
python-git-jwt-jwt-jws-jwe-json-web-tokenjwt-oss-1-2-apscheduler-rpc-rpc-1-rpc-rpc-socketio-1-elasticsearch-1-2-elasticsearch">本教程的知识点为:简介 1. 内容 2. 目标 产品效果 ToutiaoWeb虚拟机使用说明 数据库 理解ORM 作用 思考: 使用ORM的方式选择 数据库 SQLAlchemy操作 1 新增 2 查询 all() 数据库 分布式ID 1 方案选择 2 头条 使用雪花算法 (代码 toutiao-backend/common/utils/snowflake) 数据库 Redis 1 Redis事务 基本事务指令 Python客户端操作 Git工用流 调试方法 JWT认证方案 JWT & JWS & JWE Json Web Token(JWT) OSS对象存储 存储 需求 方案 使用 缓存 缓存架构 多级缓存 头条项目的方案 缓存数据 缓存 缓存问题 1 缓存 2 缓存 头条项目缓存与存储设计 APScheduler定时任务 定时修正统计数据 RPC RPC简介 1. 什么是RPC RPC 编写客户端 头条首页新闻推荐接口编写 即时通讯 即时通讯简介 即时通讯 Socket.IO 1 简介 优点: 缺点: Elasticsearch 简介与原理 1 简介 属于面向文档的数据库 2 搜索的原理——倒排索引(反向索引)、分析、相关性排序 Elasticsearch 文档 索引文档(保存文档数据) 获取指定文档 判断文档是否存在 单元测试 为什么要测试 测试的分类 什么是单元测试 断言方法的使用:
pythonnotemd">完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/Python/嘿马头条项目从到完整开发教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:

缓存
缓存问题
1 缓存穿透
缓存只是为了缓解数据库压力而添加的一层保护层,当从缓存中查询不到我们需要的数据就要去数据库中查询了。如果被黑客利用,频繁去访问缓存中没有的数据,那么缓存就失去了存在的意义,瞬间所有请求的压力都落在了数据库上,这样会导致数据库连接异常。
解决方案:
- 约定:对于返回为NULL的依然缓存,对于抛出异常的返回不进行缓存,注意不要把抛异常的也给缓存了。采用这种手段的会增加我们缓存的维护成本,需要在插入缓存的时候删除这个空缓存,当然我们可以通过设置较短的超时时间来解决这个问题。
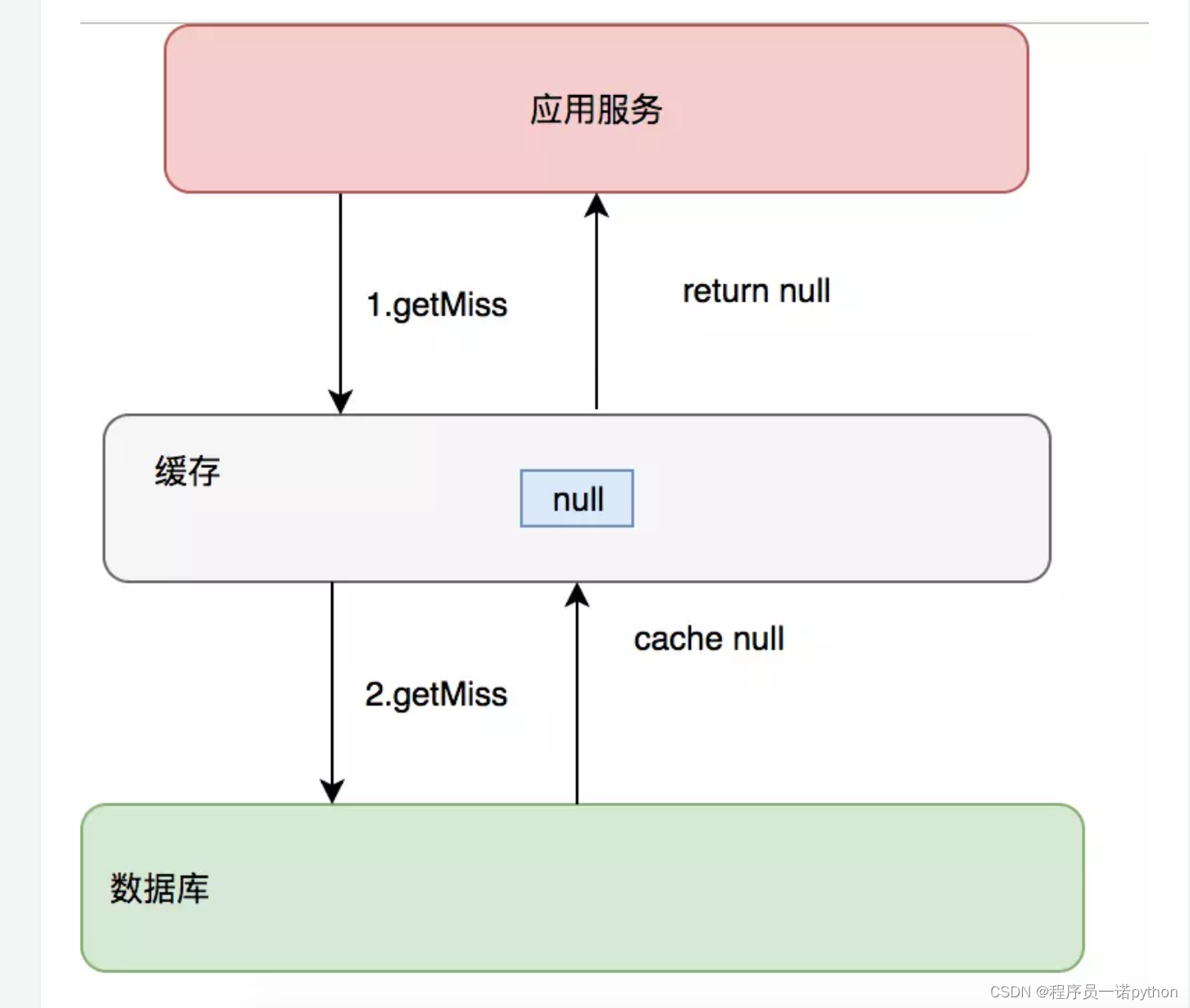
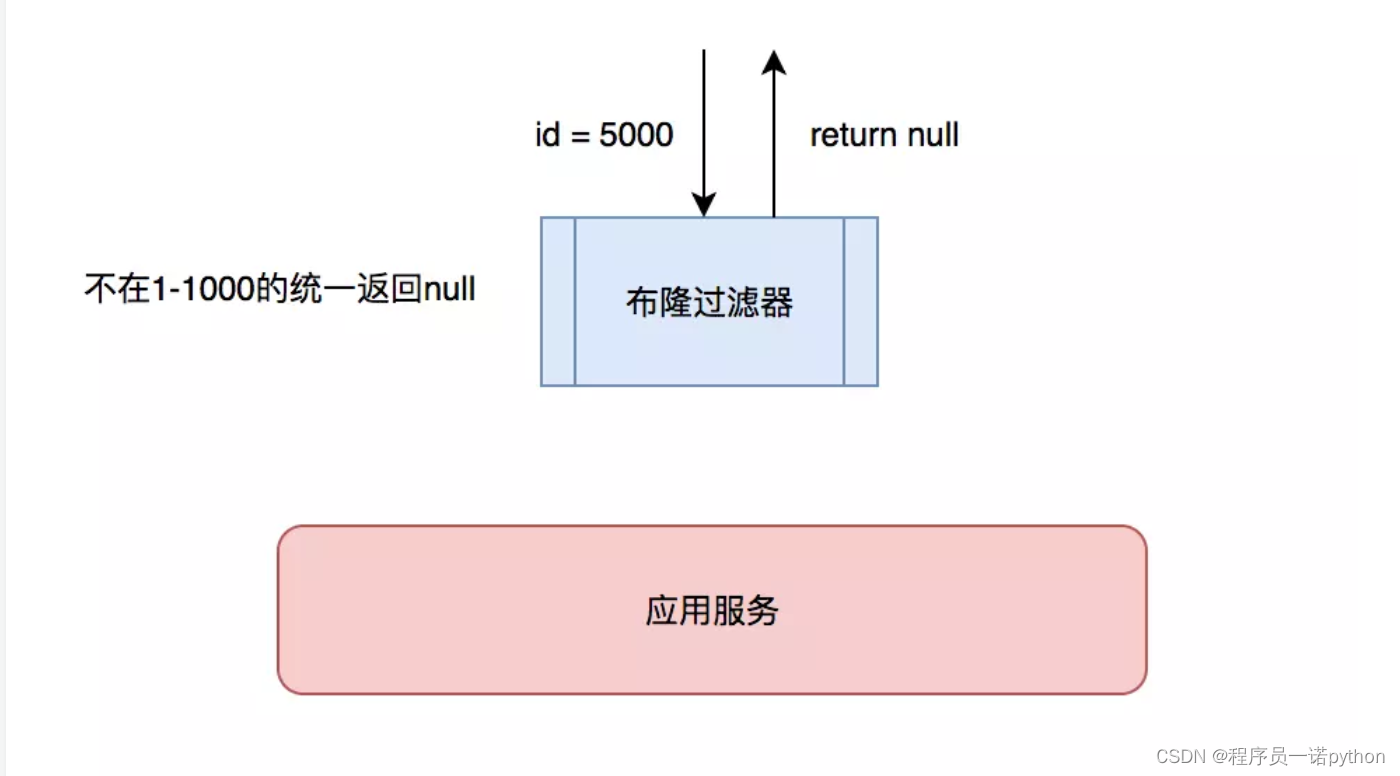
- 制定一些规则过滤一些不可能存在的数据,小数据用BitMap,大数据可以用布隆过滤器,比如你的订单ID 明显是在一个范围1-1000,如果不是1-1000之内的数据那其实可以直接给过滤掉。
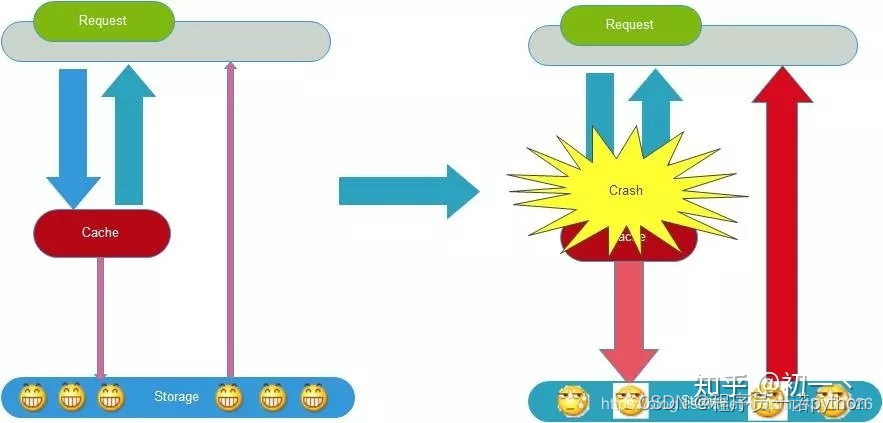
2 缓存雪崩
缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
解决方案:
1、给缓存加上一定区间内的随机生效时间,不同的key设置不同的失效时间,避免同一时间集体失效。比如以前是设置10分钟的超时时间,那每个Key都可以随机8-13分钟过期,尽量让不同Key的过期时间不同。
2、采用多级缓存,不同级别缓存设置的超时时间不同,及时某个级别缓存都过期,也有其他级别缓存兜底。
3、利用加锁或者队列方式避免过多请求同时对服务器进行读写操作。
头条项目缓存与存储设计
缓存设计
1 User Cache
用户资料
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:profile | string | user_id用户的数据缓存,包括手机号、用户名、头像 |
用户扩展资料
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:profilex | string | user_id用户的性别 生日 |
用户状态
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:status | string | user_id用户是否可用 |
