文章主要工作
- 论述了构建网络安全知识库的三个步骤,并提出了一个构建网络安全知识库的框架;
- 讨论网络安全知识的推演
1.框架设计
总体知识图谱框架如图1所示,其包括数据源(结构化数据和非结构化数据)、信息抽取及本体构建、网络安全知识图谱的生成: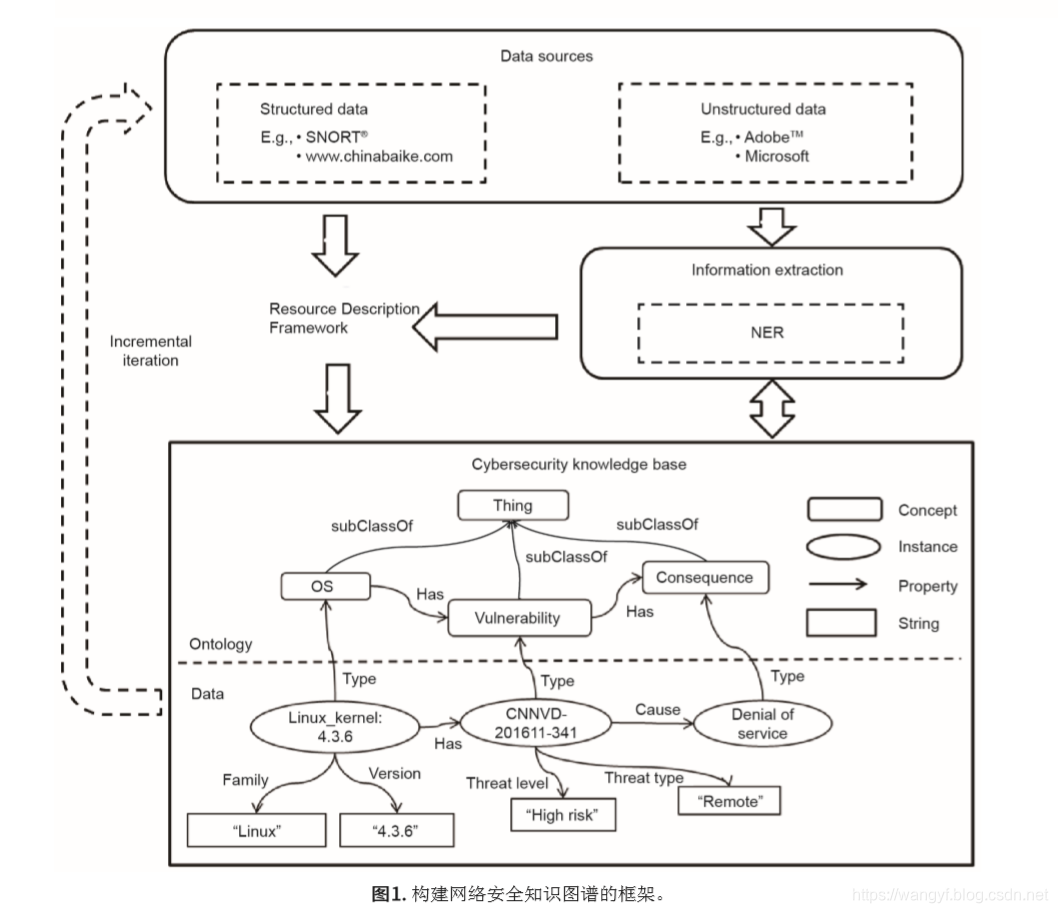
1.1 网络安全本体构建
文中提出了一个基于网络安全知识库的五元组模型,该模型包含:概念、实例、关系、属性和规则。网络安全知识库的架构如图2所示。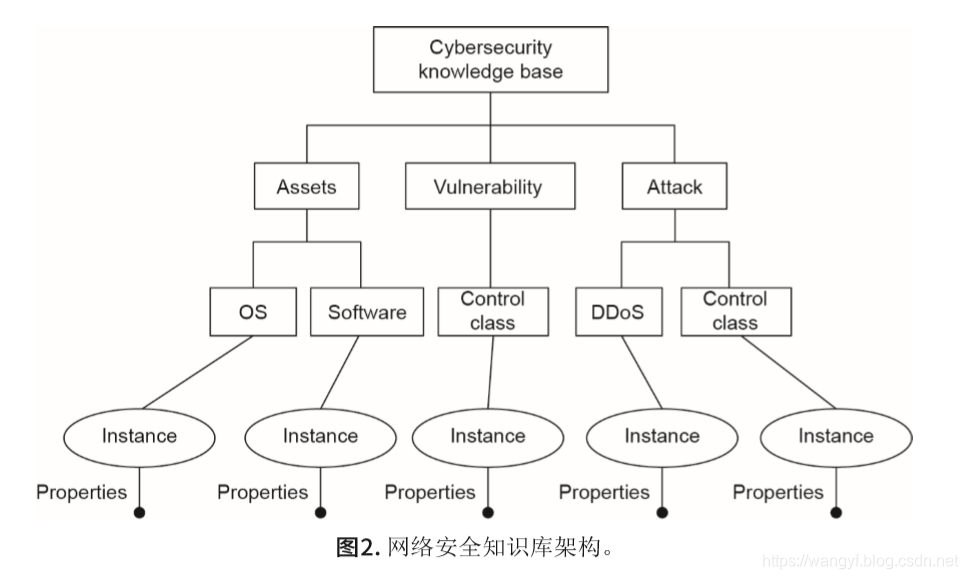
该架构如图2所示,其中包括三个本体:资产(Assets)、漏洞(Vulnerability)和攻击(Attack)。图3表示网络安全本体,其中包含五个实体类型:漏洞、资产、软件、操作系统、攻击。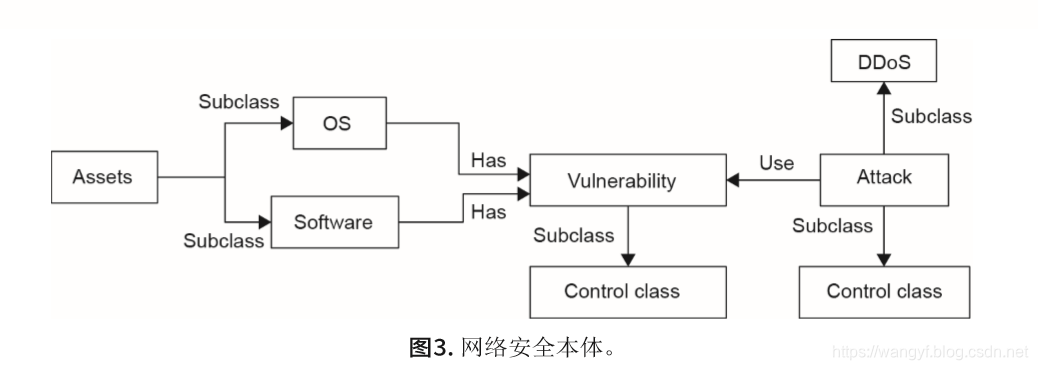
1.2 基于机器学习提取网络安全相关实体
由于条件随机场模型(CRF)保留了条件概率框架的优点,如最大熵Markov 模型,也解决了标记偏差的问题,所以适用于命名实体识别。
Stanford NER提供了线性链条件随机场(CRF)序列模型的一般实现,于是文中使用它来提取网络完全相关的实体。下面是Stanford NER的一些主要特征:
- UseNGrams:利用n-gram取特征,即词的子串。
- MaxNGramLeng:这个特征的值类型为整型。如果这个特征的值为正,则大于该值的n-gram将不会在 模型中使用。在本文中,我们将maxNGramLeng的值设 置为6。
- UsePrev:这可以给我们提供<previous word, class of previous word>的特征,并与其他选项一起启用, 如<previous tag,class>。这导致基于当前单词与一对< previous word,class of previous word >之间的关系的特 征。当有连续的词属于同一个类时,这个特征将是非常 有用的。
- UseNext:和UsePrev特征非常相似。
- UseWordPairs:这个特征基于两个词对—— <Previous word,current word,class> 和 <current word, next word,class>。
- UseTaggySequences:这是一个重要的特征,它 使用类的序列而不是单词的集合,而是使用第一、第二 和第三顺序类和标签序列作为交互特征。
