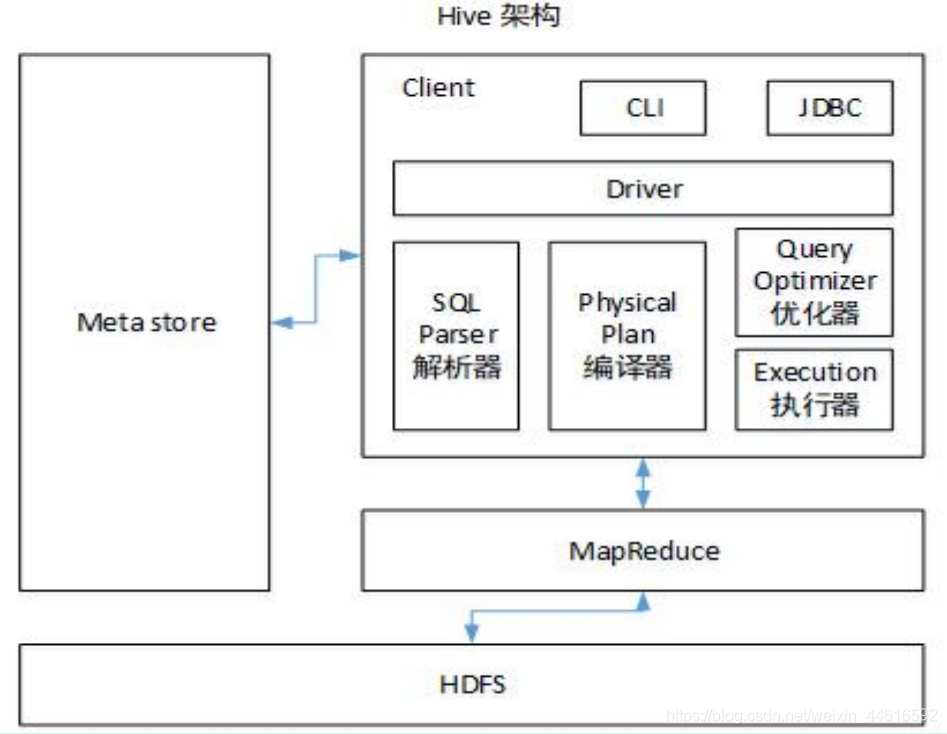
注意:
1.Hive处理的数据存储在HDFS上
2.hive分析数据的底层处理逻辑是MapReduce
3.执行运行在Yarn上执行
Hive运行原理

Hive为什么要分区(partitioned by)?
随着系统运行时间越来越长,表的数据量不断增大,通过hive查询通常是"全表扫描"这样就会出现数据量过大,全表扫描时间过长,会造成查询效率更加低下
Hive中分区就是分目录 ,把一个大的数据集根据业务需求分隔成小的数据集,在查询的时候where子句中的表达式选择需要查询的分区,这样就可以提高效率
通过对表进行分区,避免hive进行全表扫描,这样可以提高查询效率
hive的分区对应HDFS文件系统上独立的文件夹,该文件夹下是该分区所有的数据文件
其实Hive中分区就是分目录 ,把一个大的数据集根据业务需求分隔成小的数据集,在查询的时候where子句中的表达式选择需要查询的分区,这样就可以提高效率
Hive与mysql的对比
数据存储位置:Hive的数据都存储在HDFS上,数据库是保存在设备或本地文件系统中
搜索引擎:Hive 搜索引擎是MR,数据库通常有自己的搜索引擎
执行延迟:Hive没有索引,需要全表扫描,因此延迟高。数据库小数据处理延迟较低,但处理大数据能力不如hive
扩展性:Hive基于hadoop扩展性高,数据库由于ACID语义限制,扩展非常有限,即使Oracle也只有100台左右
Hive内部表和外部表
1.内部表(管理表):当删除一个内部表时,hive也会删除这个表中的数据。内部表不适合和其他工具共享数据
2.外部表:删除该表并不会删除掉原始数据,删除的是表的元数据
hive_62">hive数据类型
hive数据类型分两种基础数据类型和复杂数据类型
基础数据类型包括
| 基础数据类型 | 长度 |
|---|---|
| TINYINT | 1byte有符号整数 |
| SMALINT | 2byte有符号整数 |
| INT | 3byte有符号整数 |
| BIGINT | 4byte有符号整数 |
| BOOLEAN | 布尔类型,true或false |
| FLOAT | 单精度浮点 |
| DOUBLE | 双精度浮点 |
| STRING | 字符序列 |
| TIMESTAMP | 整数,浮点数或者字符串 |
| BINARY | 字节数组 |
复杂数据类型
| 复杂数据类型 | 字面语法示例 |
|---|---|
| STRUCT | Struct(‘John’,’Doe’) |
| MAP | Map(‘first’,’JOIN’,’last’,’Doe’) |
| ARRAY | Array(‘John’,’Doe’) |
hive_97">hive数据存格式
textfile 普通的文本文件存储,不会压缩
sequencefile 二进制存储格式,本身即是压缩格式,不能使用load进行数据加载
orcfile 行列混合存储,hive在该格式下,会尽量将附近的列和行的块存在一起,仍然是压缩格式,查询效率比较高
自定义函数UDF和UDTF
UDF通常是一个输入对应一个输出,应用场景有:根据身份证号判断该用户年龄自定义UDF需要继承UDF并重写evaluate方法
UDTF为一个输入多个输出,应用场景有:根据登录的信息拆分成多个字段输出继承GenericUDTF,重写实现initialize(定义输出参数的名字和类型), process, close三个方法,用来解析事件字段
自定义函数相比json解析:自定义函数方便定位错误