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:following | zset | user_id的关注用户 | [{user_id, update_time}] |
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:fans | zset | user_id的粉丝用户 | [{user_id, update_time}] |
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:art | zset | user_id的文章 | [{article_id, create_time}] |
2 Comment Cache
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| art:{article_id}:comm | zset | article_id文章的评论数据缓存,值为comment_id | [{comment_id, create_time}] |
| comm:{comment_id}:reply | zset | comment_id评论的评论数据缓存,值为comment_id | [{'comment_id', create_time}] |
| comm:{comment_id} | string | 缓存的评论数据 |
3 Article Cache
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| ch:all | string | 所有频道 | |
| user:{user_id}:ch | string | 用户频道 | |
| ch:{channel_id}:art:top | zset | 置顶文章 | [{article_id, sequence}] |
| art:{article_id}:info | string | 文章的基本信息 | |
| art:{article_id}:detail | string | 文章的内容 |
4 Announcement Cache
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| announce | zset | [{'json data', announcement_id}] | |
| announce:{announcement_id} | string | 'json data' |
持久存储设计
1 阅读历史
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:his:reading | zset | [{article_id, read_time}] |
2 搜索历史
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| user:{user_id}:his:searching | zset | [{keyword, search_time}] |
3 统计数据
| key | 类型 | 说明 | 举例 |
|---|---|---|---|
| count:art:reading | zset | 文章阅读数量 | [{article_id, count}] |
| count:user:arts | zset | 用户发表文章数量 | [{user_id, count}] |
| count:art:collecting | zset | 文章收藏数量 | [{article_id, count}] |
| count:art:liking | zset | 文章点赞数量 | [{article_id, count}] |
| count:art:comm | zset | 文章评论数量 | [{article_id, count}] |
头条项目缓存实现
以用户信息数据缓存为例
common/cache/user.py
python linenums">from flask import current_app
from redis.exceptions import RedisError
import json
from sqlalchemy.orm import load_onlyfrom models.user import User