- UseGazettes:如果为真,则由下一个名为“gazette”的特征将把文件指出为实体字典。
- Gazette:该值可以是一个或多个文件名(以逗 号、分号或空格分隔的名称)。如果从这些文件加载公 开的实体词典,每行应该是一个实体类名称,后跟一个 空格,后面再跟上一个实体。
- CleanGazette:如果这个值为真,则仅当全部词 在字典中被匹配时,此特征才会触发。如果在字典中 有一个词“Windows 7”,那么整个词应该在字典中进 行匹配。
- SloppyGazette:如果这个值为真,词和字典中 的词局部匹配也能触发这个特征,如“Windows ”可以 和“windows 7”进行匹配。
2. 知识推演
2.1 数据源
- 漏洞的来源:CVE、NVD、 SecurityFocus、CXSECURITY、Secunia、中国国家漏 洞数据库(CNVD)、 CNNVD和安全内容自动化协议中 国社区(SCAP)。
- 攻击的数据来源
(1).一类来自信息安全网站,其中包括Pediy BBS、Freebuf、 Kafan BBS和开放Web应用安全项目(OWASP);
(2).另一 类来自企业自建信息响应中心,包括360安全响应中心 (360SRC)和阿里巴巴安全响应中心(ASRC)。
2.2 属性推演
如图4所示,图中有三个实例:Ni、Nj和Nl,每一个实例对应一对(key,values)值。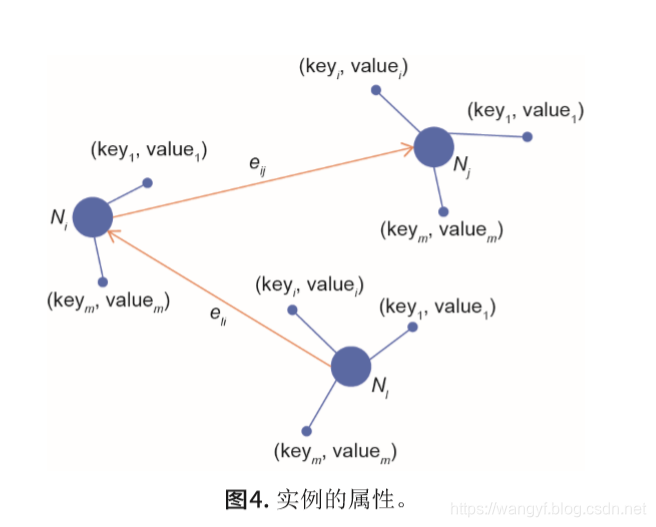
属性值Valueik的 预测公式如下: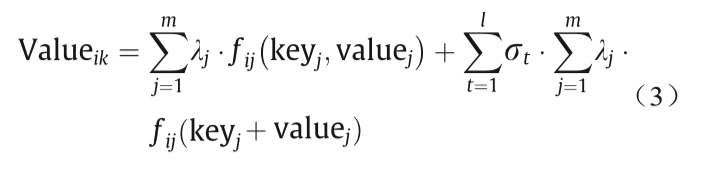
对于实例Ni,通过计算下述公式可以得到新的属性,如图5所示。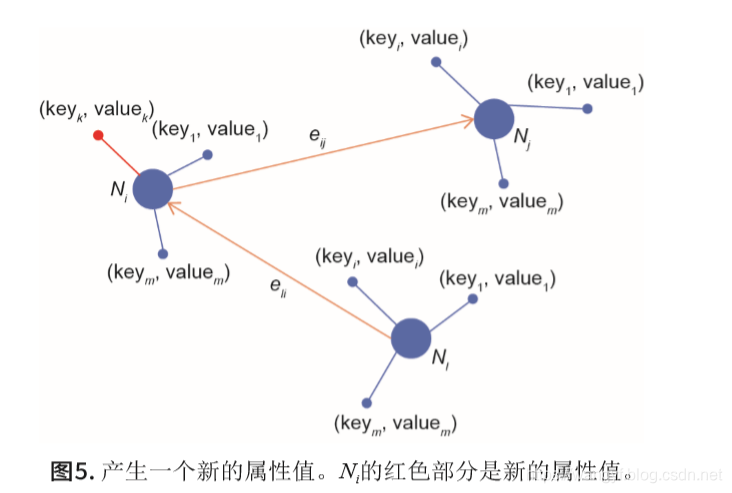
2.3 关系推演
常用推理方法有三种:基于嵌入的技术、基于低维 向量表示和路径排序算法。在本文中,我们选择使用路径排序算法。路径排序的基本思想是使用连接两个实体的路径作为特征来预测两个实体之间的关系。实例Ni、Nj和Nk 之间的属性值和关系如图6所示。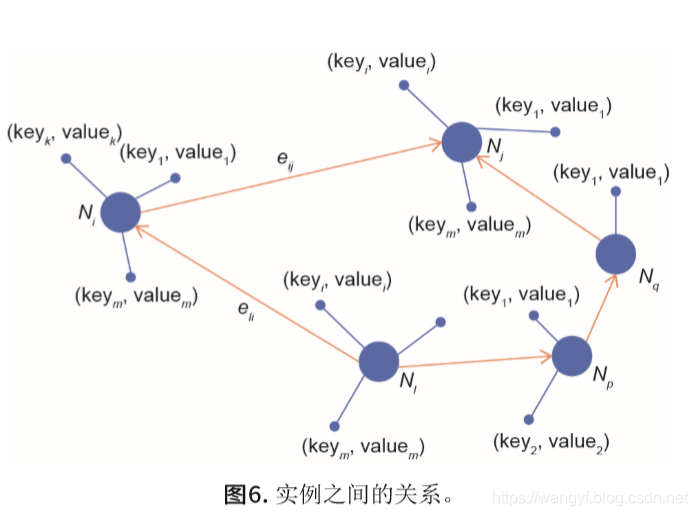
关系推理的预测公式如下: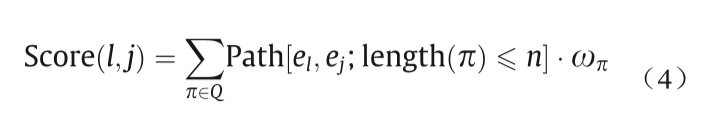
式中,π为所有从l到j的可达路径,length(π)≤n。如果 Score(l, j)≥τ,τ为阈值,则elj成立;否则不成立。通过路径排序算法可以得到新的关系,如图7所示。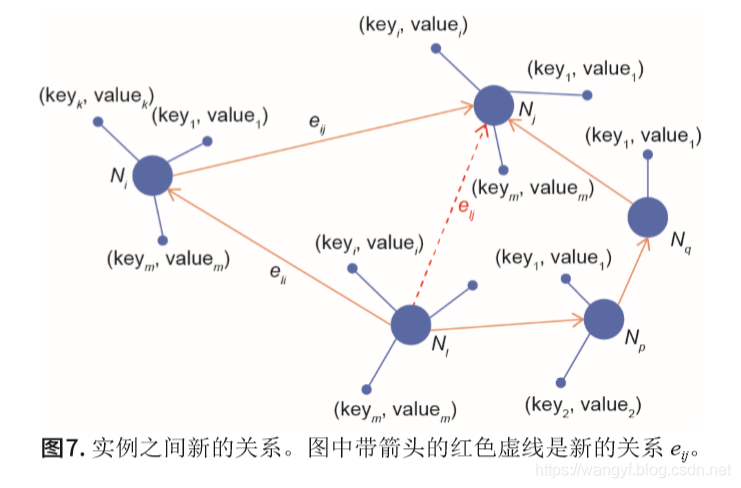
2.4 评估标准
