率调度器设置
- 5.混合精度训练设置
- 6.训练循环
- 3.结果展示
- 五、可视化维度分析
- 1.混淆矩阵图
- 2.雷达图
- 3.准确率和损失率的收敛曲线图
- 4.仿真指标柱状图
- 5.仿真指标折线图
- 六、总结
卷积神经网络(CNN)因其强大的特征提取能力和深度学习架构而备受推崇,CNN在处理图像数据时展现出的卓越性能,使其成为解决各种视觉识别任务的首选工具。WISDM数据集是一个广泛用于运动估计研究的基准数据集,它包含了多个视频序列,每个序列都记录了摄像头在不同方向上移动时捕捉到的图像。在本研究中,我们将探讨如何利用 CNN来训练和优化WISDM数据集,以提高运动估计的准确性和鲁棒性。
一、WISDM数据集分析及介绍
WISDM数据集是一个用于人类活动识别(Human Activity Recognition, HAR)的公共数据集。它包含了从智能手机和智能手表收集的传感器数据,这些数据被用来识别多种不同的人类活动:
-
数据集来源与构成:
- WISDM数据集由福特汉姆大学计算机与信息科学系的Gary Weiss博士领导的团队创建。
- 数据集包含了51名参与者进行的18种不同的活动,每种活动的数据都是通过佩戴在身体不同部位的智能手机和智能手表上的加速度计和陀螺仪以20Hz的频率收集得到的。
-
数据集特点:
- 数据集中的活动包括但不限于走路、跑步、上下楼梯、坐、站等。
- 每个活动的数据长度为3分钟,为研究者提供了充足的时间序列数据进行分析。
-
数据集的应用:
- WISDM数据集适用于开发和测试各种HAR模型,尤其是基于深度学习的模型,如卷积神经网络(CNN)。
二、CNN网络结构及介绍
卷积神经网络是一种专门用来处理具有类似网格结构的数据的神经网络,如图像。CNN在图像识别、视频分析和自然语言处理等领域取得了巨大的成功。
1. CNN的核心组件
1.1 卷积层(Convolutional Layer)
- 功能:通过卷积核(filter)在输入数据上滑动,提取局部特征。
- 数学表示:
( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( i − m , j − n ) ⋅ K ( m , n ) (I * K)(i,j) = \sum_{m}\sum_{n} I(i-m, j-n) \cdot K(m,n) (I∗K)(i,j)=m∑n∑I(i−m,j−n)⋅K(m,n)
其中, I I I为输入, K K K为卷积核。 - 参数:
- 卷积核大小(kernel size):通常为3×3或5×5
- 步幅(stride):控制滑动步长
- 填充(padding):保持特征图尺寸
1.2 池化层(Pooling Layer)
- 功能:对特征图进行下采样,降低计算复杂度,增强特征不变性。
- 类型:
- 最大池化(Max Pooling):取局部区域最大值
