目录
一、进程终止
<1>使用语言和系统自带的方法,进行转换
<2>自定义错误码
<3>小结:
<2>两个接口exit / _exit
二、进程等待
<1>简单了解
<2>wait调用
<3>waitpid调用
<4>status
<1>WIFEITED(status)
<2>WEXITSTATUS(status)
<5>waitpid的阻塞调用和非阻塞调用
一、进程终止
在我们平常写C/C++代码时,为什么我们要加一个return 0呢?这里可不可以返回其他的数字呢?
不知道大家有没有思考过这些问题,main函数也是函数,在运行之后形成了一个进程。那我们该如何了解进程的运行状况呢?其实就是通过main的返回值来判断程序的运行状况。而main函数的返回值表示进程的退出码,一般我们用0表示进程执行成功,非零表示失败。为什么用非零来表示失败呢?其实在Linux系统中是想用不同的数字表示不同的失败原因。
我们可以用一段代码演示一下
#include<stdio.h>
int main()
{printf("hello world\n");return 10;
}运行成功,系统就会打印除hello world, 但是父进程要怎么确定这个子进程的运行状态呢?系统中存在一个命令叫 " echo $?" ,bash会保存最近一次进程退出的退出码,如下图所示(下图中最近一次进程退出码变为0,是因为上一次的进程变成了echo $? 这个命令)

当然,退出码并不是给普通用户读的,是给进程读取的,如果我们想要看到进程退出码的错误信息,必需转换成错误描述才可以,这种转换一般有两种方法:1、使用语言和系统自带的犯法,进行转换。2、可以自定义。
<1>使用语言和系统自带的方法,进行转换
系统中存在strerror接口,该接口可以帮助我们进行查看错误码的错误描述。

这里我们打印出一些,供大家参考(直接用for循环即可打印,退出码的范围大概是1 - 133,超过了就变成unkown error,这些在不同的环境下,退出码的大小和个数可能是不同的);

<2>自定义错误码
我们可以自己写一段代码来描述进程的退出码,如下图
#include<stdio.h>
#include<string.h>
enum{success = 0,malloc_err,open_err,close_err
};
void my_strerror(int code)
{switch (code){case success:printf("success\n");break;case malloc_err:printf("malloc fail\n");break;case open_err:printf("open error\n");break;case close_err:printf("close error\n");break;default:printf("unknow\n");break;}}
int main()
{int code = malloc_err;my_strerror(code);return code;}运行结果

errno:
在进程退出时,有进程退出码,当函数退出时,有函数返回值。而在调用函数里面,我们通常向看到两种结果,一是函数的执行结果 ,二是函数的执行情况。一般情况下函数的执行结果就代表了函数的执行结果。如果我们函数调用失败,函数会返回特定的值,这个值一般称为错误码,errno函数可以通过错误码来打印出对应信息,本质上这和退出码没什么区别。
<3>小结:
进程的退出情况无非一下三种:
1.进程代码执行完,结果正确;
2.进程代码执行完,结果是不正确的;
3.进程代码没有执行完,进程出异常了;
而进程出现异常,本质就是进程受到了信号,而每个信号都有各自的编号,不同的信号编号代表不同的异常原因。根据上述的三种情况,我们可以使用两个数字来表示进程的具体执行情况(一是信号,二是进程的退出码。如果信号为零,表示进程没有出现异常,如果不为零,表示进程出现了异常情况。如果进程退出码为零表示结果正确,不为零表示结果异常。一般是先看信号,再看退出码,如果信号不为零,根本就得不到退出码)。
信号

<2>两个接口exit / _exit
当然,进程的退出还有exit和_exit接口,准确地来说exit接口是进程退出

只要某个进程调用这个接口,系统就会终止这个进程,status是进程退出时的退出码,_exit接口两个运行结果是一样的,但exit是C语言的库,_exit是系统调用的结果。这两函数的区别是exit 会支持刷新缓冲区,_exit是不支持缓冲区的刷新。缓冲区刷新会让一些信息打印到显示屏上。
int main()
{printf("hello world");sleep(2);exit(0);
}我们运行这段代码后,一段时间后就会让缓冲区的信息刷新到屏幕上。
![]()
而我们把exit改为系统调用接口后,屏幕上就不会出现对应信息,因为缓冲区并没有刷新。

