案例背景
时间序列的预测一直是经久不衰的实际应用和学术研究的对象,但是绝大多数的时间序列可能就没有太多的其他的变量,例如一个股票的股价,还有一个企业的用电量,人的血糖浓度等等,空气的质量,温度这些,有时候你拿到这个数据只有一条数据,它只有一个维度,它没有别的变量,所以就很难会让你能做出一些特征衍生等方法去让你的数据效果变得更好。
但是我最近发现了这样一个包tsfresh,它可以自己从时间训练里面自动提取特征,它会计算特别多的信号学和各种统计学的一些关于时间序列的指标,从而可以作为特征进行入模应用。还是非常好用的,本次案例就来演示一下这个包到底怎么用一个风电的数据去进行预测。
首先用这个包进行特征的扩展,然后再用常用的这些神经网络 MLP,LSTM,GRU,Attention-LSTM,BiLSTM,BiGRU,Attention-GRU 去进行预测评价。
参考文章:时间序列 工具库学习(1) tsfresh特征提取、特征选择-CSDN博客
官方文档:https://tsfresh.readthedocs.io/en/latest/text/introduction.html
学习了这两个资料之后,就写了这样一个案例,方便自己以后用得上万一可以复用。
需要本次案例的全部代码文件和数据的可以参考:扩展风电预测
代码实现
先导入包
python">import os
import math
import time
import datetime
import random as rn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,StandardScaler
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_scoreimport tensorflow as tf
import keras
from keras.layers import Layer
import keras.backend as K
from keras.models import Model, Sequential
from keras.layers import GRU, Dense,Conv1D, MaxPooling1D,GlobalMaxPooling1D,Embedding,Dropout,Flatten,SimpleRNN,LSTM,Bidirectional
from keras.callbacks import EarlyStopping
#from tensorflow.keras import regularizers
#from keras.utils.np_utils import to_categorical
from tensorflow.keras import optimizers读取数据
python">data0 = pd.read_excel('WindForecast_20240801-20240816.xls',usecols=['DateTime', 'Measured & upscaled [MW]'],skiprows=5)
data0['DateTime'] = pd.to_datetime(data0['DateTime'], format='%d/%m/%Y %H:%M')
data0=data0.set_index('DateTime').fillna(data0.mean(numeric_only=True)).rename(columns={'Measured & upscaled [MW]':'power'})
data0.head()
python">data0=data0.reset_index('DateTime')
data0['id']=range(len(data0))
data0.head()
提取特征