- 平均池化(Average Pooling):取局部区域平均值
- 参数:
- 池化窗口大小:通常为2×2
- 步幅:通常与窗口大小一致
1.3 激活函数层(Activation Layer)
- 功能:引入非线性,增强模型的表达能力。
- 常用激活函数:
- ReLU(Rectified Linear Unit): f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
- Leaky ReLU: f ( x ) = max ( 0.01 x , x ) f(x) = \max(0.01x, x) f(x)=max(0.01x,x)
- Swish: f ( x ) = x ⋅ σ ( x ) f(x) = x \cdot \sigma(x) f(x)=x⋅σ(x),其中 σ \sigma σ为sigmoid函数
1.4 全连接层(Fully Connected Layer)
- 功能:将提取的特征映射到输出空间(如分类概率)。
- 特点:
- 参数量较大
- 通常位于网络末端
2. CNN的层次化特征提取
CNN通过多层卷积和池化操作,逐步提取从低级到高级的特征:
- 低级特征:边缘、角点、纹理等
- 中级特征:局部形状、简单模式
- 高级特征:语义信息、复杂结构
3. CNN的变体与扩展
3.1 深度可分离卷积(Depthwise Separable Convolution)
- 结构:
- 深度卷积(Depthwise Convolution):每个输入通道单独卷积
- 逐点卷积(Pointwise Convolution):1×1卷积融合通道信息
- 优点:
- 显著减少参数量和计算量
- 公式: 1 N + 1 D k 2 \frac{1}{N} + \frac{1}{D_k^2} N1+Dk21( N N N为输出通道数, D k D_k Dk为卷积核大小)
3.2 空洞卷积(Dilated Convolution)
- 特点:
- 通过增加卷积核采样间隔,扩大感受野
- 公式: F d i l a t e d ( i , j ) = ∑ m ∑ n I ( i + r ⋅ m , j + r ⋅ n ) ⋅ K ( m , n ) F_{dilated}(i,j) = \sum_{m}\sum_{n} I(i+r\cdot m, j+r\cdot n) \cdot K(m,n) Fdilated(i,j)=∑m∑nI(i+r⋅m,j+r⋅n)⋅K(m,n)
- 其中, r r r为空洞率
3.3 注意力机制(Attention Mechanism)
- 作用:
- 动态调整特征权重
- 增强重要特征的表达能力
- 常见形式:
- 通道注意力(SENet)
- 空间注意力(CBAM)
4. CNN在时间序列数据中的应用
4.1 1D卷积
- 特点:
- 卷积核沿时间维度滑动
- 适用于传感器数据、语音信号等
- 示例:
python">tf.keras.layers.Conv1D(filters=64, kernel_size=3, strides=1, padding='same')
4.2 时序池化
- 方法:
- 全局平均池化(Global Average Pooling)
- 自适应最大池化(Adaptive Max Pooling)
4.3 混合架构
- CNN-LSTM:
- CNN提取局部特征
- LSTM捕捉时序依赖
- CNN-Transformer:
- CNN提取空间特征
- Transformer建模长时依赖
5. CNN的优化策略
5.1 正则化方法
- Dropout:随机丢弃神经元,防止过拟合
- Batch Normalization:标准化层输入,加速训练
- 权重衰减(L2正则化):约束权重幅度
5.2 学习率调整
- 策略:
- 学习率衰减(Learning Rate Decay)
- 余弦退火(Cosine Annealing)
- 预热(Warmup)
6. 典型CNN架构示例
python">def cnn(input_shape, num_classes):inputs = tf.keras.Input(shape=input_shape)# 卷积模块x = tf.keras.layers.Conv1D(64, 5, padding='same', activation='relu')(inputs)x = tf.keras.layers.MaxPooling1D(2)(x)x = tf.keras.layers.Conv1D(128, 3, padding='same', activation='relu')(x)x = tf.keras.layers.GlobalAveragePooling1D()(x)# 分类头x = tf.keras.layers.Dense(128, activation='relu')(x)outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x)return tf.keras.Model(inputs, outputs)
三、WISDM数据集分割及处理
WISDM数据集下载链接:https://www.cis.fordham.edu/wisdm/includes/datasets/latest/WISDM_ar_latest.tar.gz
加载、预处理和准备WISDM数据集,以便用于人类活动识别(HAR)任务:
- 参数设定:
dataset_dir: 指定原始数据存放的目录。WINDOW_SIZE: 定义滑窗的大小。OVERLAP_RATE: 定义滑窗的重叠率。SPLIT_RATE: 定义训练集和验证集的分割比例。VALIDATION_SUBJECTS: 定义留一法验证时使用的特定主题(subject)集合。Z_SCORE: 决定是否进行标准化处理。SAVE_PATH: 定义预处理后数据保存的路径。