在信息检索和提取系统中,有两个主要的评估指 标,包括精确率和召回率。有时,为了全面评估系统的性能,通常计算精确率和召回率的调和平均值。这就是我们通常所说的F-Measure。在本文中,我们使用 F-Measure的特殊形式F1值。精确率、召回率和F1值由真正、假正和假负定义。定义如下:
- 真正(TP):将正类预测为正类数。
- 假正(FP):将负类预测为正类数。
- 假负(FN):将正类预测为负类数。
精确率(Precision)由以下公式给出: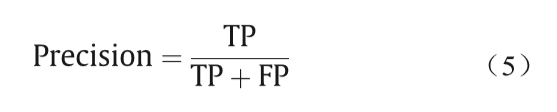
召回率(Recall)由以下公式给出:
F1值由以下公式给出: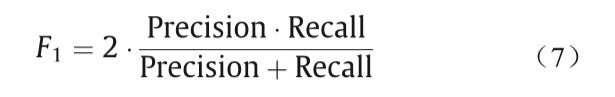
2.5 实验结果(主要复制文章细节)
为了验证useGazettes的影响,我们建立了三个模型 (NER1、NER2和NER3)。
- NER1没有使用useGazettes作为它的特征
- NER2使用useGazettes,并选择了cleanGazette选项
- NER3也使用了useGazettes,但是它选择了 sloppyGazette选项。
然后,采用了10倍交叉验证的方法 来评估这些模型,将数据分成10个数据块,将十分之九的块用作训练数据,其余用作测试数据。
NER1的平均识别结果如表1所示,该表显示结果的精度相对较高。对于F1度量,软件和漏洞的识别率相近,且高于其他任何实体类型,也就是说, 软件和漏洞的识别在整体识别效果方面取得了良好的表现。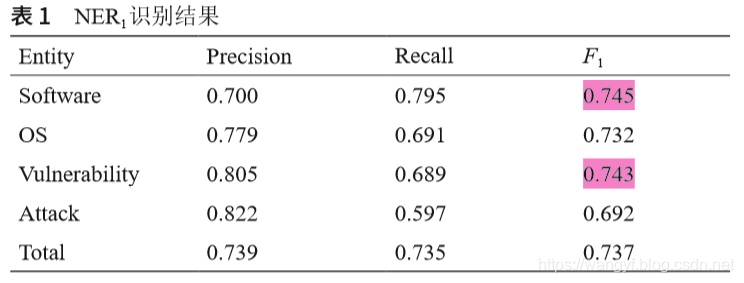
然后,我们使用了包含useGazettes的特征,并选择 了cleanGazette的选项来训练NER2。NER3是根据包含 useGazettes和sloppyGazette两个选项的特征进行训练的。 平均识别结果如表2所示。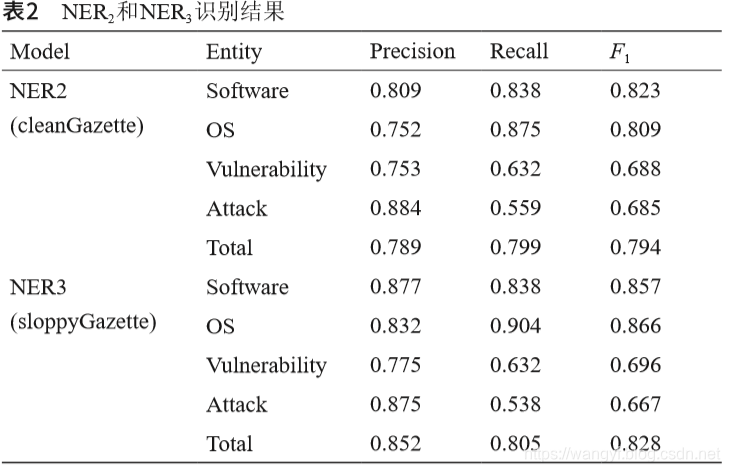
如表2所示,在NER2的识别结果中,对软件的识别取得了良好的整体表现。对于NER3,OS的识别实现了高F1值。就软件和操作系统的认可而言,NER3的整体 性能比NER2好。这个结果表明sloppyGazette选项有助于识别与网络安全相关的实体。NER2和NER3的后果和平均值的F1测量值仍然很低,均小于70%。图8给出了这三种模型之间的直观比较。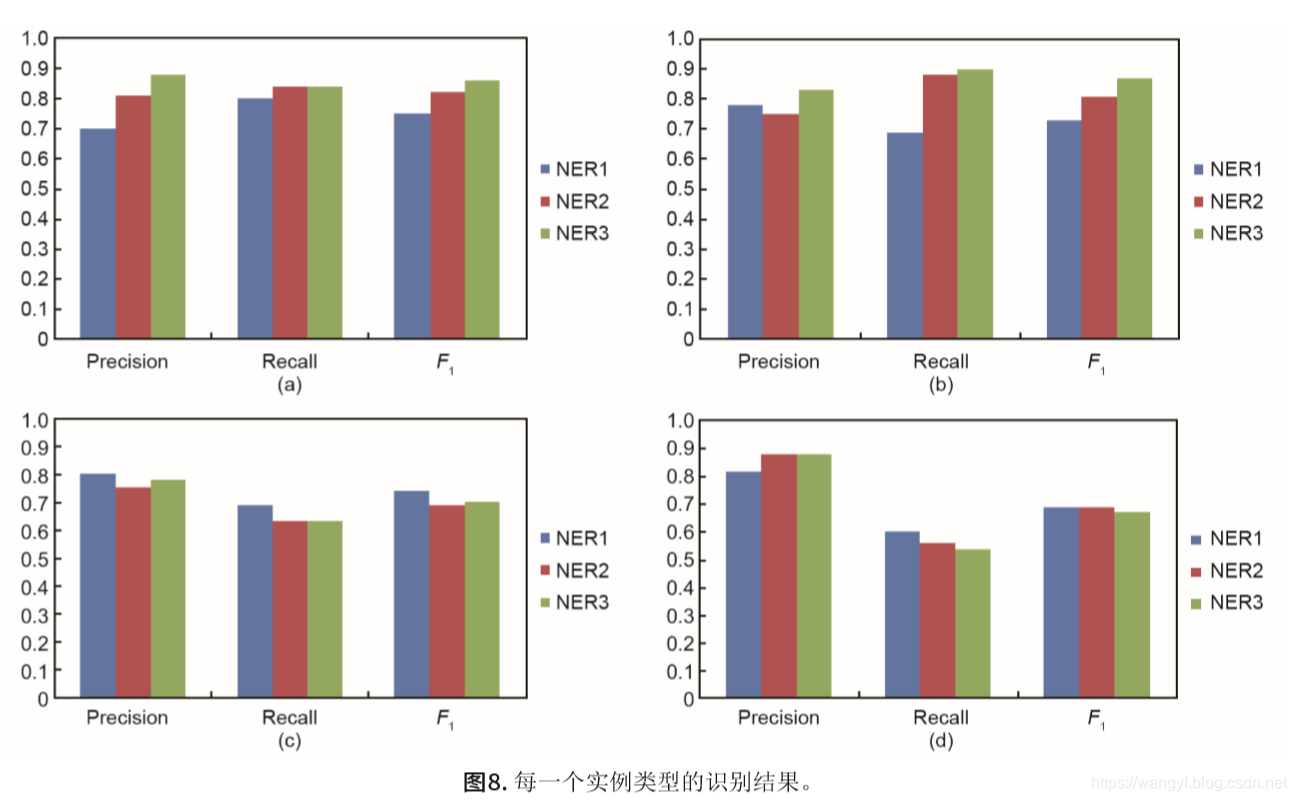
from:https://cloud.tencent.com/developer/article/1556641
