Title
题目
SPIRiT-Diffusion: Self-Consistency Driven Diffusion Model for Accelerated MRI
SPIRiT-Diffusion:基于自一致性驱动的加速MRI扩散模型
01
文献速递介绍
磁共振成像(MRI) 在临床和研究领域被广泛应用。然而,其长时间的采集过程仍然是一个主要限制,导致在空间分辨率、时间分辨率和覆盖范围之间存在权衡。因此,如何从有限的 k-空间数据中重建高质量的 MR 图像以加速采集,成为研究的热点。近年来,压缩感知(CS) 和 深度学习(DL) 在 MR 重建领域取得了显著进展。这些方法利用图像先验信息创建手工设计或可学习的正则化,并将其与数据一致性项结合,用以解决 MR 重建中的逆问题。
最近,基于得分的扩散模型 已成为 MR 重建中的一种强大深度生成先验这些模型依赖于前向和反向随机微分方程(SDEs)来编码和解码(生成)图像。前向 SDE 包括一个漂移项,表示前向过程的确定性趋势,以及一个扩散项,表示随机波动。例如,在方差保持(VP)SDE 中,漂移项线性描绘了能量减少的确定性趋势,表明图像信号的均值会确定性地衰减到零。反向 SDE 是从前向 SDE 推导出来的,通过边际概率密度的得分函数来指导图像重建。与传统方法不同,基于得分的 MR 重建学习的是数据分布,而不是 k-空间数据和图像之间的端到端映射,这使得无监督学习成为可能,并且有助于适应分布外的数据。已有的研究表明,这种方法在 MR 重建中取得了很好的效果。
扩散模型在 MRI 中已经取得了成功。目前,许多基于扩散模型的重建方法主要设计在图像域,依赖于单个线圈的空间灵敏度图(CSM)作为多通道图像的加权函数。然而,准确地测量 CSM 是一个挑战,尤其是在视场(FOV)受限时 或当存在相位奇点时 , 。即使是微小的灵敏度估计误差,也可能导致线圈图像和采集的 k-空间数据之间的不一致,从而导致重建图像中的伪影。另一方面,直接插值缺失的 k-空间数据可以规避与 CSM 估计相关的挑战,这在 k-空间并行成像(PI)方法中得到体现,如 GRAPPA 、SPIRiT 等方法。这些方法通过估计平移不变的插值核,描述多通道 k-空间数据之间的冗余先验,从而使得缺失的 k-空间数据能够在较低的灵敏度估计误差下进行估计。因此,k-空间插值方法相比图像域方法展现出了更大的鲁棒性。基于这一点,依赖 k-空间插值的扩散模型可能继承了对不准确 CSM 估计的鲁棒性。此外,这种方法结合了通道冗余和数据分布的先验,从而提高了在高加速条件下插值缺失 k-空间数据的准确性 。然而,目前的扩散模型主要是在图像域内构建的,因此不能直接应用于这种情况。
为了应对这一问题,我们从优化的角度重新评估了传统的 k-空间插值 SPIRiT 模型。通过将 SPIRiT 模型的迭代算法视为某些 SDEs 的离散欧拉形式,我们从这一角度获得灵感,提出了一种基于扩散的 MR 重建方法。在这种方法中,SPIRiT 的自一致性项作为 SDE 中的主要漂移系数起着关键作用。此外,CSM 被引入到扩散系数中,以准确计算扰动核的均值和方差。虽然我们提出的方法仍需要纳入 CSM,但其主要关注的是多通道 k-空间插值,而不是基于 CSM 合成的单通道图像重建。因此,我们提出的模型展现出了对不准确灵敏度估计的鲁棒性。由于该方法在自一致性方面受到 SPIRiT 启发,我们将其称为 SPIRiT-Diffusion。
Aastract
摘要
Diffusion models have emerged as a leadingmethodology for image generation and have proven successful in the realm of magnetic resonance imaging (MRI)reconstruction. However, existing reconstruction methodsbased on diffusion models are primarily formulated in theimage domain, making the reconstruction quality susceptible to inaccuracies in coil sensitivity maps (CSMs). k-spaceinterpolation methods can effectively address this issue butconventional diffusion models are not readily applicablein k-space interpolation. To overcome this challenge, weintroduce a novel approach called SPIRiT-Diffusion, whichis a diffusion model for k-space interpolation inspiredby the iterative self-consistent SPIRiT method. Specifically, we utilize the iterative solver of the self-consistentterm (i.e., k-space physical prior) in SPIRiT to formulatea novel stochastic differential equation (SDE) governingthe diffusion process. Subsequently, k-space data canbe interpolated by executing the diffusion process. Thisinnovative approach highlights the optimization model’srole in designing the SDE in diffusion models, enablingthe diffusion process to align closely with the physicsinherent in the optimization model-a concept referred toas model-driven diffusion. We evaluated the proposedSPIRiT-Diffusion method using a 3D joint intracranial andcarotid vessel wall imaging dataset. The results convincingly demonstrate its superiority over image-domain reconstruction methods, achieving high reconstruction qualityeven at a substantial acceleration rate of 10.
