背景介绍
Apache Doris是一个基于MPP架构的易于使用,高性能和实时的分析数据库,以其极高的速度和易用性而闻名。海量数据下返回查询结果仅需亚秒级响应时间,不仅可以支持高并发点查询场景,还可以支持高通量复杂分析场景。
这些都使得 Apache Doris 成为报表分析、即席查询、统一数据仓库和数据湖查询加速等场景的理想工具。在 Apache Doris 上,用户可以构建各种应用,如用户行为分析、AB 测试平台、日志检索分析、用户画像分析、订单分析等。
2023年亚洲多丽丝峰会即将到来,热烈邀请您加入!单击“立即 🔗doris-summit.org.cn
🎉 版本 2.0.2 版本现已发布。2.0.2版本在标准基准测试上实现了超过10倍的性能提升,日志分析和湖仓场景全面提升,数据更新和写入效率更加高效稳定,支持更全面的多租户和资源隔离机制,在资源弹性和存储计算分离的方向上迈出了新的一步。它还为企业用户添加了一系列可用性功能。我们欢迎所有对2.0版本新功能有需求的用户进行部署和升级。在此处🔗查看发行说明。
🎉 1.2.7版本现已发布!它是完全进化的版本,建议所有用户升级到此版本。在此处🔗查看发行说明。
🎉 版本 1.1.5 现已发布。它是基于1.1版本的稳定性改进和错误修复版本。在此处🔗查看发行说明。
👀 查看官方网站,了解🔗Apache Doris的核心功能,博客和用户案例的完整列表。

使用场景
