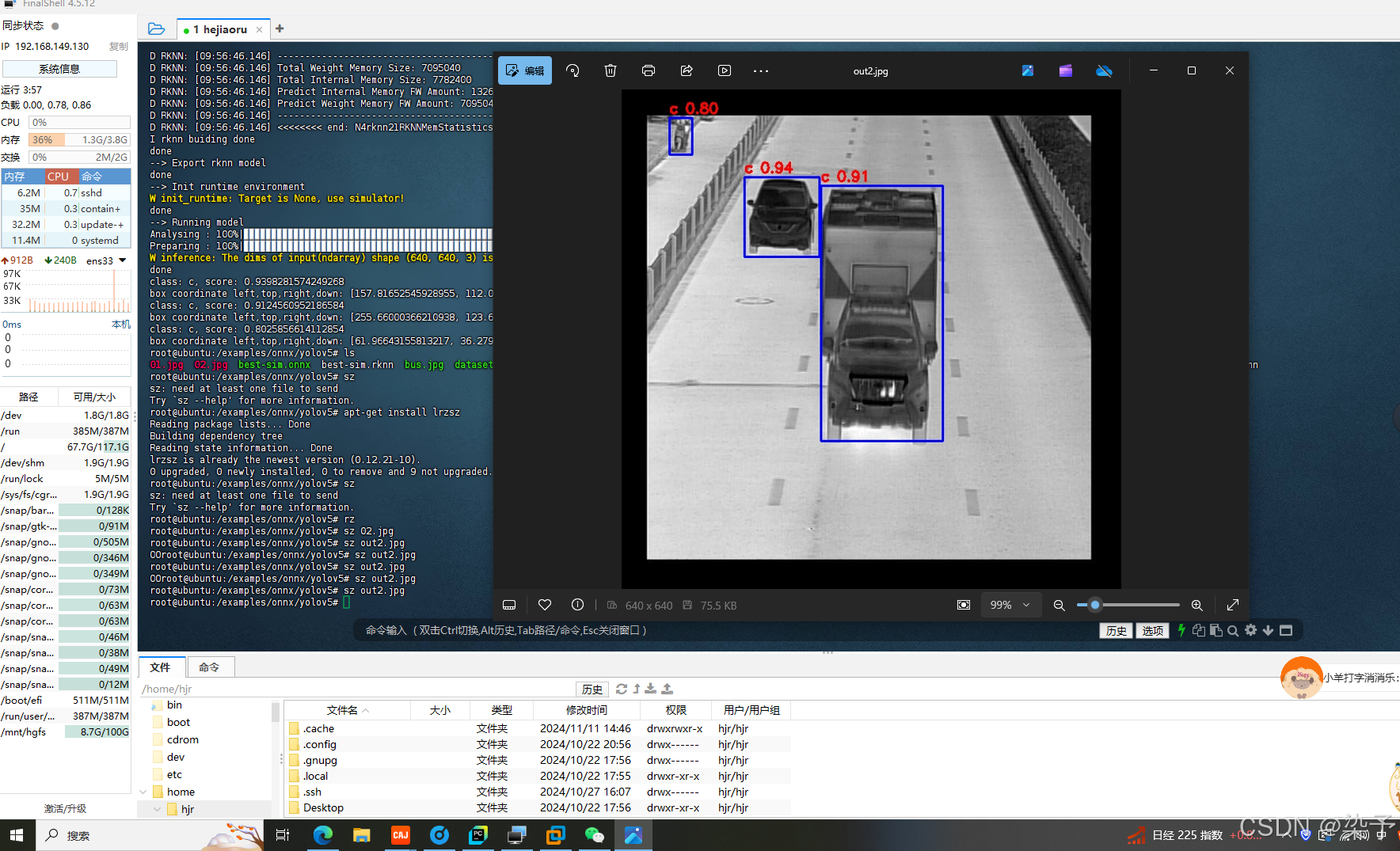
训练脚本:
python">from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torch import nn
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
import torch.nn.functional as F
import os
import distributed_patch# 设置 NCCL 日志环境变量
'''
os.environ["NCCL_DEBUG"] = "INFO"
os.environ["NCCL_DEBUG_SUBSYS"] = "ALL" # 或者 COLL
os.environ["NCCL_LOG_FILE"] = "nccl_log.txt"# 运行 PyTorch 分布式代码
'''class Net(nn.Module): # 模型定义def __init__(self):super(Net, self).__init__()self.flatten = nn.Flatten()self.seq = nn.Sequential(nn.Linear(28 * 28, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, 10))def forward(self, x):x = self.flatten(x)return self.seq(x)def main():dist.init_process_group(backend='nccl') # 【集合通讯】其他进程连master,大家互认rank = dist.get_rank()world_size = dist.get_world_size()device_name = f'cuda:{rank}'checkpoint = None # 各自加载checkpointtry:checkpoint = torch.load('checkpoint.pth', map_location='cpu') # checkpoint是cuda:0保存的,加载默认会读到cuda:0,所以明确指定给cpuexcept:passmodel = Net().to(device_name)if checkpoint and rank == 0: # rank0恢复模型参数model.load_state_dict(checkpoint['model'])model = DDP(model) # 【集合通讯】rank0广播参数给其他进程optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # model参数一致,则optim会保证其初始状态一致if checkpoint:optimizer.load_state_dict(checkpoint['optimizer']) # 各自加载checkpointtrain_dataset = MNIST(root='./data', download=True, transform=ToTensor(), train=True) # 各自加载datasetsampler = DistributedSampler(train_dataset) # 指派子集给各进程train_dataloader = DataLoader(train_dataset, batch_size=32, sampler=sampler, persistent_workers=True, num_workers=2)val_dataset = MNIST(root='./data', download=True, transform=ToTensor(), train=False)val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True, persistent_workers=True, num_workers=2)for epoch in range(20):sampler.set_epoch(epoch) # 【集合通讯】生成随机种子,rank0广播给其他进程model.train()for x, y in train_dataloader:x, y = x.to(device_name), y.to(device_name)pred_y = model(x) # 【集合通讯】rank0广播model buffer给其他进程loss = F.cross_entropy(pred_y, y)optimizer.zero_grad()loss.backward() # 【集合通讯】每个参数的梯度做all reduce(每个进程会收到其他进程的梯度,并求平均)optimizer.step()dist.reduce(loss, dst=0) # 【集合通讯】rank0汇总其他进程的lossif rank == 0:train_avg_loss = loss.item() / world_size# evaluateraw_model = model.moduleval_loss = 0with torch.no_grad():for x, y in val_dataloader:x, y = x.to(device_name), y.to(device_name)pred_y = raw_model(x)loss = F.cross_entropy(pred_y, y)val_loss += loss.item()val_avg_loss = val_loss / len(val_dataloader)print(f'train_loss:{train_avg_loss} val_loss:{val_avg_loss}')# checkpointtorch.save({'model': model.module.state_dict(), 'optimizer': optimizer.state_dict()}, '.checkpoint.pth')os.replace('.checkpoint.pth', 'checkpoint.pth')dist.barrier() # 【集合通讯】等待rank0跑完evalif __name__ == '__main__':main()# torchrun --nproc_per_node 1 pytorch_dis_gpu.py
插桩脚本:
python">import torch.distributed as dist# 保存原始函数引用
original_functions = {"init_process_group": dist.init_process_group,"all_reduce": dist.all_reduce,"reduce": dist.reduce,"broadcast": dist.broadcast,"barrier": dist.barrier,"get_rank": dist.get_rank,"get_world_size": dist.get_world_size
}# 插桩函数
def patched_init_process_group(*args, **kwargs):print("[distributed] init_process_group called")return original_functions["init_process_group"](*args, **kwargs)def patched_all_reduce(tensor, op=dist.ReduceOp.SUM, group=None, async_op=False):print("[distributed] all_reduce called")return original_functions["all_reduce"](tensor, op, group, async_op)def patched_reduce(tensor, dst, op=dist.ReduceOp.SUM, group=None, async_op=False):print("[distributed] reduce called")return original_functions["reduce"](tensor, dst, op, group, async_op)def patched_broadcast(tensor, src, group=None, async_op=False):print("[distributed] broadcast called")return original_functions["broadcast"](tensor, src, group, async_op)def patched_barrier(*args, **kwargs):print("[distributed] barrier called")return original_functions["barrier"](*args, **kwargs)def patched_get_rank(*args, **kwargs):print("[distributed] get_rank called")return original_functions["get_rank"](*args, **kwargs)def patched_get_world_size(*args, **kwargs):print("[distributed] get_world_size called")return original_functions["get_world_size"](*args, **kwargs)# 替换分布式接口函数为插桩版本
dist.init_process_group = patched_init_process_group
dist.all_reduce = patched_all_reduce
dist.reduce = patched_reduce
dist.broadcast = patched_broadcast
dist.barrier = patched_barrier
dist.get_rank = patched_get_rank
dist.get_world_size = patched_get_world_size