1安全知识图谱
智慧安全知识图谱[9](Intelligent Cyber Security Knowledge Graph)是知识图谱在网络安全领域的实际应用,包括基于本体论构建的安全知识本体架构,以及通过威胁建模等方式对多源异构的网络安全领域信息( Heterogeneous Cyber Security Information)进行加工、处理、整合,转化成为的结构化的智慧安全领域知识库。
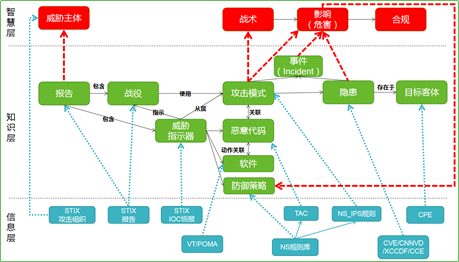
针对信息安全领域知识图谱构建的两个关键要素,构建了威胁元语言模型对威胁知识的结构化描述,包括概念、实体、属性的定义以及知识关系的定义。研究中依据STIX2.0以及领域专家知识,构建三层安全知识图谱,如下图所示。知识图谱辅助安全事件分析、安全合规标准、APT追踪溯源等实际业务场景所需的数据表示和语义关系。
![]()
图2.1 安全知识图谱
其中信息层为知识图谱从外界抽取的知识实体,知识层和智慧层为信息安全领域关键概念及这些概念之间的逻辑语义关系。
在威胁元语言模型中,威胁实体构建和实体关系是两个最为关键两个步骤。
2图嵌入
知识图谱最大的特点是具有语义信息,然而构建好的内网安全知识图谱如何应用到内网威胁识别中。这就需要一些图分析方法,传统的图分析方法主要是:路径分析(可达性,最短路径,k-out),社区发现等。利用图模型做内网威胁识别,一个很直接的方法是利用社区发现[4,5,6]方法对威胁主体进行社区划分,把威胁度高的攻击主体划到一起,从而实现威胁识别。理论上这种方法是可行的,因为构建的实体与实体之间的关联和行为在社区内关系紧密,而在社区间关系稀疏。
而现有社区发现方法一方面只考虑顶点的邻居关联,忽略了潜在的近邻关系,同时,社区发现的复杂度较高,不适合大规模图分析。
为了对这种高维图模型进行降维,图嵌入技术应运而生,图嵌入的本质是在尽量保证图模型的结构特性的情况下把高维图数据映射到低维向量空间。发展到现在图嵌入技术已经不仅仅是一种降维方法,与深度学习相结合后图嵌入技术可以具有更复杂的图计算与图挖掘功能。
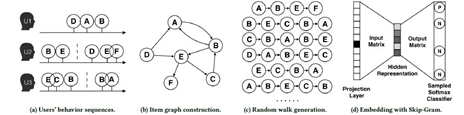
图2.2 图嵌入流程
