索引优势劣势


索引分类和索引命令语句
单值索引
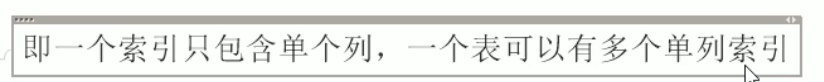
唯一索引
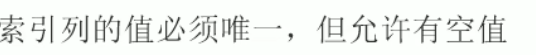
复合索引

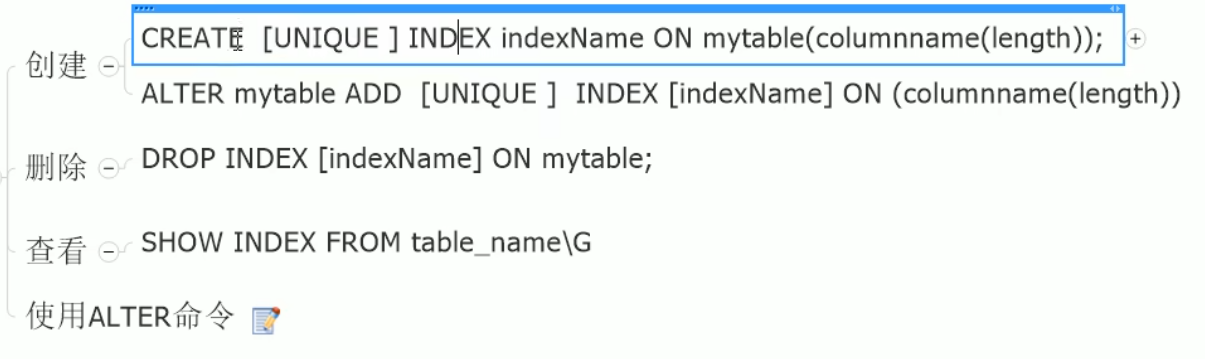
基本语法
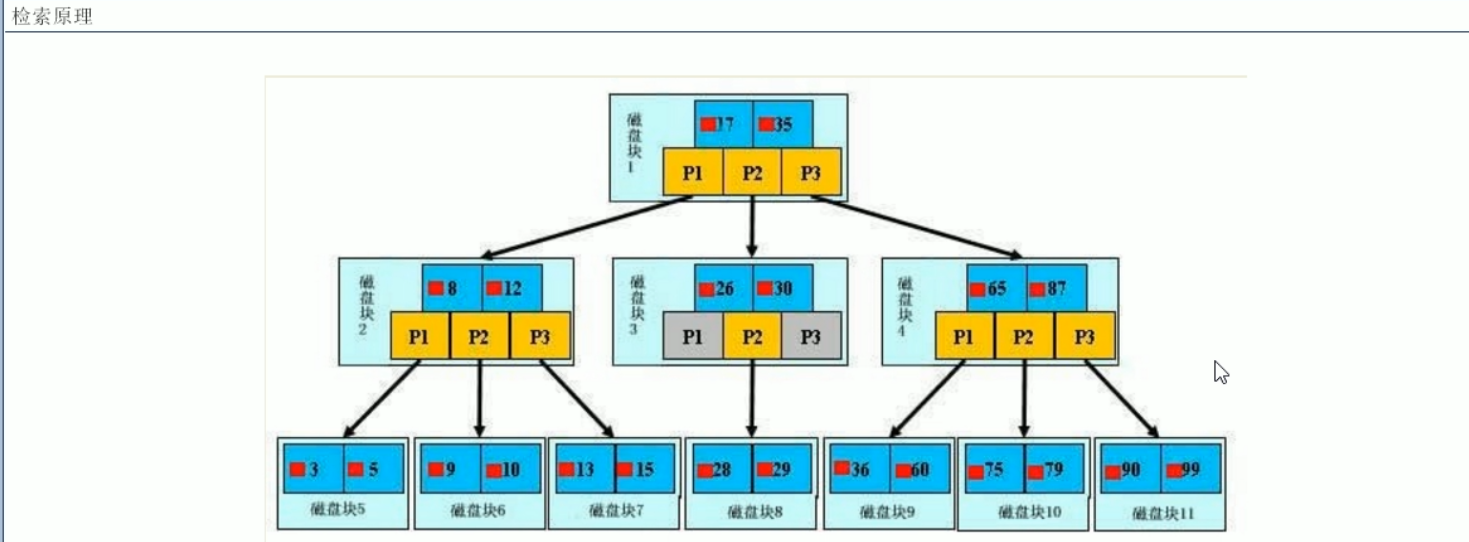
Mysql 索引结构