扩散模型已经成为图像生成的领先方法,并且在磁共振成像(MRI)重建领域取得了成功。然而,现有基于扩散模型的重建方法主要是在图像域中进行公式化,这使得重建质量容易受到线圈灵敏度图(CSM)不准确性的影响。k空间插值方法可以有效解决这个问题,但传统的扩散模型在k空间插值中并不容易应用。为了克服这一挑战,我们提出了一种新的方法,称为SPIRiT-Diffusion,这是一种受迭代自一致性SPIRiT方法启发的k空间插值扩散模型。具体来说,我们利用SPIRiT中自一致性项(即k空间物理先验)的迭代求解器,公式化了一个新的随机微分方程(SDE)来控制扩散过程。随后,可以通过执行扩散过程对k空间数据进行插值。这个创新方法突出了优化模型在设计扩散模型中SDE的作用,使得扩散过程能够与优化模型中固有的物理规律紧密对齐——这一概念被称为模型驱动扩散。我们使用一个3D联合颅内和颈动脉血管壁成像数据集评估了所提出的SPIRiT-Diffusion方法。结果充分证明了该方法优于图像域重建方法,在大幅加速率(10倍)下仍能实现高质量重建。
Method
方法
can be expressed as follows:
y = Ax + n,where x := [x1, ..., x*m] is the image to be reconstructed andxi* is the ith channel image, y is the undersampled k-spacedata, n is the Gaussian noise, A is the encoding matrix withA** := MF, M is the undersampling operator and F denotesFourier transform.Reconstructing a multi-channel MR image is akin to interpolating missing data from undersampled k-space data y.Achieving precise interpolation inevitably requires the utilization of prior information from the k-space data. In this context,SPIRiT serves as a model that exploits the self-consistencyprior in k-space. The self-consistency prior embodies a statistical regularity in k-space, where any point can be linearlyinterpolated based on its local points, including itself. Inother words, a self-interpolation kernel G exists, enabling themulti-channel k-space data ˆx to be interpolated as Gˆx = ˆx,where ˆx is the k-space data with ˆx = F(x). Therefore,the regularization model, utilizing the self-consistency priorto solve the inverse problem Eq. , can be formulated asfollows:
多通道 MR 重建的正向模型可以表示为:
y=Ax+n\mathbf{y} = \mathbf{A}\mathbf{x} + \mathbf{n}y=Ax+n
其中,x := [x₁, ..., xₘ] 是待重建的图像,xᵢ 是第 i 个通道图像,y 是欠采样的 k-空间数据,n 是高斯噪声,A 是编码矩阵,定义为 A := MF,M 是欠采样算子,F 表示傅里叶变换。重建多通道 MR 图像类似于从欠采样的 k-空间数据 y 中插值缺失的数据。要实现精确的插值,必然需要利用 k-空间数据的先验信息。在这种情况下,SPIRiT 作为一种模型,利用 k-空间中的自一致性先验。自一致性先验体现了 k-空间中的统计规律性,其中任何一点都可以基于其局部点线性插值,包括它自身。换句话说,存在一个自插值核 G,使得多通道 k-空间数据 ˆx 可以被插值为 Gˆx = ˆx,其中 ˆx 是通过 ˆx = F(x) 得到的 k-空间数据。因此,利用自一致性先验来求解逆问题 Eq. (5) 的正则化模型可以如下表示:minˆx∥Gˆx − ˆx∥ 2 2 + µ∥Ax − y∥ 2 2 ,
Conclusion
结论
In this paper, we have proposed a novel paradigm of modeldriven diffusion, where the diffusion equation is driven in accordance with the physics inherent in the optimization model.Specifically, we employed the SPIRiT model to drive a newdiffusion model, enabling the accurate interpolation of missingk-space data. In comparison to conventional diffusion modelsformulated in the image domain, our approach demonstratedrobust performance when confronted with challenges such asa limited FOV, phase singular points, and other factors that ledto inaccurate CSM estimation. Finally, experimental validationon a 3D joint intracranial and carotid vessel wall imagingdataset confirmed the superiority of the proposed method.
