【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
- 1. LeNet-5网络
- ※ LeNet-5网络结构
- 2. 读取数据
- 2.1 Torchvision读取数据
- 2.2 MNIST & FashionMNIST 下载解包读取数据
- 2. Mnist
- ※ 训练 LeNet5 预测分类
- 3. EMnist
- ※ 训练 LeNet5 预测分类
- 4. FashionMnist
- ※ 训练 LeNet5 预测分类
- 5. CIFAR-10
- ※ 训练 LeNet5 预测分类
1. LeNet-5网络
标志:经典的卷积神经网络
LeNet-5由Yann Lecun 提出,是一种经典的卷积神经网络,是现代卷积神经网络的起源之一。
Yann将该网络用于邮局的邮政的邮政编码识别,有着良好的学习和识别能力。
※ LeNet-5网络结构
LeNet-5具有一个输入层,两个卷积层,两个池化层,3个全连接层(其中最后一个全连接层为输出层)。

下面我们以灰度值黑白图像为例,描述LeNet网络结构,其中:”接纳“表示”中间层输入“,”传递“表示”中间层输出“。
层次结构:
- 输入层 (Input Layer)
- 输入尺寸:32 × 32 数据图
- 灰度值:0 ~ 255(一般进行预处理)
- 传递通道数:1
- 卷积层 C1 (Convolutional Layer c1)
- 卷积核尺寸:5 × 5
- 卷积核数量:6
- 步长:1
- 填充:0
- 传递尺寸:28 × 28 特征图
- 传递通道数:6
- 子采样/池化层 S2 (Subsampling Layer S2)
- 类型:MaxPooling
- 窗口尺寸:2 × 2
- 步长:2
- 传递尺寸:14 × 14 特征图
- 传递通道数:6
- 卷积层 C3 (Convolutional Layer c3)
- 卷积核尺寸:5 × 5
- 卷积核数量:16
- 步长:1
- 填充:0
- 传递尺寸:10 × 10 特征图
- 传递通道数:16
- 子采样/池化层 S4 (Subsampling Layer S4)
- 类型:MaxPooling
- 窗口尺寸:2 × 2
- 步长:2
- 传递尺寸:5 × 5 特征图
- 传递通道数:6
- 全连接层 C5 (Fully Connected Layer C5)
- 展平尺寸:400 ( 25 * 16 )
- 传递尺寸:120
- 全连接层 C6 (Fully Connected Layer C6)
- 接纳尺寸:120
- 传递尺寸:84
- 输出层 (Output Layer)
- 接纳尺寸:84
- 输出尺寸:10
Same卷积 & Full卷积 & Valid卷积:
- Same卷积:根据卷积核大小对输入特征图自适应 零填充 (以k定p),确保输出的特征图大小与输入的特征图尺寸相同。
- Full卷积:允许卷积核超出特征图范围,但须确保卷积核边缘与特征图边缘相交。Same卷积是特殊的Full卷积。
- Valid卷积:卷积过程中不使用填充,输出特征图的尺寸小于输入特征图的尺寸。
本文 Torch & Torchvision版本:

2. 读取数据
2.1 Torchvision读取数据
Datasets 使用
torchvision.datasets模块包含多种预定义类型的数据集,例如MNIST、EMNIST、FashionMNIST、CIFAR-10、ImageNet等。它封装了这些数据集的下载、加载和预处理步骤。
torchvision.datasets 4个参数
- root:字符串类型,指定存放路径
- train:布尔类型,区分训练集与测试集
- download:布尔类型,开启下载,若本地存在则不进行下载
- transform:用于对数据预先处理的转换
2.2 MNIST & FashionMNIST 下载解包读取数据
定义读取函数
python">""" 定义读取函数 """
def load_mnist(path, kind='train'):import osimport gzipimport numpy as np""" Load MNIST data for `path` """labels_path = os.path.join(path, '{}-labels-idx1-ubyte.gz'.format(kind))images_path = os.path.join(path, '{}-images-idx3-ubyte.gz'.format(kind))with gzip.open(labels_path, 'rb') as lbpath:labels = np.frombuffer(lbpath.read(), dtype=np.uint8, offset=8)with gzip.open(images_path, 'rb') as lbpath:images = np.frombuffer(lbpath.read(), dtype=np.uint8, offset=16).reshape(len(labels), 28*28)return images, labels
抽取:训练集测+ 试集
python">X_train, y_train = load_mnist(path="./data/mnist")
X_test, y_test = load_mnist(path="./data/mnist", kind='t10k')
自定义 Pytorch Dataset 类
python">""" 自定义 Pytorch Dataset 类 """
class MnistDataset(Dataset):def __init__(self, data_path, kind=None, transform=None):self.transform = transformimages, labels = load_mnist(path="./data/mnist", kind=kind)2. Mnist
Mnist数据集:手写数字识别数据集,数据集分为训练集和测试集,用以训练和评估机器学习模型。
该数据集在深度学习领域具有重要地位,尤其适合初学者学习和实践图像识别技术。
- 该数据集含有
10种类别,共70000张灰度图像。包含 60000个训练集样本 和 10000个测试集样本。 - 每张图像以 28×28 像素的分辨率提供。
MNIST是一个手写数字数据集,该数据集由美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)发起整理。该数据集的收集目的是希望通过算法,实现对手写数字的识别。
1998年,Yan LeCun 等人首次提出了LeNet-5 网络,利用上述数据集实现了手写字体的识别。
MNIST数据集由4个部分组成,分别为训练集图像、训练集标签、测试集图像和测试集标签。其中训练集图像为 60,000 张图像,测试集图像为 10,000 张。每张图像即为一个28*28的像素数组,每个像素的值为0或255(黑白图像)。
每个标签则为长度为10的一维数组,代表其为0-9数字的概率。
卷积神经网络 - 手写数字 - 可视化:


代码
利用torchvision.datasets.MNIST()读取
python">""" 导入三方库 """
import torch
import torchvision
from torch.utils.data import DataSet, DataLoader
import torchvision.transforms as transforms# 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5])] # transforms.Normalize() 归一化处理
)# 加载MNIST数据集
trainset = torchvision.datasets.MNIST(root='./data/',train=True, download=True, transform=data_transform)
testset = torchvision.datasets.MNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True)
testloader = troch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
python">import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
python">device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.MNIST()读取
python"># 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5], std=[0.5])] # transforms.Normalize() 归一化处理
)# 加载FashionMNIST数据集
train_set = torchvision.datasets.FashionMNIST(root='./data/',train=True, download=True, transform=data_transform)
test_set = torchvision.datasets.FashionMNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100, shuffle=False)
③ 创建神经网络
创建神经网络
python">class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( # 为匹配 LeNet 32*32 输入,故对 28*28 图像作 p=2 padding。nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=10),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
python"># 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 5
# 小批量训练次数
batch_size = 100
# 训练损失记录
final_losses = []
定义神经网络训练函数
python">def train_model():count = 0for epoch in range(epochs):for images, labels in train_loader:images, labels = images.to(device), labels.to(device)train = images.view(100, 1, 28, 28)# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
python">train_model()
torch.save(model.state_dict(), "mlenet.pth")
print("Saved PyTorch Model State to mlenet.pth")
绘制训练损失图像
python">for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
python">confusion_matrix = np.zeros((10,10))
定义神经网络测试函数
python">def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('mlenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]labels = torch.max(labels, 1)[1]correct += (preds == labels).sum()total += len(images)print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
python"># 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')