def WISDM(dataset_dir='./WISDM_ar_v1.1', WINDOW_SIZE=200, OVERLAP_RATE=0.5, SPLIT_RATE=(8, 2), VALIDATION_SUBJECTS={}, Z_SCORE=True, SAVE_PATH=os.path.abspath('D:/PycharmProjects/xyp-task')):
- 数据集下载:
- 使用
download_dataset函数,从福特汉姆大学提供的URL下载WISDM数据集,并将其存储在dataset_dir指定的目录中。
download_dataset(dataset_name='WISDM',file_url='https://www.cis.fordham.edu/wisdm/includes/datasets/latest/WISDM_ar_latest.tar.gz', dataset_dir=dataset_dir
)
- 数据清洗与读取:
- 从指定路径的文本文件中读取原始数据,该文件包含了多个以逗号分隔的条目。
- 清洗数据,移除不完整的条目,确保每行数据都包含参与者ID、活动标签和三个传感器信号。
- 将清洗后的数据转换为NumPy数组,便于后续处理。
- 标签编码:
- 使用
category_dict字典,将活动标签的字符串表示(如’Walking’、'Jogging’等)映射为整数ID,以便于机器学习模型处理。
- 滑窗处理:
- 对清洗并编码后的数据应用滑窗分割,生成固定大小的样本窗口。这些窗口将用于训练和测试机器学习模型。
- 分割数据集:
- 根据是否提供了
VALIDATION_SUBJECTS,选择留一法或平均法来分割数据集。留一法是为每个参与者ID分别创建训练集和测试集,而平均法则是按照SPLIT_RATE比例分割数据。
- 数据整合:
- 将分割后的数据和标签分别整合到
xtrain、xtest、ytrain、ytest列表中,这些列表将包含所有训练和测试数据。
- 标准化处理:
- 如果
Z_SCORE参数为True,则对整合后的xtrain和xtest进行Z分数标准化处理,以消除不同传感器信号量级的影响。
- 数据保存:
- 如果提供了
SAVE_PATH,则使用save_npy_data函数将预处理后的训练集和测试集数据保存为.npy格式的文件,这有助于后续加载和使用数据。
准备WISDM数据集,使其适合用于CNN网络模型的训练和测试。通过滑窗处理,可以将原始的长时间序列传感器数据转换为固定大小的短时间序列数据,这有助于训练卷积神经网络等模型进行人类活动识别。此外,通过留一法或平均法分割数据集,可以为模型提供训练集和验证集,以评估模型性能。最后,通过Z分数标准化,可以提高模型对数据分布变化的鲁棒性。
四、CNN网络训练WISDM数据集
1.常用的仿真指标
