一、实验目的
- 阐述HBase在Hadoop体系结构中的角色;
- 能够掌握HBase的安装和配置方法
- 熟练使用HBase操作常用的Shell命令;
二、实验要求
- 学习HBase的安装步骤,并掌握HBase的基本操作命令的使用;
三、实验平台
- 操作系统:
- Linux(Ubuntu16.04);
- Hadoop版本:3.1.3;
- JDK版本:1.8;
- HBase版本:2.2.2
- 实验内容、结果及分析(直接在题目后面列出实验结果以截图及分析)
(实验代码参考网址:HBase2.2.2安装和编程实践指南_厦大数据库实验室博客)
(一)HBase安装配置(请根据你的Hadoop版本在官网:
https://hbase.apache.org/book.html#basic.prerequisites![]() https://hbase.apache.org/book.html查看匹配的HBase版本进行安装)
https://hbase.apache.org/book.html查看匹配的HBase版本进行安装)
1、减压,配置环境
2、 添加HBase权限
3、确定hbase安装成功
- 单机安装配置、分析各配置项的含义,并启动HBase验证安装是否成功,结束后关闭HBase;
1、配置hbase-env.sh和hbase-site.xml文件以及配置项含义分析:
(1)hbase-env.sh里面添加:
①设置 JAVA_HOME 环境变量
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
含义:指定 Java 安装目录,确保 HBase 能够找到正确的 Java 环境。
②设置 HBASE_MANAGES_ZK 为 true
export HBASE_MANAGES_ZK=true
含义:在伪分布式模式下,设置为 true 可以避免依赖外部的 ZooKeeper 服务,简化部署和管理。控制 HBase 是否自行管理 ZooKeeper,简化伪分布式模式下的部署。
true:表示 HBase 将自行启动和管理 ZooKeeper 实例。这适用于伪分布式和单节点部署。
false:表示 HBase 将使用外部提供的 ZooKeeper 服务。
③设置 HBASE_CLASSPATH 环境变量
export HBASE_CLASSPATH=/usr/local/hbase/conf
含义:确保 HBase 能够找到配置文件和其他必要的类库,指定 HBase 启动时需要包含的额外类路径,通常包括配置文件和其他库。
(2)hbase-site.xml添加:
配置项含义分析:
hbase.rootdir: 这个配置项用于指定 HBase 数据的存储位置。如果不设置,HBase 默认会将数据存储在 /tmp/hbase-${user.name},这意味着每次重启系统时,数据都会丢失。通过设置为 file:///usr/local/hbase/hbase-tmp,可以确保数据持久化存储在指定的目录中。
2、HBase验证安装成功:
3、HBase关闭并验证:
- 伪分布模式配置、分析各配置项的含义,启动HBase验证是否安装成功;
1、配置/usr/local/hbase/conf/hbase-env.sh
2、配置/usr/local/hbase/conf/hbase-site.xml
配置项含义分析
①hbase.rootdir:这个配置项用于指定 HBase 数据的存储位置。在伪分布式模式下,HBase 数据存储在 HDFS上,这里设置为 hdfs://Localhost:9000/hbase,表示数据存储在运行在本地的HDFS上,NameNode 监听在端口 9000。
②hbase.cluster.distributed: 这个配置项用于设置 HBase 是否运行在分布式模式。设置为true 表示 HBase 运行在分布式模式。
③hbase.unsafe.stream.capability.enforce: 这个配置项用于控制 HBase 是否强制执行流能力。在某些情况下,设置为false 可以避免一些兼容性问题。
