随着企业不断壮大,信息孤岛的问题变得日益突出,信息集成因此成为企业发展的关键因素。在数据分析过程中,数据集成是必不可少的一环。ETLCloud是一款强大的数据集成和管理平台,专注于数据的提取、转换和加载(ETL),并提供了一个简洁明了的用户界面,便于用户在各个数据源之间进行迁移和转换。下面从四个中数据处理方式上分析一下ETLCloud支持的数据处理类型。
一、数据抽取
ETLCloud支持从各种不同的数据源进行数据抽取。包括常规关系数据库、数仓、消息队列、API以及各种文件。
1.从数据库抽取数据:
对于各种系统来说,各种数据基本都是存在各自的系统数据库中,因此,从数据库中抽取数据是数据集成最常见的场景。

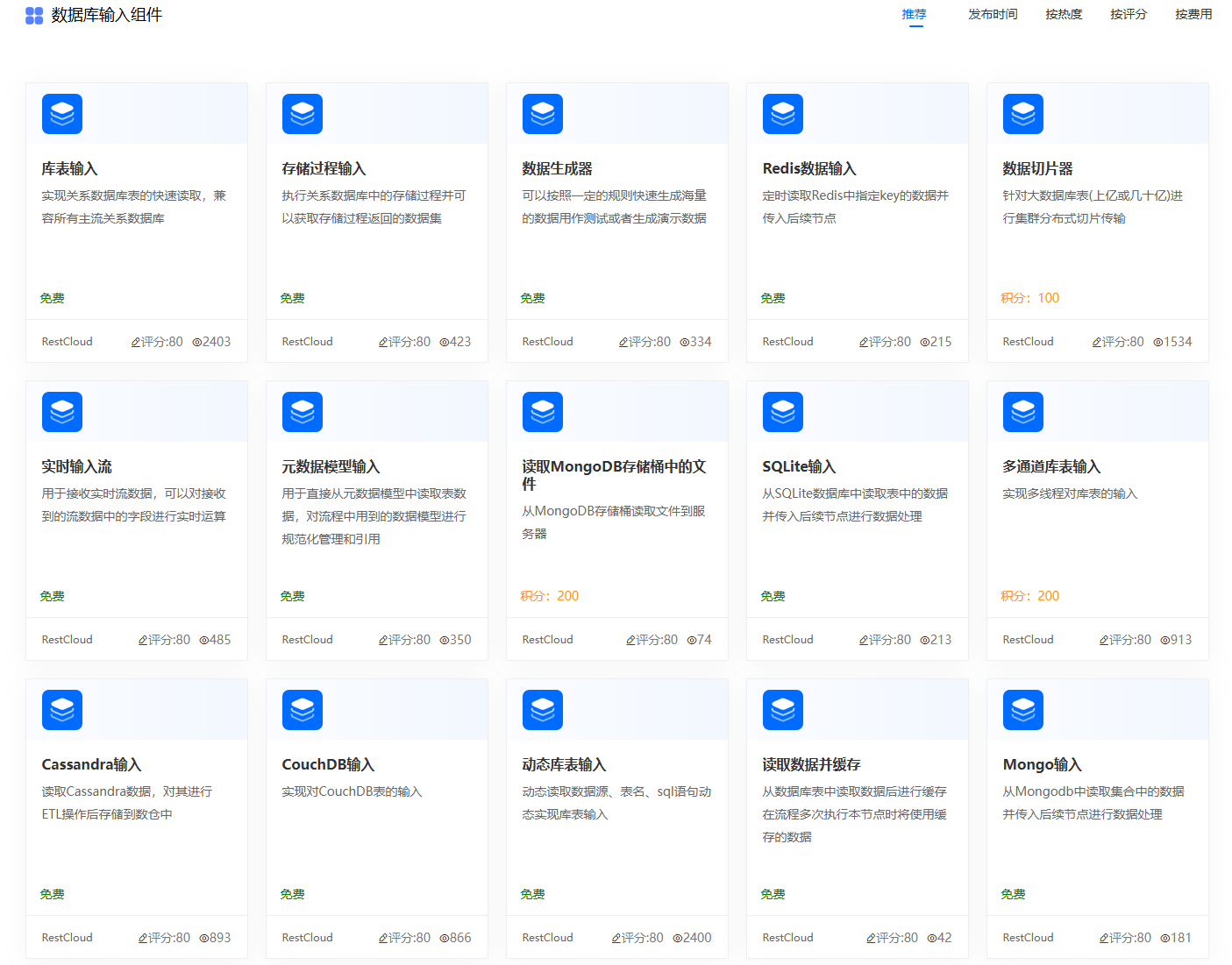
官网数据库数据输入组件:
2.从消息队列中抽取消息数据
在现代系统中,为了解决系统间的强耦合以及提高系统吞吐量与并发程度,消息队列已经成为了各系统中不可或缺的元素,ETLCloud也支持从市面上的各种消息队列抽取数据。
在ETLCloud连接MQ:

3.从API中获取数据
当数据分散在不同的系统、应用或服务中时,API 是一种方便的数据交换方式,此外某些场景需求,可能需要调用特定的API并且从请求的返回消息中提取数据。ETLCloud支持调用第三方系统的认证接口,获取认证令牌后再调用其他接口并从接口中获取数据。