首先图2.2(a)中是用户行为,从知识图谱的角度可以抽象成图2.2(b)中的图模型。在当前推荐系统和安全领域都比较常见,而对于抽象的图模型如何利用图嵌入技术处理呢?首先,DeepWalk[1,2,3]将随机游走得到的节点序列当做句子,从截断的随机游走序列中得到网络的部分信息,再经过部分信息来学习节点的潜在表示。该方法借助语言建模word2vec中的一个模型,skip-gram来学习节点的向量表示。将网络中的节点模拟为语言模型中的单词,而节点的序列(可由随机游走得到)模拟为语言中的句子,作为skip-gram的输入。可以看出在表示图模型中图嵌入技术有天然的优势,因为它本身把多维图模型映射到同一向量空间,顶点之间的关联关系可以通过顶点向量的相似度计算,任一顶点与其他顶点的潜在关系都可以很快的计算出来。
当前已有一些针对社区发现的图嵌入技术[6,7]。社区嵌入可以描述其成员节点在低维空间中的分布情况,所以这次不能简单的把社区看成一个向量,而是低维空间中的分布(高斯混合分布)。
一方面,节点嵌入可以帮助改进社区检测,从而输出良好的社区以适应更好的社区嵌入,另一方面,社区嵌入可以通过引入a community-aware 高阶近似性来优化节点嵌入。在这指导下,提出了一个新的社区嵌入框架,如图2.3所示。

图2.3 社区感知的图表示框架
三、基于安全知识图谱的内网威胁识别
基于知识图谱的内网威胁主要包括三部分:图模型构建、图嵌入和威胁评估。针对内网威胁已经有一些检测组件,但是通常这些检测设备之间缺少关联性,需要安全人员组合不同组件的告警利用经验分析,而图模型本身具有很强的关联性,可以有效关联多源数据,并且易于下钻。
1图模型构建
图模型的构建主要是确实图中的实体与关系,实体的选择通常比较容易确定,通常以ip、端口、网段、告警、文件、日志等实体为主,而关系通常分为显示关系与隐式关系,显示关系是直接可以得到的关系,而隐式关系是通过数据挖掘方法得到的一些数据中暗含的关联关系。
1.1
实体构建
实体的构建根据场景的不同会有不同选择,可以参照STIX2.0中的十二个对象域的划分,以及当前世界范围内对安全元素描述的使用较为广泛的标准来确定实体,本文只介绍几个核心实体类型:
攻击模式:攻击发起者使用的策略、技术和程序,参考:通用攻击模式枚举和分类(CAPEC)、MITRE公司的PRE-ATT&CK、ATT&CK、Kill Chain
目标客体:攻击目标资产,参考:通用平台枚举(CPE)
威胁主体:攻击发起者,可以是个人、团体和组织,参考:威胁代理风险评估(TARA)中的威胁代理库
战役:针对具体目标的一系列恶意行为或攻击
威胁指示器:在检测或取证中,具有高置信度的威胁对象或特征信息。
内网环境中的威胁主体是指攻击的发起者,通常指两类,一类是组织内部人员由于个人原因有意或无意的造成的违规行为;一类是外部用户伪装成内部用户进行一些攻击行为。目标客体通常是攻击的目标,通常是网段、端口、终端及文件等。攻击模式包含已有的一些通用攻击策略相关知识,如果攻击链,att&ck,等,现在一些威胁检测组件产生的告警信息已经包含了部分相关知识。
