之前客户提出过一个需求,就是希望可以将一本教材,快速的转换为教学ppt,虽然通过人工+程序脚本的方式,已经实现了该功能,但是因为没有做到通用,每次都需要修改脚本,无法让客户自行完成所有流程,所以决定重新设计一下这个功能,最终目标就是用户自行上传一本书,可以自动生成所有的ppt。 首先,我们设计一下方案。先与gpt聊聊,看看他的想法。
产品方案
一、产品目标
目标:
-
用户上传一本 Word/PDF 电子书,我们的程序将其 自动化地转成 PPT。 -
整个流程尽量减少用户手动干预,通过 大模型和 接口服务的配合,实现自动化和规范化处理。
核心需求:
-
将电子文档(Word/PDF)内容提取,并 准确保留层级结构。 -
自动拆分文档到合适的粒度(如:章/节)。 -
基于大模型,规范化并生成 适合 PPT 展示的标题和段落内容。 -
通过 AIPPT 服务(如「文多多easegen.docmee.cn」)选择/应用模板,一键生成 PPT。
二、整体流程设计
为了更好地拆解每一步的逻辑,下面给出一个从输入到输出的可能流程。可以视为 MVP(最小可行产品)的流程,也可以在此基础上扩展更多的功能。
1. 上传电子文档
-
用户上传:用户在前端界面上传 Word 或 PDF 文件。 -
文档接收:后端服务器接收文件,进行排队/存储。 -
格式识别:如果是 PDF,则需要做 OCR 或基于 PDF 解析工具(如 PyPDF2、pdfplumber 等)提取文本及结构;如果是 Word,利用 Python-docx 或者其他库来读取段落、标题信息。
注意点:
-
PDF 的解析准确性和对“标题层级”的捕捉需要仔细处理;Word 相对更容易获取结构。 -
大批量页数的文档,可能需要异步处理或者任务队列提高效率。
2. 转换为 Markdown
-
提取文本 + 结构:识别文档中的标题、段落、列表、图片等内容,按照 层级做一个内部数据结构存储(如树形结构:章 -> 节 -> 小节)。 -
生成 Markdown:将文档中每个标题、段落转换为相应的 Markdown 语法。 -
例如“第一章”用 # 第一章,如果有节则用##标记,依此类推。 -
对段落使用普通文本行表示,对列表、引用等可以使用 Markdown 语法进行标记。
-
注意点:
-
标题的级别需要先简单做规则匹配(如大纲级别或者正则)或通过自然语言模型判断(如 GPT、BERT),以尽量保证结构准确。 -
如果有插图(如 PDF 中插画或 Word 中的图片),需要决定是否保留在 Markdown 中(可以用 标记),或暂时忽略。