目前只考虑BTree

那些情况适合建索引

那些情况不适合建索引
性能分析

Explain


字段解释
id->表的加载顺序

第三种情况

衍生表一般存在于from 中存在子查询的情况,子查询结果作为一张临时表
注意 可能为NULL,在涉及UNION操作的时候存在,排在最后
select_type-> 查询的类型 和 table -> 查询的表


type



- system

- const

- eq_ref

- ref

- range

- index

- all

passible_key 和 key

key_len

ref

rows

extra
Using filesort 文件内排序 -> 排序没有索引
Using temnporary 使用了临时表保存中间结果 -> 常见于排序和分组查询
Using index -> 关联覆盖索引

关联覆盖索引的知识

特别注意最下面的两点注意
Using where
Using join buffer
imposible where -> where 里面总是 false
索引优化
单表案例
CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT (10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL ,
`views` INT(10) UNSIGNED NOT NULL ,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);insert into `article`(author_id,category_id,views,comments,title,content) values
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');explain SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
## 没有建以前,all
## 建立索引
CREATE INDEX idx_article_ccv on article(category_id, comments, views);## 存在 filesort 中间的 范围查询,导致后续索引失效
DROP INDEX idx_article_ccv on article;CREATE INDEX idx_article_ccv on article(category_id, views);

双表案例
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
);
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
);insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));
insert into class(card) values(floor(1+(rand()*20)));insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));
insert into book(card) values(floor(1+(rand()*20)));多表查询sql的索引如何建立
左连接前提下,
目标 sql,两个都是 ALL
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

加在右表上
ALTER TABLE `book` ADD INDEX Y (`card`);

ref
加在左表上
DROP INDEX Y on book;
ALTER TABLE `class` ADD INDEX Y (`card`);

index
左连接,加右表
理解:左边所有数据都会被检索到,关键是为了加速匹配右表的数据
三表案例
添加一张 phone 表
CREATE TABLE IF NOT EXISTS `phone`(`phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,`card` INT (10) UNSIGNED NOT NULL
)ENGINE = INNODB;insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
insert into phone(card) values(floor(1+(rand()*20)));
案例sql
DROP INDEX Y on class;
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;

右边建立索引
ALTER TABLE phone ADD INDEX z (`card`);
ALTER TABLE book ADD INDEX mylock (`card`);