在本文中,我们提出了一种新颖的模型驱动扩散范式,其中扩散方程依据优化模型中固有的物理学进行驱动。具体来说,我们采用了SPIRiT模型来驱动新的扩散模型,从而实现对缺失k-空间数据的精确插值。与传统的基于图像域的扩散模型相比,我们的方法在面对有限视野(FOV)、相位奇点以及其他导致CSM(接收灵敏度映射)估计不准确的因素时,表现出了更强的鲁棒性。最后,在3D联合颅内和颈动脉血管壁成像数据集上的实验验证证明了所提方法的优越性。
Figure
图
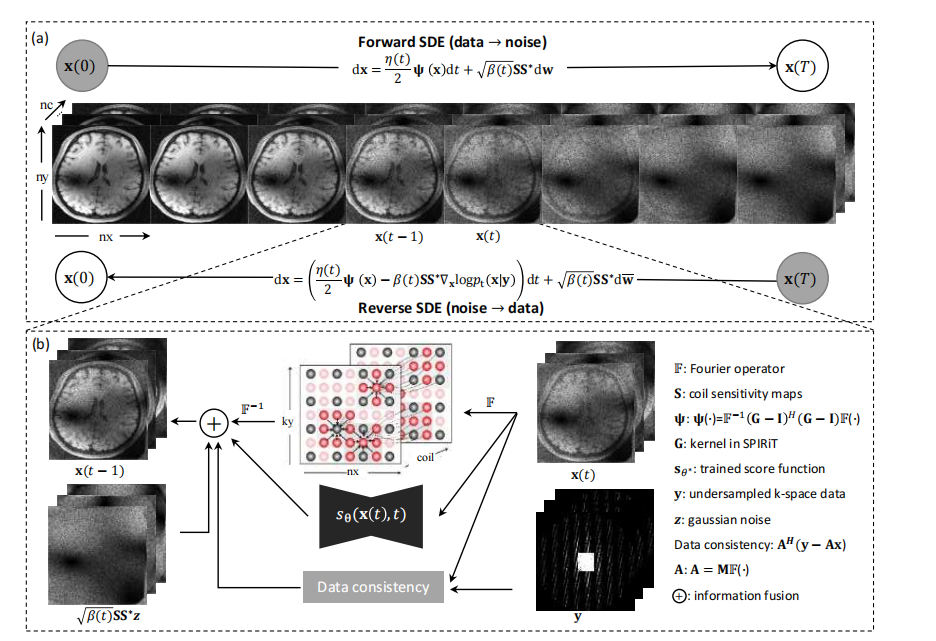
Fig. 1: The SPIRiT-Diffusion framework. (a) Forward SDE: Self-consistent noise at different scales is gradually injected intothe multi-coil images. Reverse SDE: The self-consistent noise introduced by the Forward SDE is gradually removed fromthe noisy data. (b) Reverse SDE description: From time t to t − 1, first, transform x(t) to the k-space domain, execute oneiteration involving the self-consistency term, and then transform back to the image domain. Subsequently, incorporate the dataconsistency term, the learned probability density prior (i.e., score function), and noise to calculate x(t − 1). By iterativelyexecuting the reverse process, missing data in k-space is gradually updated. It is important to note that the image related toself-interpolation of k-space data is referenced from
图 1:SPIRiT-Diffusion 框架。(a) 正向 SDE:在不同尺度下,自一致性噪声逐渐注入到多线圈图像中。逆向 SDE:正向 SDE 引入的自一致性噪声逐渐从噪声数据中去除。(b) 逆向 SDE 描述:从时间 t 到 t − 1,首先将 x(t) 转换到 k-空间域,执行涉及自一致性项的一次迭代,然后转换回图像域。随后,结合数据一致性项、学习的概率密度先验(即得分函数)和噪声来计算 x(t − 1)。通过反复执行逆向过程,k-空间中缺失的数据逐渐得到更新。需要注意的是,涉及 k-空间数据自插值的图像参考。
