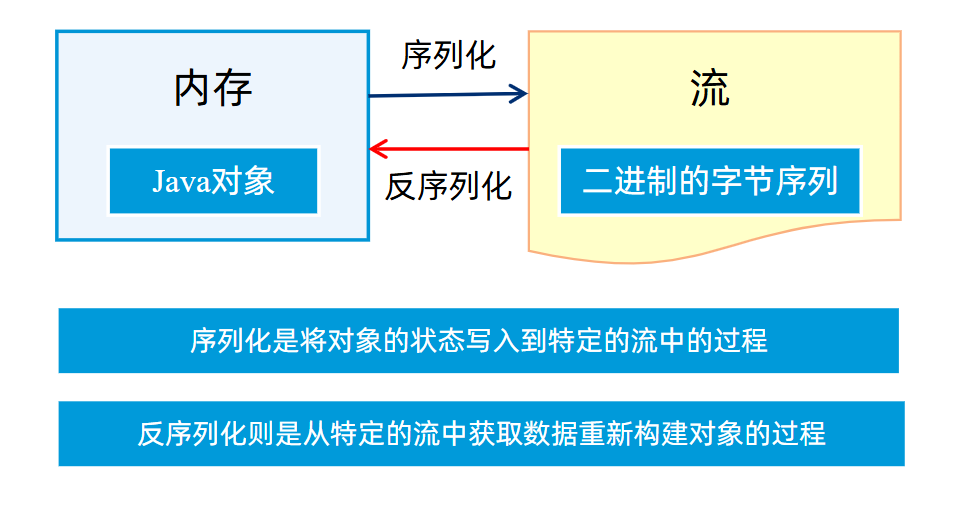
安装
安装包获取
可以自己找资源,我这里也有百度云的资源,如果没失效的话可以直接用。

通过百度网盘分享的文件:RabbitMQ
链接:https://pan.baidu.com/s/1rzcdeTIYQ4BqzHLDSwCgyw?pwd=fj79
提取码:fj79
安装教程可参考:消息队列RabbitMQ在Windows中安装与配置完全解析_rabbitmq windows-CSDN博客
主要就是安装和设置环境变量,安装的时候版本对应上就可以了。
插件安装
安装插件后就可以后续进入到 web 的管理界面
rabbitmq-plugins.bat enable rabbitmq_management
启动服务
rabbitmq-service start
界面操作
http://127.0.0.1:15672/
用户名密码默认都是 guest

登录到界面,就可以看到队列的整体情况了。

还可以在界面上进行新增队列等操作

pika使用
可使用 python 的第三方包 pika 连接使用 rabbitmq 进行消息队列的发送和接收,示例如下。
我下面的示例使用的是 pika==0.13.1,所以先安装包 pip install pika==0.13.1
server.py
import jsonimport pika# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))# 有密码
credentials = pika.PlainCredentials("guest", "guest")
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1',port=5672,virtual_host='/',credentials=credentials))channel = connection.channel()# 创建一个队列
channel.queue_declare(queue='hello')# 发送数据
for i in range(5):value = f"Hello world! {i}"print(f"Sent '{value}'")msg = {"key": value}body = json.dumps(msg)# 同一条消息同时往多个队列发送channel.basic_publish(exchange='',routing_key='hello', # 消息队列名称body=body) # 发送的数据channel.basic_publish(exchange='',routing_key='test_queue', # 消息队列名称body=body) # 发送的数据connection.close()
client.py
import jsonimport pikacredentials = pika.PlainCredentials('guest', 'guest') # rabbit用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1', port=5672, virtual_host='/', credentials=credentials))
channel = connection.channel()channel.queue_declare(queue='hello')# 3.确定回调函数
def callback(ch, method, properties, body):print("Received %r" % body)# 手动应答s = body.decode('utf-8') # 将 bytes 转换为字符串data = json.loads(s)print(data)# 4.确定监听队列参数
channel.basic_consume(callback,queue='hello',no_ack=True)print('Waiting for messages. To exit press CTRL+C')# 5.正式监听
channel.start_consuming()
注意事项
报错解决
如果报错:
AttributeError: module 'collections' has no attribute 'Callable'将报错行的 collections.Callable 修改为 collections.abc.Callable 即可。
这个报错一般是 python 的版本太高导致。
队列堆积
如果队列消息生产的速度大于消费的速度,可能造成队列堆积,堆积到一定程度以后,可能导致 rabbitmq 崩溃,所以一般可以启动多个消费者来进行消费。
连接断开
消费者默认并不是取一个消费一个,一般是取一批数据先进行消费,消费完以后再去取下一批数据,如果两次取数间隔时间比较长。或者消费者连接 rabbitmq 的连接如果没有长时间去取数的话,会导致远端强制关闭连接。
报错:
(-1, "ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)")此时,可以通过 while True ,报错时重新连接取数。
import json
import timeimport pika# 3.确定回调函数
def callback(ch, method, properties, body):print("Received %r" % body)time.sleep(10)# 手动应答s = body.decode('utf-8') # 将 bytes 转换为字符串data = json.loads(s)print('Waiting for messages. To exit press CTRL+C')# 5.正式监听
while True:try:credentials = pika.PlainCredentials('guest', 'guest') # rabbit用户名和密码# connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1', port=5672, virtual_host='/', credentials=credentials, heartbeat=0))connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1', port=5672, virtual_host='/', credentials=credentials))channel = connection.channel()channel.queue_declare(queue='duoshu_mq') # 队列声明, queue 为空时 自动命名队列channel.basic_consume(callback,queue='duoshu_mq',no_ack=True)channel.start_consuming()except Exception as e:print("!!!!!!!!")print(e)
或者设置连接参数的 heartbeat 为 0 进行解决,表示关闭心跳检测。
connection = pika.BlockingConnection(pika.ConnectionParameters('127.0.0.1', port=5672, virtual_host='/', credentials=credentials, heartbeat=0))