3. 拆分 Markdown
-
按规则拆分:如按照 章或者 节进行拆分,拆分成多个独立的 Markdown 文件(或内存对象),以方便后续处理。 -
存储管理:将拆分后的文档保存到数据库或对象存储中,记录各自的标题、文本内容、层级信息等元数据。 -
处理顺序:可并行或顺序对每个部分进行后续处理。
4. 标题和内容的规范化
-
调用大模型:对于每个拆分单元,调用大模型(如 GPT-4 / ChatGPT)对标题进行重新整理或概括。 -
例如,若标题写法不统一:有些写了“第一章”,有些只写了“1.1”,或标题过长;则让大模型输出一个“最合适、最简洁/最贴切的标题”。 -
同时可以让大模型对段落做简要摘要,或者做对 PPT 友好的精简。
-
-
保证一致性:可能需要一些 prompt 工程,给大模型输入“当前已有标题”和“整体风格”,告诉它要以何种风格输出标题(如“统一中文,尽量简洁”)。 -
可选:内容精炼:如果需要做 PPT,就需要精炼文字;也可以让大模型输出要点式、分点式的内容。
注意点:
-
标题太长或不符合 PPT 场景时,需要做裁剪或优化。 -
有些用户可能想保留章节编号等信息,需要在设计 prompt 时设置“保留”或“移除”等。
5. 生成 PPT
-
选择 PPT 模板: -
后端可以直接调用 AIPPT 服务(如「文多多」)的 API,传递模板 ID 或者让用户自己上传模板 PPT 文件(需要解析或兼容该模板)。
-
-
组装 PPT: -
通过 AIPPT 的接口把每个拆分单元的标题、段落、图片等按照一定的版式规则填充到 PPT 中的占位符。 -
如果要有更多炫酷效果,需要先在模板里定义布局,然后通过接口插入对应的文字和图片。
-
-
生成下载链接: -
生成好的 PPT 存储在后端或第三方对象存储中,返回下载链接或在前端直接预览。
-
注意点:
-
不同章节可以采用不同的版式(如大标题页 vs 内容页 vs 图片页),需要在产品设计中给用户更多自定义或自动判断的选项。 -
需要接口配合,不同 AIPPT 平台的对接方式略有差异。
三、技术架构概述
从整体上看,可以考虑分为前端、后端和第三方服务三个模块:
-
前端
-
提供上传文件界面、进度条或任务队列状态展示。 -
设置 PPT 模板选择/管理界面,或可自定义一些基础参数(字号、配色、页眉页脚等)。 -
提供生成完成后的 PPT 预览和下载。
-
-
后端
-
文件解析模块:用相应的 Python 库或第三方服务进行 Word/PDF 解析,输出结构化数据。 -