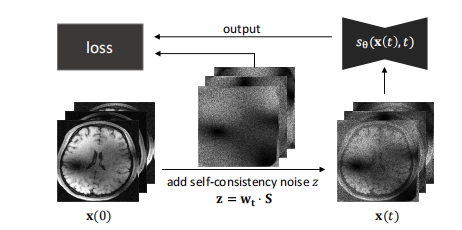
Fig. 2: Training Flowchart: Generate x(t) by adding selfconsistent noise z to x(0) through a forward SDE, wherewt represents random noise at time t and S denotes coilsensitivity. Feed x(t) into the network sθwith z as the label,and use the network’s output in conjunction with z to computethe training loss Eq.
图 2:训练流程图:通过向 x(0) 添加自一致性噪声 z,通过正向 SDE 生成 x(t),其中 w(t) 表示在时间 t 的随机噪声,S 表示线圈灵敏度。将 x(t) 输入到网络 sθ 中,z 作为标签,并使用网络的输出与 z 一起计算训练损失(公式)。
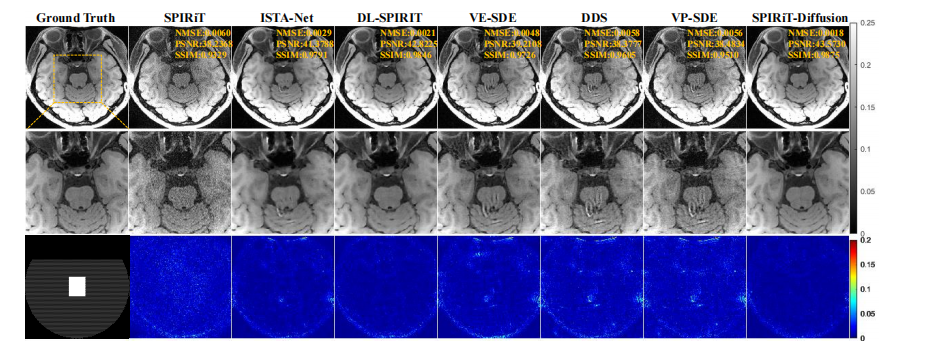
Fig. 3: Reconstruction results of VWI data at absolutely R = 7.6 The top row shows the ground truth and the reconstructionsobtained using different methods. The second row shows an enlarged view of the ROI, and the third row displays the errormap of the reconstructions.
图 3:绝对值 R = 7.6 时 VWI 数据的重建结果。第一排展示了地面真值和使用不同方法得到的重建结果。第二排显示了感兴趣区域(ROI)的放大视图,第三排展示了重建结果的误差图。
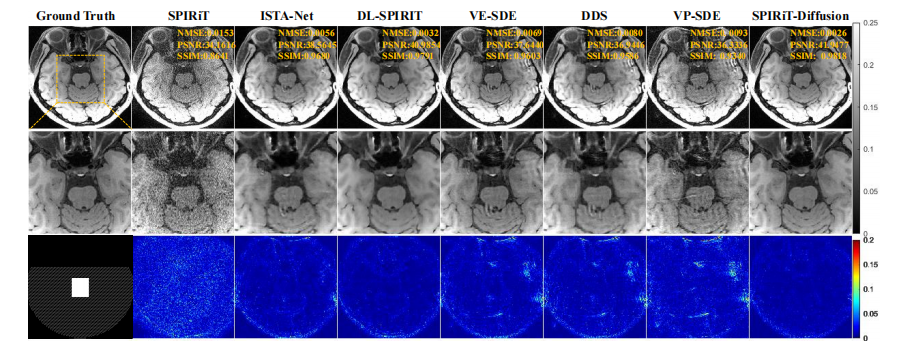
Fig. 4: Reconstruction results of VWI data at R = 10. The top row shows the ground truth and the reconstructions obtainedusing different methods. The second row shows an enlarged view of the ROI, and the third row displays the error map of thereconstructions.