python">from tsfresh import extract_features
extracted_features = extract_features(data0, column_id="id", column_sort="DateTime")python">from tsfresh.feature_extraction import ComprehensiveFCParameters
from tsfresh.utilities.dataframe_functions import impute
extraction_settings = ComprehensiveFCParameters()
X = extract_features(data0, column_id='id', column_sort='DateTime',default_fc_parameters=extraction_settings,# impute就是自动移除所有NaN的特征impute_function=impute)
X.head()
可以看到1列数据变成了738列数据。很多特征。
我们和原来的数据合并
python">data1=pd.concat([data0.drop(columns='id'),X],axis=1).set_index('DateTime')
data1=data1[data1.columns[1:].to_list()+['power']]
data1.head()
进行一定的清洗
python">#取值唯一的变量删除
for col in data1.columns:if len(data1[col].value_counts())==1:print(col)data1.drop(col,axis=1,inplace=True)查看剩下的数据信息
python">data1.info()
可以看到最后有24列数据,我们一列特征变成了24列,还是很多的。数据准备好了,我们下面就用这些新构件的特征来进行神经网络的预测。
后面都是老一套的时间序列预测的标准流程了,我之前的文章都做烂了,可以看我之前文章的解释,这里就不过多的解释了。
构建训练集和测试集¶
python">def build_sequences(text, window_size=24):#text:list of capacityx, y = [],[]for i in range(len(text) - window_size):sequence = text[i:i+window_size]target = text[i+window_size]x.append(sequence)y.append(target)return np.array(x), np.array(y)def get_traintest(data,train_ratio=0.8,window_size=24):train_size=int(len(data)*train_ratio)train=data[:train_size]test=data[train_size-window_size:]X_train,y_train=build_sequences(train,window_size=window_size)X_test,y_test=build_sequences(test,window_size=window_size)return X_train,y_train[:,-1],X_test,y_test[:,-1]标准化
python">data=data1.to_numpy()
scaler = MinMaxScaler()
scaler = scaler.fit(data[:,:-1])
X=scaler.transform(data[:,:-1]) y_scaler = MinMaxScaler()
