1. 简介
strings库 存储了 一些针对 字符串的具体操作 其 代码短小精悍 可以学习到很多编程的思路 尤其是 涉及到字符串使用性能的方面,其源码库有好多的优秀案例可以学习。向强者对齐不一定成为强者,但向弱者对齐一定变为弱者。
介绍思路是先介绍 strings 库的一些基础 结构体和函数,它们被其它函数调用,然后挑选几个比较有代表性的函数介绍,下面开始吧
2. Strings.Builder 结构体
Builder结构体主要是用来处理字符串的拼接的,它底层采用了 append的 形式,可以大幅度减少内存的开销。至少比 + 要快很多,尤其在for循环里进行字符串拼接, + 每次都要 进行内存分配,效率低下,但是append 时 内存分配时倍数增长的,内存copy次数要少很多。
下面我们来看下 Builder源码
type Builder struct {addr *Builder // 检测是否有 Builder 值传递buf []byte // 字节数组 用来 拼接字符串 采用 append 形式
}我们来挑选几个代表性的 函数来说明下
2.1 WriteString(s string) (int, error) 函数
func (b *Builder) WriteString(s string) (int, error) {b.copyCheck() // 检查 Builder 是否是值传递 例如 是否 将 c:=b 然后 调用 c.WriteString ,之所以不允许这样 主要还是考虑 避免内存复制 保证 Builder 的执行效率b.buf = append(b.buf, s...) // 将 s 拆分成 byte 类型 添加到 buf中return len(s), nil // 返回 长度
}其中 b.copyCheck() 代码说明 如下
func (b *Builder) copyCheck() {if b.addr == nil {// This hack works around a failing of Go's escape analysis// that was causing b to escape and be heap allocated.// See issue 23382.// TODO: once issue 7921 is fixed, this should be reverted to// just "b.addr = b"b.addr = (*Builder)(noescape(unsafe.Pointer(b))) // 赋值操作,且 保证 b空间 一直在 栈上 ,避免逃逸分析;调用 unsafe.Pointer 进行类型强转 保证效率 不内存复制,但不保证安全。} else if b.addr != b {// 避免 Builder 值赋值 ,例如不允许 执行 c:=b c.WriteString(...)这种操作 ,否则 panicpanic("strings: illegal use of non-zero Builder copied by value")}
}2.2 Grow(n int) 函数
todo
2.3 String() 函数
用来 将 b.buf 中的字节数组 转换成字符串
func (b *Builder) String() string {return unsafe.String(unsafe.SliceData(b.buf), len(b.buf)) // 采用 无安全包 将 内存缓冲区的 字符数组直接转换为string 无需 内存复制 ps: string([]byte) 会产生一次内存复制
}
3. Strings.Index(s, substr string)int 函数
Index 函数是其他函数的基础函数 需首先介绍,其代码如下
func Index(s, substr string) int {n := len(substr)switch {case n == 0:return 0case n == 1:return IndexByte(s, substr[0])case n == len(s):if substr == s {return 0}return -1case n > len(s):return -1case n <= bytealg.MaxLen: // 当子串长度小于等于阈值63时 执行如下操作// Use brute force when s and substr both are smallif len(s) <= bytealg.MaxBruteForce { // 当 len(s) 小于阈值时 直接调用 bytealg 的IndexString()方法来 计算 也就是 当 s 和 substr 都比较小的时候可直接调用 底层函数// bytealg库不对用户开放,它比直接调原生的c库和go语言编写更加的效率高。 //bytealg.IndexString 是采用汇编直接跟底层编译器通信 来编写的 查找索引的函数 速度更快。