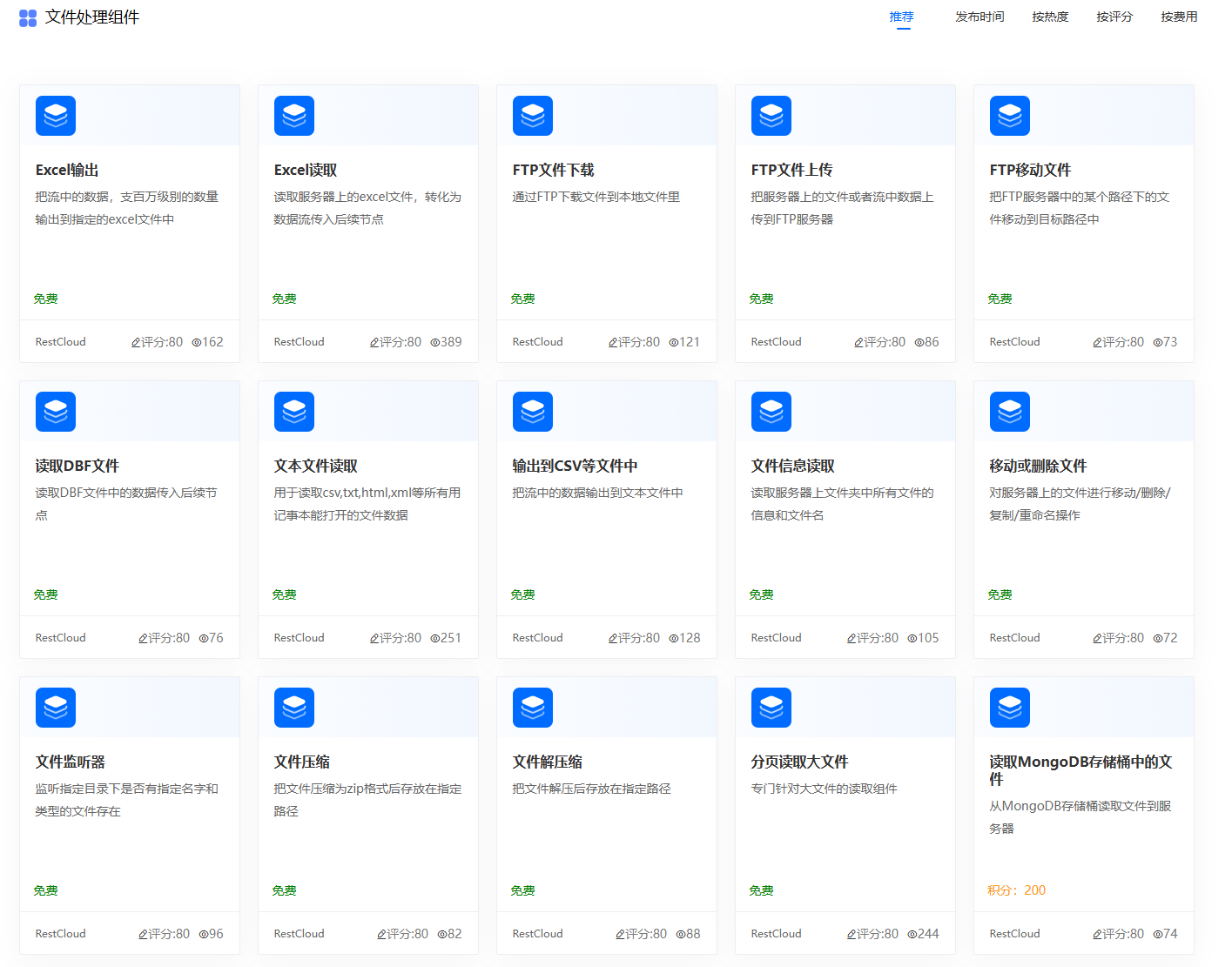
4.从文件中解析数据
有些数据保存在各式各样的文件中,ETLCloud同样支持从各类文件中读取数据加载到流程中等待后续进一步的处理。
二、数据同步
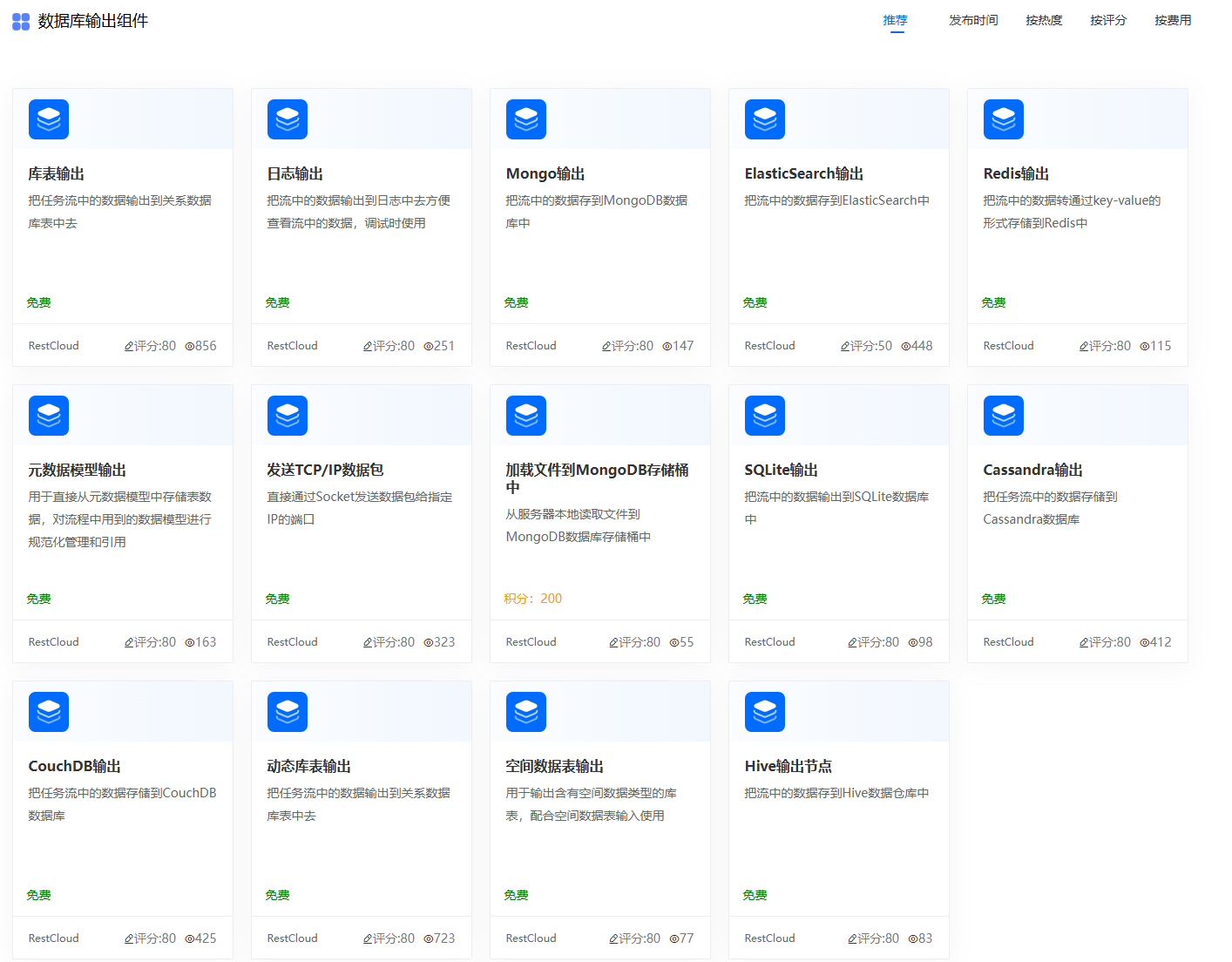
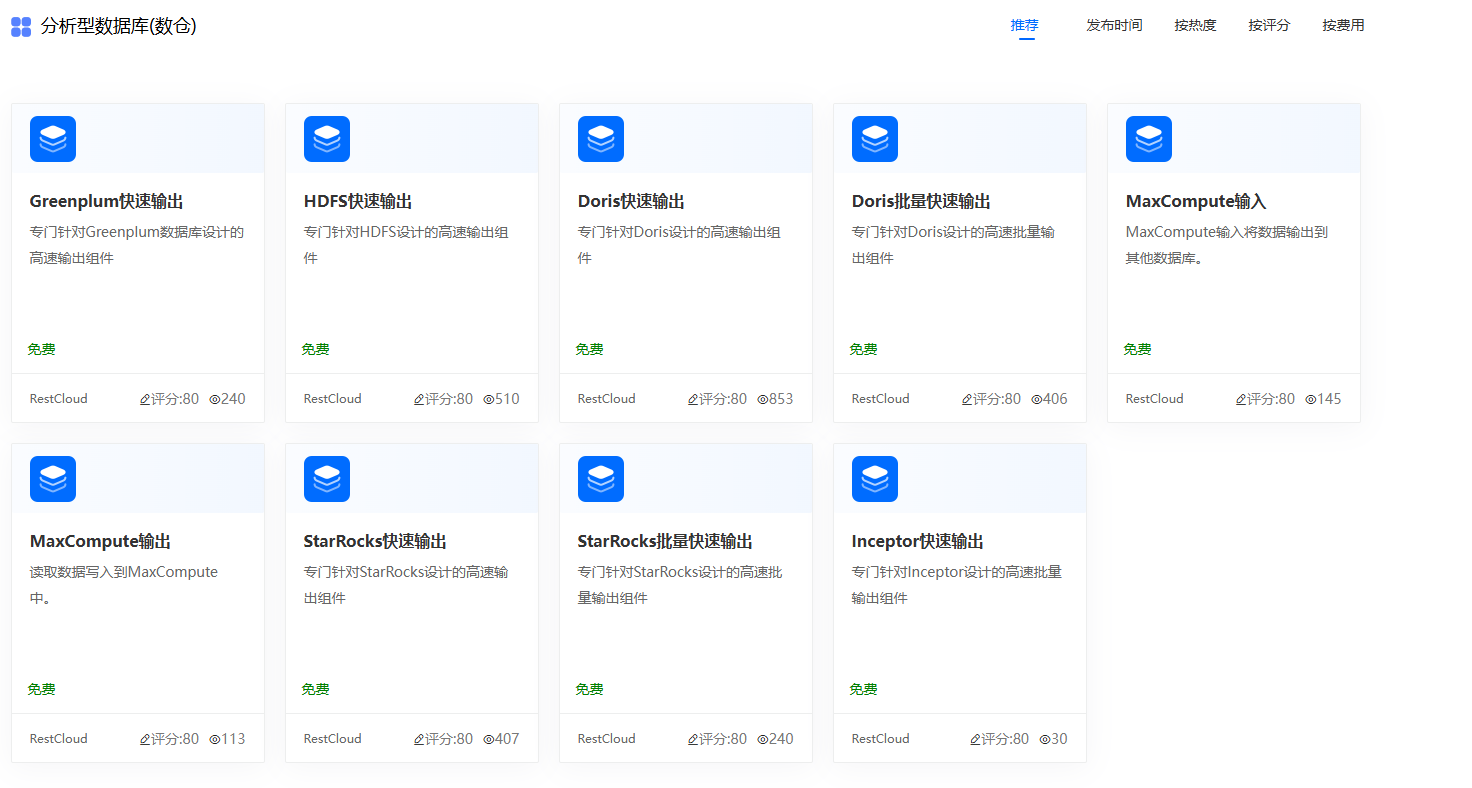
在数据集成的过程中,最后都是将处理好的数据同步到目标数据源,ETlCloud提供了库表输出组件来将流程内存中的数据落库到目标数据库中,并且针对一些数仓数据库,根据其特性提供了专用类型的数仓输出组件。