识别步骤参考:https://github.com/PaddlePaddle/PaddleOCR/blob/main/doc/doc_ch/recognition.md
微调步骤参考:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7.1/doc/doc_ch/finetune.md
训练必要性
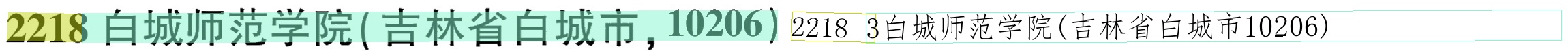
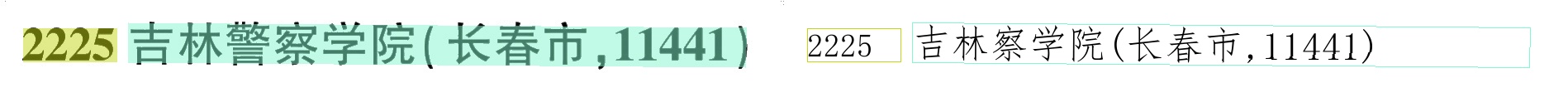
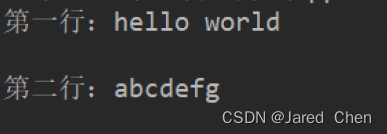
原始模型标点符号和括号容易识别不到
数据准备
通用数据 用于训练以文本文件存储的数据集(SimpleDataSet);
一张图片 一行文本
格式类似:

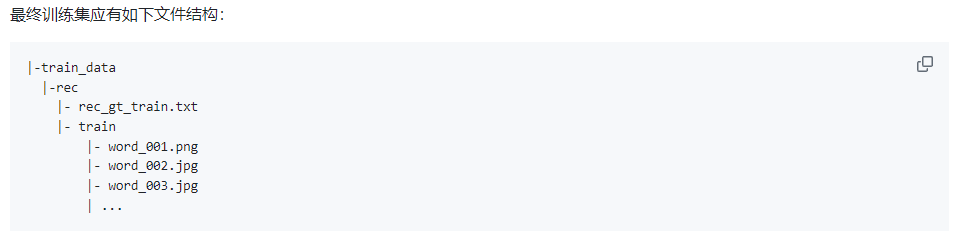
注意:图像文件名写xxx.jpg即可,文件夹名可以在配置文件中指定
数据源:垂直领域的pdf,经过剪裁生成了10万张图片(文本内容没有去重,为了保证一些词出现的频率不变)
开始训练
训练v4的模型,所以选择配置文件:ch_PP-OCRv4_rec.yml ,需要做如下更改
更改学习率为[1e-4, 2e-5]左右,
更改图片文件夹路径
更改batch_size大小(训练报错时,适当调节大小,)
下载pretrain model,使用v4预训练模型
https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_train.tar
注意:v4预训练模型没有best,只有student
正常启动训练
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv4_rec_train/student Global.save_model_dir=./output/rec_ppocr_v4
注意使用ch_PP-OCRv4_rec_distill.yml配置文件训练,报错KeyError: ‘NRTRLabelDecode’,官方暂时没有解决。
python3 tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_distill.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv4_rec_train/student
导出模型
python3 tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec_jilin.yml -o Global.pretrained_model=./output/rec_ppocr_v4/best_accuracy Global.save_inference_dir=./inference/PP-OCRv4_rec_jilin/
python3 tools/infer/predict_rec.py --rec_model_dir="./inference/PP-OCRv4_rec/" --image_dir="./train_data/rec/jilin_001_0_27_5.jpg"
推理
python3 tools/infer_rec.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=./output/rec_ppocr_v4/best_accuracy Global.infer_img=./train_data/rec/jilin_001_0_27_5.jpg
实践:
参考:https://blog.csdn.net/qq_52852432/article/details/131817619
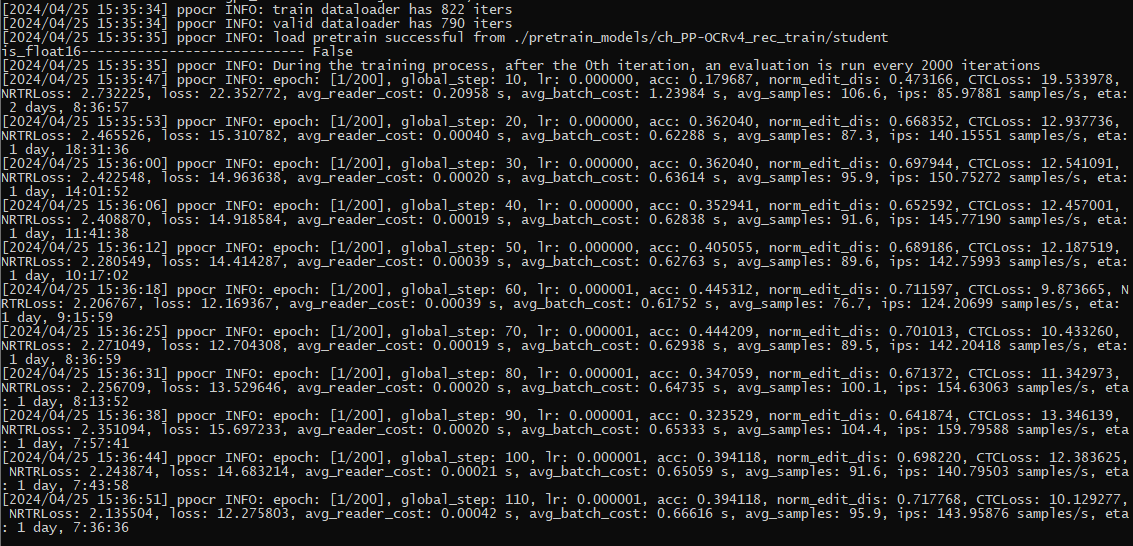
一共训练了20轮,第五轮训练测试集达到最大精度,85%,之后精度逐渐下降