return bytealg.IndexString(s, substr)}c0 := substr[0] // c0: 子串第一个字符c1 := substr[1] // c1: 子串第二个字符 用于 进行多一层比较后 在进行字符串比较时 可以提升查询效率i := 0 // 字符串s参与比较的 起始索引,初始化为0t := len(s) - n + 1 // 最大比较次数fails := 0 // 失败次数 也就是 for循环执行的次数for i < t {if s[i] != c0 { // 如果某次比较的 s 起始索引对应字符 s[i]跟 子串第一个字符不相等,走这里// IndexByte is faster than bytealg.IndexString, so use it as long as// we're not getting lots of false positives.o := IndexByte(s[i+1:t], c0) // 调用底层汇编函数 查找 字符 c0 在 s[i+1:t] 中第一次出现的 位置 起始位置从 i+1 开始查找,大家思考下为什么if o < 0 { // 没找到 直接返回 -1 循环退出return -1}i += o + 1 // 找到后更新 i的 位置为 当前找到的 c0 索引 起始位置,这是 是s[i]==c0}if s[i+1] == c1 && s[i:i+n] == substr { // 走到这里证明 s[i]==c0 这时 先不急与 比较 s[i:i+n] == substr 而是 再对 需要比较的两个子串的 第二个字符进行比较 这样 如果不相等 就不用后续 字符串比较了// 因为字符串比较 比字符比较 速度上低一个数量级 所以 如果不相等 则可以节省大量时间 如果相等 则 多出的比较时间 // 可以忽略不计 或者说 整体代价也是值得接受的 之所以不进行 第三个字符比较 可能也是为了找一个效率平衡点吧return i}fails++ // 走到这里 证明 上面没匹配到 这次比较 失败 失败次数+1 i++ // 能走到这里 证明 s[i]==c0 只是 没命中子串而已 所以 需要后移一位接着 开始比较// Switch to bytealg.IndexString when IndexByte produces too many false positives.if fails > bytealg.Cutover(i) { // 如果失败次数达到了阈值 再次以 s[i:] 为 基础 调用 bytealg.IndexString(...)函数 开始寻找 r := bytealg.IndexString(s[i:], substr) if r >= 0 {return r + i}return -1}}return -1}c0 := substr[0] // 下方代码跟 上面循环一样 只是 如果 子串 长度 >63时 执行如下操作 这时 也是先按上面循环执行逻辑 查找c1 := substr[1]i := 0t := len(s) - n + 1fails := 0for i < t {if s[i] != c0 {o := IndexByte(s[i+1:t], c0)if o < 0 {return -1}i += o + 1}if s[i+1] == c1 && s[i:i+n] == substr {return i}i++fails++if fails >= 4+i>>4 && i < t { // 翻译一下 fails >= 4+i/16 && i < t// See comment in ../bytes/bytes.go.j := bytealg.IndexRabinKarp(s[i:], substr) // 开始执行 Rabin-Karp 算法 简单来说 就是 子串太长了 需要 将 子串 取 hash 使它 缩短 然后进行匹配,感兴趣的可以了解下这个算法if j < 0 {return -1}return i + j}}return -1
}
可以看到 Index函数 会 根据 匹配字符串长度 子串长度 和 匹配次数 来综合考虑 使用那种算法 来进行 匹配,一般场景 使用 bytealg.IndexString(s, substr) 就可以了,二班三班的比较特殊。
4. Strings.Split(s, sep string) []string 函数
Split函数 如下
func Split(s, sep string) []string { return genSplit(s, sep, 0, -1) }
可以看到其 是 genSplit()函数的特殊情况,我们来介绍下 genSplit函数
// split 的 核心函数,s 需要分裂的字符串, sep分裂种子,sepSave 是需要在原始结果a[i]上额外多保存此子串后sepSave个字符, n是需要分裂成几个函数 注意 文中会进行修正
func genSplit(s, sep string, sepSave, n int) []string {if n == 0 { return nil}if sep == "" { // 子串为0时 计算字符串中 元数据的个数 return explode(s, n) }if n < 0 {n = Count(s, sep) + 1 // n是 s 最多被 sep 分为 几个子串 ,计算逻辑是 计算s中 sep的个数 +1,大家思考下为啥}if n > len(s)+1 { // 修正 n ,如果传递的 n过大 会创建 多余空间,造成浪费n = len(s) + 1}a := make([]string, n) // a 为结果集 ,初始化 空间大小是 nn-- // n-- 是 对结果的前 n-1个 可以使用 for 循环处理 最后一个 就直接是 截断后剩余的 s了 直接赋值,例如 s=="akjkl" sep="k" 则 2次循环后 已经 break 了 这时 s=="l" 直接赋值给a[i]就行i := 0 // a数组索引,计算a[i]值for i < n { // 寻找 a 的 最多前 n-1个值 sepSave 一般为0 ,当不为0时,表示需要额外获取m后sepSave个 字节 放入 a中,不确定这种使用场景,不做分析。 