同时也一并支持将数据写入消息队列、各种文件中。
1.数据清洗
数据集成通常涉及从多个来源的数据,而这些数据可能存在不一致、缺失、重复或错误的情况。数据清洗是确保集成后数据质量的关键步骤。它有助于识别并纠正这些问题,确保最终的数据准确、完整且可用,从而为后续分析、报告或决策提供可靠依据。ETLCloud主要在流程设计中通过组件来对数据进行清洗。
2.使用规则对数据流中的字段值进行清洗
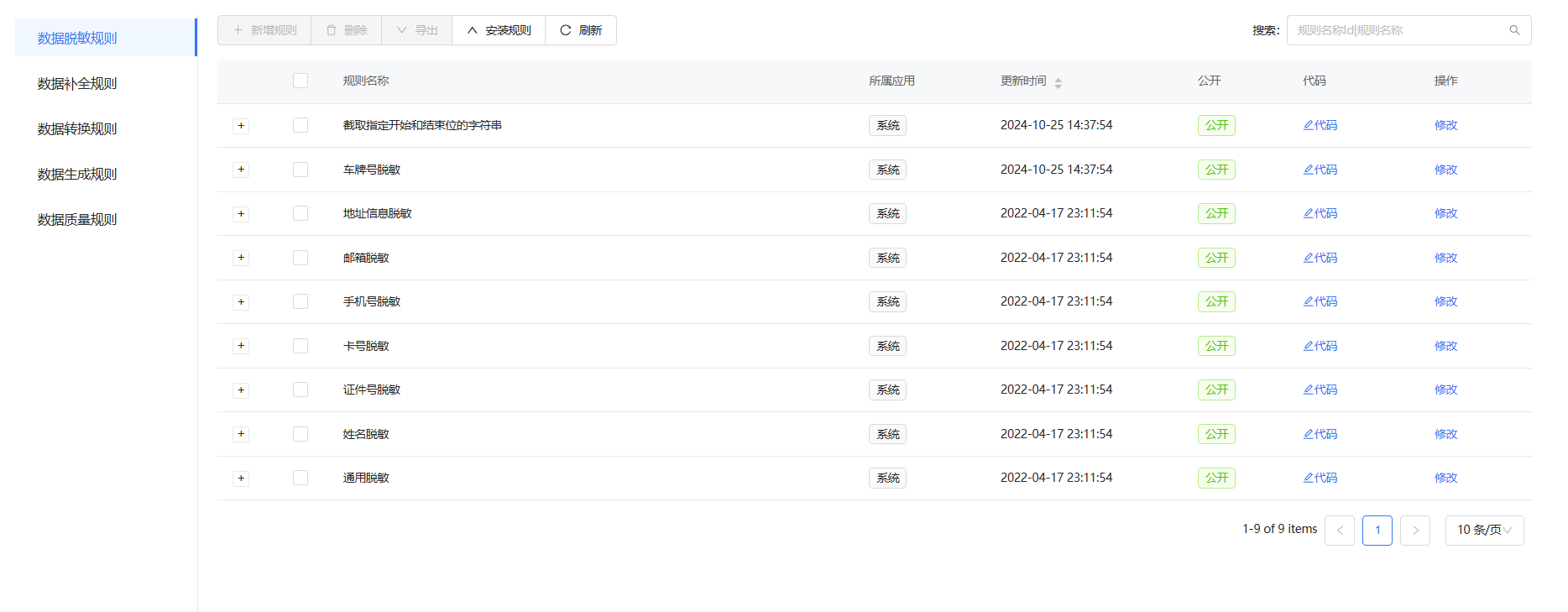
