在前一篇文章基础上,如何将报告图片中的文本解析出来,最近研究了基于Tesseract的OCR方案,Tesseract OCR是一个开源的OCR引擎,主要结合开源的tesseract和pytesseract,实现了jpg/png等格式图片文本识别,供大家参考,具体步骤和测试示例如下。
1.下载和安装tesseract和pytesseract
先安装pytesseract包,安装命令:pip3 install pytesseract
下载tesseract工具,地址:Home · UB-Mannheim/tesseract Wiki · GitHub
下载支持语言包(tessdata),地址:https://github.com/tesseract-ocr/tessdata,解压后拷贝到D:\tools\Tesseract-OCR目录下。
2.配置环境变量
配置环境到path变量:D:\xxx\Tesseract-OCR\tessdata和D:\xxx\Tesseract-OCR
增加环境变量TESSDATA_PREFIX=D:\xxx\Tesseract-OCR\tessdata
查看Tesseract的配置运行情况:tesseract -v 和 tesseract --list-langs
3.修改tesseract_cmd命令路径
修改pytesseract下的pytesseract.py文件,将tesseract路径设置为如下路径,具体如下:
tesseract_cmd = 'D:\xxx\Tesseract-OCR\tesseract.exe'
4.测试示例
# 利用tesseract实现图像的OCR,通过OCR提取图像中的文本信息,详见txt目录。
localFiles=['d:\img\1.jpg']
image = Image.open(Path(localFiles[i]))
ocr_text = pytesseract.image_to_string(image)
ocrfilename = localFiles[i].split('\\')[-1][:-4]
with open(os.path.join(output_folder, f'{ocrfilename}.txt'), 'w', encoding='utf-8') as ocr_file: ocr_file.write(ocr_text)
print(str(i) + ".", ocrfilename, ' is completed by ocr')
5.OCR识别结果
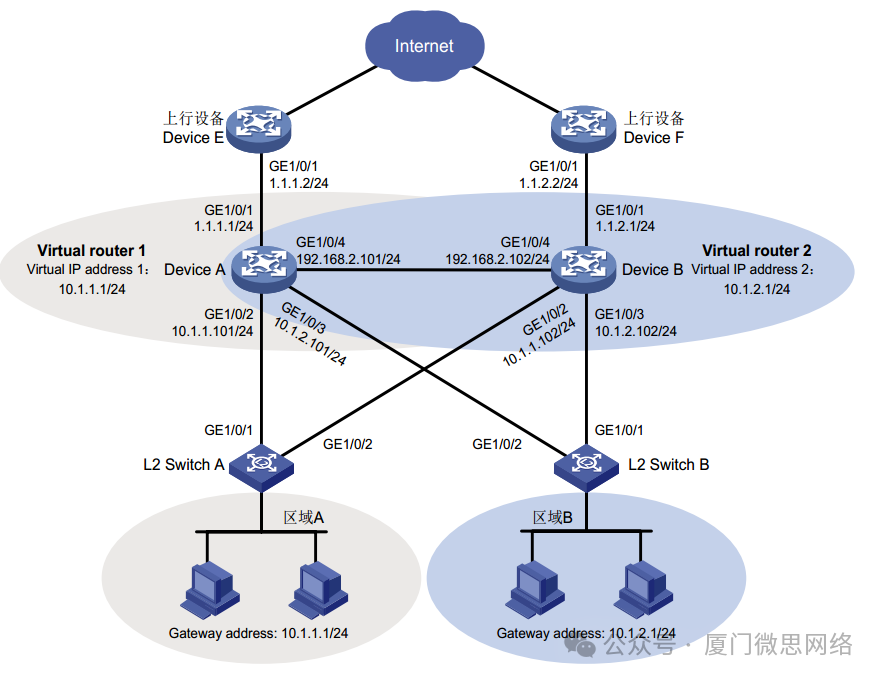
原始图片

识别文字结果