1.1 准确率 (Accuracy)
准确率是所有正确预测样本数占总样本数的比例。它是最直观的性能指标,计算公式如下:
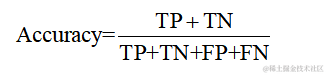
1.2 精确率 (Precision)
精确率是所有预测为正类中真正为正类的比例,它关注的是预测为正类的结果的准确性。计算公式如下:
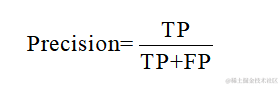
1.3 召回率 (Recall)
召回率是所有实际为正类中被正确预测为正类的比例,它衡量的是模型捕捉正类样本的能力。计算公式如下:
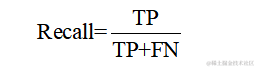
1.4 F1分数 (F1-Score)
F1分数是精确率和召回率的调和平均值,它在两者之间取得平衡,是评价分类模型性能的一个重要指标。计算公式如下:

1.5 参数量 (Parameters)
参数量指的是网络模型中需要训练的参数总数。参数量越多,模型的容量越大,但也越容易过拟合。
1.6 推理时间 (Inference Time)
推理时间指的是模型对数据进行预测的时间。它可以是单个样本的推理时间,也可以是整个数据集推理所需的总时间。推理时间是评估模型在实际应用中效率的重要指标,尤其是在需要实时响应的应用场景中。
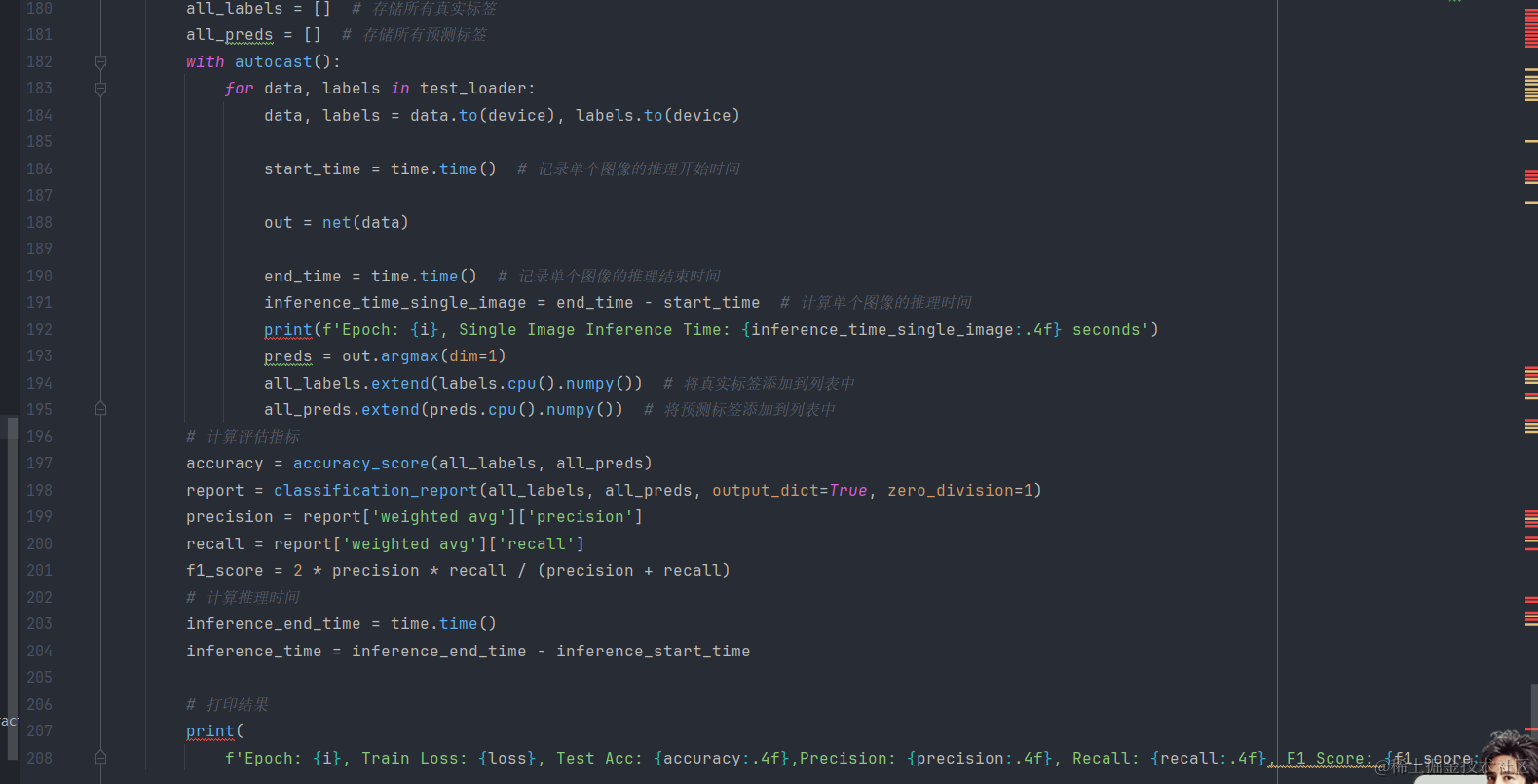
2.具体的训练过程
1.数据集加载
根据选择的数据集和模型,加载数据集,并进行必要的预处理。
2.模型实例化
根据选择的模型,实例化一个模型对象,并将其移动到选定的设备上。
3.创建数据加载器
使用DataLoader创建训练和测试数据的加载器,允许在训练中以小批量方式加载数据。
4.优化器和学习率调度器设置
定义了AdamW优化器和学习率调度器,用于在训练过程中更新模型参数和调整学习率。
5.混合精度训练设置
实例化GradScaler对象,用于在训练中使用混合精度,可以提高训练效率和精度。
6.训练循环
对于每个训练轮次,执行以下步骤:
- 设置模型为训练模式。
- 在每个小批量数据上执行前向传播、计算损失、执行反向传播并更新模型参数。
- 学习率调度器步进。
- 设置模型为评估模式。
- 在测试集上进行预测,并计算模型的准确率、精确率、召回率和F1分数。
- 打印每个轮次的训练损失、测试准确率和其他评估指标。
for i in range(EP):net.train()inference_start_time = time.time()for data, label in train_loader:data, label = data.to(device), label.to(device)# 前向过程(model + loss)开启 autocast,混合精度训练with autocast():out = net(data)loss = loss_fn(out, label)optimizer.zero_grad() # 梯度清零scaler.scale(loss).backward() # 梯度放大scaler.step(optimizer) # unscale梯度值scaler.update()lr_sch.step()
