作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:
这篇论文介绍了StockEmotions数据集,它包含从金融社交媒体平台StockTwits收集的10,000条英文评论,旨在通过识别投资者情绪来进行金融情绪分析和多变量时间序列预测。数据集提出了12种细粒度的情绪类别,并提供了包括投资者情绪类别、表情符号和时间序列数据在内的细粒度特征。实验结果表明,DistilBERT在金融情绪/情感分类任务中表现优异,而结合价格指数、文本和情绪特征的Temporal Attention LSTM模型在多变量时间序列预测中取得了最佳性能。
一、引言
现有数据集在数据量和情绪分析深度上略有不足,比如:多数数据集规模较小,且在训练集中存在空标签的问题。此外,现有研究多使用公众情绪代理来预测股市,而非直接从文本数据中提取情绪信息。为解决这些问题,本文提出了StockEmotions数据集,该数据集包含从StockTwits平台收集的10,000条评论,设计了与投资者情绪波动相关的12种细粒度情绪类别,并提供了包括情绪类别、表情符号和时间序列数据在内的多种特征。这一章节还概述了数据集的潜在应用,包括金融情绪分类和股市时间序列预测,旨在通过更精细的情绪分析增强预测模型的性能。

二、StockEmotions数据集
StockEmotions数据收集自StockTwits平台,涵盖了2020年1月1日至2020年12月31日间的评论,这些评论覆盖了超过80%的S&P 500市值加权公司。为了确保数据的公平代表性并减少用户偏见,每天只选取单一用户的评论,并去除了广告或受损数据。在标记化和长度过滤阶段,限制了序列长度,并选择了长度超过3个标记的评论。掩码处理中,特殊字符如现金标签、话题标签和网址被替换为相应的[CTAG]、[HTAG]、[URL]标记。表情符号在社交媒体中常用于表达情绪,因此章节中特别关注了包含至少一个表情符号的评论,并将表情符号转换为文本含义以便于情绪分析。注释过程采用了预训练语言模型和人类注释者的协作方式,通过多步骤流水线进行情绪标注,并根据反馈更新了情绪分类法。数据质量验证通过人类参与的验证过程来检查数据质量,确保了数据集的准确性和可靠性。

三、数据分析
数据集包含10,000条评论,分为两大类金融情绪:看涨(55%)和看跌(45%),并进一步细分为12种不同的情绪类别。情绪类别的分布不均,乐观、兴奋、焦虑和厌恶情绪较为常见,而恐慌、惊讶和沮丧情绪则较为罕见。此外,用户在市场低迷时期也会分享愿望、希望或成就。情绪相关性分析揭示了某些情绪对在同一情境下出现的倾向,例如乐观与兴奋之间存在强正相关,而愤怒与信念之间存在负相关。表情符号分析显示,某些表情符号在正面和负面情绪中都很常见,表明它们可以表达多种情绪。这些分析结果有助于理解投资者在社交媒体上的情绪表达,并为后续的情绪分类和时间序列预测任务提供了有价值的见解。

四、建模和实验
金融情绪分析:
- 数据集被随机划分为训练集(80%)、验证集(10%)和测试集(10%)。
- 实验中比较了多种基线模型,包括传统的机器学习算法如逻辑回归、朴素贝叶斯SVM,以及基于神经网络的方法如GRU、Bi-GRU。
- 预训练语言模型DistilBERT、BERTbase和RoBERTabase也被纳入对比,以评估其在金融情绪分析任务上的表现。
- 实验结果显示DistilBERT在二分类的金融情绪分类任务上表现最佳,平均F1得分为0.81;在多分类的情绪分类任务上,同样展现了优越的性能,F1得分为0.42。

多变量时间序列预测:
实现了Temporal Attention LSTM模型,该模型利用来自文本、情绪标签和数值数据的时间序列信息,以预测标准普尔500指数。

使用Yahoo财经API获取了股票价格指数数据,并将2020年1月1日至2020年9月3日的数据作为训练集,剩余时间的数据作为测试集。
性能评估采用均方误差(MSE),其中结合价格指数、文本和情绪特征的模型在预测标准普尔500指数时表现最佳,MSE值为0.83×10^-3。
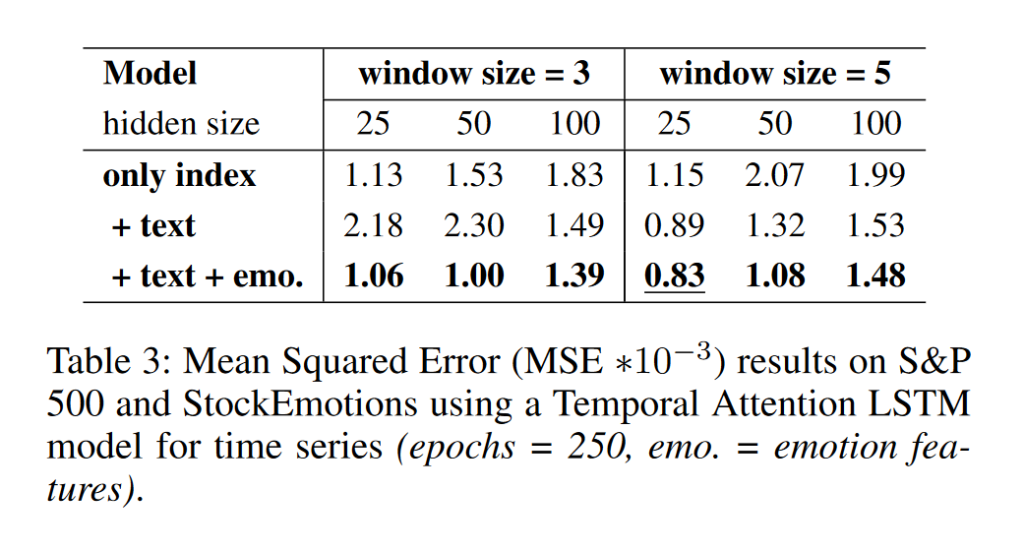
超参数设置包括滚动窗口大小、隐藏层大小和训练周期,通过超参数搜索确定了最优的模型配置。
五、结论
本文总结了StockEmotions数据集的创建和通过一系列下游任务进行的实验,展示了该数据集在金融情绪分类和时间序列预测中的有效性,同时提出了未来研究的方向,包括进一步的细节探索和其他基线模型的比较,以更全面地评估文本和情绪数据在股票市场预测中的影响。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
转发请注明原作者和出处。