y_scaler = y_scaler.fit(data[:,-1].reshape(-1,1))
y=y_scaler.transform(data[:,-1].reshape(-1,1))划分训练集和测试集。
划分训练集和测试集。train_ratio=0.8 #训练集比例 window_size=64 #滑动窗口大小,即循环神经网络的时间步长
python">train_ratio=0.8 #训练集比例
window_size=64 #滑动窗口大小,即循环神经网络的时间步长
X_train,y_train,X_test,y_test=get_traintest(np.c_[X,y],window_size=window_size,train_ratio=train_ratio)
print(X_train.shape,y_train.shape,X_test.shape,y_test.shape)可视化
python">y_test = y_scaler.inverse_transform(y_test.reshape(-1,1))
test_size=int(len(data)*(1-train_ratio))
plt.figure(figsize=(10,5),dpi=256)
plt.plot(data1.index[:-test_size],data1.iloc[:,-1].iloc[:-test_size],label='Train',color='#FA9905')
plt.plot(data1.index[-test_size:],data1.iloc[:,-1].iloc[-(test_size):],label='Test',color='#FB8498',linestyle='dashed')
plt.legend()
plt.ylabel('Predict Series',fontsize=16)
plt.xlabel('Time',fontsize=16)
plt.show()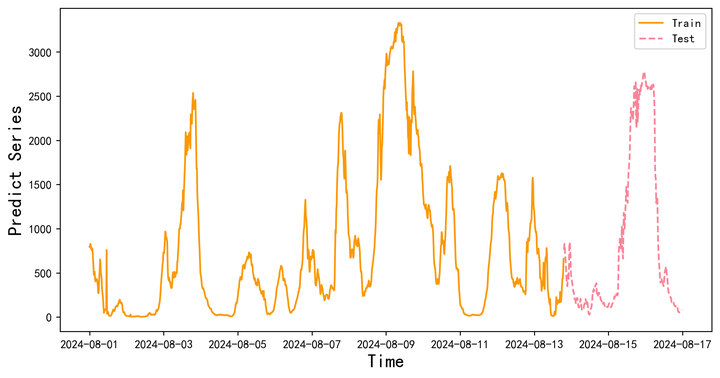
定义评价指标函数
python">def set_my_seed():os.environ['PYTHONHASHSEED'] = '0'np.random.seed(1)rn.seed(12345)tf.random.set_seed(123)def evaluation(y_test, y_predict):mae = mean_absolute_error(y_test, y_predict)mse = mean_squared_error(y_test, y_predict)rmse = np.sqrt(mean_squared_error(y_test, y_predict))mape=(abs(y_predict -y_test)/ y_test).mean()#r_2=r2_score(y_test, y_predict)return mse, rmse, mae, mape #r_2注意力层
python">class AttentionLayer(Layer): #自定义注意力层def __init__(self, **kwargs):super(AttentionLayer, self).__init__(**kwargs)def build(self, input_shape):self.W = self.add_weight(name='attention_weight',shape=(input_shape[-1], input_shape[-1]),initializer='random_normal',trainable=True)self.b = self.add_weight(name='attention_bias',shape=(input_shape[1], input_shape[-1]),initializer='zeros',trainable=True)super(AttentionLayer, self).build(input_shape)def call(self, x):# Applying a simpler attention mechanisme = K.tanh(K.dot(x, self.W) + self.b)a = K.softmax(e, axis=1)output = x * areturn outputdef compute_output_shape(self, input_shape):return input_shape定义模型们,MLP,LSTM,GRU,Attention-LSTM,BiLSTM,BiGRU,Attention-GRU
python">def build_model(X_train,mode='LSTM',hidden_dim=[32,16]):set_my_seed()model = Sequential()if mode=='MLP':model.add(Dense(hidden_dim[0],activation='relu',input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(Flatten())model.add(Dense(hidden_dim[1],activation='relu'))elif mode=='LSTM':# LSTMmodel.add(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(LSTM(hidden_dim[1]))elif mode=='GRU':#GRUmodel.add(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1])))model.add(GRU(hidden_dim[1]))elif mode == 'Attention-LSTM':model.add(LSTM(hidden_dim[0], return_sequences=True, input_shape=(X_train.shape[-2], X_train.shape[-1])))model.add(AttentionLayer())model.add(LSTM(hidden_dim[1]))#, return_sequences=False#model.add(Dense(hidden_dim[2], activation='relu'))elif mode=='BiLSTM':model = Sequential()model.add(Bidirectional(LSTM(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1]))))#model.add(Dropout(0.2))model.add(Bidirectional(LSTM(hidden_dim[1])))#model.add(Dropout(0.2))model.add(Dense(1))elif mode=='BiGRU':model = Sequential()model.add(Bidirectional(GRU(hidden_dim[0],return_sequences=True, input_shape=(X_train.shape[-2],X_train.shape[-1]))))#model.add(Dropout(0.2))model.add(Bidirectional(GRU(hidden_dim[1])))#model.add(Dropout(0.2))model.add(Dense(1))elif mode == 