from . import constantsclass UserProfileCache(object):"""用户资料信息缓存"""def __init__(self, user_id):self.key = 'user:{}:info'.format(user_id)self.user_id = user_iddef save(self):"""查询数据库保存缓存记录:return:"""r = current_app.redis_cluster# 查询数据库user = User.query.options(load_only(User.name,User.profile_photo,User.introduction,User.certificate)).filter_by(id=self.user_id).first()# 判断结果是否存在# 保存到redis中if user is None:try:r.setex(self.key, constants.USER_NOT_EXISTS_CACHE_TTL, -1)except RedisError as e:current_app.logger.error(e)return Noneelse:cache_data = {'name': user.name,'photo': user.profile_photo,'intro': user.introduction,'certi': user.certificate}try:r.setex(self.key, constants.UserProfileCacheTTL.get_val(), json.dumps(cache_data))except RedisError as e:current_app.logger.error(e)return cache_datadef get(self):"""获取用户的缓存数据:return:"""r = current_app.redis_cluster# 先查询redistry:ret = r.get(self.key)except RedisError as e:current_app.logger.error(e)ret = Noneif ret is not None:# 如果存在记录,读取if ret == b'-1':# 判断记录值,如果为-1,表示用户不存在return None# 如果不为-1,需要json转换,返回else:return json.loads(ret)else:# 如果记录不存在,cache_data = self.save()return cache_datadef clear(self):"""清除用户缓存"""try:current_app.redis_cluster.delete(self.key)except RedisError as e:current_app.logger.error(e)def exists(self):"""判断用户是否存在"""# 查询redisr = current_app.redis_clustertry:ret = r.get(self.key)except RedisError as e:current_app.logger.error(e)ret = None# 如果缓存记录存在if ret is not None:if ret == b'-1':# 如果缓存记录为-1 ,表示用户不存在return Falseelse:# 如果缓存记录不为-1, 表示用户存在return True# 如果缓存记录不存在,查询数据库else:cache_data = self.save()if cache_data is not None:return Trueelse:return False
common/cache/constants.py
python linenums">class BaseCacheTTL(object):"""缓存有效期为防止缓存雪崩,在设置缓存有效期时采用设置不同有效期的方案通过增加随机值实现"""TTL = 0 # 由子类设置MAX_DELTA = 10 * 60 # 随机的增量上限@classmethoddef get_val(cls):return cls.TTL + random.randrange(0, cls.MAX_DELTA)class UserProfileCacheTTL(BaseCacheTTL):"""用户资料数据缓存时间, 秒"""TTL = 30 * 60
