1.概述
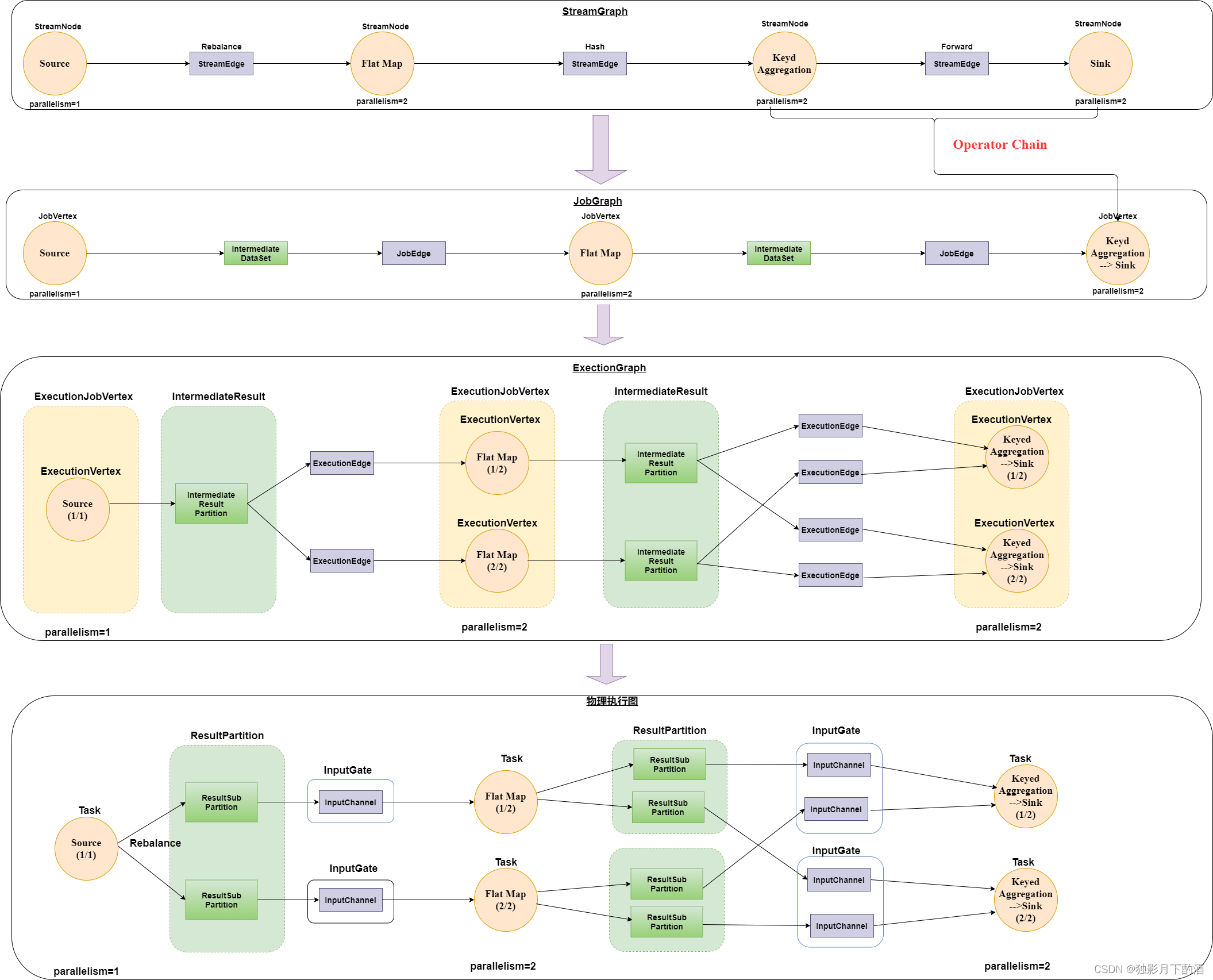
Flink 集群中运行的 Job,最终归根到底:还是构建一个高效能分布式并行执行的DAG执行图。一个 Flink 流式作业从 Client 提交到 Flink 集群到最后执行,总共经历 4 种状态,总体来说:Flink中的执行图可分成四层:StreamGraph ==> JobGraph ==> ExecutionGraph ==> 物理执行图。
-
StreamGraph: 根据用户通过Stream API 编写的代码生成最初的图,用来表示程序的拓扑结构。
-
JobGraph: StreamGraph 经过优化之后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为:将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需的序列化与反序列化传输消耗。
-
ExecutionGraph: JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
-
物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager上部署Task后形成的图,并不是一个具体的数据结构。
2.StreamGraph构建和提交源码解析

**StreamGraph:根据用户编写 Stream API 编写的代码生成的最初的图。**Flink 将每一个算子 transform 成一个对流的转换,并且注册到执行环境中,用于生成StreamGraph。它包含的主要抽象概念有:
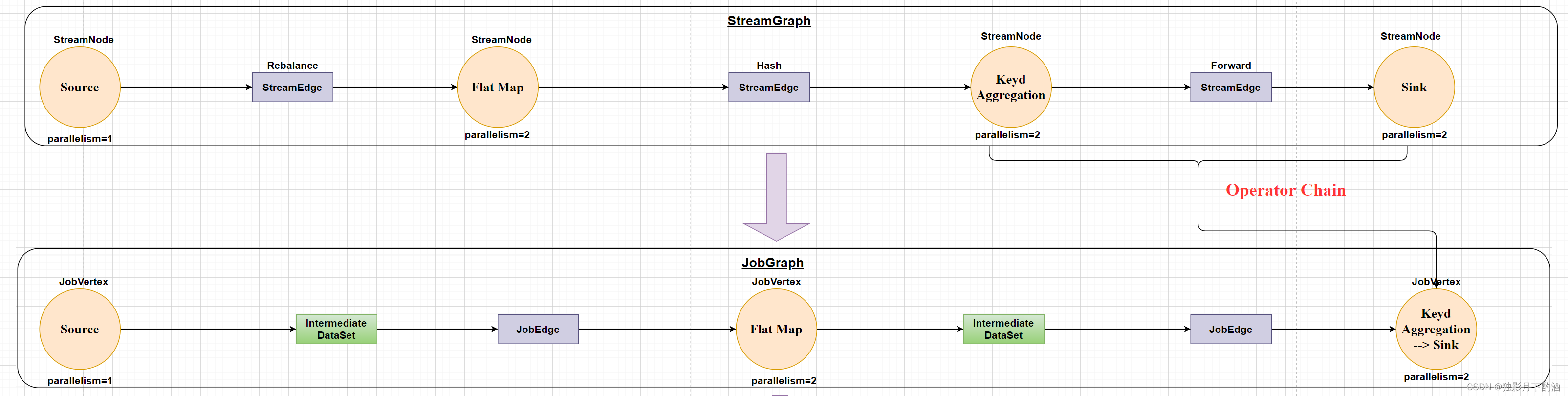
- StreamNode: 用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
- StreamEdge: 表示链接两个StreamNode的边。
源码核心入口:
StreamExecutionEnvironment.execute(getStreamGraph(jobName));
StreamGraph 先生成一个 StreamGraphGenerator,随后调用 generate() 方法生成一个StreamGraph,StreamExecutionEnvironment.execute() 用于执行一个StreamGraph。
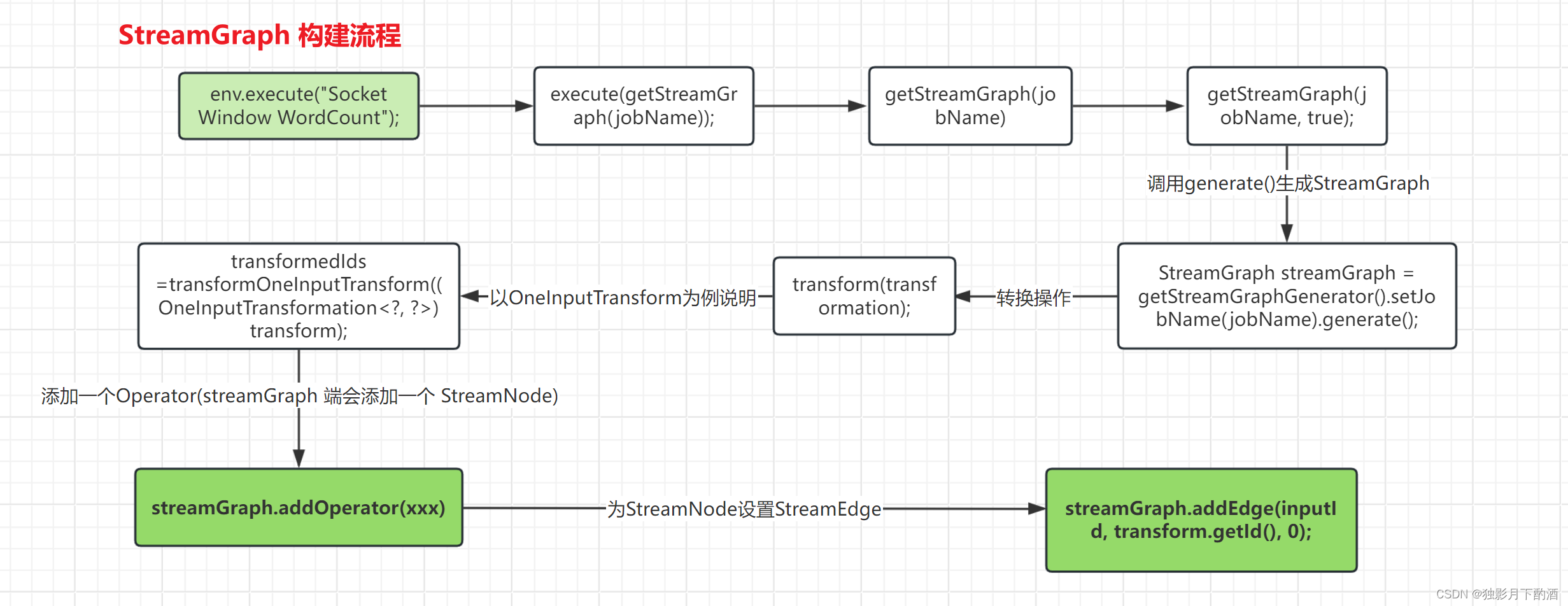
StreamGraph生成过程中,StreamNode的代码入口:
// 注释:添加一个 Operator(streamGraph 端会添加一个 StreamNode)streamGraph.addOperator(transform.getId(),slotSharingGroup,transform.getCoLocationGroupKey(),transform.getOperatorFactory(),transform.getInputType(),transform.getOutputType(),transform.getName());
StreamGraph生成过程中,StreamEdge的代码入口:
for (Integer inputId: inputIds) {
//注释:根据输入的 id,给这个 node 在 graph 中设置相应的 graphstreamGraph.addEdge(inputId, transform.getId(), 0);
}
3.JobGraph 构建和提交源码解析
JobGraph :StreamGraph 经过优化之后生成了 JobGraph,提交给 JobManager 的数据结构。
它包含的主要抽象概念有:
- JobVertex: 经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 JobVertex,即一个 JobVertex 包含一个或者多个 operator,JobVertex 的输入是 JobEdge,输出是IntermediateDataSet。