'Attention-GRU':model.add(GRU(hidden_dim[0], return_sequences=True, input_shape=(X_train.shape[-2], X_train.shape[-1])))model.add(AttentionLayer())model.add(GRU(hidden_dim[1]))#, return_sequences=Falseelse:print('模型名称输入错误')model.add(Dense(1))model.compile(optimizer='Adam', loss='mse',metrics=[tf.keras.metrics.RootMeanSquaredError(),"mape","mae"])return model
画图函数
python">def plot_loss(hist,imfname=''):plt.subplots(1,4,figsize=(16,2))for i,key in enumerate(hist.history.keys()):n=int(str('14')+str(i+1))plt.subplot(n)plt.plot(hist.history[key], 'k', label=f'Training {key}')plt.title(f'{imfname} Training {key}')plt.xlabel('Epochs')plt.ylabel(key)plt.legend()plt.tight_layout()plt.show()
def plot_fit(y_test, y_pred):plt.figure(figsize=(4,2))plt.plot(y_test, color="red", label="actual")plt.plot(y_pred, color="blue", label="predict")plt.title(f"拟合值和真实值对比")plt.xlabel("Time")plt.ylabel('power')plt.legend()plt.show()自定义训练函数
python">df_eval_all=pd.DataFrame(columns=['MSE','RMSE','MAE','MAPE']) ; df_preds_all=pd.DataFrame()
def train_fuc(mode='LSTM',batch_size=64,epochs=30,hidden_dim=[32,16],verbose=0,show_loss=True,show_fit=True):#构建模型s = time.time() ; set_my_seed()model=build_model(X_train=X_train,mode=mode,hidden_dim=hidden_dim)earlystop = EarlyStopping(monitor='loss', min_delta=0, patience=5)hist=model.fit(X_train, y_train,batch_size=batch_size,epochs=epochs,callbacks=[earlystop],verbose=verbose)if show_loss:plot_loss(hist)#预测y_pred = model.predict(X_test)y_pred = y_scaler.inverse_transform(y_pred)#print(f'真实y的形状:{y_test.shape},预测y的形状:{y_pred.shape}')if show_fit:plot_fit(y_test, y_pred)e=time.time()print(f"运行时间为{round(e-s,3)}")df_preds_all[mode]=y_pred.reshape(-1,)s=list(evaluation(y_test, y_pred))df_eval_all.loc[f'{mode}',:]=s ; s=[round(i,3) for i in s]print(f'{mode}的预测效果为:MSE:{s[0]},RMSE:{s[1]},MAE:{s[2]},MAPE:{s[3]}')print("=======================================运行结束==========================================")return s[0]参数初始化
python">window_size=64
batch_size=64
epochs=30
hidden_dim=[32,16]verbose=0
show_fit=True
show_loss=True
mode='LSTM' #MLP,GRUMLP网络训练和评估
python">train_fuc(mode='MLP',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)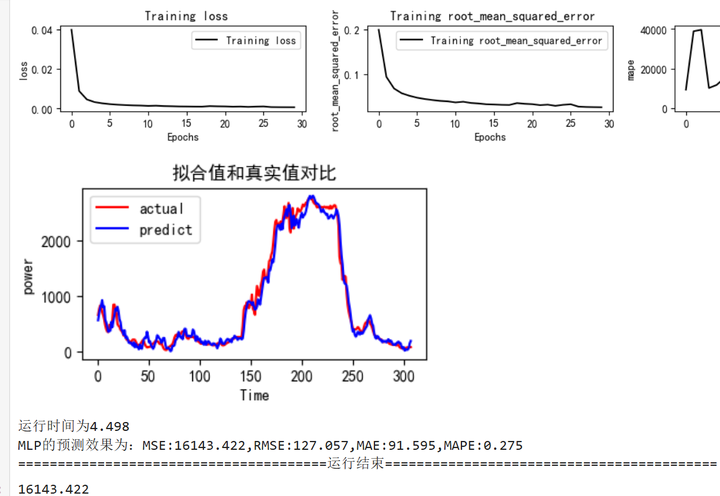
GRU网络训练和评估
python">train_fuc(mode='GRU',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)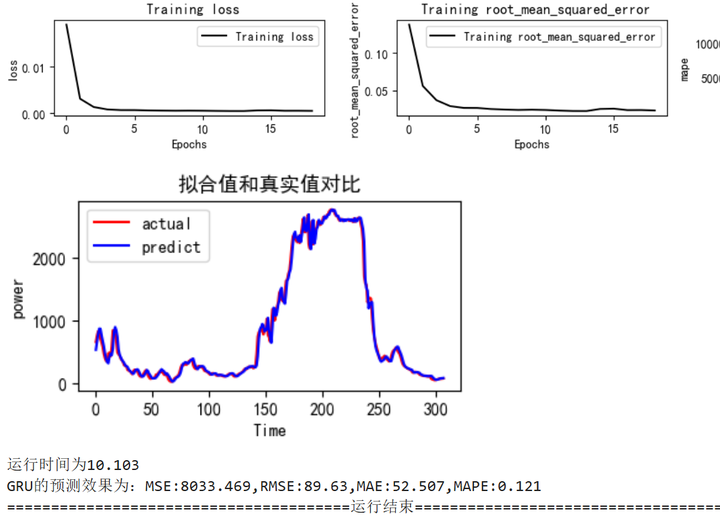
LSTM网络训练和评估
python">train_fuc(mode='LSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim,verbose=1)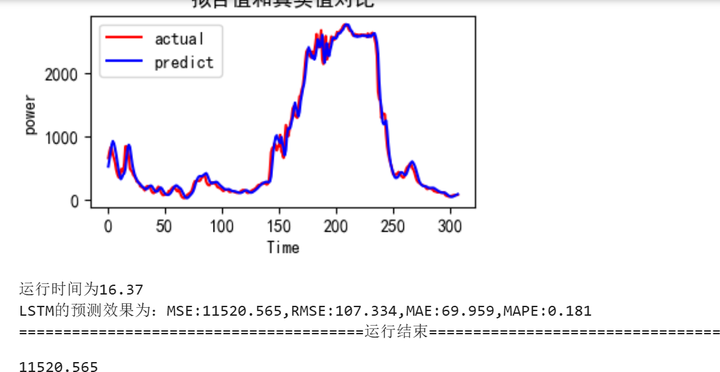
python">train_fuc(mode='Attention-LSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)Attention-LSTM网络训练和评估
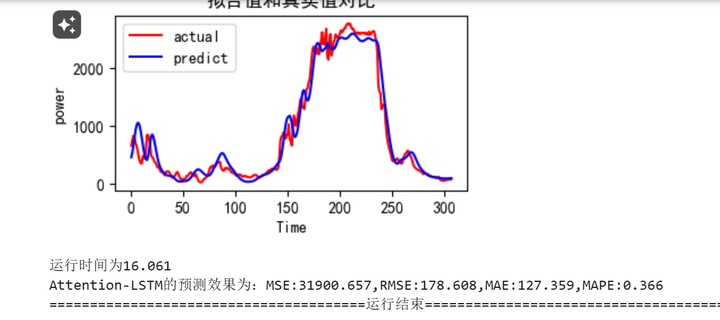
BiLSTM网络训练和评估
python">train_fuc(mode='BiLSTM',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)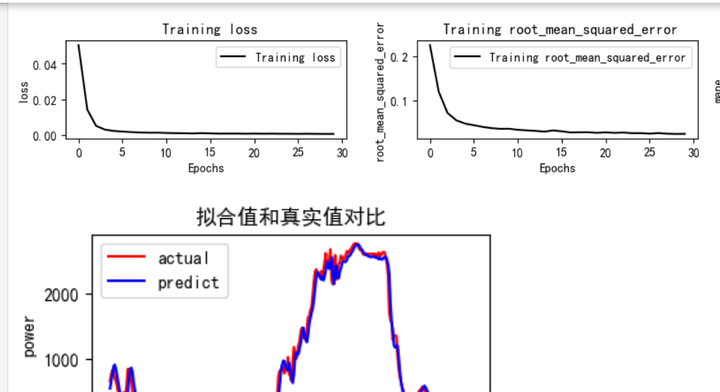
BiGRU网络训练和评估
python">train_fuc(mode='BiGRU',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)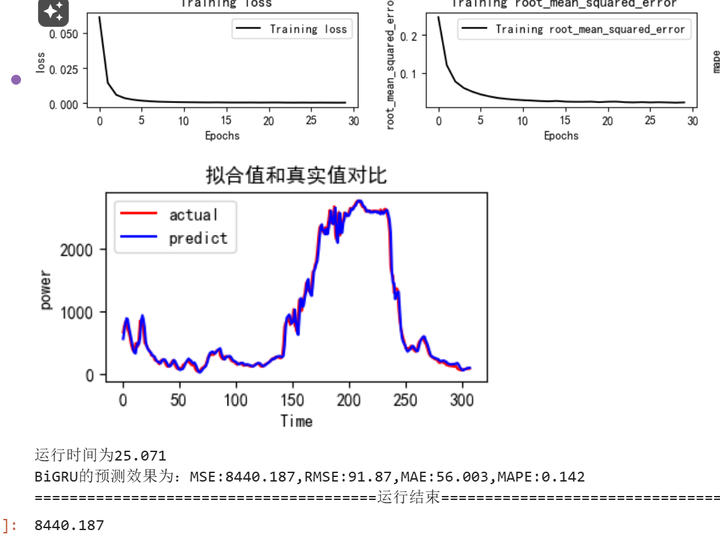
Attention-BiGRU网络训练和评估
python">train_fuc(mode='Attention-GRU',batch_size=batch_size,epochs=epochs,hidden_dim=hidden_dim)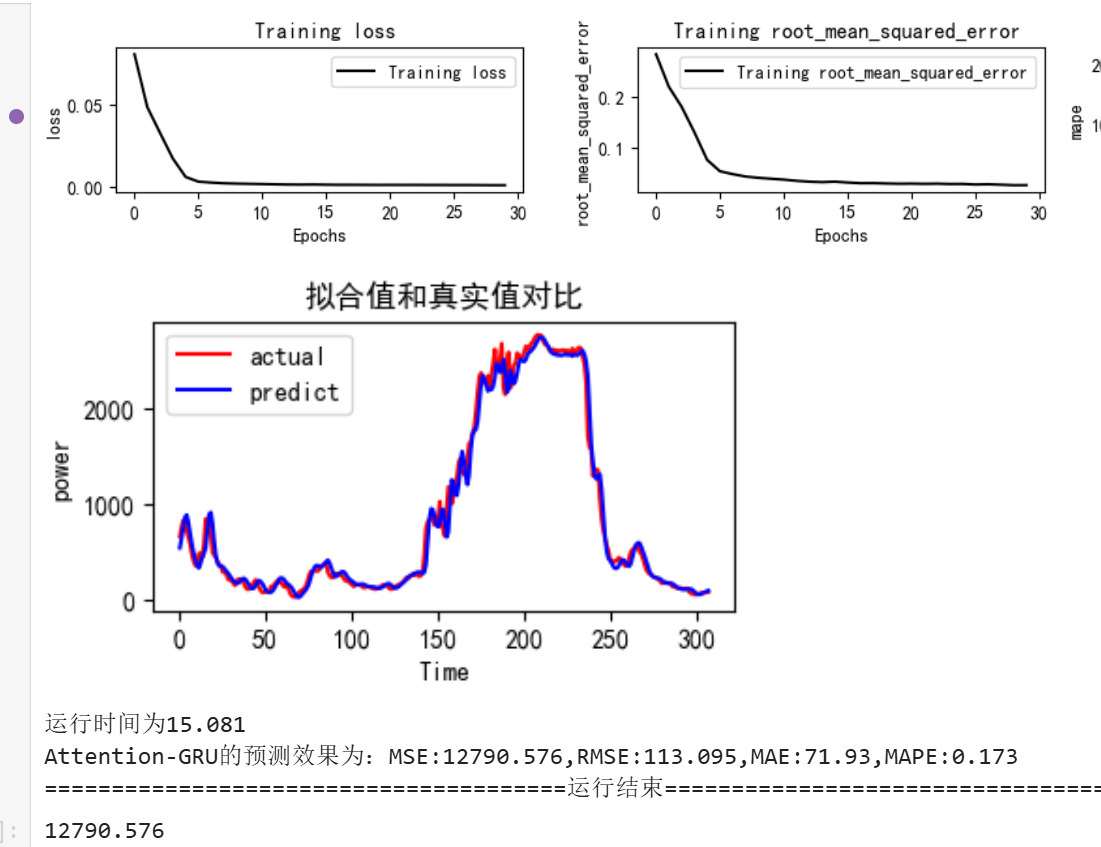
添加图片注释,不超过 140 字(可选)
查看评价指标
python">df_eval_all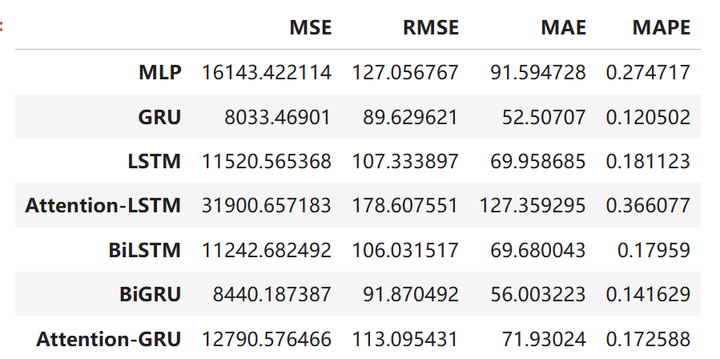
python">bar_width = 0.4
colors=['c', 'orange','g', 'tomato','b', 'm', 'y', 'lime', 'k','orange','pink','grey','tan']
fig, ax = plt.subplots(2,2,figsize=(8,6),dpi=128)