总结

索引失效
2.最佳左前缀

带头大哥不能死,中间兄弟不能断
case
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';insert into staffs(NAME,age,pos,add_time) values('z3',22,'manager',NOW());
insert into staffs(NAME,age,pos,add_time) values('July',23,'dev',NOW());
insert into staffs(NAME,age,pos,add_time) values('2000',23,'dev',NOW());
添加索引
ALTER TABLE staffs ADD INDEX idx_staffs_nap(name, age, pos);
SHOW INDEX FROM staffs;
我们看如果查询
-- 正常
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July';
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July' AND age = 25;
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July' AND age = 25 AND pos = 'dev';EXPLAIN SELECT * FROM staffs WHERE age = 25 AND pos = 'dev'; -- 无法使用索引
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July' AND pos = 'dev'; -- 只能利用部分索引 name
3.不在索引上做任何操作
-- 索引上计算
EXPLAIN SELECT * FROM staffs WHERE LEFT(name, 4) = 'July'; -- all
EXPLAIN SELECT * FROM staffs WHERE name = 'July';
4.不能使用索引中范围条件右边的列
name age
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July' AND age = 25 AND pos = 'dev';
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July' AND age > 25 AND pos = 'dev'; -- range
5.尽量使用覆盖索引
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July' AND age = 25 AND pos = 'dev';
EXPLAIN SELECT `name`, age, pos FROM staffs WHERE `name` = 'July' AND age = 25 AND pos = 'dev'; -- using index
6.不等于无法使用索引
EXPLAIN SELECT * FROM staffs WHERE `name` = 'July';
EXPLAIN SELECT * FROM staffs WHERE `name` <> 'July'; -- range
7.is null is not null 也无法使用索引
EXPLAIN SELECT * FROM staffs WHERE `name` is NULL; -- NULL
EXPLAIN SELECT * FROM staffs WHERE `name` is not NULL; -- ALL
8.like 通配符开头
EXPLAIN SELECT * FROM staffs WHERE `name` like '%July%'; -- ALL
EXPLAIN SELECT * FROM staffs WHERE `name` like '%July'; -- ALL
EXPLAIN SELECT * FROM staffs WHERE `name` like 'July%'; -- range
可以用覆盖索引来解决,可以达到 index,不需要回表
回表->先根据普通索引确定位置id,再去主键索引找数据
9.字符串不加单引号
EXPLAIN SELECT * FROM staffs WHERE name = 2000; -- ALL
10.OR
EXPLAIN SELECT * FROM staffs WHERE name = 'zhangsan' or name='lisi'; -- range
面试题及其他
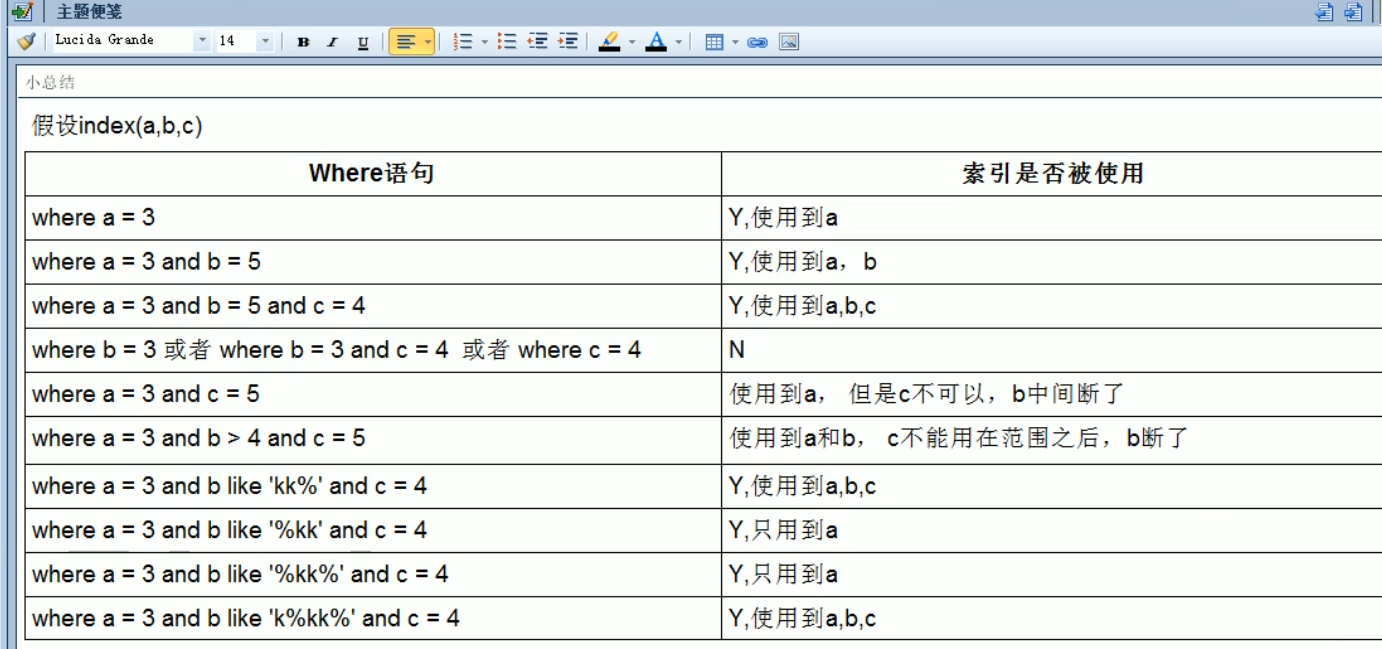
解释最后 k%kk% 这种情况,因为 k 开头,所以mysql可以先过滤k开头的数据,后续在内存中再去过滤满足 %kk% 的数据
口诀
全职匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
Like 百分写最右,覆盖索引不写*;
不等空值还有 OR,索引影响要注意;
VAR 引号不可丢,SQL 优化有诀窍
in 与 exist