m := Index(s, sep) // 计算 m 索引if m < 0 { // 查找不到 breakbreak}a[i] = s[:m+sepSave] //为 a的第 i个索引 赋值 一般是是s[:m]s = s[m+len(sep):] // 截取s 现在可以知道 s[i:j] 为啥是 i是可取 j是不可取了吧 这种左闭右开的思路 正是为这种迭代情况设计的i++ }a[i] = s // 将最后截断后的 s赋值给 a[i] 注意 这是 i<=nreturn a[:i+1] // 返回 值 ,这是对a的截断,因为不一定全部存储满
}
5. Strings.Join(elems []string, sep string) string 函数
Join 函数底层 也是调用的 Builder 结构体相关函数 大体思路是 先计算 Join后形成的新字符串需要的空间 然后分配空间 再 调用 WriteString(…)函数 append进 数组 然后用 不安全 指针 强转成 string
我们来简单梳理下
func Join(elems []string, sep string) string {switch len(elems) { // 特殊情况处理case 0:return ""case 1:return elems[0]}var n intif len(sep) > 0 { // 计算 引入的 sep需要的空间if len(sep) >= maxInt/(len(elems)-1) {panic("strings: Join output length overflow")}n += len(sep) * (len(elems) - 1)}for _, elem := range elems { // 计算 总的空间if len(elem) > maxInt-n {panic("strings: Join output length overflow")}n += len(elem)}var b Builderb.Grow(n) // 初始化空间b.WriteString(elems[0]) // 将第一个先写入 则 后续可以用for 循环一次搞定;for循环也可以从0 开始 ,最后在把 elems[len(elems)-1]写入缓存区for _, s := range elems[1:] {b.WriteString(sep)b.WriteString(s)}return b.String() // 一次性强转 byte[]-->string 没有使用多余空间,底层强转
}6. Strings.TrimRight(s, sep string) []string 函数
这个函数 利用了 位图的思想来计算 s 中是否包含字符,位图的思想其实 就是将 一些 字符等 通过 一定的映射算法 把它 映射到 字节码数组的行 行列上 其位置置为1 且是独有的位置。举个简单地例子如下:
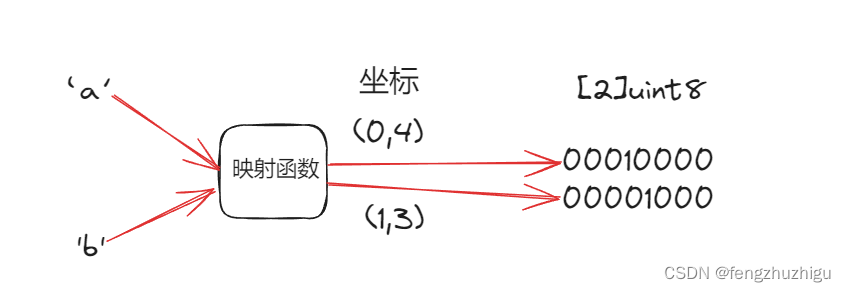
如上图 字符 ‘a’,‘b’ 通过 映射函数 获得坐标(0,3),(1,4)这个数组中的 相应为置为 1,规则是 行坐标确定索引,列坐标确定左移个数。则可以获得一个set集, 这样,要查找某字符在不在是,只要计算出坐标 查看其时是否是1就行了 (&运算)。举个例子:
字符’c’ 经过映射 发现其 行坐标是 1 则取出 set 中的 值 二进制表示是 00001000 ,列坐标假设是 2,则 我们执行 1<<2 得到 00000010,则
00001000&00000010=0 则证明,'c’不在set中。
介绍完了 位图思想 我们来看下 在源码中的应用
TrimRight源码 如下
// TrimRight 删除字符串 s 右侧 在 cutset集合中的字符
func TrimRight(s, cutset string) string {if s == "" || cutset == "" {return s}if len(cutset) == 1 && cutset[0] < utf8.RuneSelf { // 如果 cutset 长度为1 则从右边开始 挨个匹配 直到 不是 cutset为止,然后返回。这里直接直接字符比较就行return trimRightByte(s, cutset[0])}if as, ok := makeASCIISet(cutset); ok { // 如果所有字符都是 ascii码<127的 字符, cutset映射成位图set集 return trimRightASCII(s, &as) // 从最后边开始 挨个字符查看是否正在set集中,直到不在为止,然后返回。}return trimRightUnicode(s, cutset) // 如果cutset中存在非ascii字符 例如 中文 走这里。不是本文重点,且使用概率较小,感兴趣的可以看看。
}其中 TrimRight 中的 makeASCIISet 生成位图集的源码如下
// makeASCIISet 采用位图的思想 将 chars 对应set坐标 置为 1
