02-分布式对象存储设计原理
保存图片、音视频等大文件就是对象存储:
-
很好的大文件读写性能 -
还可通过水平扩展实现近乎无限容量 -
并兼顾服务高可用、数据高可靠
对象存储“全能”,主要因为,对象存储是原生分布式存储系统,相比MySQL、Redis等单机存储系统,虽这些非原生存储系统,也具备集群能力,但它们构建大规模分布式集群非常不易。
随云计算普及,很多新生代存储系统,都是原生分布式系统,原设计目标之一就是分布式存储集群,如[ES]、[Ceph]和国内很多大厂推出的新一代数据库,做到:
-
近乎无限存储容量 -
超高读写性能 -
数据高可靠:节点磁盘损毁不会丢数据 -
实现服务高可用:节点宕机不会影响集群对外提供服务
这些原生分布式存储如何实现这些特性?“互相抄作业”,除了存储的数据结构不一样,提供的查询服务不一样以外,这些分布式存储系统,面临的很多问题都一样,实现方法差不多。
对象存储的查询服务和数据结构都简单,是最简单的原生分布式存储系统。
1 对象存储数据咋保存大文件的?
对象存储对外提供的服务,就是近乎无限容量的大文件KV存储,所以对象存储和分布式文件系统之间,无明确界限。对象存储的内部,肯定有很多存储节点,保存这些大文件,这个就是数据节点的集群。
为管理这些数据节点和节点中的文件,还需一个存储系统保存集群的节点信息、文件信息和它们的映射关系。这些为管理集群而存储的数据,叫元数据。保存元数据的存储系统须为集群。但元数据集群存储的数据量少,数据变动不频繁,客户端或网关都会缓存一部分元数据,所以元数据集群对并发要求不高。类似zk或etcd分布式存储即可。
存储集群为对外提供访问服务,还要一个网关集群,对外接收外部请求,对内访问元数据和数据节点。网关集群中的每个节点不需保存任何数据,都是无状态节点。有些对象存储没有网关,是客户端,功能和作用一样。

对象存储如何处理对象读写请求?处理读和写请求的流程一样。网关收到对象读写请求后,先拿请求中的Key,去元数据集群查找这Key在哪个数据节点,再去访问对应数据节点读写数据,最后把结果返回给客户端。
这张图虽画的对象存储集群结构,但名词改改,可套用到绝大多数分布式文件系统和数据库上去,如HDFS。
2 对象如何拆分和保存的?
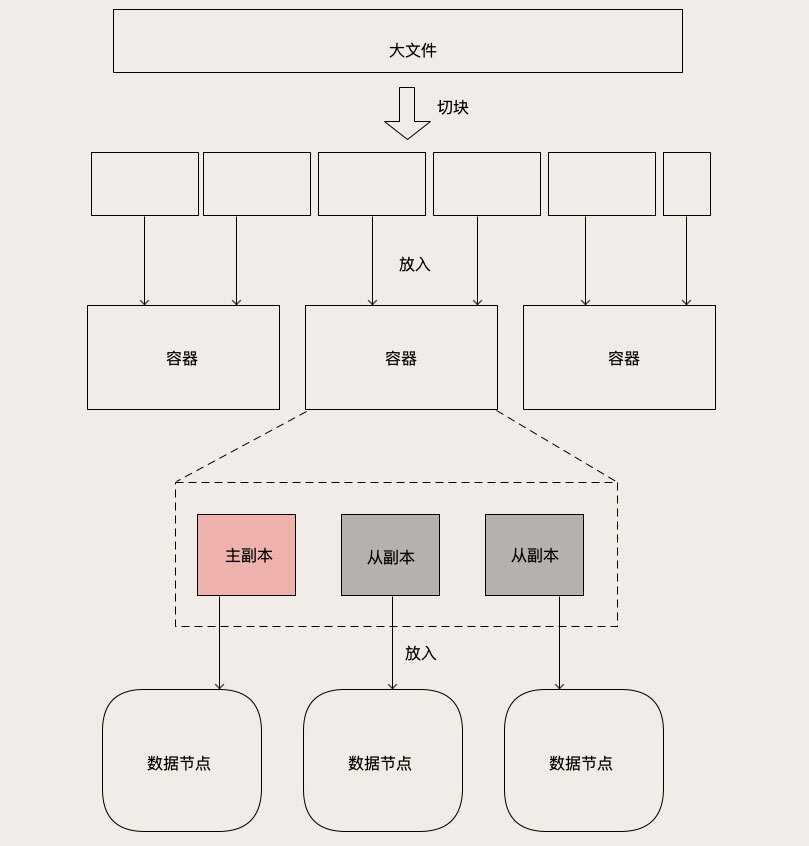
对象存储如何保存大文件对象。一般,对象存储中保存的文件都是图片、视频大文件。在对象存储中,每个大文件都会被拆成多个大小相等块儿(Block),把文件从头到尾按固定块大小,切成一块一块,最后一块长度有可能不足一个块大小,也按一块处理。块大小配置为几十KB到几MB。
大对象文件拆分成块的目的:
-
提升读写性能,这些块可分散到不同的数据节点,就可并行读写 -
把文件分成大小相等块儿,便于维护管理
对象被拆成块后,还是过于碎片化,如直接管理这些块,会导致元数据的数据量大,也没必要管理到这么细粒度。所以一般都会再把块聚合,放到块的容器。“容器”,存放一组块的逻辑单元。没有统一叫法,如ceph中称为Data Placement。容器内的块数大多固定,所以容器大小也固定。
容器类似MySQL和Redis的“分片”,都是复制、迁移数据的基本单位。每个容器都会有N个副本,这些副本的数据都一样。其中有一个主副本,其他是从副本,主副本负责数据读写,从副本去到主副本上去复制数据,保证主从数据一致。
对象存储一般不记录类似Binlog的日志。主从复制复制的不是日志,而是整块数据:
-
性能。操作日志里就包含数据。在更新数据时,先记录操作日志,再更新存储引擎中的数据,相当于在磁盘上串行写2次数据。对于像数据库这种,每次更新的数据都很少的存储系统,这个开销可接受。但对于对象存储,它每次写入的块很大,两次磁盘IO的开销就有些不太值得 -