ETLCloud系统内置了多种数据清洗规则,可以在库表输入、库表输出等组件为字段绑定规则,流程在运行时会对数据流中的数据进行针对性清洗。
系统自带常见数据清洗规则:
为数据绑定清洗规则:
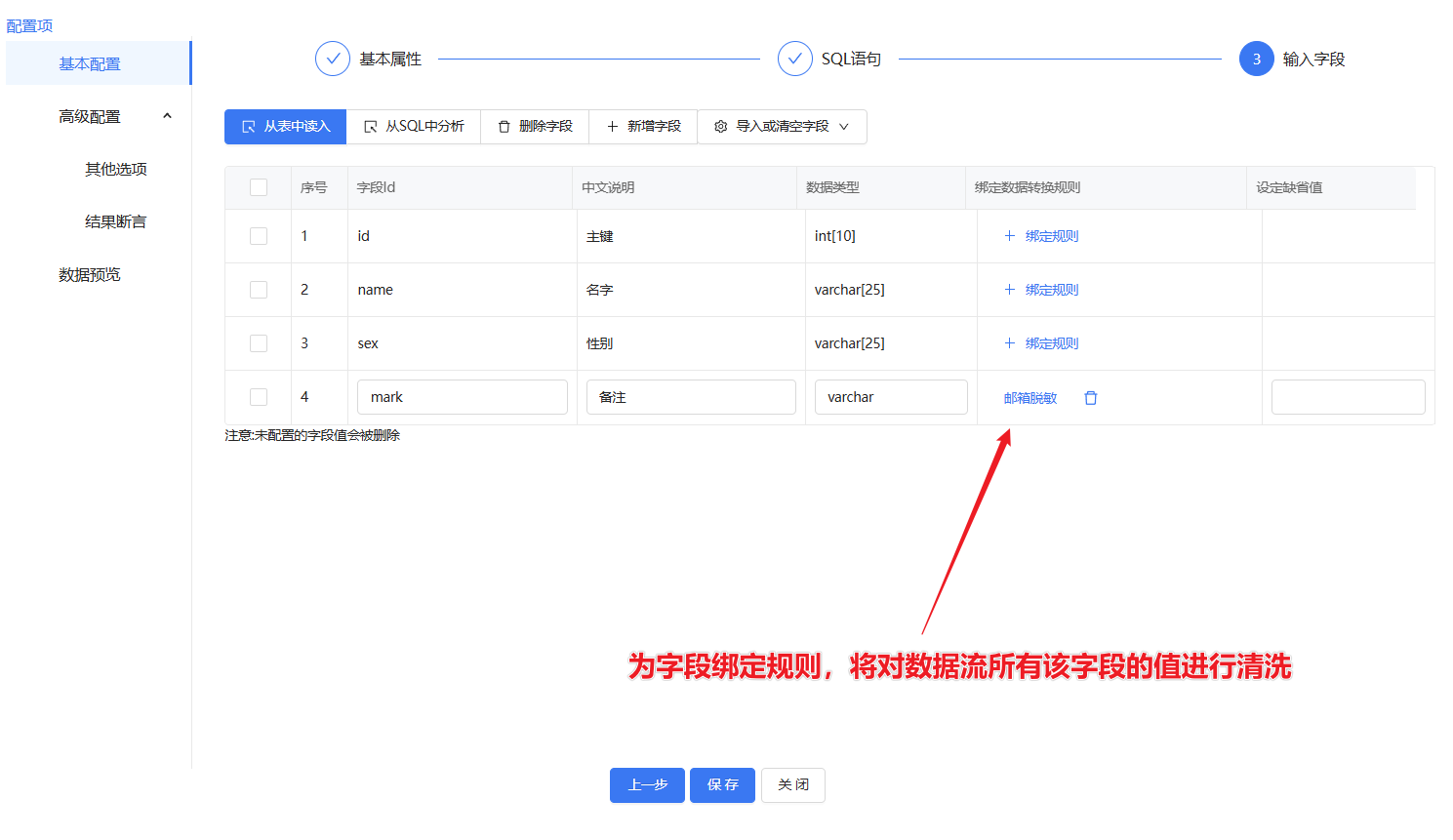
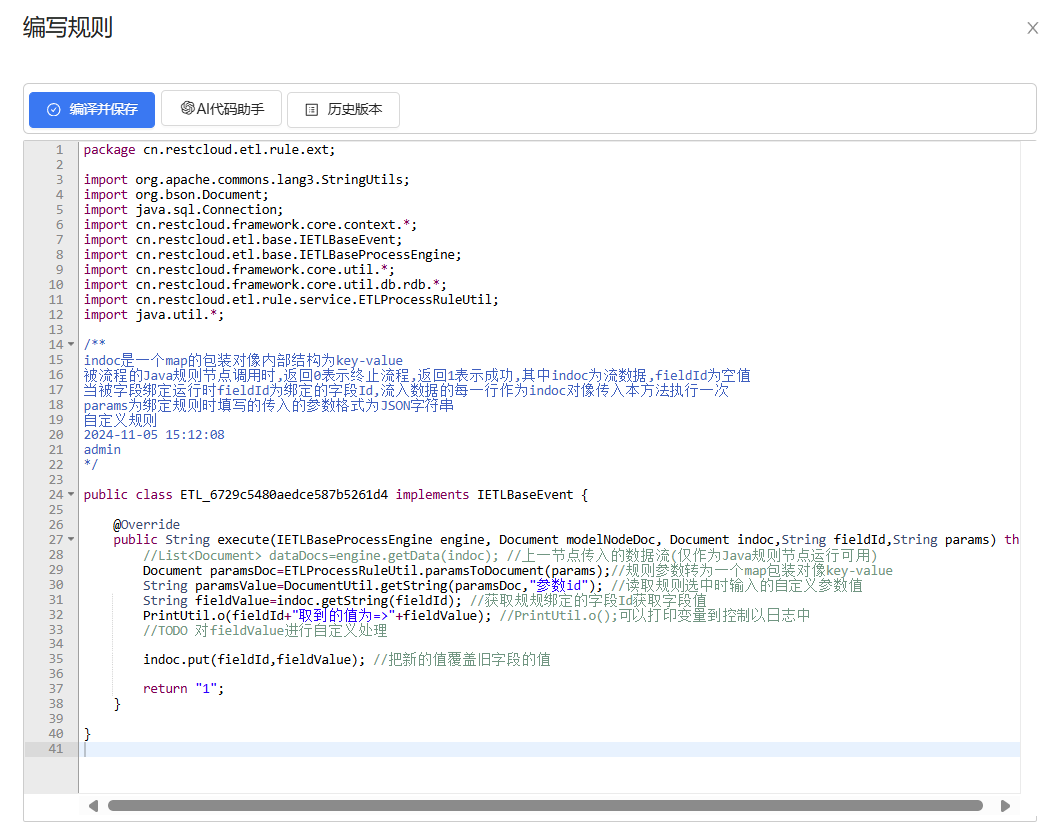
3.手动编写逻辑进行规则清洗
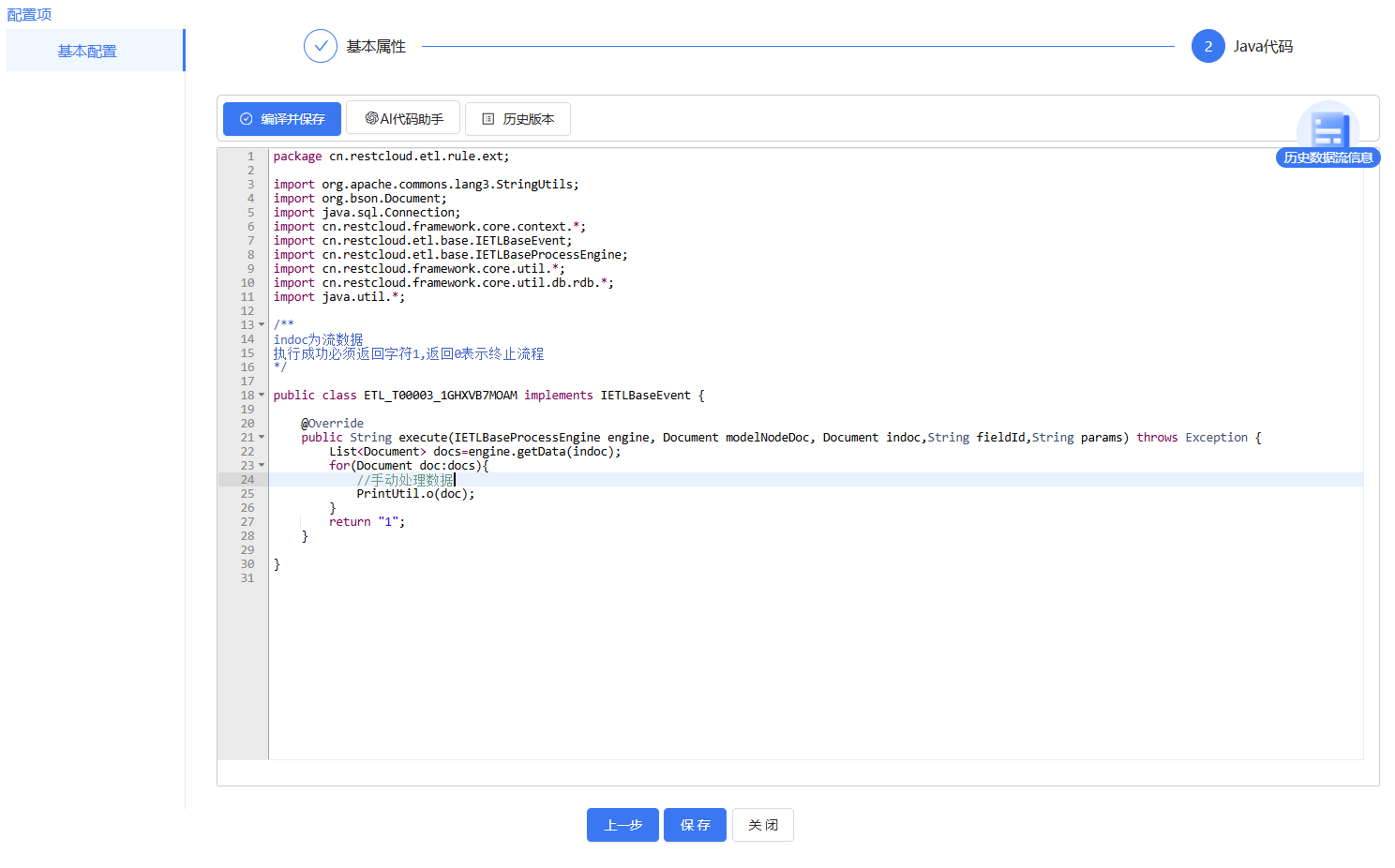
系统自带的规则以及官网提供的规则可能都不满足一些场景的数据清洗要求,此时可以自定义规则,或者使用脚本组件来手动处理数据。
手动编写规则:
在脚本组件处理数据:
4.流程通过组件进行清洗