- IntermediateDataSet: 表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是 JobVertex,consumer 是 JobEdge。
- JobEdge: 表示 job graph 中的一条数据的传输通道。输入 IntermediateDataSet,输出是 JobVertex。即数据是通过 JobEdge 由 IntermediateDataSet 传递给目标 JobVertex。
源码核心代码入口:
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
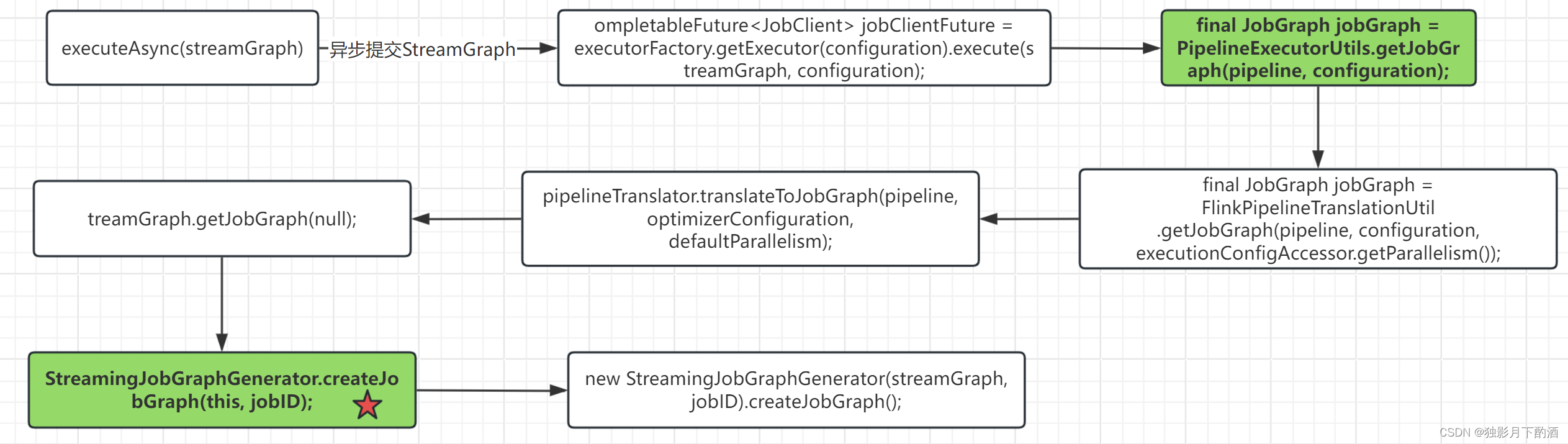
private JobGraph createJobGraph() {preValidate();// make sure that all vertices start immediatelyjobGraph.setScheduleMode(streamGraph.getScheduleMode());// Generate deterministic hashes for the nodes in order to identify them across// submission iff they didn't change.Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);// Generate legacy version hashes for backwards compatibilityList<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());for (StreamGraphHasher hasher : legacyStreamGraphHashers) {legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));}setChaining(hashes, legacyHashes);setPhysicalEdges();setSlotSharingAndCoLocation();setManagedMemoryFraction(Collections.unmodifiableMap(jobVertices),Collections.unmodifiableMap(vertexConfigs),Collections.unmodifiableMap(chainedConfigs),id -> streamGraph.getStreamNode(id).getMinResources(),id -> streamGraph.getStreamNode(id).getManagedMemoryWeight());configureCheckpointing();jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());JobGraphUtils.addUserArtifactEntries(streamGraph.getUserArtifacts(), jobGraph);// set the ExecutionConfig last when it has been finalizedtry {jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());}catch (IOException e) {throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +"This indicates that non-serializable types (like custom serializers) were registered");}return jobGraph;}
在 StreamGraph 构建 JobGraph 的过程中,最重要的事情就是是否能构建 OperatorChain?