接口示例
定义获取当前用户信息的接口
GET /v1_0/user
返回JSON
在toutiao/resources/user/__init__.py中定义路由
python linenums">user_api.add_resource(profile.CurrentUserResource, '/v1_0/user', endpoint='CurrentUser')
在toutiao/resources/ user/profile.py 中
python linenums">class CurrentUserResource(Resource):"""用户自己的数据"""method_decorators = [login_required]def get(self):"""获取当前用户自己的数据"""user_data = cache_user.UserProfileCache(g.user_id).get()user_data['id'] = g.user_idreturn user_data
项目Redis持久存储实现
common/cache/statistic.py
python linenums">from flask import current_appfrom redis.exceptions import ConnectionErrorclass CountStorageBase(object):"""统计数据存储父类"""key = ''@classmethoddef get(cls, user_id):"""获取指定用户的数值:param user_id::return:"""try:ret = current_app.redis_master.zscore(cls.key, user_id)except ConnectionError as e:current_app.logger.error(e)ret = current_app.redis_slave.zscore(cls.key, user_id)if ret is not None:return int(ret)else:return 0@classmethoddef incr(cls, user_id, increment=1):"""给指定用户机统计数据累计:param user_id::param increment::return:"""current_app.redis_master.zincrby(cls.key, user_id, increment)class UserArticleCountStorage(CountStorageBase):"""用户文章数量存储"""key = 'count:user:arts'class UserFollowingCountStorage(CountStorageBase):"""用户关注数量"""key = 'count:user:followings'
APScheduler定时任务
APScheduler使用
APScheduler (advanceded python scheduler)是一款Python开发的定时任务工具。
文档地址 [
特点:
-
不依赖于Linux系统的crontab系统定时,独立运行
-
可以动态添加新的定时任务,如
下单后30分钟内必须支付,否则取消订单,就可以借助此工具(每下一单就要添加此订单的定时任务)
- 对添加的定时任务可以做持久保存
1 安装
pip install apscheduler
2 使用方式
python linenums">from apscheduler.schedulers.background import BackgroundScheduler# 创建定时任务的调度器对象scheduler = BackgroundScheduler()# 定义定时任务def my_job(param1, param2):pass# 向调度器中添加定时任务scheduler.add_job(my_job, 'date', args=[100, 'python'])# 启动定时任务调度器工作scheduler.start()
3 调度器 Scheduler
负责管理定时任务
BlockingScheduler: 作为独立进程时使用
python linenums">from apscheduler.schedulers.blocking import BlockingSchedulerscheduler = BlockingScheduler()scheduler.start() # 此处程序会发生阻塞