1.2
关系构建
关系的构建包括直接关系与间接关系构建。直接关系比较容易得到,内网环境中通常能通过日志、沙箱、原始流量和外部数据直接得到的关系对,例如,文件访问域名,域名解析IP,文件访问IP等。
间接关系是通过间接关联得到的关系,比如使用同一种攻击工具的攻击者有一定的相似性,文件与文件通过相似度计算得到的相似性等等都属于间接关系。这样通过直接关系与间接关系的构建就构成了内网安全知识图谱。
工业互联网安全漏洞知识图谱构建
本文提出的基于知识图谱的工业互联网安全漏洞分析方法如图1所示。首先从ISVD漏洞库原始数据中提取出全部的3 727条工业互联网安全漏洞信息,形成漏洞节点。此外,对漏洞原始信息进行半自动化分析,提取出漏洞信息中涉及的工业互联网安全事件以及工业互联网产品,分别形成事件节点和产品节点。在提取出各类节点之后,将节点信息注入关联分析引擎,对事件与漏洞、漏洞与产品、产品与事件这三类关联关系进行梳理与记录。至此,工业互联网安全漏洞知识图谱关键组件:节点、节点间的关联关系都已经生成。将节点与节点间关联关系存储至Neo4j图数据库的方式有两种:一是利用Python库py2neo实现数据的插入;二是使用Neo4j官方提供的工具Neo4j-import,将节点信息文件nodes.csv与关联关系信息文件relation.csv导入Neo4j。
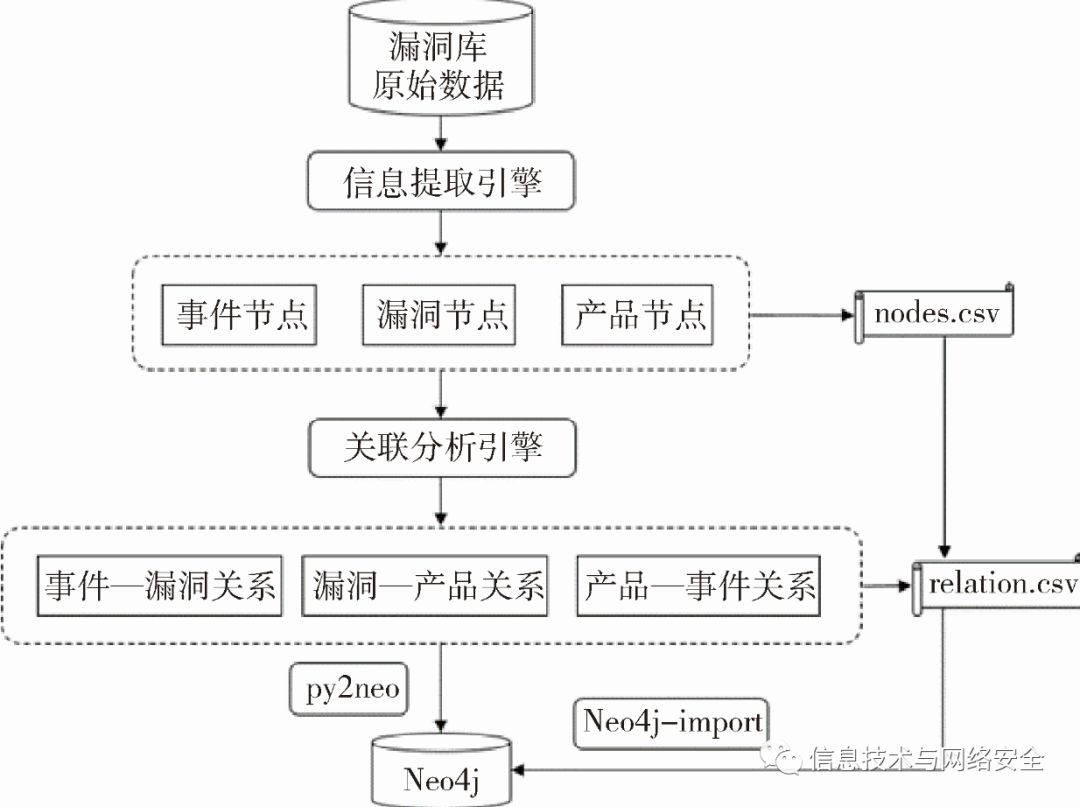
图1工业互联网安全漏洞知识图谱分析方法
2.1原始数据信息提取
ISVD中的漏洞信息是本文进行研究与分析的基础数据信息。主要包括如下字段:isvdId(ISVD漏洞ID)、name(漏洞名称)、dateTime(发布时间)、cveId(CVE-ID)、riskLevel(风险级别)、vulType(漏洞类型)、description(漏洞描述)、deviceList(影响设备)、refer(参考资料)、supplier(供应商)、patch(补丁信息)、score(漏洞评分)、eventId(事件ID)、eventDescription(事件描述)等。每一个漏洞信息条目不仅对漏洞自身属性进行了详细的描述,而且对漏洞涉及的产品和事件进行了记录。但是产品和事件信息与漏洞信息杂糅在一起,难以梳理出漏洞、产品、事件之间的逻辑关系。因此,本文的工作在此基础上进行了信息的提取与关联分析。
信息提取引擎的工作,目的是将漏洞信息、事件信息、产品信息从原始数据中提取出来,并形成节点,用于知识图谱的构建。