图 4:R = 10 时 VWI 数据的重建结果。第一排展示了地面真值和使用不同方法得到的重建结果。第二排显示了感兴趣区域(ROI)的放大视图,第三排展示了重建结果的误差图。
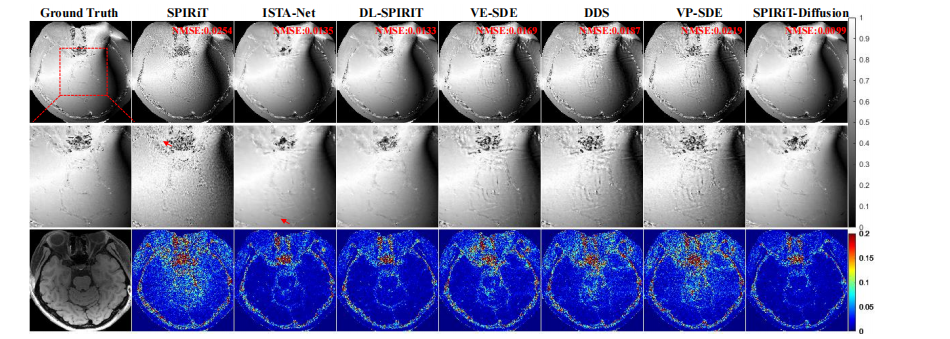
Fig. 5: Phase reconstruction results of VWI data at R = 7.6. The top row shows the ground truth and the reconstructionsobtained using different methods. The second row shows an enlarged view of the ROI, and the third row displays the errormap of the reconstructions.
图 5:R = 7.6 时 VWI 数据的相位重建结果。第一排展示了地面真值和使用不同方法得到的重建结果。第二排显示了感兴趣区域(ROI)的放大视图,第三排展示了重建结果的误差图。
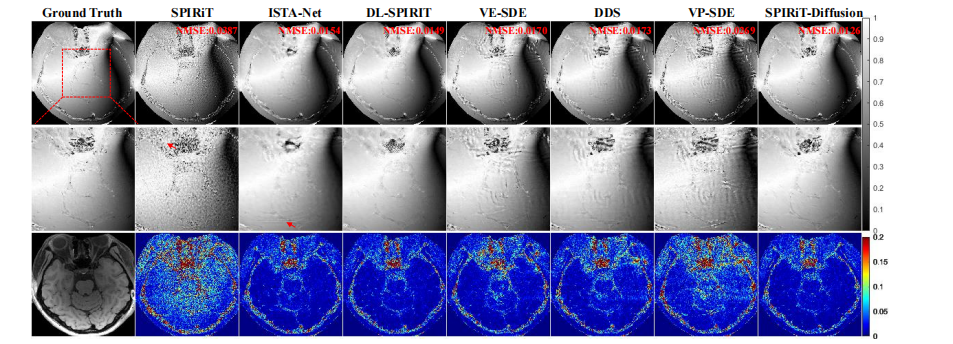
Fig. 6: Phase reconstruction results of VWI data at R = 10. The top row shows the ground truth and the reconstructionsobtained using different methods. The second row shows an enlarged view of the ROI, and the third row displays the errormap of the reconstructions.