如下图所示,经过各种数据集成和处理后,数据源通常存储在实时数据仓库 Apache Doris 和离线数据湖或数据仓库(在 Apache Hive、Apache Iceberg 或 Apache Hudi 中)。
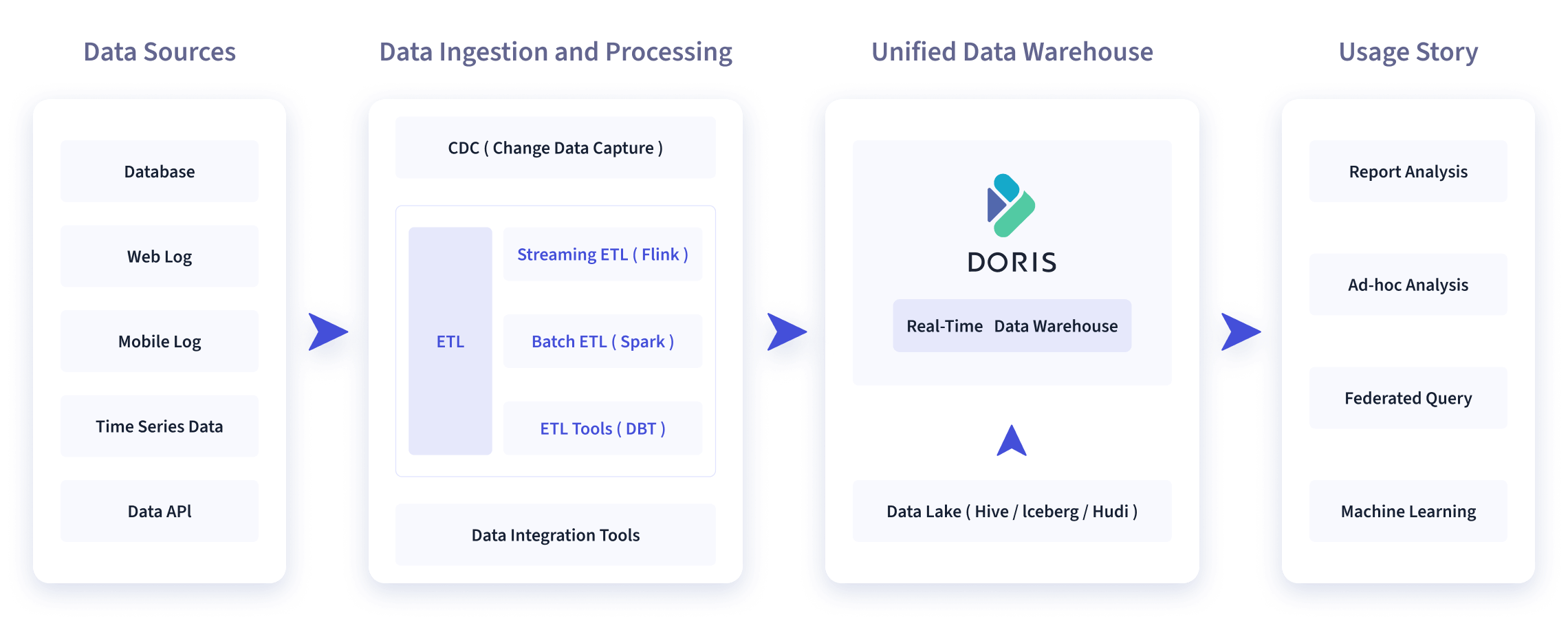
Apache Doris广泛应用于以下场景:
报告分析
实时仪表板 面向内部分析师和经理的报告 高度并发的用户导向或客户导向的报告分析:例如通常需要数千个QPS和以毫秒为单位的快速响应时间的网站分析和广告报告。一个成功的用户案例是,Doris 已被中国电子商务巨头 JD.com 用于广告报告,它每天接收 10 亿行数据,处理超过 10,000 QPS,并提供 99 毫秒的 150% 查询延迟。 即席查询。面向分析师的自助式分析,具有不规则的查询模式和高吞吐量要求。小米基于Doris构建了增长分析平台(Growth Analytics,GA),利用用户行为数据进行业务增长分析,平均查询延迟为10秒,第95百分位查询延迟为30秒或更少,每天数万次SQL查询。
统一数据仓库建设。Apache Doris允许用户通过单一平台构建统一的数据仓库,省去处理复杂软件栈的麻烦。中国火锅连锁店海底捞与Doris建立了一个统一的数据仓库,以取代其由Apache Spark,Apache Hive,Apache Kudu,Apache HBase和Apache Phoenix组成的旧复杂架构。