首先,介绍信息提取引擎的提取规则。
规则1:漏洞节点中的eventId、eventDescription字段,直接映射到事件节点中的eventId、eventDescription。
规则2:通过正则表达式在eventDescription中匹配事件时间的描述,若存在,则规范化为****-**-**的形式并记录在eventTime字段;若不存在,则将漏洞节点的dataTime直接映射到事件节点的eventTime。
规则3:将漏洞节点中的deviceList直接映射到事件节点的deviceList,若同一eventId对应多条漏洞,则将deviceList进行增量补充。
规则4:将漏洞节点中的cveId、cnnvdId、cnnvdId等唯一标识漏洞条目的字段,按照上述优先级直接映射到事件节点的vulnerabilities,若同一eventId对应多条漏洞,则将vulnerabilities进行增量补充。
规则5:遍历漏洞节点,将其中的deviceList字段内容进行分割,并赋予唯一性标识productId:PID,规范化数据以自动化方式直接映射,非规范化数据使用人工处理的方式。
规则6:将漏洞节点中deviceList切割后的内容直接映射到产品节点的productVersion字段。
规则7:若漏洞节点中的漏洞描述字段(description)包含漏洞涉及产品的相关描述(模糊匹配),则将匹配到的内容映射到产品节点的productDescription。
规则8:将漏洞节点中的cveId、cnnvdId、cnnvdId等唯一标识漏洞条目的字段,按照上述优先级直接映射到产品节点的vulnerabilities,若同一产品对应多条漏洞,则将vulnerabilities进行增量补充。
其次,介绍各类节点的构成以及节点示例。对于漏洞节点来说,其内部构成与ISVD漏洞数据结构和内容没有大的差别,较为完整与详细地记录了漏洞的自身属性以及相关的产品与事件属性。以ISVD-2014-0824漏洞为例,其漏洞节点部分信息如表1所示。

对于事件节点,维度相较于漏洞节点少一些。一方面,安全事件自身的敏感性导致其事件细节不会被广泛公开,这就给信息安全研究者的事件分析带来了难度;另一方面,安全事件数据侧重于语言描述,缺乏结构性信息。事件ID(eventId)用来唯一标识事件,事件描述(eventDescription)从事件发生背景、攻击手段、事件影响等方面进行说明,事件发生时间(eventTime)记录事件发生的时间属性,设备列表(deviceList)记录了此次安全事件中主要涉及的存在漏洞的产品信息,漏洞(vulnerabilities)记录了该事件涉及的漏洞编号。以事件ISED-2014-0001为例,其事件节点信息如表2所示。