ETLCloud预设自带一些数据清洗组件,也可以从官网下载。
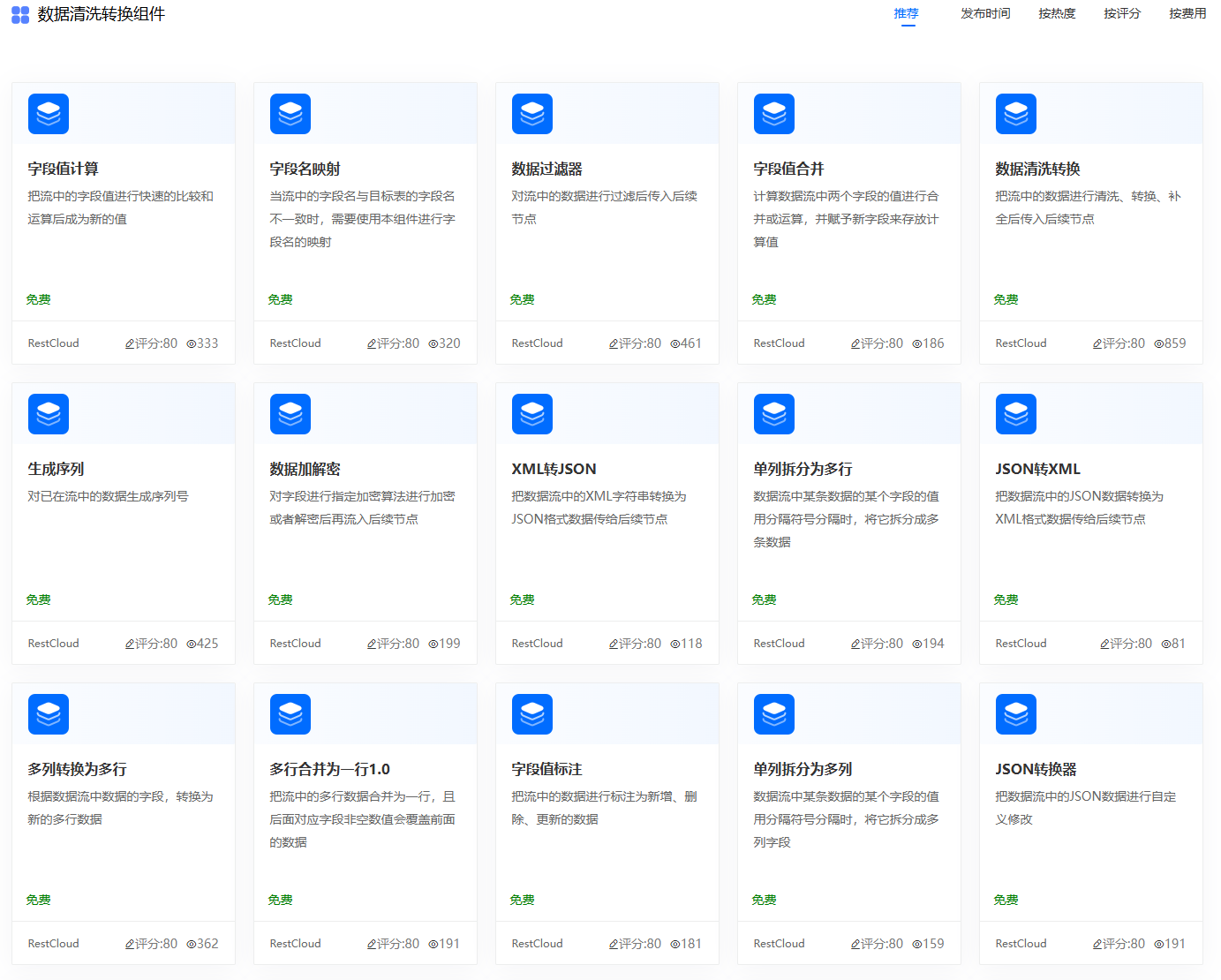
三、数据融合
数据集成过程中,除了对数据值进行清洗外,还有个关键点是处理多源异构数据,异构数据的处理通常涉及结构统一化、语义一致化、去重、填充缺失值、数据类型转换等多个方面。通过数据融合,可以有效地将来自不同来源的数据合并在一起,消除差异,确保数据的完整性、准确性和一致性。这为后续的分析、报告和决策提供了可靠的数据基础。ETLCloud提供了非常多的组件,足以应对各种数据结构转换成相同结构的问题,并把转换好的数据融合到一起。
数据运算组件:
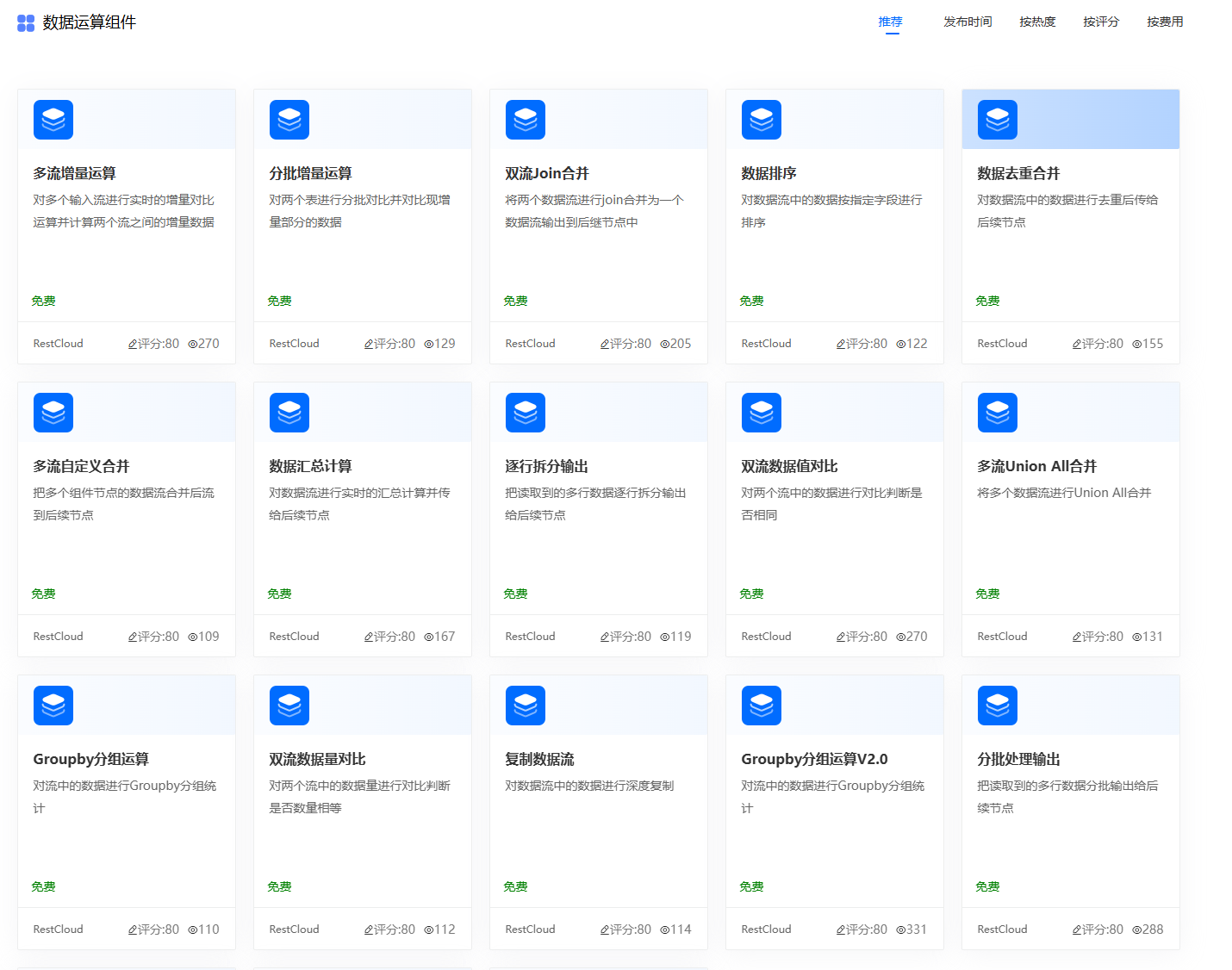
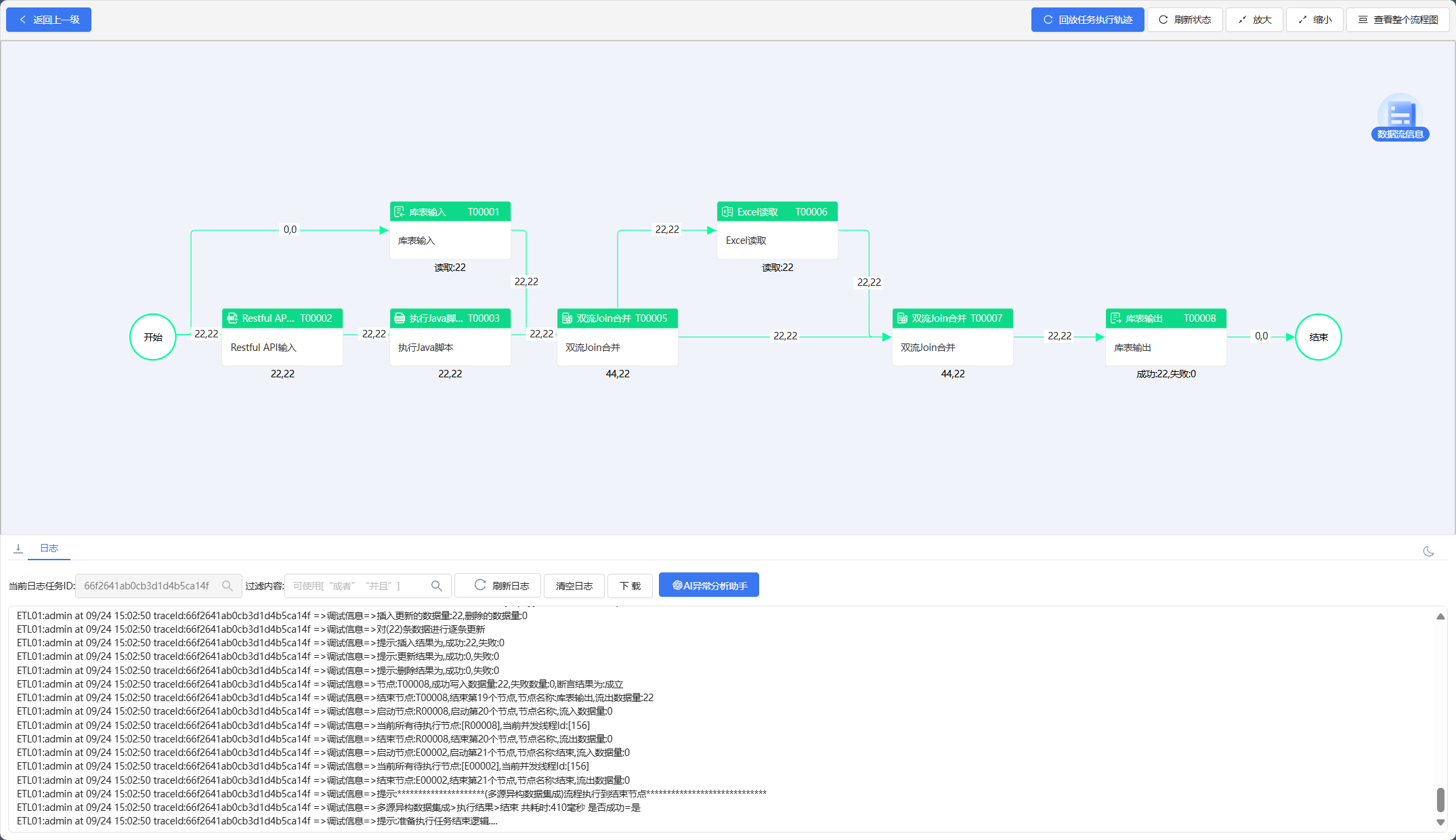
多源异构数据融合演示(数据库数据、API响应数据、Excel表格数据):
四、数据监听
为了保证数据的实时有效性,ETLCloud还支持对数据库、消息队列、文件夹进行监听,实时获取数据的变更情况,及时地发起同步流程,确保数据一致性。
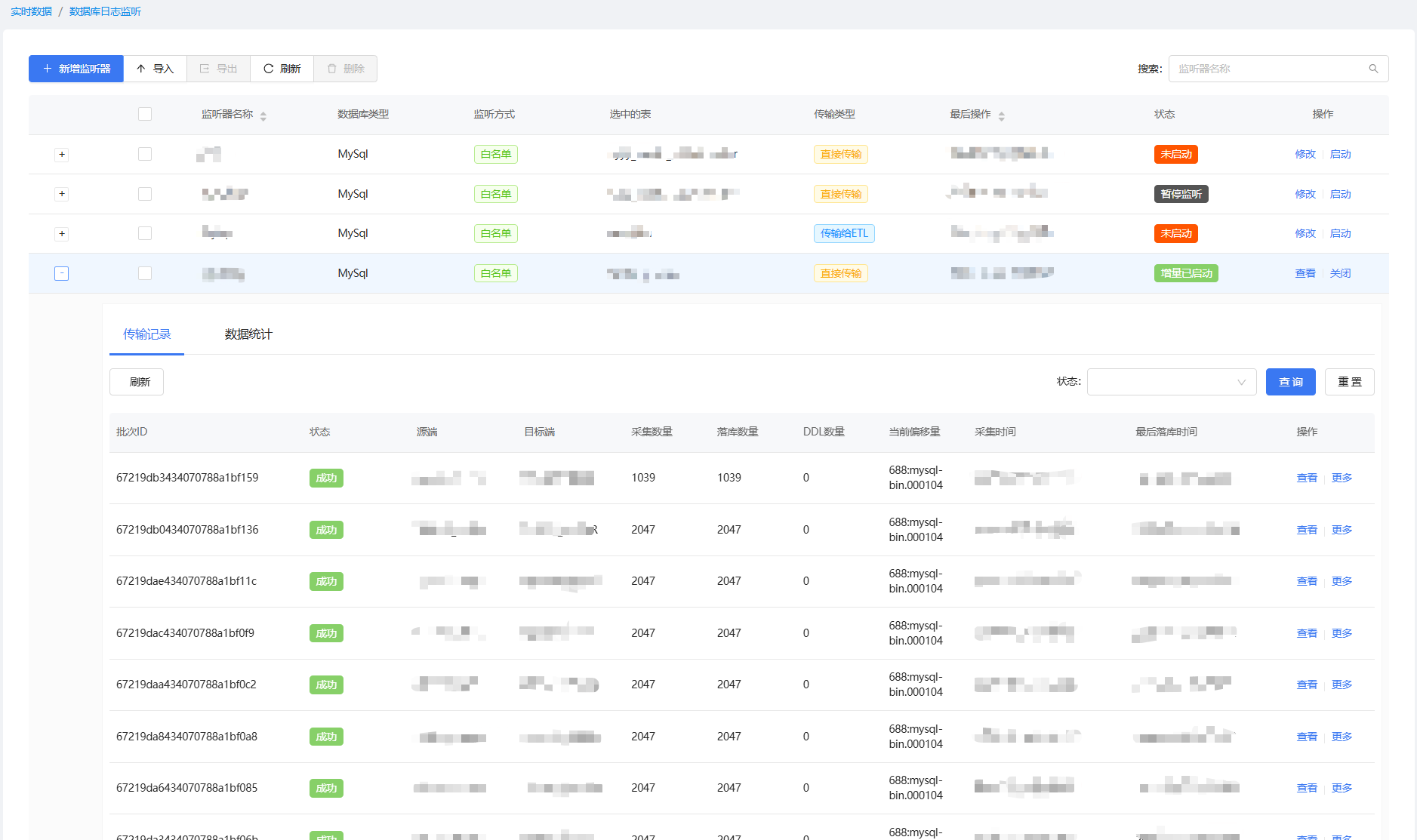
1.数据库监听