这里显示器上就没有出现对应的信息。exit和_exit的区别就在于此。当然,本质上来说,exit就是_exit的上层封装。用户要终止进程,只能通过系统接口,让操作系统去终止进程,所以最终无论调用哪一个函数,最后调用的时候,都是调_exit接口。为什么还要封装_exit接口呢?很大一个原因就是因为在不同的操作系统下,对应功能的系统调用可能大不相同,编写的代码就只能在特定机器下运行,不具有移植性。所以为了屏蔽这种底层差异,我们就可以通过封装这些系统调用来实现跨平台开发(比如在linux和window操作系统下,要实现进程终止,是由两个完全不同的接口实现的,但是我们平常写代码时只要写exit就可以实现进程终止这个功能,无论是在window还是在linux),这样是我们下载安装包时,经常看到window版,macos版等等。
二、进程等待
<1>简单了解
之前描述过,子进程一旦退出后,父进程不读取子进程数据信息,就会造成僵尸状态(Z)。父进程就需要通过进程等待来接触这个状态。进程等待做的事情其实就是两件,一是父进程通过wait方式回收子进程的资源,二是通过wait方式,获取子进程的退出信息。
首先我们先看一下进程等待相关的系统接口,wait和waitpid。

这里的wstatus都是输出型的参数,我们先设置为NULL。
<2>wait调用
1.wait调用会默认进行阻塞等待,阻塞等待就是子进程不退,父进程也不退,直到子进程死亡,然后才返回。
2.等待任意一个子进程,只要有子进程,都需要等待。
返回值:如果大于零,就是等待子进程的pid,如果小于零,就表示等待失败了。
下面演示一下用wait回收过程
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/wait.h>int main()
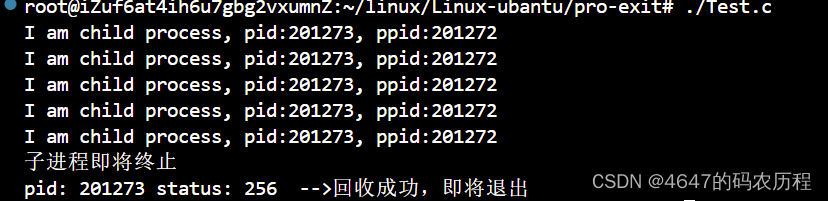
{pid_t id = fork();if(id == 0){int ret = 5;while(ret--){printf("I am child process, pid:%d, ppid:%d\n",getpid(),getppid());sleep(1);}printf("子进程即将终止\n");sleep(1);exit(0);//开始变僵尸}sleep(10);pid_t t = wait(NULL);if(t > 0){printf("pid: %d 回收成功,即将退出\n",t);sleep(3);}return 0;
}
运行结果


我们可以看见,wait确实成功回收了子进程。所以父进程一般先回收完子进程后再退出,所以父进程一般都是最后退出。
<3>waitpid调用
waitpid也具有回收子进程资源的功能,同时该接口还能获取子进程的退出信息。这个函数的返回值含义跟wait并无区别,只是在参数上稍有差异。