数据湖查询。Apache Doris 通过使用外部表联合 Apache Hive、Apache Iceberg 和 Apache Hudi 中的数据来避免数据复制,从而实现出色的查询性能。
🖥️ 核心概念
📂 Apache Doris的架构 Apache Doris 的整体架构如下图所示。Doris 架构非常简单,只有两种类型的流程。
前端(FE):用户请求访问、查询解析和规划、元数据管理、节点管理等。
后端 (BE):数据存储和查询计划执行
这两种类型的进程都可以水平扩展,单个集群可以支持多达数百台机器和数十 PB 的存储容量。而这两类流程通过一致性协议保证了业务的高可用性和数据的高可靠性。这种高度集成的架构设计大大降低了分布式系统的运维成本。
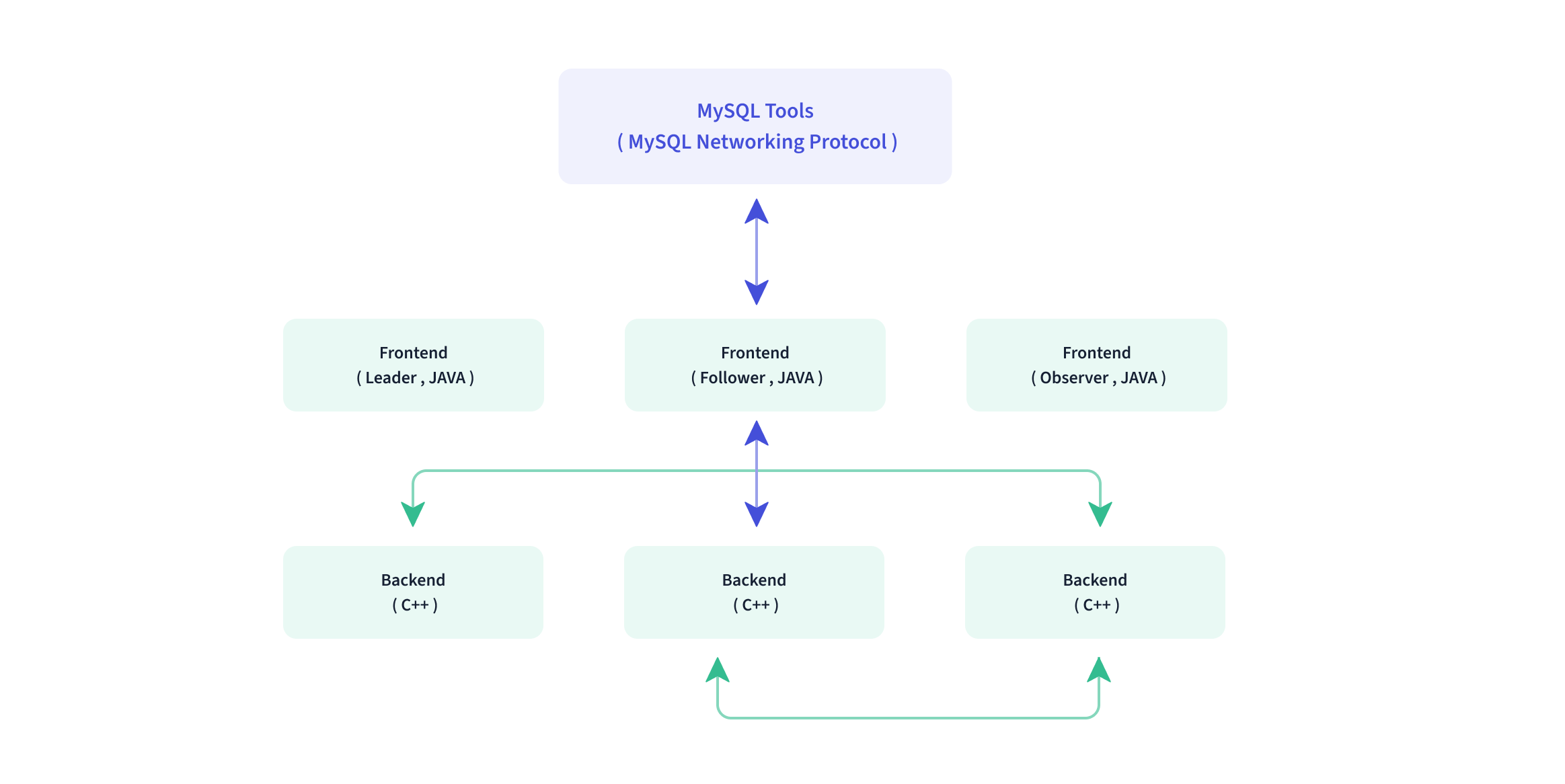
Apache Doris的整体架构
在接口方面,Apache Doris采用MySQL协议,支持标准SQL,与MySQL方言高度兼容。用户可以通过各种客户端工具访问 Doris,它支持与 BI 工具的无缝连接。
💾 存储引擎 Doris 使用列式存储引擎,按列编码、压缩和读取数据。这实现了非常高的压缩比,并大大减少了无关的数据扫描,从而更有效地利用了 IO 和 CPU 资源。Doris 支持多种索引结构,尽量减少数据扫描:
排序复合键索引:用户最多可以指定三列来形成复合排序键。这可以有效地修剪数据,以更好地支持高并发报告方案。 最小/最大索引:这样可以有效筛选数值类型的等效性和范围查询。 布隆过滤器:在高基数列的等价过滤和修剪中非常有效 反转索引:这样可以快速搜索任何字段。 💿 存储模型 Doris 支持多种存储模型,并针对不同场景进行了优化:
聚合键模型:能够合并具有相同键的值列,并显着提高性能
唯一键模型:键在此模型中是唯一的,具有相同键的数据将被覆盖以实现行级数据更新。
重复密钥模型:这是一个详细的数据模型,能够详细存储事实数据表。
Doris 也支持强一致性的物化视图。物化视图自动选择和更新,大大降低了用户的维护成本。
🔍 查询引擎 Doris 在其查询引擎中采用 MPP 模型,实现节点之间和节点内部的并行执行。它还支持多个大型表的分布式随机连接,以处理复杂的查询。
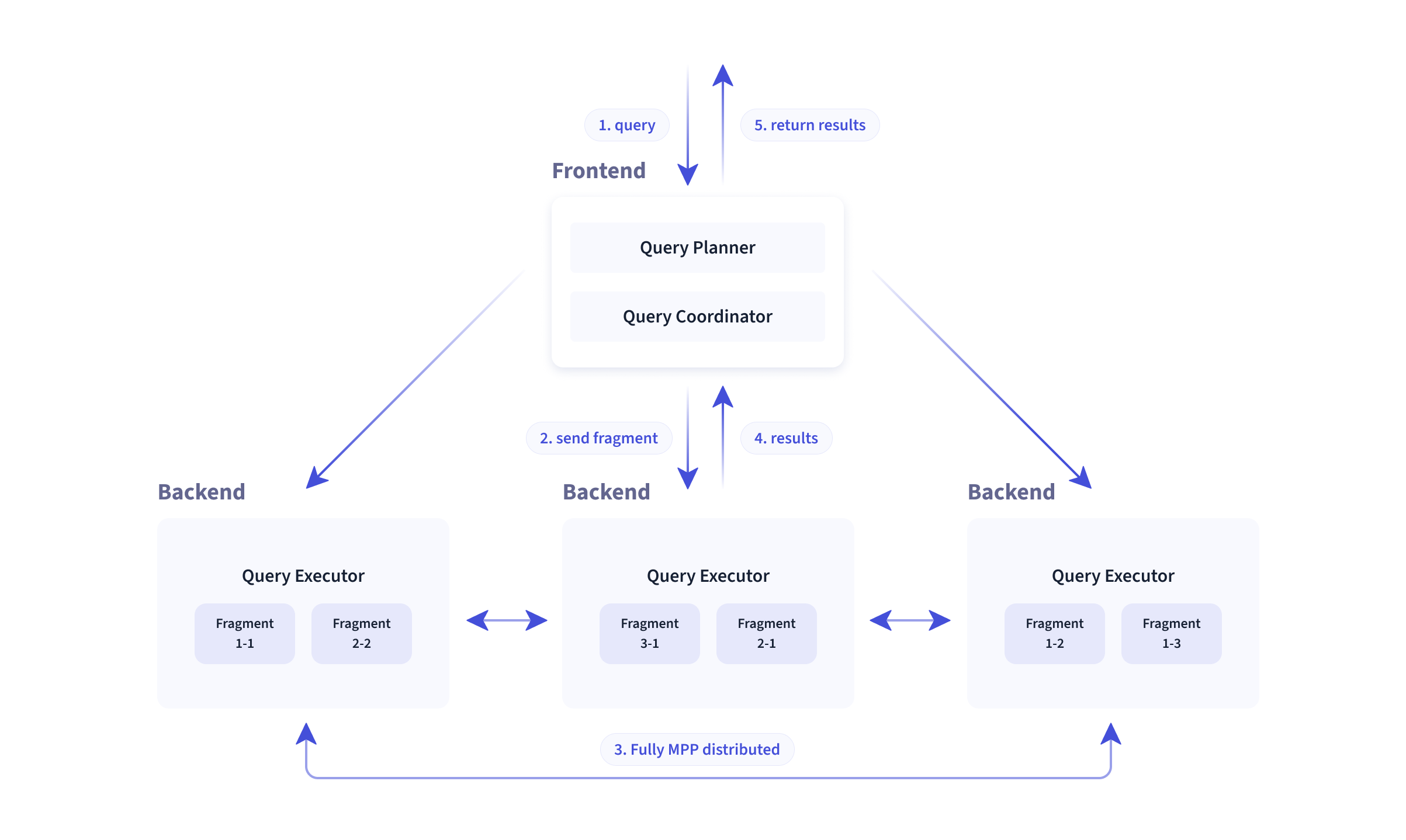
Doris 查询引擎是矢量化的,所有内存结构都以列格式布局。这可以在很大程度上减少虚拟函数调用,提高缓存命中率,并有效利用 SIMD 指令。Doris 在宽表聚合场景中提供的性能是非矢量化引擎的 5-10 倍。
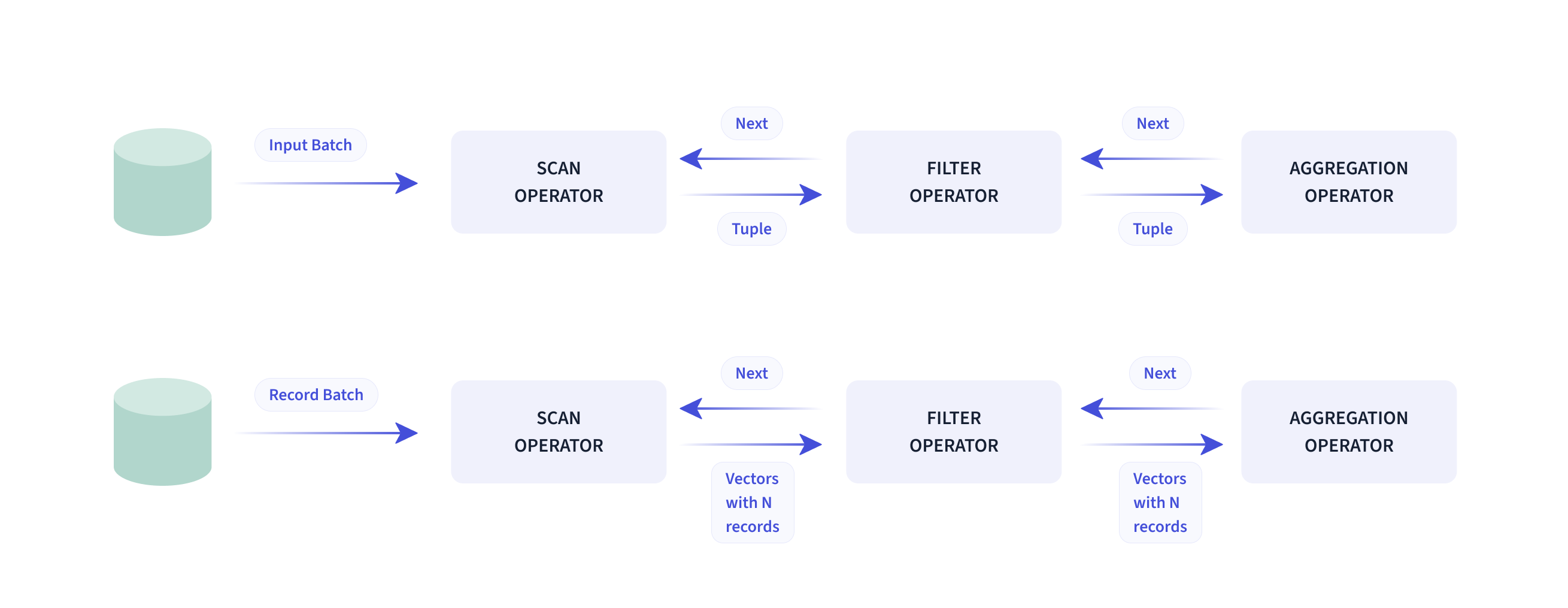
Apache Doris 使用自适应查询执行技术,根据运行时统计信息动态调整执行计划。例如,它可以生成运行时过滤器,将其推送到探测端,并自动渗透到底部的 Scan 节点,从而大大减少探测中的数据量并提高连接性能。Doris 中的运行时过滤器支持 In/Min/Max/Bloom 过滤器。