图 6:R = 10 时 VWI 数据的相位重建结果。第一排展示了地面真值和使用不同方法得到的重建结果。第二排显示了感兴趣区域(ROI)的放大视图,第三排展示了重建结果的误差图。
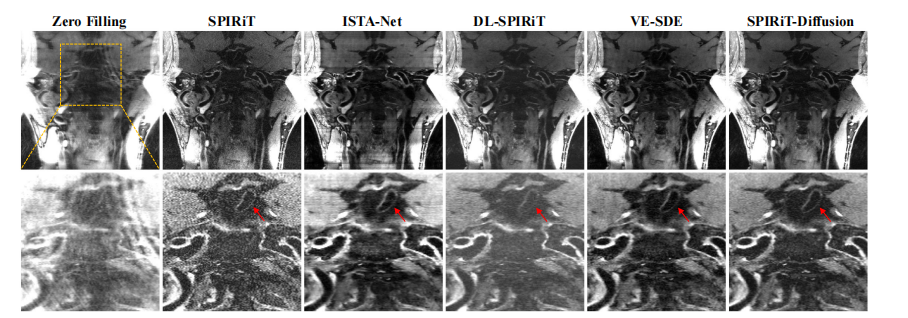
Fig. 7: Prospective reconstruction results of VWI data at R = 4.5, with images reformatted in the coronal direction. The toprow displays the ground truth alongside reconstructions obtained using various methods. The second row presents an enlargedview of the region of interest (ROI) marked by the yellow box in the first row. The SPIRiT image appears somewhat noisy.Aliasing artifacts are visible in the images from ISTA-Net and VE-SDE. The DL-SPIRiT result is missing parts of the vesselwall. SPIRiT-Diffusion demonstrates a strong capability to suppress artifacts and noise.
图 7:R = 4.5 时 VWI 数据的前瞻性重建结果,图像按冠状面重排。第一排展示了地面真值及使用各种方法得到的重建结果。第二排展示了第一排中黄色框标出的感兴趣区域(ROI)的放大视图。SPIRiT 图像出现了一定的噪声。ISTA-Net 和 VE-SDE 方法的图像中可见别名伪影。DL-SPIRiT 结果缺失了部分血管壁。SPIRiT-Diffusion 方法在抑制伪影和噪声方面表现出较强的能力。
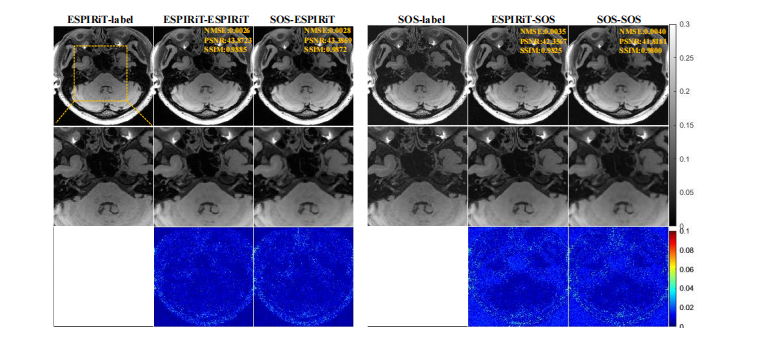
Fig. 8: SPIRiT-Diffusion Reconstruction results at R = 7.6 with different CSMs. The term “ESPIRiT-SOS” indicates theused CSM methods in training (ESPIRiT) and testing (SOS), respectively. Other terms are the same. The ESPIRiT/SOS-labeldenotes the combination of full-sampled k-space using CSMs of the ESPIRiT/SOS method.