1.上下游的入度为1(即为下游节点没有来自其他节点的输入)
downStreamVertex.getInEdges().size() == 1
2.上下游节点在同一个 slot group 中
upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
3.前后算子不为空
!(downStreamOperator == null || upStreamOperator == null)
4.上游节点的 chain 策略为 ALWAYS 或者 HEAD(只能与下游连接,不能与上游连接,source默认为HEAD)
upStreamOperator.getChainingStrategy() != ChainingStrategy.NEVER
5.下游节点的 chain 策略为 ALWAYS(可以与上游连接,map、flatmap、filter等默认是ALWAYS)
downStreamOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
6.两个节点之间物理分区的逻辑是 ForwardPatitioner(数据从上游直接下游)
edge.getPartitioner() instanceof ForwardPartitioner
7.两个算子之间的shuffle方式不等于批处理模式
edge.getShuffleMode() != ShuffleMode.BATCH
8.上下游的并行度一致
upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
9.用户没有禁用 chain
streamGraph.isChainingEnabled()
4.ExecutionGraph 构建和提交源码解析
ExecutionGraph:JobManager(JobMaster) 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度底层最核心的数据结构。
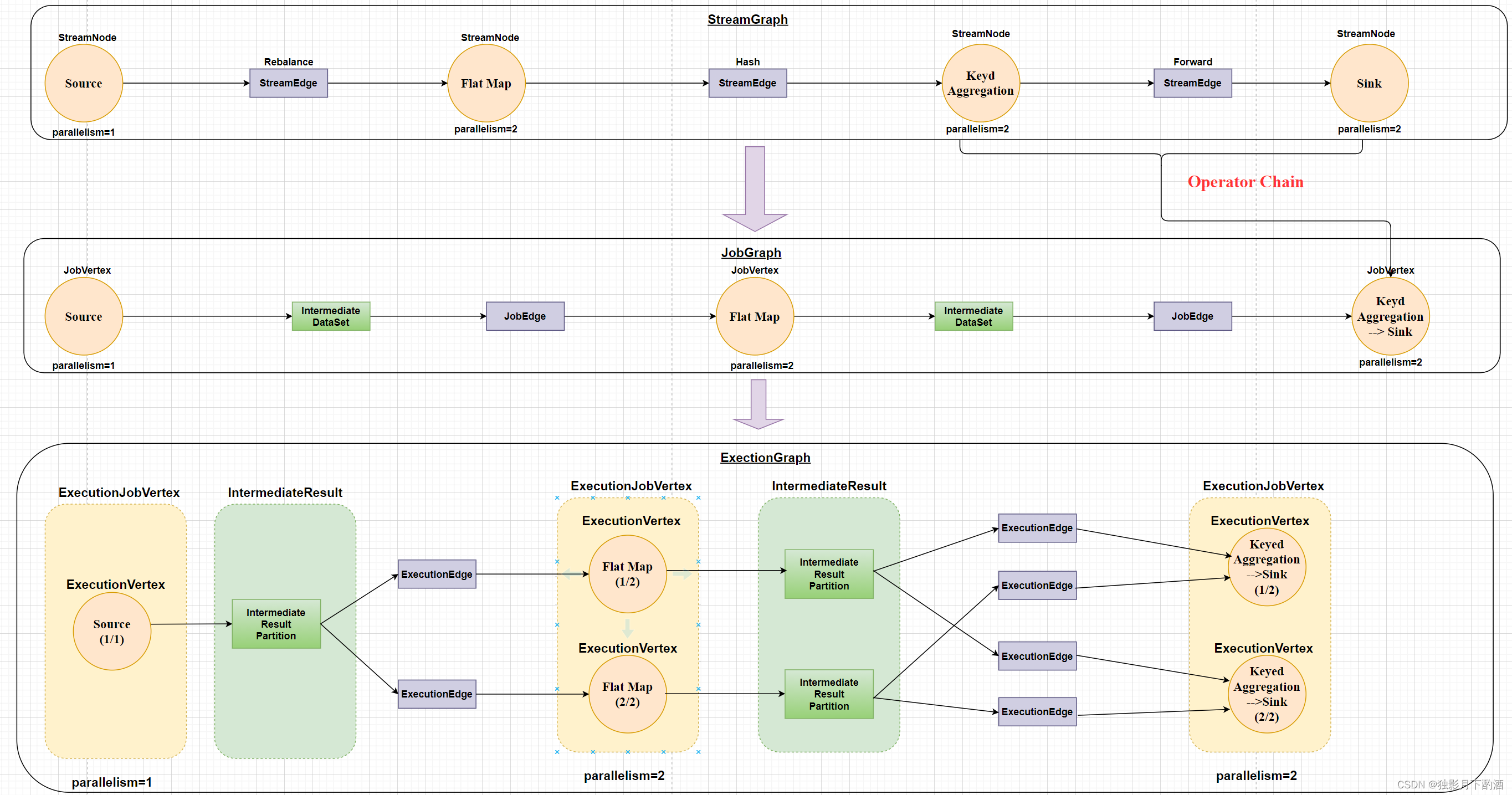
它包含的抽象概念:
-
ExecutionJobVertex: 与 JobGraph 中的 JobVertex 一一对应。每一个 ExecutionJobVertex 都有和并发度一样的 ExecutionVertex。
-
ExecutionVertex: 表示 ExecutionJobVertex 的其中一个并发子任务,输入是 Executiondge,输出是 IntermediateResultPartition。
-
IntermediateResult: 和 JobGraph 中的 IntermediateDataSet 一一对应。一个
IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
-
IntermediateResultPartition: 表示ExecutionVertex的一个输出分区,输入是
ExecutionVertex,输出是若干个ExecutionEdge。
-
ExecutionEdge: 表示ExecutionVertex的输入,source是IntermediateResultPartition,
target是ExecutionVertex。source和target都只能是一个。
源码核心代码入口:
ExecutionGraph executioinGraph = SchedulerBase.createAndRestoreExecutionGraph()
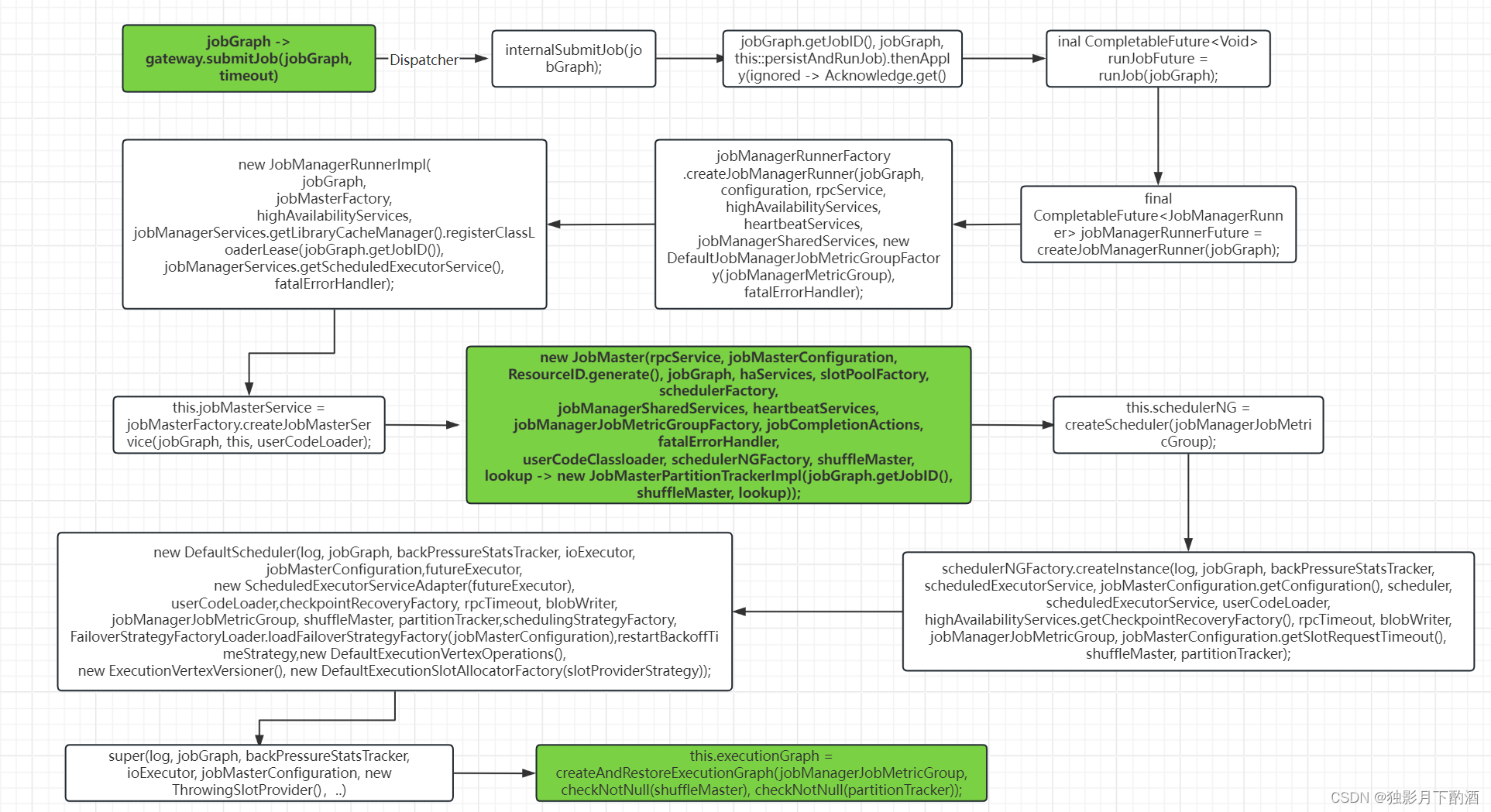
在 SchedulerBase 这个类的内部,有两个成员变量:一个是 JobGraph,一个是 ExecutioinGraph 在创建 SchedulerBase 的子类:DefaultScheduler 的实例对象的时候,会在 SchedulerBase 的构造 方法中去生成 ExecutionGraph。
SchedulerBase 类的源码如下:
public SchedulerBase(final Logger log, final JobGraph jobGraph, final BackPressureStatsTracker backPressureStatsTracker,final Executor ioExecutor, final Configuration jobMasterConfiguration, final SlotProvider slotProvider,final ScheduledExecutorService futureExecutor, final ClassLoader userCodeLoader, final CheckpointRecoveryFactory checkpointRecoveryFactory,final Time rpcTimeout, final RestartStrategyFactory restartStrategyFactory, final BlobWriter blobWriter,final JobManagerJobMetricGroup jobManagerJobMetricGroup, final Time slotRequestTimeout, final ShuffleMaster<?