Markdown 生成和拆分模块:将结构化数据转换为 Markdown,按章/节拆分。 -
大模型调用模块:对接 GPT 系列或其他大模型 API,对标题和内容做规范化处理。 -
PPT 生成模块:对接「文多多」等 AIPPT 接口,通过 API 创建 PPT 并填充内容。 -
数据库与存储:存储解析后的文本和生成后的 PPT 文件。
-
-
第三方服务(AIPPT 等)
-
与 AIPPT 平台(如「文多多」)的接口对接:上传内容、选择模板、生成 PPT、返回 PPT 链接。
-
可选的扩展:
-
如果用户对 PPT 排版有较高要求,后端可以自建一个 PPT 生成服务,基于 python-pptx 等库进行灵活的版面布局。 -
还可以接入更多大模型能力,如自动插入合适的图片/图标、自动生成演讲者备注等。
四、产品形态与交互
MVP 版交互
-
用户进入页面,上传电子书(Word/PDF)。 -
等待文档解析完成(队列/异步)。 -
系统展示检测到的 章节结构(可视化大纲),让用户有机会手动微调(如删除某些章节,或修正某些标题)。 -
用户点击“生成 PPT”按钮;选择或上传模板;设置一些偏好(如字号、主题色等)。 -
系统调用大模型对标题和内容进行精简/规范化;调用 AIPPT 接口生成 PPT;生成下载地址。 -
用户可以预览并下载 PPT。
增强版交互思路
-
模板市场:用户可浏览各种不同风格的 PPT 模板,一键套用。 -
可视化编辑:生成 PPT 之前,前端展示“预览”页,允许用户拖拽/编辑页面布局、文字样式、背景等。 -
大模型再编辑:用户对某些页面不满意,可点一下“重新生成文案”按钮,实时调用大模型给出新的文字排版。 -
协同:多用户协同编辑同一本书,最后同步生成 PPT。
五、可能的难点与挑战
-
PDF 结构化:如果书是 PDF 格式,可能存在 PDF 制作不规范、文字排版混乱等问题,标题与正文区分不明显,需要一定的 NLP 或启发式算法来识别。 -
章节层级准确:若原文档标题标注不规范,需要大模型/NLP 进行多轮判断,可能存在一定的错误率。 -
标题/内容的自动化生成质量:大模型能够简化标题,但有可能失去用户想要保留的信息,需要在产品上提供“是否保持原文”/“简化改写”/“翻译”等选项。 -
PPT 生成接口的灵活度:如果第三方 AIPPT 平台的接口不够灵活,可能无法做更精细的排版,需要自己实现或与更多平台做兼容。 -
效率和成本:长文档调用大模型会带来较高的 API 成本,也需要考虑速度和并发问题。