产品节点记录了工业互联网安全漏洞涉及的主要产品的ID、产品版本、产品描述及其相关漏洞编号。由于原始数据中对产品的描述并不多,因此当前产品节点信息量不够丰富。在后续的工作中,建设工业互联网产品知识库并与ISVD进行信息共享以实现优势互补,是一个重要的研究方向。以产品ISPD-2018-0001为例,其产品节点信息如表3所示。

2.2关联分析
知识图谱中的另一个重要构成要素就是关系(Relationship)。关系,将各个分散的节点关联在一起,表现出逻辑性,体现了数据的深层次价值。工业互联网安全漏洞知识图谱关注于三类关系:事件—漏洞关系、漏洞—产品关系、产品—事件关系。关联分析引擎的作用就是以前文所述节点为基础,对这三类关联关系进行挖掘并存储。
首先,介绍关联分析引擎的关联规则。
规则9:遍历事件节点,对于eventId:EID、vulnerabilities字段数值同时存在的情况,对每一个从eventId:EID到vulnerabilities的映射,建立一个从事件ID指向漏洞ID的关系。
规则10:遍历产品节点,对于productId:PID、vulnerabilities字段数值同时存在的情况,对每一个从productId:PID到vulnerabilities的映射,建立一个从产品ID指向漏洞ID的关系。
规则11:遍历事件节点,对于eventId:EID、vulnerabilities字段数值同时存在的情况,以vulnerabilities为线索遍历产品节点,对每一个从eventId:EID到productId:PID的映射,建立一个从事件ID指向产品ID的关系。
其次,介绍各类关系的构成以及关系示例。
事件—漏洞关系包括事件ID(:EID)、类型(type)、漏洞ID(:VID)三个字段。以ISED-2014-0001事件为例,该事件涉及两个漏洞,类型字段为include,两个漏洞分别是ISVD-2014-0824、ISVD-2014-0015,如表4所示。

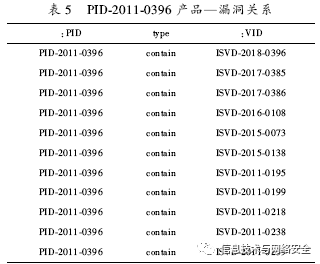
漏洞—产品关系包括产品ID(:PID)、类型(type)、漏洞ID(:VID)三个字段,如表5所示。
事件—产品关系包括事件ID(:EID)、类型(type)、产品ID(:PID)三个字段,ISED-2014-0001事件为例,该事件涉及7个产品,类型字段为involve,如表6所示。




