最近在家过年闲的没事,于是研究起深度学习开发工具链的配置和安装,之前欲与天公试比高,尝试在win上用vscode+cuda11.6+vs2019的cl编译器搭建cuda c编程环境,最后惨败,沦为笑柄,痛定思痛,这次直接和cl编译器离的远远的。
安装WSL+vscode工作链
首先是已经安装好了wsl2,wsl是windows下的Linux子系统,特别好用相当于集齐了linux的开源架构特点和win中的图形化界面(我安装wsl2后,下载的是ubuntu 22.04LTS版本)。直接可以在命令行启动,或者也可以在vscode中安装一个插件。
wsl安装命令如下(来自deepseek,不保证完全可行)
wsl --install
wsl --list --online
wsl --install -d Ubuntu
正是该传奇插件,安装好后,就可以通过remote SSH直连WSL2,相当于借鸡生蛋,只是借用了个windows中的vscode的图形化界面,操作的还是Linux中的东西。

这里可以看到打开的终端对应的是linux中的bash shell。
安装cuda11.7
然后就是安装cuda11.7(之所以选择cuda11.7是因为cuda11.7比较完善,而且GPU Invida3060以上就能支持),大概的安装命令就是问deepseek就行了,deepseek给出的安装办法如下:
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-11-7-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda安装好后还需要配置环境变量,要配置bin和lib64的,这里我的配置方法如下:
首先:
vim ~/.bashrc其次:
export PATH=/usr/local/cuda-11/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}保存并退出后:
source ~/.bashrc随后检验一下用如下命令:
nvcc --version搭建cuda c编程环境并检验
要建设cuda c编程环境还要再安装个gcc编译器包(不确定,不安可能也行),安装好后,在工作目录新建一个test.cu。
#include <stdio.h>
#include <cuda_runtime.h>// CUDA 核函数,用于向量加法
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements) {int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < numElements) {C[i] = A[i] + B[i];}
}int main() {// 定义向量大小int numElements = 50000;size_t size = numElements * sizeof(float);// 分配主机内存float *h_A = (float *)malloc(size);float *h_B = (float *)malloc(size);float *h_C = (float *)malloc(size);// 初始化主机数据for (int i = 0; i < numElements; ++i) {h_A[i] = rand() / (float)RAND_MAX;h_B[i] = rand() / (float)RAND_MAX;}// 分配设备内存float *d_A, *d_B, *d_C;cudaMalloc((void **)&d_A, size);cudaMalloc((void **)&d_B, size);cudaMalloc((void **)&d_C, size);// 将数据从主机复制到设备cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);// 定义线程块和网格大小int threadsPerBlock = 256;int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;// 启动 CUDA 核函数vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);// 将结果从设备复制回主机cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// 验证结果for (int i = 0; i < numElements; ++i) {if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) {fprintf(stderr, "Result verification failed at element %d!\n", i);exit(EXIT_FAILURE);}}printf("Test PASSED\n");// 释放设备内存cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);// 释放主机内存free(h_A);free(h_B);free(h_C);return 0;
}然后在终端中输入如下命令
nvcc -o test test.cu
./test结果如下,上面的命令是先编译.cu文件然后再运行编译后的生成。

搭建pytorch深度学习开发环境
这里就稍微麻烦一些了,首先要确保安装了anaconda,conda是专门的为Python虚拟环境的搭建而服务的,安装命令如下:
wget https://repo.anaconda.com/miniconda/Miniconda3-py38_4.9.2-Linux-x86_64.sh
bash Miniconda3-py38_4.9.2-Linux-x86_64.sh
conda init
随后新建python3.8的虚拟环境并启动
conda create --name myenv python=3.8
conda activate myenv
确保是在虚拟环境中去安装pytorch,这里安装的是pytorch2.0.1,具体安装的时候我犯了好几次错误,实际上问ai让ai来换源是不可行的,ai换的源总是有问题,但是不换源又下的太慢,这里的解决办法是用梯子魔法+pip来安装(实测发现pip安装比conda安装要快一些),具体安装命令如下:
Previous PyTorch Versions | PyTorch是在这个安装历史版本中找的命令。
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
安装完成后的验证代码如下:
import torchprint(torch.__version__)
print(torch.cuda.is_available())
安装cudnn
cudnn是英伟达专门开发的cuda neural network库,安装命令如下:
wget https://developer.download.nvidia.com/compute/cudnn/9.7.0/local_installers/cudnn-local-repo-ubuntu2204-9.7.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2204-9.7.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2204-9.7.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnncuDNN 9.7.0 Downloads | NVIDIA Developer
但是有个问题我是不太清楚,我安装的是cudnn的9.7.0但是跑下面的验证代码的时候却告诉我cudnn是8.5.00
import torch# 检查 PyTorch 版本
print(torch.__version__)# 检查 CUDA 是否可用
print(torch.cuda.is_available())# 检查 cuDNN 版本
print(torch.backends.cudnn.version())# 检查当前 GPU 设备
print(torch.cuda.current_device())# 检查 GPU 名称
print(torch.cuda.get_device_name(0))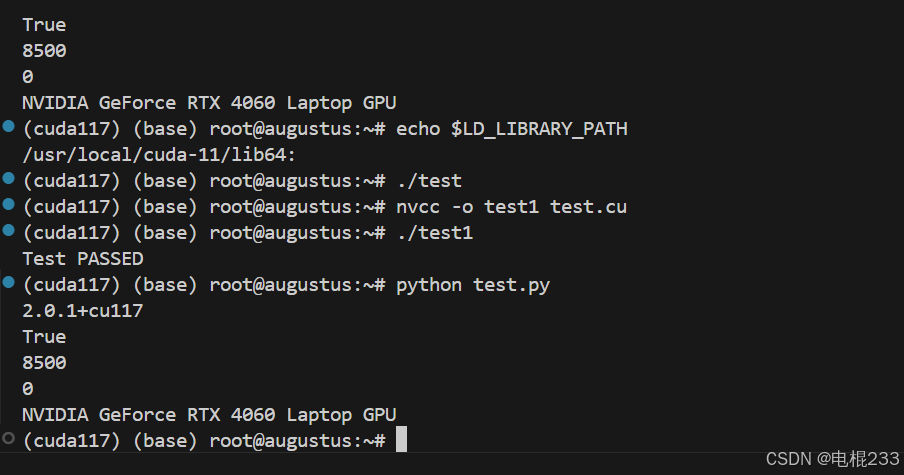
总结
环境配置是电信技术中的集大成者,我本人也不是很懂,经常失败是很正常的。但是千万记得,不要直接去下载国外网站大文件,否则下载失败再重来会是很痛苦的。



![[Python学习日记-80] 用 socket 实现文件传输功能(上传下载)](https://i-blog.csdnimg.cn/direct/e369f5917db641b6a7215145da459cf8.png)