社区版支持监听的源端数据库有Mysql、Oracl、PostgreSql、SqlServer,数据库需要根据文档开启前置功能才能正常使用ETlCloud监听数据库。监听到的数据可以直接传输到目标库,也可以直接输出到kafka,或者要对监听到的数据做处理后在入库可以选择将数据传输到ETL流程,在流程中欧给处理监听到的数据并做落库等处理。
CDC监听器:
2.kafka监听
社区版ETLCloud还支持kafka监听,可以将监听到的kafka消息传输到ETL流程中处理。
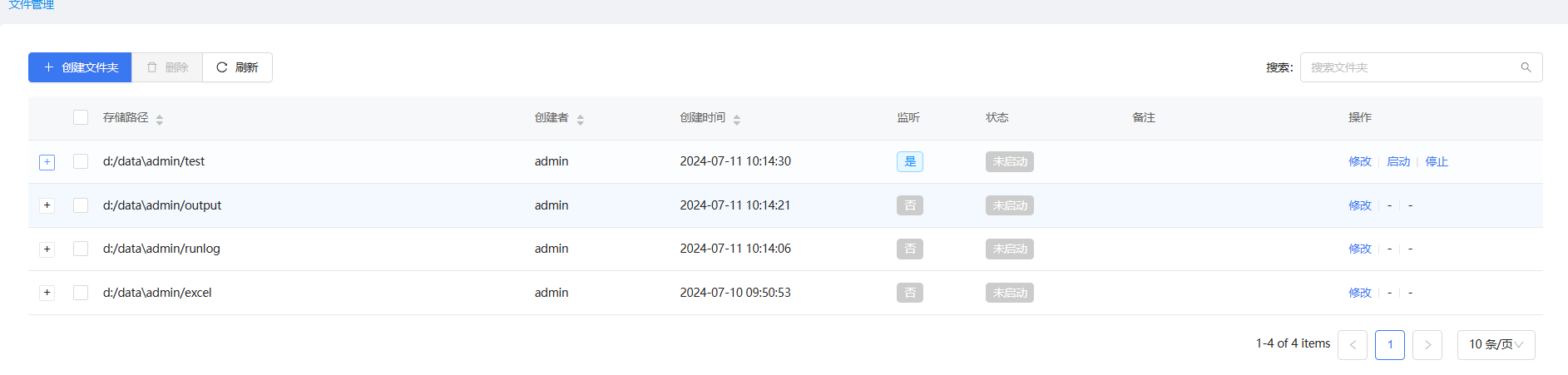
3.文件夹监听
ETLCloud还可以监听文件夹状态,一旦文件夹里面的文件有新增的情况下也可以启动流程并处理流程逻辑。