3.结果展示
在每个训练轮次结束时,打印出当前轮次的训练信息和模型评估指标。
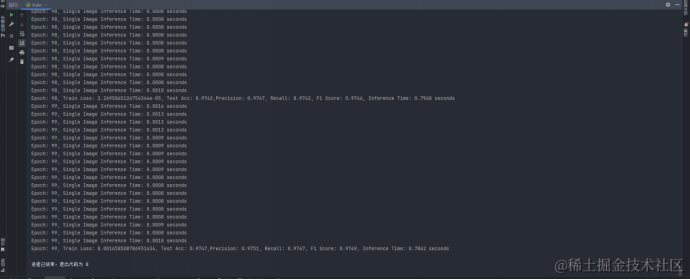
从训练结果中可以看出,基于CNN网络训练得到的以上六种指标数据分别为:
| CNN | 0.9729 | 0.9734 | 0.9729 | 0.9732 | 528390 | 0.0008 0.7563 |
|---|
五、可视化维度分析
将CNN网络训练WISDM数据集的结果进行可视化维度分析:
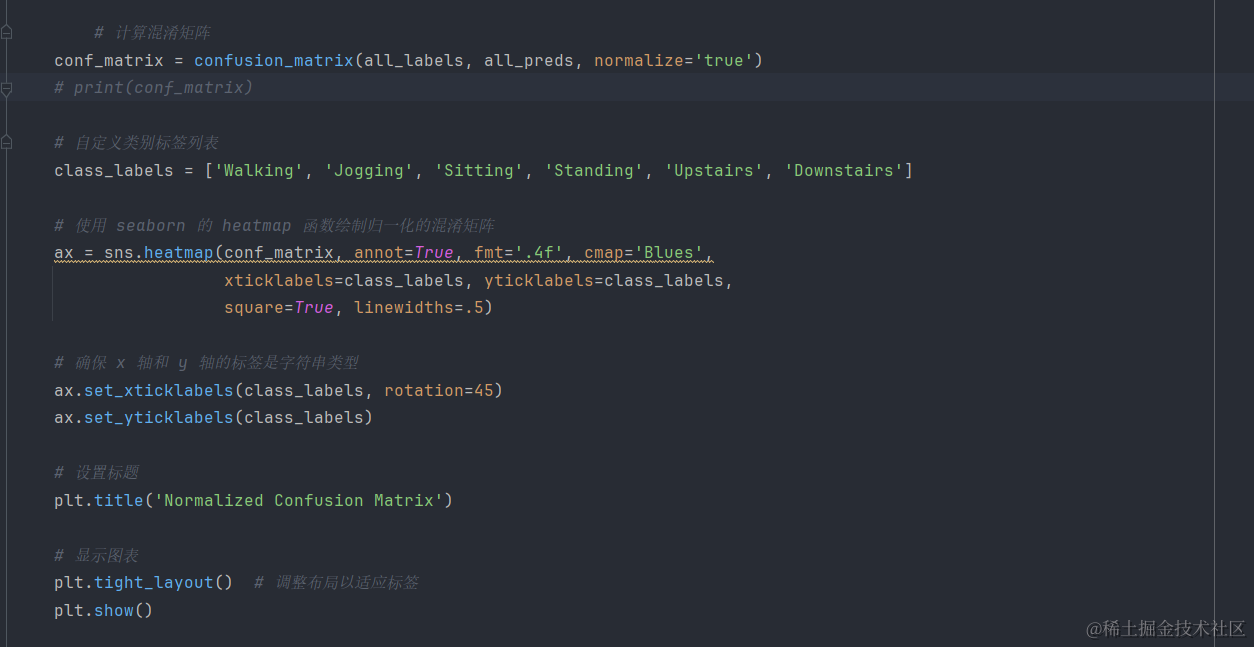
1.混淆矩阵图
混淆矩阵是一个N×N的矩阵,N代表的是你的分类标签个数。混淆矩阵的横纵坐标轴分别为模型预测值和真实值,在图中纵轴是真实值而横轴代表模型预测值。
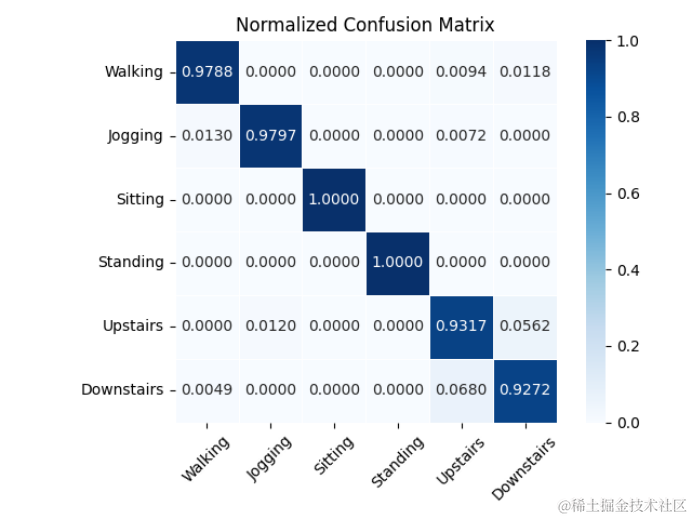
2.雷达图
雷达图可以反映多个行为的某个指标值映射在坐标轴上,可以更直观的观察出每个行为的指标值大小。
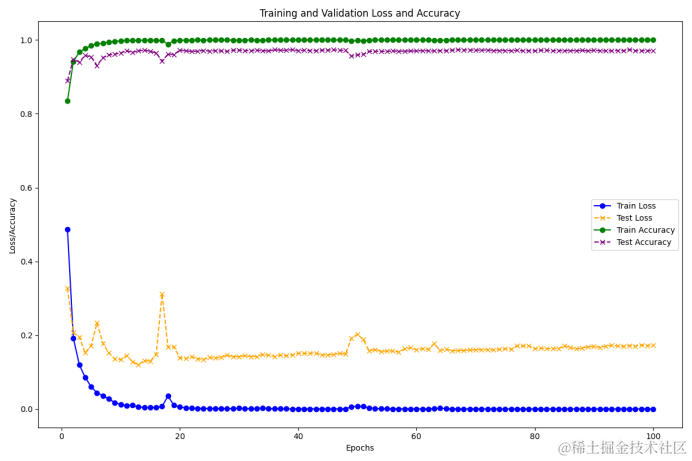
3.准确率和损失率的收敛曲线图
准确率和损失率的收敛曲线图横坐标是训练轮次,纵坐标是模型的准确率以及损失率,这个图可以直观的看出你的模型在训练以及测试过程中的准确率和损失率走向和模型收敛以后的准确率的数值范围,也可以反映出你的模型在训练过程中是否稳定。
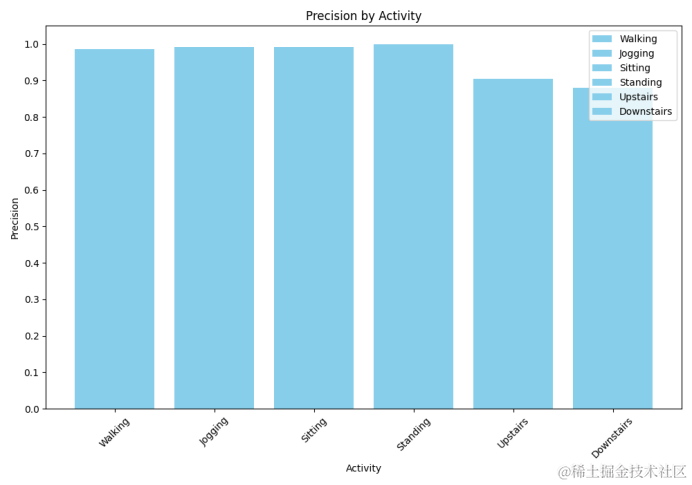
4.仿真指标柱状图
仿真指标柱状图是一种以长方形的长度为变量来表示各个行为的指标值,例如可以表示你的模型在WISDM数据集中的每个行为精确率的值,通过由一系列高度不等的纵向条纹表示数据分布的情况。
5.仿真指标折线图
仿真指标折线图是一种用来表示超参数设置大小对模型效果影响的可视化方式,可以表示我们的CNN网络模型在WISDM数据集中Batch size对加权F1分数的影响。

六、总结
在本研究中,我们深入探讨了卷积神经网络(CNN)在处理WISDM数据集时的应用,该数据集是一个用于人类活动识别(HAR)的公共数据集。通过一系列数据处理步骤,我们将原始的长时间序列传感器数据转换为适合CNN模型训练的固定大小的短时间序列数据。此外,我们还介绍了CNN的核心思想、优点、缺点以及基本的网络结构,并通过可视化方法对训练结果进行了全面的分析。
通过本研究,我们证明了CNN在处理时间序列数据和人类活动识别任务中的有效性。未来的工作可以探索更先进的网络结构和训练策略,以进一步提高模型的性能和应用范围。