EXISTS操作符用于检查子查询是否返回任何行。如果子查询返回至少一行,则EXISTS返回true。
IN 和 EXISTS 的比较
性能: 对于大型数据集,EXISTS通常比IN更快,因为EXISTS可以在找到第一个匹配项后就停止搜索。
结果: IN比较的是实际的值,而EXISTS只检查是否存在匹配项。
NULL处理: IN对NULL值的处理可能会导致意外结果,而EXISTS不受此影响。
可读性: IN通常更易读,特别是对于简单的查询。
order by 优化
原理部分

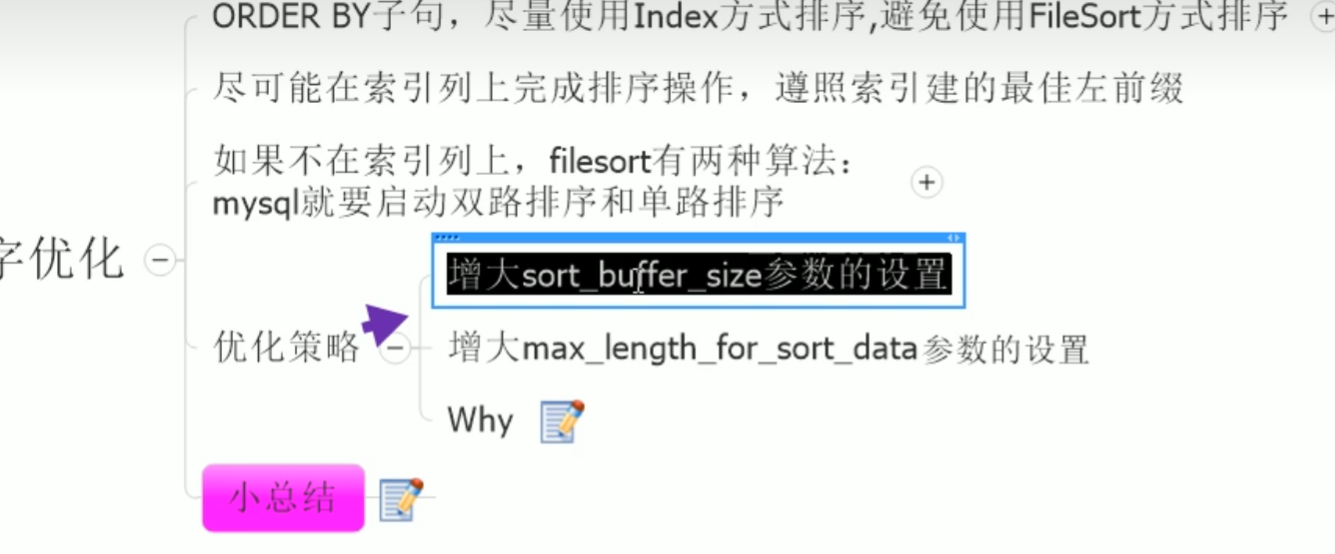

规则总结

group by

慢查询日志分析

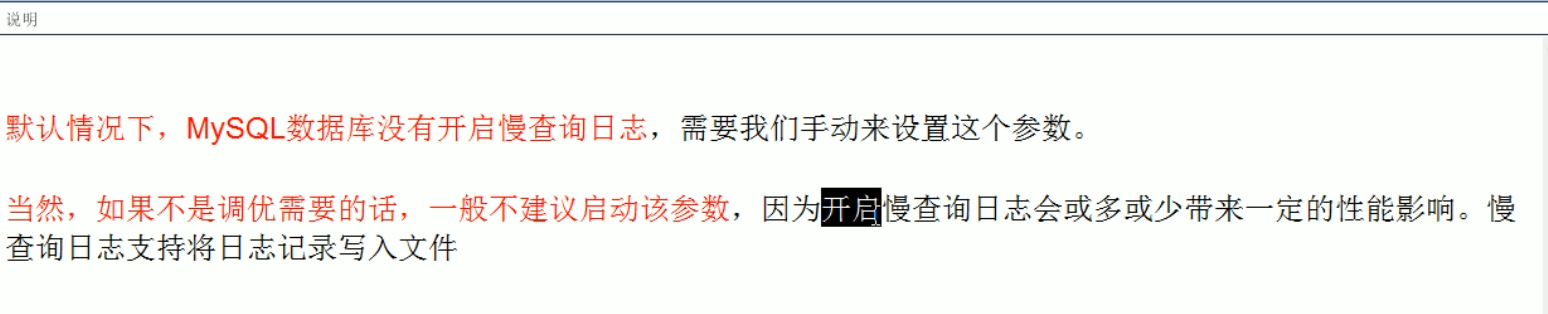

set global slow_query_log=1;