3. EMnist
EMnist数据集:手写字符识别数据集,Mnist数据集进阶版本,数据集分为训练集和测试集,用以训练和评估机器学习模型。
该数据集在深度学习领域具有重要地位,尤其适合初学者学习和实践图像识别技术。
- 该数据集含有
10种类别,共70000张灰度图像。包含 60000个训练集样本 和 10000个测试集样本。 - 每张图像以 28×28 像素的分辨率提供。
EMNIST 分为以下 6 类:
By_Class : 共 814255 张,62 类,与 NIST 相比重新划分类训练集与测试集的图片数。
By_Merge: 共 814255 张,47 类, 与 NIST 相比重新划分类训练集与测试集的图片数。
Balanced : 共 131600 张,47 类, 每一类都包含了相同的数据,每一类训练集 2400 张,测试集 400 张。
Digits :共 28000 张,10 类,每一类包含相同数量数据,每一类训练集 24000 张,测试集 4000 张。
Letters : 共 103600 张,37 类,每一类包含相同数据,每一类训练集 2400 张,测试集 400 张。
MNIST : 共 70000 张,10 类,每一类包含相同数量数据(注:这里虽然数目和分类都一样,但是图片的处理方式不一样,EMNIST 的 MNIST 子集数字占的比重更大)
Letter中相似的字母 (例如c或o) 被整合为1个字符,则共有37个字母可被识别,但因 未区分大小写&手写印刷体 最终被统一归为 26 类别,又因为包含未分类类别 [N/A] 故归为 27 类别。
本小节利用 EMNIST-Letters 数据集训练LeNet5模型,进行字符识别。
数据集排列:
| [N/A] | a | b | c | d | …… |
|---|
※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
python">import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
python">device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.EMNIST()读取
python"># 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5], std=[0.5])] # transforms.Normalize() 归一化处理
)# 加载FashionMNIST数据集
train_set = torchvision.datasets.FashionMNIST(root='./data/',train=True, download=True, transform=data_transform)
test_set = torchvision.datasets.FashionMNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100, shuffle=False)
③ 创建神经网络
创建神经网络
python">class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( # 为匹配 LeNet 32*32 输入,故对 28*28 图像作 p=2 padding。nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=27),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
python"># 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 5
# 小批量训练次数
batch_size = 100
# 训练损失记录
final_losses = []
定义神经网络训练函数
python">def train_model():count = 0for epoch in range(epochs):for images, labels in train_loader:images, labels = images.to(device), labels.to(device)# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
python">train_model()
torch.save(model.state_dict(), "elenet.pth")
print("Saved PyTorch Model State to mlenet.pth")
绘制训练损失图像
python">for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
python">confusion_matrix = np.zeros((27,27))
定义神经网络测试函数
python">def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('elenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]correct += (preds == labels).sum()total += len(images)for i in range(len(preds)):confusion_matrix[preds[i]][labels[i]] += 1print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
python"># 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')


4. FashionMnist
FashionMnist:衣物图标识别数据集,Mnist数据集进阶版本,数据集分为训练集和测试集,用以训练和评估机器学习模型。
该数据集在深度学习领域具有重要地位,尤其适合初学者学习和实践图像识别技术。
- 该数据集含有
10种类别,共70000张灰度图像。包含 60000个训练集样本 和 10000个测试集样本。 - 每张图像以 28×28 像素的分辨率提供。
| 标注编号 | 类别 |
|---|---|
| 0 | T恤 T-shirt |
| 1 | 裤子 Trousers |
| 2 | 套衫 Pullover |
| 3 | 裙子 Dress |
| 4 | 外套 Coat |
| 5 | 凉鞋 Sandal |
| 6 | 汗衫 Shirt |
| 7 | 运动鞋 Sneaker |
| 8 | 包 Bag |
| 9 | 踝靴 Ankle boot |
※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
python">import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
python">device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.FashionMNIST()读取
python"># 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5], std=[0.5])] # transforms.Normalize() 归一化处理
)# 加载FashionMNIST数据集
train_set = torchvision.datasets.FashionMNIST(root='./data/',train=True, download=True, transform=data_transform)
test_set = torchvision.datasets.FashionMNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100, shuffle=False)
③ 创建神经网络
创建神经网络
python">class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( # 为匹配 LeNet 32*32 输入,故对 28*28 图像作 p=2 padding。nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=10),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
python"># 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 5
# 小批量训练次数
batch_size = 100
# 训练损失记录
final_losses = []
定义神经网络训练函数
python">def train_model():count = 0for epoch in range(epochs):for images, labels in train_loader:images, labels = images.to(device), labels.to(device)train = images.view(100, 1, 28, 28)# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
python">train_model()
torch.save(model.state_dict(), "fmlenet.pth")
print("Saved PyTorch Model State to fmlenet.pth")
绘制训练损失图像
python">for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
python">confusion_matrix = np.zeros((10,10))
定义神经网络测试函数
python">def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('fmlenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]correct += (preds == labels).sum()total += len(images)for i in range(len(preds)):confusion_matrix[preds[i]][labels[i]] += 1print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
python"># 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')