3、测试运行HBase
(1)登录ssh
(2)启动HBase
中途出现问题
原因分析:namenode与datanode在其他进程中运行没有关闭
解决办法:尝试重新启动它们之前,先停止已经运行的 NameNode 和 DataNode。
4、切换目录至/usr/local/hbase;再启动HBase:
进入shell界面:
5、关闭Hbase并验证成功关闭:
- 配置系统环境变量PATH,添加HBase中bin和sbin路径到PATH中,验证配置是否成功;
1、配置:
2、验证成功
3、返回当前用户的主目录,关闭HBase,并查看是否关闭成功;
- HBase Shell命令完成下列任务:
启动HBase:
进入HBase:
- 创建一个新表,以”Student”命名,如果出错请分析错误原因并改正,实现表的创建;
- 查看创建的”Student”表的结构;
- 向已经创建好的表添加列族“info”、”scores”;
- 在“scores”列族中添加列“english”、”math”、“computer”;
- 向表中添加两条完整的数据记录,数据自定义,同时自定义列族“info”中相关列的信息;
- 查看表“Student”的所有记录数据;
- 根据指定的行键值查询对应数据记录的所有数据;
- 统计“Student”表中数据的行数
- 删除指定行键对应数据中所有的成绩数据;
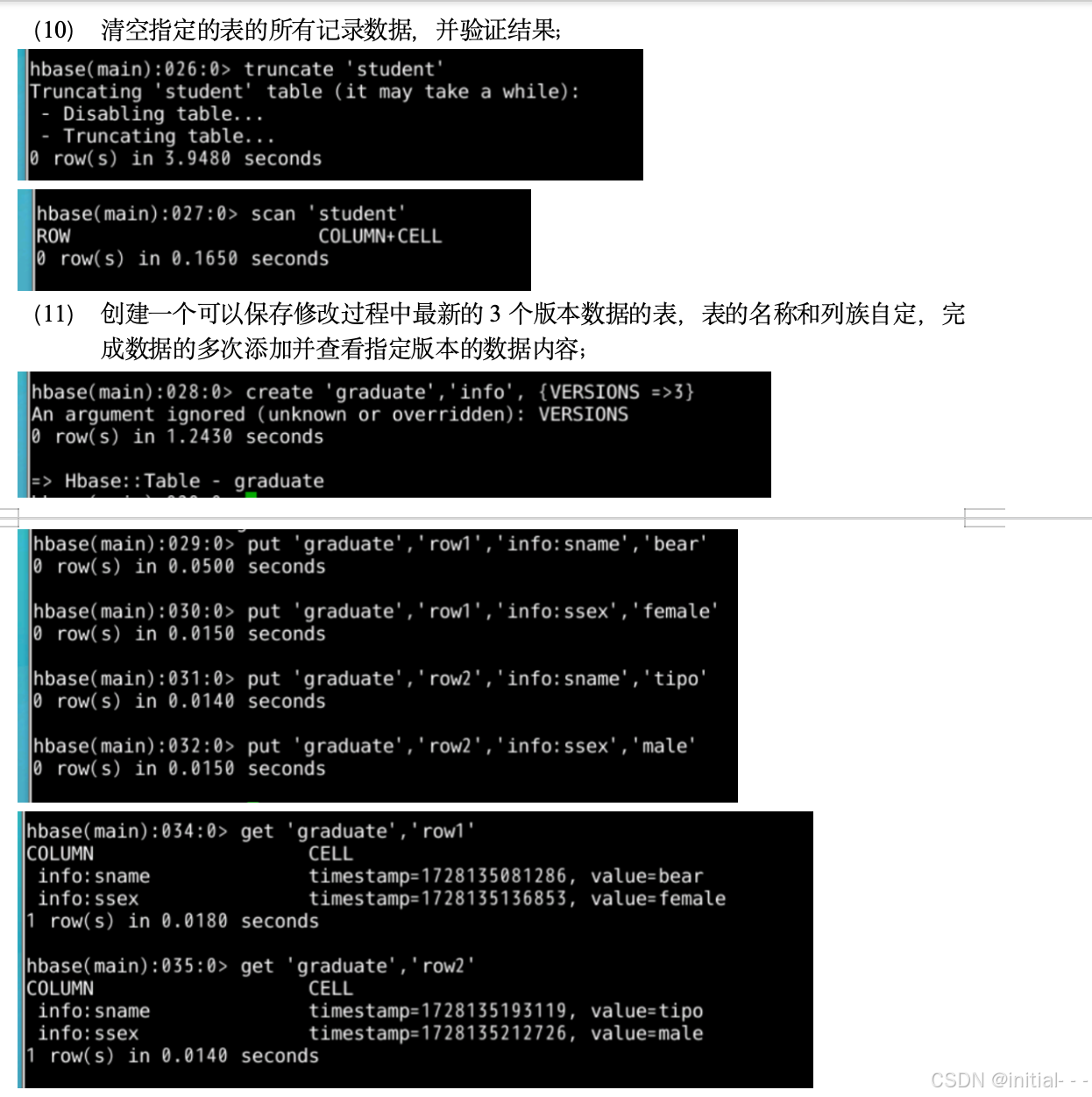
- 清空指定的表的所有记录数据,并验证结果;
- 创建一个可以保存修改过程中最新的3个版本数据的表,表的名称和列族自定,完成数据的多次添加并查看指定版本的数据内容;
- 总结HBase初次使用的优缺点;
优点:
水平扩展性:HBase设计用于水平扩展,可以处理PB级别的数据。
高性能:HBase提供了快速的读写访问,特别是对于随机实时读/写访问。
列族模型:HBase的列族模型允许用户定义数据的存储方式,有助于优化查询性能。
强一致性:HBase提供了强一致性的读写操作。
可伸缩的架构:HBase可以运行在廉价的硬件上,可无缝地扩展到成千上万的节点。
与Hadoop生态系统的集成:HBase与Hadoop生态系统紧密集成,可以与其他Hadoop组件(如HDFS、MapReduce、Hive、Pig等)一起工作。
自动分片:HBase表会自动根据行键进行分片,从而实现负载均衡。
缺点:
学习曲线:对于新手来说,HBase的学习曲线可能比较陡峭,因为它与传统的关系型数据库有很大不同。
缺乏事务支持:虽HBase支持行级别的事务,但它不支持跨行或跨表的复杂事务。
有限的查询能力:HBase不支持SQL查询,虽然有像Phoenix这样的项目试图提供SQL接口,但它们通常不如传统数据库的查询能力那么强大。
维护复杂性:HBase需要ZooKeeper进行集群协调,这增加了系统的复杂性。
数据模型限制:HBase的列族模型限制了数据模型的灵活性,不适合所有类型的数据存储需求。
数据一致性问题:虽然HBase提供了强一致性,但在某些情况下,如网络分区或服务器故障,可能会出现数据一致性问题。
资源消耗:HBase是一个资源密集型的系统,尤其是在大型集群中,可能会消耗大量的内存和CPU资源












- 问题和收获
问题:
数据模型设计:确定如何设计表、行键和列族很具有挑战性。
故障恢复:在集群出现故障时,恢复数据和服务会很复杂。
监控和维护:监控HBase集群的性能和健康状况需要专业的工具和技能。
版本兼容性:不同版本的HBase或Hadoop生态系统组件之间存在兼容性问题。
安全性:确保数据的安全性和遵守相关的数据保护法规很复杂。
收获:
分布式系统知识:通过使用HBase,你可以获得关于分布式系统架构、数据一致性和容错机制的深入理解。
大数据技能:HBase是处理大数据的有力工具,使用它可以帮助你掌握处理大规模数据集的技能。
性能优化:在调优HBase的过程中,你将学会如何优化数据库性能,包括读写路径、内存使用和存储。