三个参数:
pid:pid = - 1,等待任一子进程,与wait等效;wait >0 ,等待其进程ID与pid相等的子进程。
wstatus:表示输出型参数,这里我们获取退出信息时,给定一个int*指针,将退出信息写入指针中
option:0(阻塞)和非阻塞状态,这里我们先设置为0;
下面我们在微调一下上面wait的演示代码,看看waitpid的效果。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{pid_t id = fork();if(id == 0){int ret = 5;while(ret--){printf("I am child process, pid:%d, ppid:%d\n",getpid(),getppid());sleep(1);}printf("子进程即将终止\n");sleep(1);exit(1);//开始变僵尸}sleep(10);int status = 0;pid_t t = waitpid(id, &status,0);if(t > 0){printf("pid: %d status: %d -->回收成功,即将退出\n",t,status);sleep(3);}return 0;
}运行结果
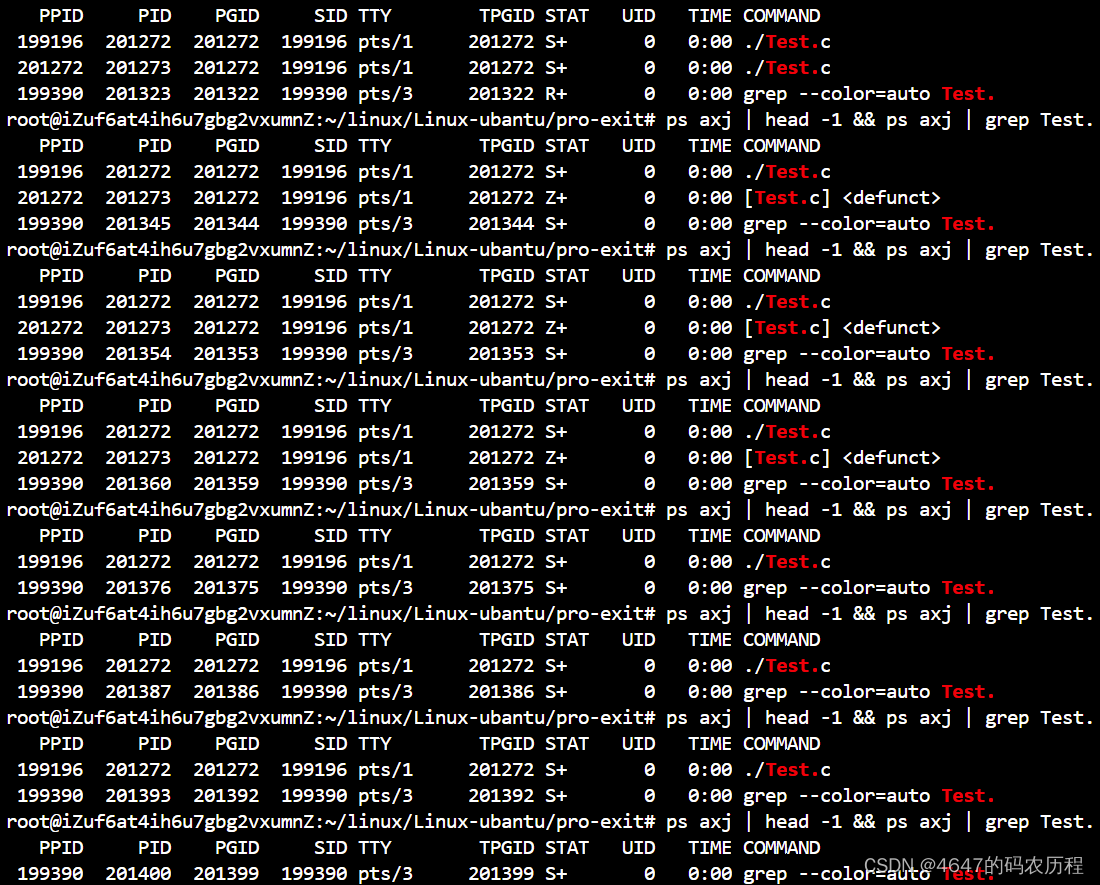
进程状态其实和wait是一样,在下面的运行结果中,存在一个令人疑惑的点,那就是status的值,明明退出时,给的退出码是“1”,打印出来的却是256。
<4>status
这里特别介绍一下status存储信息的方式,首先根据前面的介绍,进程退出信息包括了进程退出码和退出信号。为了在一个整型变量里面存储这些信号,这里status采取了一种类似于局部性位图的方式存储这两个变量。
下图是status这个变量的32个比特位,其中的一些区域暂不做介绍,只介绍进程退出码和退出时收到信号编号在status里面的存储方式。