show variables like ‘%slow_query_log%’;
开启慢查询日志后,什么样的sql会被记录到慢查询日志里面
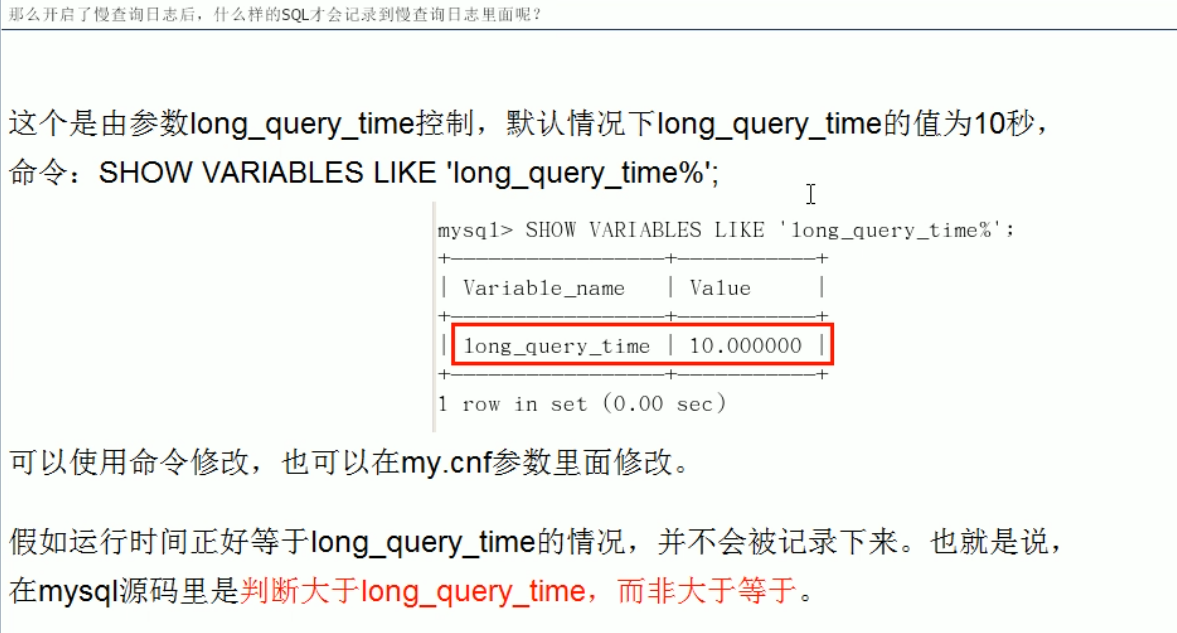
show variables like ‘%long_query_time%’;
设置后看不到变化需要重新连接或者新开一个会话
测试 sql
select sleep(11);# User@Host: root[root] @ [192.168.139.2] Id: 40
# Query_time: 11.000906 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
SET timestamp=1727535466;
select sleep(11);