预测
图片:
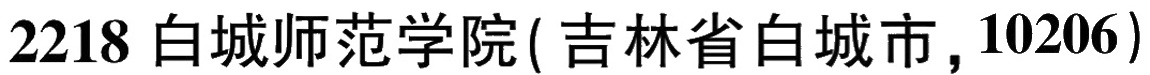

训练的模型:
(‘2218白城师范学院(吉林省白城市,10206)’, 0.9582517743110657)
(‘2225吉林警察学院(长春市,11441)’, 0.9862592816352844)
原始v4模型:
(2218白城师范学院(吉林省白城市,10206)', 0.9726919531822205)
(‘2225吉林警察学院(长春市,11441)’, 0.9829413294792175)
总结
可以看到,训练后模型识别括号基本统一成英文了。其实光是识别,起始v4效果已经很好了,原来检测的效果不太行,会拉低识别正确率
改进:微调文字检测模型,待完成后补充
其他需要注意的
实践时,使用了预训练模型,但一开始模型准确率acc一直为0,因为数据准备错误了,图片包含了多行文字,后来修正了图片,acc飞速提高。
其他版本
由于我数据集存在很多文本,我想更改max_length,从25改到50,并且image.shape的宽从320改成1280
结果时是拟合
训练模型可能有的疑问
文本识别训练时宽高比大于 10 或者文本长度大于 25 的图像会直接丢弃吗?会
参考:https://github.com/PaddlePaddle/PaddleOCR/issues/5017
如果训练数据较少的话,配置越高越容易过拟合。
英文长度是按照字母计算的,需要将空格计算在内。
我印象中,定义的max_text_length需要比实际的长度至少多两位数。
比如要想识别身份证号,实际中身份证号是18位,那在config文件中定义的max_text_length至少要为20,否则会报错。
尽量让字典里的每个字的出现频率在200以上(最好均匀),可以用text_renderer-master合成试试效果