图 8:在 R = 7.6 时,使用不同 CSM 的 SPIRiT-Diffusion 重建结果。术语“ESPIRiT-SOS”表示在训练和测试中分别使用的 CSM 方法(ESPIRiT 和 SOS)。其他术语保持一致。ESPIRiT/SOS 标签表示使用 ESPIRiT/SOS 方法的 CSM 对完整采样的 k-空间进行组合。
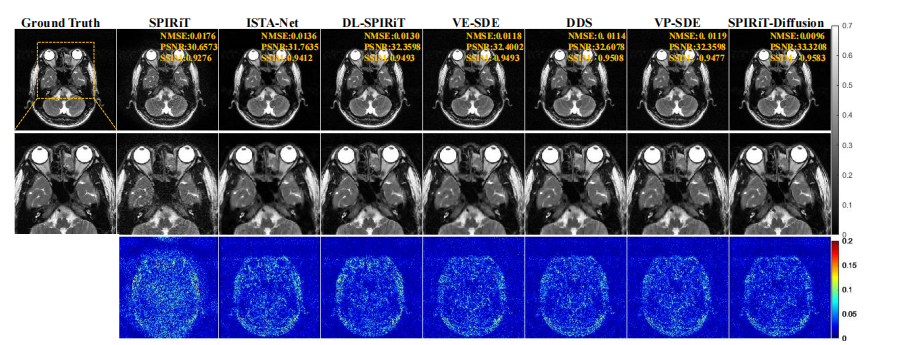
Fig. 9: Reconstruction results of brain T2w data at R = 7.6. SPIRiT-Diffusion achieves the best reconstruction quality
图 9:R = 7.6 时脑部 T2加权(T2w)数据的重建结果。SPIRiT-Diffusion 方法实现了最佳的重建质量。
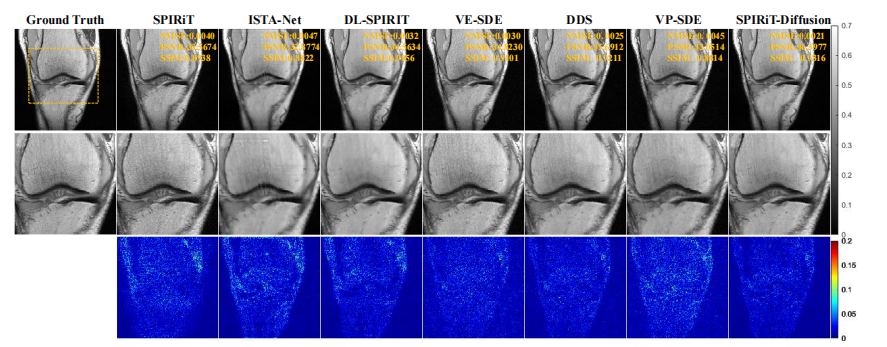
Fig. 10: Reconstruction results of fastMRI knee data at R = 7.6. SPIRiT-Diffusion achieves excellent reconstruction quality
图 10:R = 7.6 时 fastMRI 膝关节数据的重建结果。SPIRiT-Diffusion 方法实现了卓越的重建质量。
Table
表
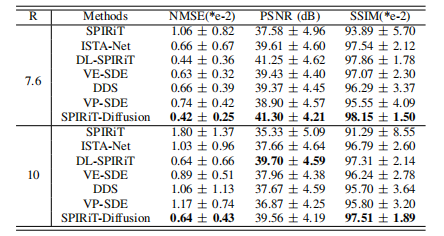
TABLE I: The average quantitative metrics on test dataset Iat R = 7.6 and 10
表 I:在测试数据集 I 上,R = 7.6 和 10 时的平均定量指标
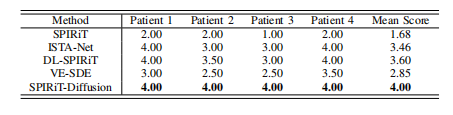
TABLE II: The average subjective scores of two radiologistsfor the prospective experiment.
表 II:两位放射科医生对前瞻性实验的平均主观评分
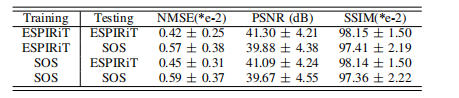
TABLE III: The average quantitative metrics of SPIRiTDiffusion using different CSM estimation methods on testdataset I at R = 7.6.
表 III:在测试数据集 I 上,R = 7.6 时使用不同 CSM 估计方法的 SPIRiT-Diffusion 平均定量指标
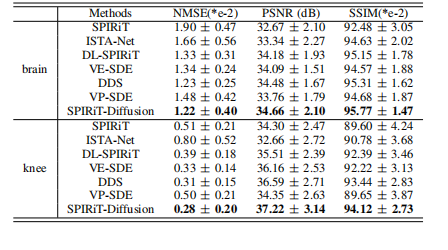
TABLE IV: The average quantitative metrics on the T1w kneedata and T2W brain data at R = 7.6.
表 IV:在 R = 7.6 时,T1加权膝关节数据和T2加权脑部数据的平均定量指标