> shuffleMaster,final JobMasterPartitionTracker partitionTracker, final ExecutionVertexVersioner executionVertexVersioner,final boolean legacyScheduling) throws Exception {this.log = checkNotNull(log);// jobGraphthis.jobGraph = checkNotNull(jobGraph);this.backPressureStatsTracker = checkNotNull(backPressureStatsTracker);this.ioExecutor = checkNotNull(ioExecutor);this.jobMasterConfiguration = checkNotNull(jobMasterConfiguration);this.slotProvider = checkNotNull(slotProvider);this.futureExecutor = checkNotNull(futureExecutor);this.userCodeLoader = checkNotNull(userCodeLoader);this.checkpointRecoveryFactory = checkNotNull(checkpointRecoveryFactory);this.rpcTimeout = checkNotNull(rpcTimeout);final RestartStrategies.RestartStrategyConfiguration restartStrategyConfiguration = jobGraph.getSerializedExecutionConfig().deserializeValue(userCodeLoader).getRestartStrategy();this.restartStrategy = RestartStrategyResolving.resolve(restartStrategyConfiguration, restartStrategyFactory, jobGraph.isCheckpointingEnabled());if(legacyScheduling) {log.info("Using restart strategy {} for {} ({}).", this.restartStrategy, jobGraph.getName(), jobGraph.getJobID());}this.blobWriter = checkNotNull(blobWriter);this.jobManagerJobMetricGroup = checkNotNull(jobManagerJobMetricGroup);this.slotRequestTimeout = checkNotNull(slotRequestTimeout);this.executionVertexVersioner = checkNotNull(executionVertexVersioner);this.legacyScheduling = legacyScheduling;// executionGraphthis.executionGraph = createAndRestoreExecutionGraph(jobManagerJobMetricGroup, checkNotNull(shuffleMaster), checkNotNull(partitionTracker));this.schedulingTopology = executionGraph.getSchedulingTopology();this.inputsLocationsRetriever = new ExecutionGraphToInputsLocationsRetrieverAdapter(executionGraph);this.coordinatorMap = createCoordinatorMap();}
ExecutionGraph构建源码
/***this.executionGraph = createAndRestoreExecutionGraph(xx);* --> ExecutionGraph newExecutionGraph = createExecutionGraph(xxx)* --> ExecutionGraphBuilder.buildGraph(xx)*/