BackgroundScheduler: 在框架程序(如Django、Flask)中使用
python linenums">from apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler()scheduler.start() # 此处程序不会发生阻塞
4 执行器 executors
在定时任务该执行时,以进程或线程方式执行任务
- ThreadPoolExecutor
python linenums">from apscheduler.executors.pool import ThreadPoolExecutorThreadPoolExecutor(max_workers) ThreadPoolExecutor(20) # 最多20个线程同时执行
使用方法
python linenums">executors = {'default': ThreadPoolExecutor(20)}scheduler = BackgroundScheduler(executors=executors)
- ProcessPoolExecutor
python linenums">from apscheduler.executors.pool import ProcessPoolExecutorProcessPoolExecutor(max_workers)ProcessPoolExecutor(5) # 最多5个进程同时执行
使用方法
python linenums">executors = {'default': ProcessPoolExecutor(3)}scheduler = BackgroundScheduler(executors=executors)
5 触发器 Trigger
指定定时任务执行的时机
1) date 在特定的时间日期执行
python linenums">from datetime import date# 在2019年11月6日00:00:00执行sched.add_job(my_job, 'date', run_date=date(2009, 11, 6))# 在2019年11月6日16:30:05sched.add_job(my_job, 'date', run_date=datetime(2009, 11, 6, 16, 30, 5))
sched.add_job(my_job, 'date', run_date='2009-11-06 16:30:05')# 立即执行sched.add_job(my_job, 'date')
sched.start()
2) interval 经过指定的时间间隔执行
- weeks (int) – number of weeks to wait
- days (int) – number of days to wait
- hours (int) – number of hours to wait
- minutes (int) – number of minutes to wait
- seconds (int) – number of seconds to wait
- start_date (datetime|str) – starting point for the interval calculation
- end_date (datetime|str) – latest possible date/time to trigger on
- timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations
python linenums">from datetime import datetime# 每两小时执行一次sched.add_job(job_function, 'interval', hours=2)# 在2010年10月10日09:30:00 到2014年6月15日的时间内,每两小时执行一次sched.add_job(job_function, 'interval', hours=2, start_date='2010-10-10 09:30:00', end_date='2014-06-15 11:00:00')
3) cron 按指定的周期执行
- year (int|str) – 4-digit year