🚅 查询优化器 在优化器方面,Doris 使用了 CBO 和 RBO 的组合。RBO 支持常量折叠、子查询重写、谓词下推,CBO 支持联接重新排序。Doris CBO正在不断优化,以实现更准确的统计信息收集和推导,以及更准确的成本模型预测。Apache Doris已成功从Apache孵化器毕业,并于2022年<>月成为顶级项目。
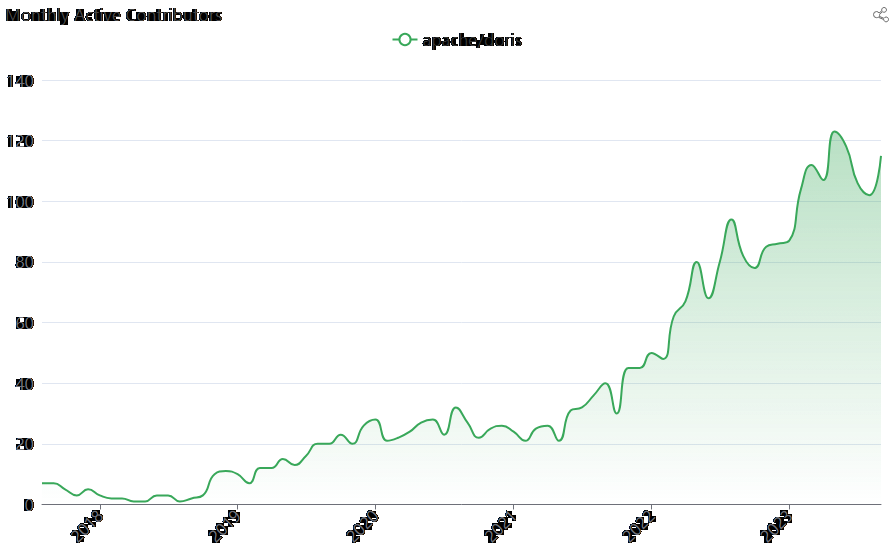
目前,Apache Doris 社区已经聚集了来自不同行业的近 400 家公司的 200 多名贡献者,每月活跃贡献者数量接近 100 人。Apache Doris已成功从Apache孵化器毕业,并于2022年<>月成为顶级项目。
目前,Apache Doris 社区已经聚集了来自不同行业的近 400 家公司的 200 多名贡献者,每月活跃贡献者数量接近 100 人。
总结
Thrift在很多开源项目中已经被验证是稳定和高效的,例如Cassandra、Hadoop、HBase等;国外在Facebook中有广泛使用,国内包括百度、美团小米、和饿了么等公司。
本文由博客一文多发平台 OpenWrite 发布!





![pytest高版本兼容test_data[“log“] = _handle_ansi(“\n“.join(logs))错误](https://i-blog.csdnimg.cn/direct/da4d245509cc4f5596ba4c29d3f50b4a.png)