由此得出,标准LeNet5网络拟合Fashion效果良好。
5. CIFAR-10
CIFAR10数据集共有60000个样本(32*32像素的RGB彩色图像),每个RGB图像包含3个通道(R通道、G通道、B通道)。
- 该数据集含有
10种类别,共60000张彩色图像。包含 50000个训练集样本 和 10000个测试集样本。
| 标注编号 | 类别 |
|---|---|
| 0 | 飞机 Airplane |
| 1 | 汽车 Automobile |
| 2 | 鸟 Bird |
| 3 | 猫 Cat |
| 4 | 鹿 Deer |
| 5 | 狗 Dog |
| 6 | 青蛙 Frog |
| 7 | 马 Horse |
| 8 | 船 Ship |
| 9 | 卡车 Truck |
CIFAR10数据集的内容,如图所示。

※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
python">import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
python">device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.CIFAR10()读取
python"># 定义一个转换参数的实例
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)# 加载CIFAR10数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=data_transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=data_transform)# 创建数据加载器
train_loader = torch.utils.data.DataLoader(trainset, batch_size=600, shuffle=True)
test_loader = torch.utils.data.DataLoader(testset, batch_size=600, shuffle=False)
③ 创建神经网络
创建神经网络
python">class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=10),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
python"># 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 50
# 小批量训练次数
batch_size = 600
# 训练损失记录
final_losses = []
定义神经网络训练函数
python">def train_model():for epoch in range(epochs):count = 0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)train = images# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
python">train_model()
torch.save(model.state_dict(), "clenet.pth")
print("Saved PyTorch Model State to clenet.pth")
绘制训练损失图像
python">for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
python">confusion_matrix = np.zeros((10,10))
定义神经网络测试函数
python">def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('fmlenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]correct += (preds == labels).sum()total += len(images)for i in range(len(preds)):confusion_matrix[preds[i]][labels[i]] += 1print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
python"># 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')

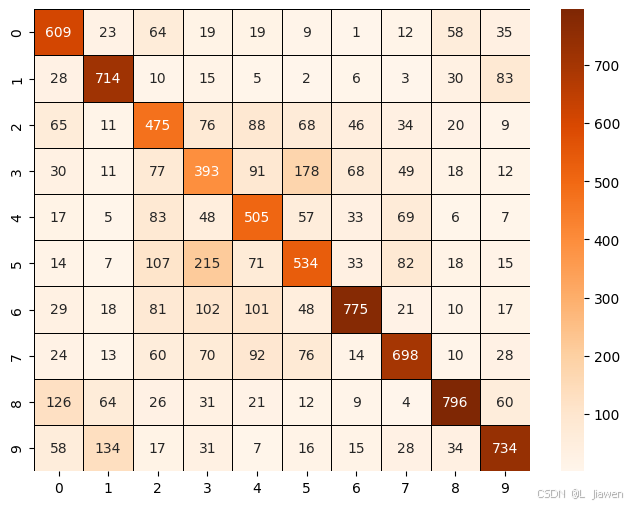
由此得出,未经修饰/改进的标准LeNet5网络对CIFAR10数据集的拟合效果不佳。
可改进的方向:
- 本文对CIFAR10数据集的拟合效果不佳,后续可对此问题再作探究。
- 本文所有网络的输出层采用了LogSoftmax函数,而非Softmax函数,后续可在此问题上继续探讨。