六、后续可扩展方向
-
支持多语言:不仅限于中文书,英文或其他语言同样可以自动生成相应 PPT。 -
支持更多输出形式:不仅是 PPT,也可以生成 PDF 报告、HTML 网页等。 -
知识库和搜索:把拆分后的文档内容建立知识库,用户可以在生成 PPT 前后进行搜索/问答。 -
多种总结粒度:PPT 只是一种表达方式,或许可以同时生成“精华版”和“详细版”,根据用户需求选择不同程度的精简。 -
数据分析:如果是教材或商业文档,可以自动分析文档结构、关键词、知识点分布,形成更多增值服务。
七、总结
这套方案的关键是:
-
精确保留并提取文档层级结构; -
通过大模型进行标题/内容的统一和精简; -
对接可定制的 PPT 生成接口,实现“所见即所得”或者“一键生成”。
在产品的早期阶段,先实现基础流程(上传->解析->拆分->生成->下载),后续逐步增强可视化交互、模板管理、多语言支持等功能。
在实际落地时,还要注意性能、API 成本、错误率等现实问题。但如果能在技术和产品设计上规划合理,这将是一个有相当使用价值、也具备差异化竞争力的应用。
可以看到,gpt帮助生成了一份非常详细的产品方案,并且还给出了MVP的落地思路,真的非常棒,接下来,我们使用https://diagrammingai.com/生成一个流程图,可以看的更清晰
流程图
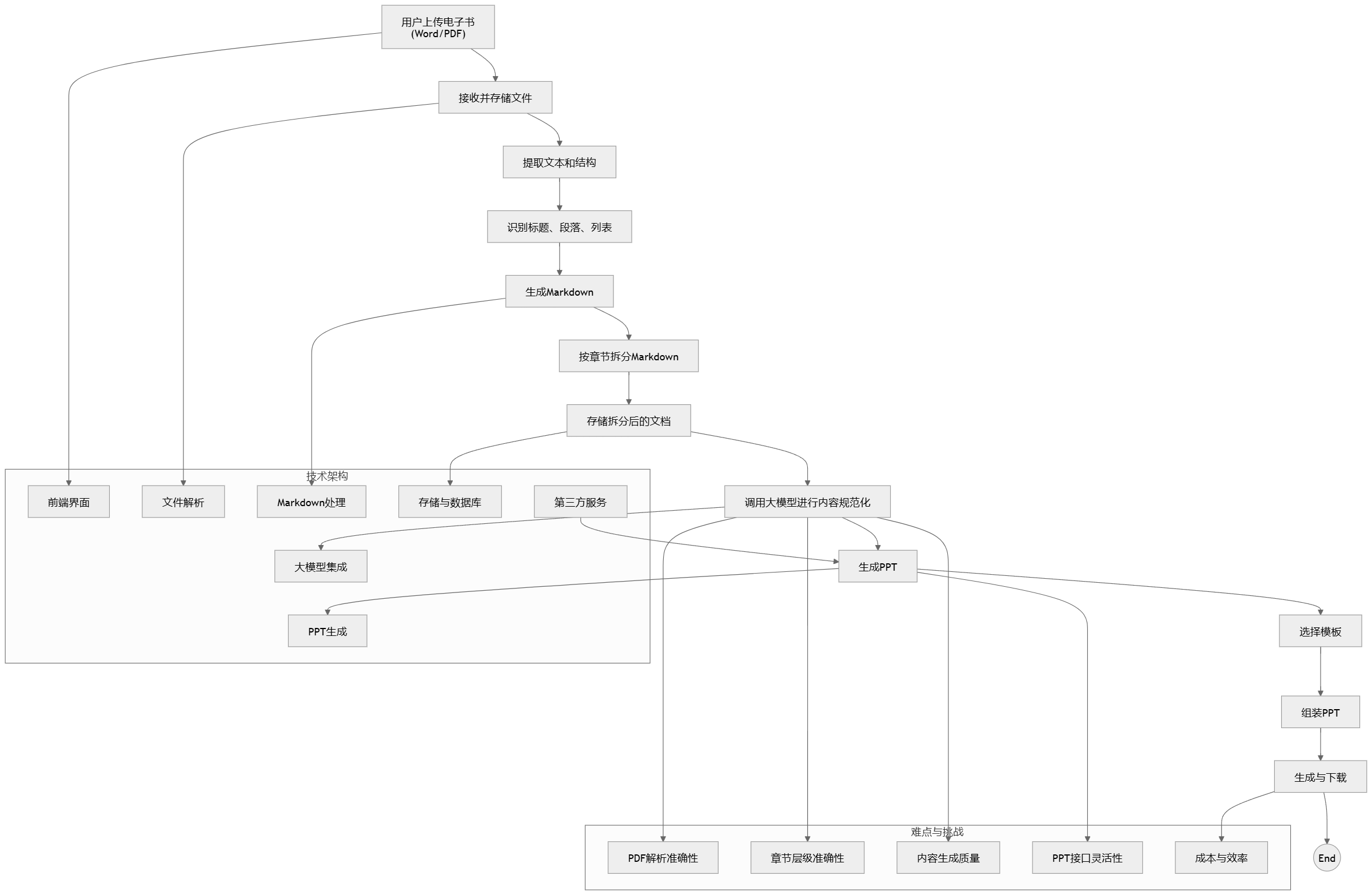
将gpt的方案输入以后,快速的生成了一个流程图,可以更清晰的了解整体方案
动手
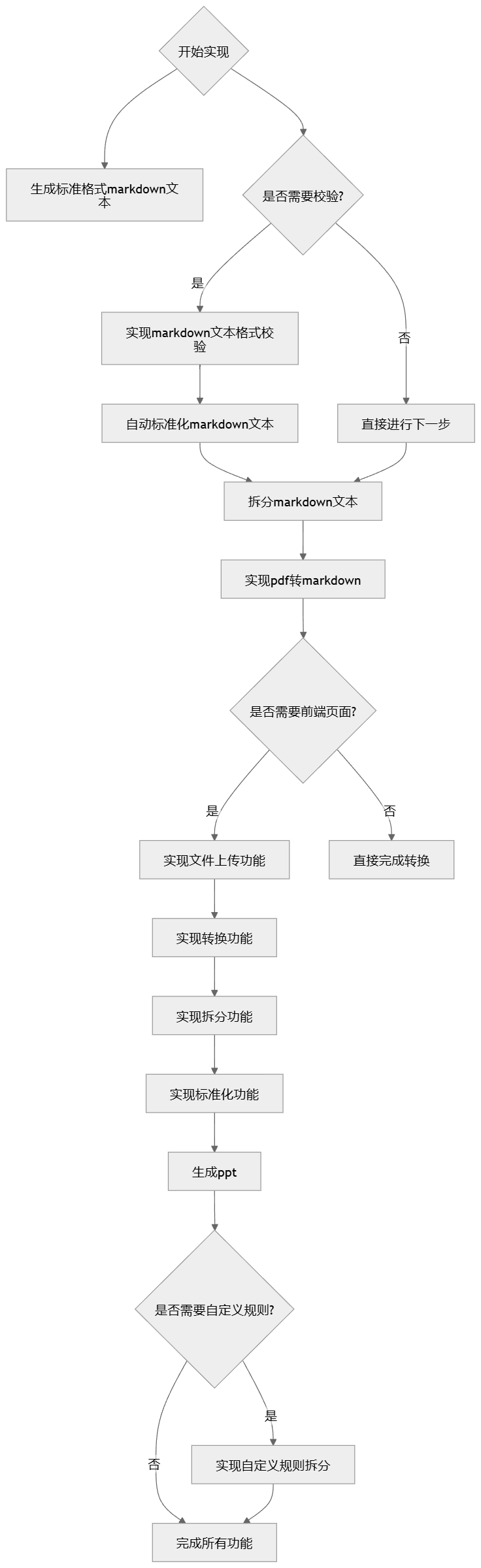
接下来我们就要开始动手实现了,因为已经有了一定的基础,所以我采用逆向的方式进行开发实现,方便每实现一个功能即可快速验证。
-
第一步先实现标准格式markdown文本生成ppt; -
第二步实现markdown文本格式的校验和自动标准化 -
第三步实现markdown文本的拆分 -
第四步实现pdf转markdown -
然后实现前端页面部分的文件上传、转换、拆分、标准化、生成ppt -
最后针对某些难点如自定义规则拆分、格式标准化场景,通过agent的方式尽量实现自动化
自我介绍 😎
我是一个AGI时代超级个体践行者,喜欢AI技术并且希望使用AI技术让我们的生活更加美好,欢迎有相同目标的朋友加好友我们一起前行。🤝
我可以提供AI大模型业务技术咨询、产品设计、产品落地。同时拥有数字人课程、在线教育、智慧知识库等产品。欢迎来撩。✉️✨

本文由 mdnice 多平台发布