所以上文status出现256的原因就好理解了,进程退出码为1,信号编号为0,退出码最低位为32个比特位中的第九位,转换成十进制,也就是256。
如果我们要查看对应的退出码和收到信号,我们可以采用位操作,下面我们微调一下上述代码,将对应的信息打印出来。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{pid_t id = fork();if(id == 0){int ret = 10;while(ret--){printf("I am child process, pid:%d, ppid:%d\n",getpid(),getppid());sleep(1);}printf("子进程即将终止\n");sleep(1);exit(1);//开始变僵尸}sleep(10);int status = 0;pid_t t = waitpid(id, &status,0);if(t > 0){printf("pid: %d status: %d 退出码:%d 收到信号:%d-->回收成功,即将退出\n",t,status,status&0x7f,(status>>8)&0xff);//0x7f 表示 0000 0000 0000 0000 0000 0000 0111 1111//0xff 表示 0000 0000 0000 0000 0000 0000 1111 1111sleep(3);}return 0;
}通过按位与操作,我们就可以打印对应信息,需要注意的是,我们一般就使用低16位存数据,高十六位字节我们一般看为零,所以对结果不影响。同时进程退出码和收到信号编号中间的一个字节(code dump),我们暂不介绍,这里我们用位多移一位,屏蔽掉这个字节的影响(收到信号的编号占7个字节,为了屏蔽影响,所以这里我们多移了一个字节)
运行结果
正常运行的运行结果

收到信号,进程退出的结果

难道我们每次想要获取进程的运行信息,都要通过位操作进行获取吗?当然不是,系统为我们提供了两个宏,一个叫WIFEITED(status),另一个叫WEXITSTATUS(status).
<1>WIFEITED(status)
该宏就是用来检查进程是否正常退出,其实这个宏本质上来说也是位操作,如果status里面存储的退出码为零,就表示子进程正常终止,表示为真,其余就表示假。
<2>WEXITSTATUS(status)
该宏是用于提取子进程的退出码,在上一个宏为真时,该宏才有调用意义。
这里又引申出一个问题,为什么不用全局变量来存储进程退出码和收到的信号编号,其实这个原因非常简单,就是因为进程的独立性,用户在最开始的时候定义的全局变量属于父进程的数据,如果把子进程的退出信息写入,就会发生写时拷贝,父进程无法看到子进程的退出信息。所以我们必需要调用系统调用来获取子进程的退出信息(该信息在进程的task_struct中,PCB处于内核之中,普通用户无权访问,必需调用系统接口)。
<5>waitpid的阻塞调用和非阻塞调用
前面我们了解过waitpid的参数,其中就包含了一个option参数,这个参数就表示调用的方式,如果是阻塞调用,就为零。如果为非阻塞调用,就可以选择一个宏来表示

这个就表示非阻塞调用。
阻塞调用和非阻塞调用的区别:
我们可以通过日常生活中的例子帮助我们理解这两者之间的区别。
假设张三同学今天想要约李四出门到景点游玩,但是李四因为需要准备随身物品,没那么快下来,所以张三就在李四楼下等李四。等了半天,发现李四还没下来,于是张三就打电话给李四,催李四快点下来,在等待过程中,张三也看了看景点的攻略。但是由于李四比较磨蹭,所以张三只能一直打电话催促,在打了很多次电话后,李四终于下来跟张三去了景点游玩。
在这之后,张三在一个假期中,又向李四发起了组团游玩景点的申请,李四欣然同意。于是在出发当天,张三又跑到李四家楼下等待李四收拾东西。鉴于上一次的经验,张三让李四别挂电话,如果李四收拾好了,直接跟张三说。而张三在此过程中一直等待李四,啥也没干,等到李四收拾完后就再次和李四去景点游玩。
这个张三打电话的过程,就是系统调用,而在第二个例子中的张三打电话,就是阻塞调用。也就是结果不就绪,系统调用就不返回。而在第一个例子中,张三每打一次电话,就是一次系统调用。打了很多次电话,就说明有多次的系统调用(这里的系统调用本质是在检查李四的状态)。这里我们的系统调用不会像第二个例子中的张三打电话那样,没有就绪就一直卡那边动不了,而是直接返回,哪怕李四没有准备好,所以这里的单次系统调用也叫非阻塞调用。而在这里我们不断调用非阻塞系统调用的过程(对应例子中张三一直打电话),就叫作基于轮询(可以看成循环的意思)的非阻塞访问。在这里我们的张三就是父进程,李四就是子进程。
非阻塞调用叫阻塞调用的优点就是非阻塞调用在轮询期间,可以做其他的事情,而阻塞调用只能卡在那里,等待子进程结束。
回到WNOHANG这个参数上来,这个宏就表示非阻塞调用,下面我们用一段代码来看看,这个参数的具体使用。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{pid_t id = fork();if(id == 0){int ret = 5;while(ret--){printf("I am child process, pid:%d, ppid:%d\n",getpid(),getppid());sleep(1);}printf("子进程即将终止\n");exit(1);//开始变僵尸}//父进程while(1){int status = 0;pid_t t = waitpid(id, &status,WNOHANG);if(t > 0)//系统调用成功,并且子进程已经退出{printf("wait success, pid : %d\n",t);break;}else if(t == 0)//系统调用成功,但子进程没退{printf("wait success , but child is still running\n");//执行其他任务}else//系统调用失败{perror("waitpid\n");break;}sleep(1);}return 0;
}运行结果