func makeASCIISet(chars string) (as asciiSet, ok bool) { // as 长度为8且一个字符占 4字节(uint32)可映射 32字符, 但是 ascii 只有 128位字符 所以 只会 使用 索引 0-3,索引 4-7是保留空间,应该是留着后续扩展的。for i := 0; i < len(chars); i++ {c := chars[i]if c >= utf8.RuneSelf { // 非ASCII字符返回错误return as, false}as[c/32] |= 1 << (c % 32) // 位图 行坐标 c/32,列坐标是 c%32, 然后 1左移 列坐标各个数 1<<(c%32) 然后 |= 或运算,这样相位坐标位置置为1}return as, true
}其中 TrimRight 中的 trimRightASCII 从右边挨个字符匹配位图集函数如下:
// trimRightASCII 从最后边开始 挨个字符查看是否在set集中,直到不在为止,然后返回。
func trimRightASCII(s string, as *asciiSet) string {for len(s) > 0 {if !as.contains(s[len(s)-1]) { // 从右边开始 挨个查看 字符的映射坐标 在as中对应的 值是否是1break}s = s[:len(s)-1]}return s // 返回 截取后的结果}其中 trimRightASCII 的 contains 是 查看位图集中是否有 字符映射 源码 如下:
// contains reports whether c is inside the set.
func (as *asciiSet) contains(c byte) bool {return (as[c/32] & (1 << (c % 32))) != 0 // 位运算 通过 列坐标获取 1左移后的 结果 与 通过行结果拿到set中的 结果,然后 与 运算 ,可查看c是否包含在 set 中。
}之所以 用 位图这种方法 不用 字符串循环查找 子串 主要是考虑到效率。位图集方式速度比字符串查找速度快很多,原因包括位图查找算法时间复杂度是o(1) 和 与或运算在硬件层面执行等,感兴趣的可以研究下。
7. Strings.Replace(s, old, new string, n int) string 函数
我们来看下 replace函数具体内容```go
func Replace(s, old, new string, n int) string {if old == new || n == 0 {return s // avoid allocation}// Compute number of replacements.if m := Count(s, old); m == 0 { // 计算字符串s 子串 old 的数量return s // avoid allocation} else if n < 0 || m < n {n = m}// Apply replacements to buffer.var b Builder // 这里用到了 Builder 比 + 速度快很多b.Grow(len(s) + n*(len(new)-len(old))) // 预先分配 空间 防止不断扩容start := 0 // 生成新字符串时 每次需要从s串截取的 子串 在s中的起始位置for i := 0; i < n; i++ {j := start // j 生成新字符串时 每次需要从s串截取的 子串 在s中的截止位置,初始化为 start位置if len(old) == 0 {if i > 0 {// 小细节 当i==0 时 下面 值wid 肯定为0,原因见下行解释 _, wid := utf8.DecodeRuneInString(s[start:]) // 如果 old 为空 其实就是在 每个单词旁边 添加 new,这时每次需要跳过 一个 utf-8 rune 元素,因为s中可能有中文(一个中文通常占3个字符) 如果一个字符一个字符跳 可能出现乱码j += wid}} else {j += Index(s[start:], old) // 通过计算 old 字符串在子串 s[start:] 中第一次出现的索引,再累加上次截止 索引,可找到 第 i+1 次 子串的 截止索引}b.WriteString(s[start:j]) //在s中 提取 第 i+1 个 子串b.WriteString(new) // 拼接需要替换的子串start = j + len(old) // 计算下次 起始位置}b.WriteString(s[start:]) // 将 s 字符串中后续没有 new 字符串的子串 拼接到 新字符串当中return b.String() // 将 内存中的byte[] 转换成字符串
}
可以看到 上述代码写的 逻辑清楚 层次分明 同时又短小精悍 简直简直了
总结
一直在用stings包,现在梳理了以便其源码,更加佩服大师们的能力了,考虑的很细节,而且优化大部分都是在最底层优化,考虑的层深至少是字节码和底层交互时的深度。所以越深入源码就是越深入优化的最核心部分,通到计算机最核心底层的优化才是真正的优化。
参考文章:
https://darjun.github.io/2021/05/18/youdontknowgo/string/
https://blog.csdn.net/ya_feng/article/details/105011464