- month (int|str) – month (1-12)
- day (int|str) – day of the (1-31)
- week (int|str) – ISO week (1-53)
- day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun)
- hour (int|str) – hour (0-23)
- minute (int|str) – minute (0-59)
- second (int|str) – second (0-59)
- start_date (datetime|str) – earliest possible date/time to trigger on (inclusive)
- end_date (datetime|str) – latest possible date/time to trigger on (inclusive)
- timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone)
python linenums"># 在6、7、8、11、12月的第三个周五的00:00, 01:00, 02:00和03:00 执行sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')# 在2014年5月30日前的周一到周五的5:30执行sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2014-05-30')
6 配置方法
方法1
python linenums">from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.executors.pool import ThreadPoolExecutorexecutors = {'default': ThreadPoolExecutor(20),
}
scheduler = BackgroundScheduler(executors=executors)
方法2
python linenums">from pytz import utcfrom apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutorexecutors = {'default': {'type': 'threadpool', 'max_workers': 20},'processpool': ProcessPoolExecutor(max_workers=5)
}scheduler = BackgroundScheduler()# .. 此处可以编写其他代码# 使用configure方法进行配置scheduler.configure(executors=executors)
7 启动
python linenums">scheduler.start()
- 对于BlockingScheduler ,程序会阻塞在这,防止退出
- 对于BackgroundScheduler,程序会立即返回,后台运行
8 扩展
任务管理
方式1
python linenums">job = scheduler.add_job(myfunc, 'interval', minutes=2) # 添加任务
job.remove() # 删除任务
job.pause() # 暂定任务
job.resume() # 恢复任务
方式2
python linenums">scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id') # 添加任务
scheduler.remove_job('my_job_id') # 删除任务
scheduler.pause_job('my_job_id') # 暂定任务
scheduler.resume_job('my_job_id') # 恢复任务
调整任务调度周期
python linenums">job.modify(max_instances=6, name='Alternate name')scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
停止APScheduler运行
python linenums">scheduler.shutdown()