这里我们就可以发现,系统就使用了非阻塞调用的方式,在等待子进程退出过程中,父进程也可以执行一些其他任务,下面用一段示例代码简单演示一下,看看就行,具体任务可自行编写。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
#include<sys/types.h>
#include<sys/wait.h>
#define num 6
typedef void(*fun)();fun task[num];
void printA()
{printf("hello! I am task A\n");
}
void printB()
{printf("hello! I am task B\n");
}
void printC()
{printf("hello! I am task C\n");
}
void printD()
{printf("hello! I am task D\n");
}void Inittask()
{task[0] = printA;task[1] = printB;task[2] = printC;task[3] = printD;task[4] = NULL;
}
void CarryTask()
{for(int i = 0; task[i]; i++){task[i]();}
}
int main()
{Inittask();pid_t id = fork();if(id == 0){int ret = 5;while(ret--){printf("I am child process, pid:%d, ppid:%d\n",getpid(),getppid());sleep(1);}printf("子进程即将终止\n");exit(1);//开始变僵尸}//父进程while(1){int status = 0;pid_t t = waitpid(id, &status,WNOHANG);if(t > 0)//系统调用成功,并且子进程已经退出{printf("wait success, pid : %d\n",t);break;}else if(t == 0)//系统调用成功,但子进程没退{printf("wait success , but child is still running\n");//可以干别的事情printf("**************** task begin ***************\n");CarryTask();printf("**************** task end ***************\n");}else//系统调用失败{perror("waitpid\n");break;}sleep(1);}return 0;
}执行结果
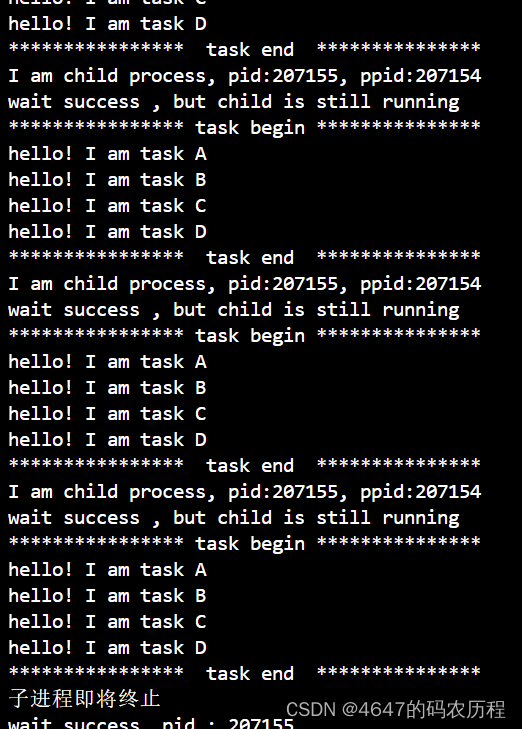
以上就是全部内容,如果文中有不对之处,还望各位大佬指正,谢谢!!!