存储结构简单,即使没有日志,只要按照顺序,整块儿的复制数据,仍然可以保证主从副本的数据一致性。
以上的对象(即文件)、块和容器,都是逻辑层概念,数据落实到副本上,这些副本就是真正物理存在。这些副本再被分配到数据节点上保存起来。这里的数据节点就是运行在服务器上的服务进程,负责在本地磁盘上保存副本的数据。
数据访问
请求一个Key时:
-
网关首先去元数据查找这个Key的元数据 -
然后根据元数据中记录的对象长度,计算出对象有多少块 -
就可分块并行处理。对每个块,还要再去元数据,找到它被放在哪个容器
容器就是分片,怎么把块映射到容器,不同的系统选择实现的方式也不一样,有用哈希分片的,也有用查表法把对应关系保存在元数据。找到容器后,再去元数据中查找容器的N个副本都分布在哪些数据节点上。然后,网关直接访问对应的数据节点读写数据就可以了。
小结
对象存储是最简单的分布式存储系统,主要由数据节点集群、元数据集群和网关集群(或者客户端)三部分构成。数据节点集群负责保存对象数据,元数据集群负责保存集群的元数据,网关集群和客户端对外提供简单的访问API,对内访问元数据和数据节点读写数据。
为了便于维护和管理,大的对象被拆分为若干固定大小的块儿,块儿又被封装到容器(也就分片)中,每个容器有一主N从多个副本,这些副本再被分散到集群的数据节点上保存。
对象存储虽然简单,但是它具备一个分布式存储系统的全部特征。所有分布式存储系统共通的一些特性,对象存储也都具备,比如说数据如何分片,如何通过多副本保证数据可靠性,如何在多个副本间复制数据,确保数据一致性等等。
希望你不仅学会对象存储,还要对比分析,对象存储和其他分布式存储系统如MySQL集群、HDFS、ES等有啥共同地方,差异在哪。想通这些,你对分布式存储系统的认知,绝对上升全新高度。然后再看之前不了解的存储系统,就简单了。
FAQ
对象存储不是基于日志来进行主从复制。假设对象存储一主二从三副本,采用半同步方式复制数据,即主副本和任意一个从副本更新成功后,就给客户端返回成功响应。主副本所在节点宕机之后,这两个从副本中,至少有一个副本上的数据是和宕机的主副本上一样的,我们需要找到这个副本作为新的主副本,才能保证宕机不丢数据。
但没有日志,如果这两个从副本上的数据不一样,如何确定哪个上面的数据是和主副本一样新?
如果出现缓存不同步的情况,在你负责的业务场景下,该如何降级或者补偿?
设置一个合理TTL,即使出现缓存不同步,等缓存过期后就会自动恢复。再如识别用户手动刷新操作,强制重新加载缓存数据(注意防止大量缓存穿透)。还可以在管理员后台系统中,预留一个手动清除缓存的功能,必要的时候人工干预。
做素材库的,现在自建对象服务器,对象服务器里面大多都是图片素材,场景是读多写少。选择Ceph可以用于生成环境吗?建议你使用公有云的对象存储服务,小规模的公司自建对象存储维护成本太高,不是太划算。
对象存储的cdn缓存是怎么做的?是每次要访问这些元数据,还是直接把这些源数据所有都放在内存里?数据量这么大感觉不适合放内存里吧?CDN缓存的文件一般是保存在CDN节点的磁盘上,当然不排除某些CDN会用节点的内存缓存文件,加速访问。
为什么分块后又聚合到容器中,直接一个容器一个块不行吗?
一个容器就是一个分片,是数据复制的基本单位。也就是说,每个分片都有n个 副本。
分片不能做的太小,越小意味着存储同样容量的数据,分片数量越多。数量过多,查找分片时,需要查找的元数据就会太多,影响查找效率。
对数据复制,同样要有一定的开销,比如记录日志位置,维护数据一致性的开销。分片太小,相对的,这些开销就大。
数据冗余技术主要由两种:
-
传统副本复制 -
纠删码,基于纠删算法,时间换空间 (著名开源对象存储MinIO就是基于纠删码的)
获取更多干货内容,记得关注我哦。
本文由 mdnice 多平台发布