public static ExecutionGraph buildGraph(xxxx){//1.创建 ExecutionGraph 对象executionGraph = (prior != null) ? prior : new ExecutionGraph(...);//2.生成 JobGraph 的 JSON 表达形式executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));//3.从 JobGraph 构建 ExecutionGraphexecutionGraph.attachJobGraph(sortedTopology);//4.返回 ExecutionGraphreturn executionGraph;
}
===============================attachJobGraph========================================
public void attachJobGraph(List<JobVertex> topologiallySorted) throws JobException {//1.遍历 JobVertex 执行并行化生成 ExecutioinVertexfor (JobVertex jobVertex : topologiallySorted) {if (jobVertex.isInputVertex() && !jobVertex.isStoppable()) {this.isStoppable = false;}// 每一个 JobVertex 对应到一个 ExecutionJobVertexExecutionJobVertex ejv = new ExecutionJobVertex(this,jobVertex,1,maxPriorAttemptsHistoryLength,rpcTimeout,globalModVersion,createTimestamp);// 刚方法内部设置并行度ejv.connectToPredecessors(this.intermediateResults);ExecutionJobVertex previousTask = this.tasks.putIfAbsent(jobVertex.getID(), ejv);if (previousTask != null) {throw new JobException(String.format("Encountered two job vertices with ID %s : previous=[%s] / new=[%s]",jobVertex.getID(), ejv, previousTask));}// 设置 IntermediateResult 对象for (IntermediateResult res : ejv.getProducedDataSets()) {IntermediateResult previousDataSet = this.intermediateResults.putIfAbsent(res.getId(), res);if (previousDataSet != null) {throw new JobException(String.format("Encountered two intermediate data set with ID %s : previous=[%s] / new=[%s]",res.getId(), res, previousDataSet));}}this.verticesInCreationOrder.add(ejv);this.numVerticesTotal += ejv.getParallelism();newExecJobVertices.add(ejv);}}
===================================ejv.connectToPredecessors=========================public void connectToPredecessors(Map<IntermediateDataSetID, IntermediateResult> intermediateDataSets) throws JobException {List<JobEdge> inputs = jobVertex.getInputs();if (LOG.isDebugEnabled()) {LOG.debug(String.format("Connecting ExecutionJobVertex %s (%s) to %d predecessors.", jobVertex.getID(), jobVertex.getName(), inputs.size()));}for (int num = 0; num < inputs.size(); num++) {JobEdge edge = inputs.get(num);if (LOG.isDebugEnabled()) {if (edge.getSource() == null) {LOG.debug(String.format("Connecting input %d of vertex %s (%s) to intermediate result referenced via ID %s.",num, jobVertex.getID(), jobVertex.getName(), edge.getSourceId()));} else {LOG.debug(String.format("Connecting input %d of vertex %s (%s) to intermediate result referenced via predecessor %s (%s).",num, jobVertex.getID(), jobVertex.getName(), edge.getSource().getProducer().getID(), edge.getSource().getProducer().getName()));}}// fetch the intermediate result via ID. if it does not exist, then it either has not been created, or the order// in which this method is called for the job vertices is not a topological orderIntermediateResult ires = intermediateDataSets.get(edge.getSourceId());if (ires == null) {throw new JobException("Cannot connect this job graph to the previous graph. No previous intermediate result found for ID "+ edge.getSourceId());}this.inputs.add(ires);int consumerIndex = ires.registerConsumer();for (int i = 0; i < parallelism; i++) {ExecutionVertex ev = taskVertices[i];ev.connectSource(num, ires, edge, consumerIndex);}}}
5.物理执行图
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署Task 后形成的“图”,并不是一个具体的数据结构。
它包含的主要抽象概念有:
-
1、Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行 逻辑的 operator。
-
2、ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的 IntermediateResultPartition一一对应。
-
3、ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个 ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
-
4、InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或 多个的ResultPartition。
-
5、InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的 ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个 ResultSubpartition的输出。
6.总结
- Flink Graph的演变:StreamGraph ==> JobGraph ==> ExecutionGraph ==> 物理执行图。
- StreamGraph: 根据用户通过Stream API 编写的代码生成最初的图,用来表示程序的拓扑结构。
- JobGraph(优化): StreamGraph 经过优化之后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为:将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需的序列化与反序列化传输消耗。
- ExecutionGraph(并行化): JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
- 物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager上部署Task后形成的图,并不是一个具体的数据结构。