造成数据倾斜的情况:
1)、key分布不均匀
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜join语句造成、count(distinct col)造成、group by造成数据倾斜
解决方案:
1.分区、分桶也是hive优化的一种
2.group by操作是否允许数据倾斜,默认是false,当设置为true时,执行计划会生成两个map/reduce作业,第一个MR中会将map的结果随机分布到reduce中,达到负载均衡的目的来解决数据倾斜。(建议开启)
hive.groupby.skewindata=false/true
3.开启数据倾斜的join优化,hive.optimize.skewjoin=false/true默认不开启false(建议开启)
特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去

Hive的优化
- 设置Map端join:
如果不指定Mapjoin或者不符合Mapjoin的条件,Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join,容易发生数据倾斜。可以用Mapjoin把小表全部加载到内存在map端进行join,避免reducer处理。
- 行列过滤
列处理:尽量使用分区过滤器,少用select * ,“ * ”代表所有字段,底层处理会将所有字段在内存罗列出来,会占用大量的计算资源
行处理:在分区裁剪中,当使用外连接时,如果将副标的过滤条件写在where后面,就会先进行全表关联再过滤,正确的写法时写在on后面,或者直接写成子查询。
- 采用分区、分桶
分区的目的是避免进行全表扫描,当分区中数据量依然很大,每次查询都会在当前区中进行全表查询也会很慢,这时需要进行分桶操作来提高查询效率
- 自动或手动决定mapTask的大小(可以有效的减少mapTask的个数)和reduce的个数
MapTask默认大小为128M,MapTask的个数并不是越多越好,maptask是会消耗内存资源的,如果maptask过多启动和初始化的时间会超过逻辑计算的时间
- 设置每个reduce任务处理数据的量,(默认为一个Reduce)以及reduce的数量
- 小文件合并:
在map执行前合并小文件,减少Map数:CombineHiveInputFormat具有小文加合并功能,HiveInputFormat没有对小文件的合并功能
7. jvm重用
(缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,直到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源)
- hive-site.xml的配置文件中设置
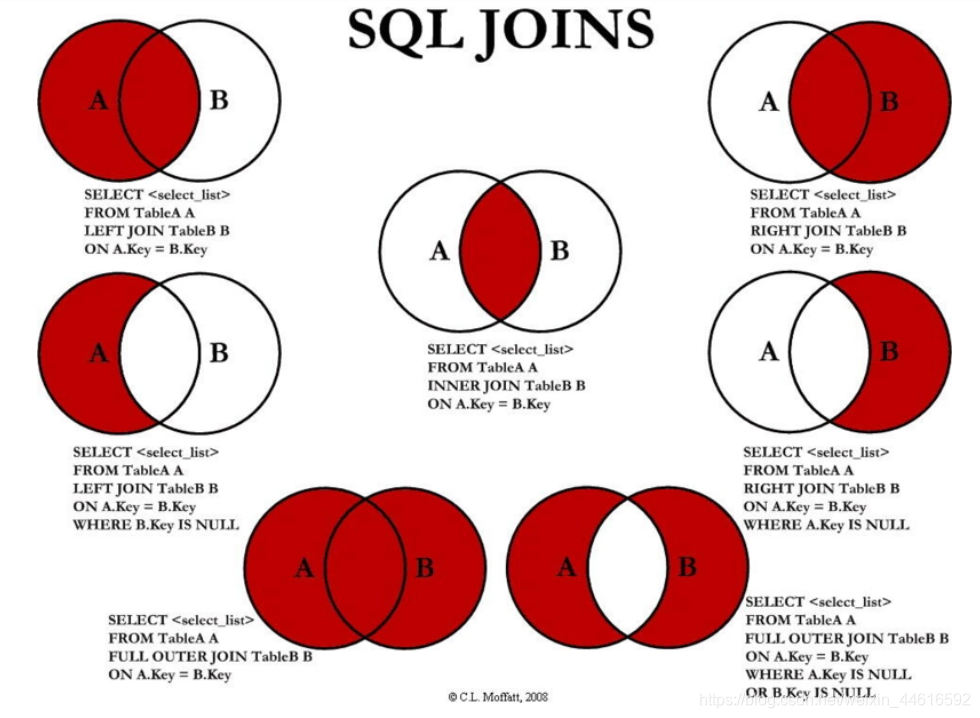
left join、right join和join的区别
有收获?希望烙铁们来个三连击,让更多的同学看到这篇文章
1、烙铁们,关注我看完保证有所收获,不信你打我。
2、点个赞呗,可以让更多的人看到这篇文章,后续还会有很哇塞的产出。
本文章仅供学习及个人复习使用,如需转载请标明转载出处,如有错漏欢迎指出
务必注明来源(注明: 来源:csdn , 作者:-马什么梅-)