for i,col in enumerate(df_eval_all.columns):n=int(str('22')+str(i+1))plt.subplot(n)df_col=df_eval_all[col]m =np.arange(len(df_col))plt.bar(x=m,height=df_col.to_numpy(),width=bar_width,color=colors)##plt.xlabel('Methods',fontsize=12)names=df_col.indexplt.xticks(range(len(df_col)),names,fontsize=10)plt.xticks(rotation=40)plt.ylabel(col,fontsize=14)plt.tight_layout()
#plt.savefig('柱状图.jpg',dpi=512)
plt.show()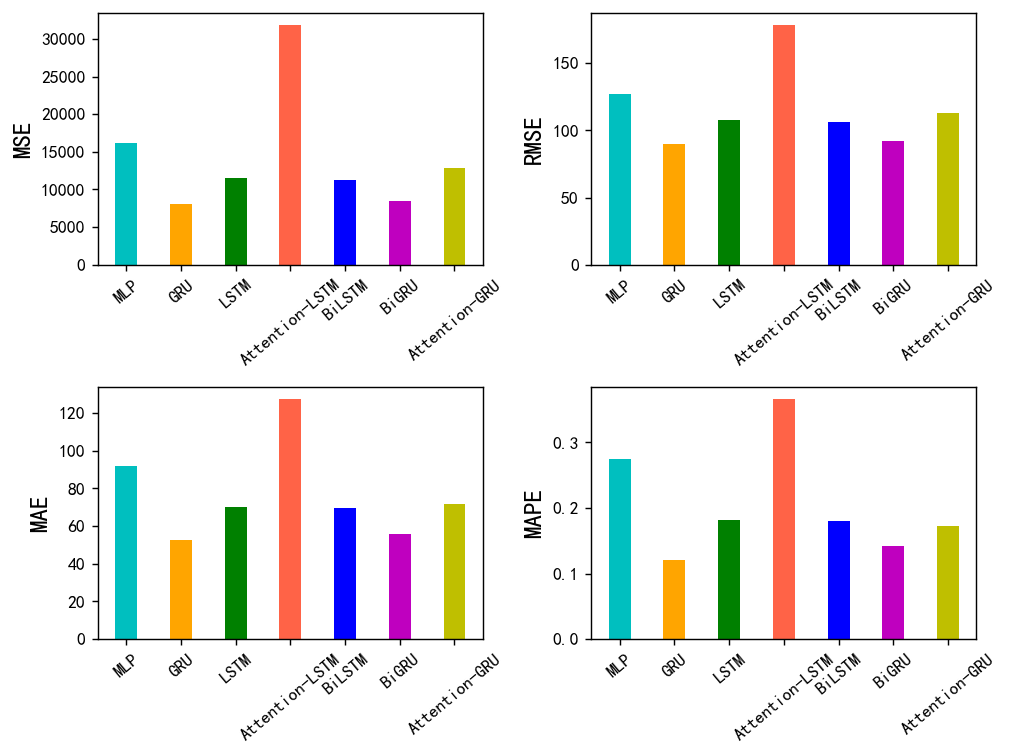
从图中来看,我们可以看到gru效果是最好的,没错,就是单纯的gre效果是最好的,什么双向加注意力机制效果反而不太行。
预测效果对比图
python">plt.figure(figsize=(10,5),dpi=256)
for i,col in enumerate(df_preds_all.columns):plt.plot(data0.index[-test_size-1:],df_preds_all[col],label=col) # ,color=colors[i]plt.plot(data0.index[-test_size-1:],y_test.reshape(-1,),label='Actual',color='k',linestyle=':',lw=2)
plt.legend()
plt.ylabel('price',fontsize=16)
plt.xlabel('Date',fontsize=16)
#plt.savefig('点估计线对比.jpg',dpi=256)
plt.show()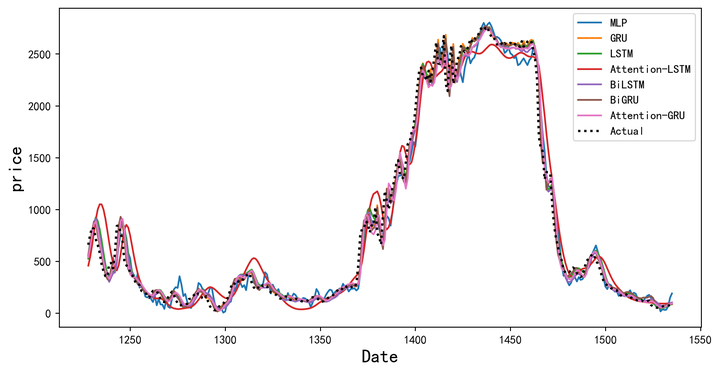
添加图片注释,不超过 140 字(可选)
和评价指标的结果是类似的,从图中可以清晰看到哪些模型的效果比较好
既然是多变量,那么我们一定要看看和之前单变量对比的话效果有没有明显的差异。
python">single_variable = {'Model': ['MLP', 'GRU', 'LSTM', 'Attention-LSTM', 'BiLSTM', 'BiGRU', 'Attention-GRU'],'MSE': [13391.117013, 7787.710462, 14987.005538, 41655.808128, 14940.871448, 8875.492952, 12071.320539],'RMSE': [115.719994, 88.248005, 122.421426, 202.747103, 122.232857, 94.209835, 109.869561],'MAE': [79.247952, 50.933237, 90.344893, 151.622649, 81.812389, 59.858434, 69.763854],'MAPE': [0.20909, 0.115656, 0.275094, 0.383146, 0.20456, 0.165368, 0.168126]
}multi_variable = {'Model': ['MLP', 'GRU', 'LSTM', 'Attention-LSTM', 'BiLSTM', 'BiGRU', 'Attention-GRU'],'MSE': [16143.422114, 8033.46901, 11520.565368, 31900.657183, 11242.682492, 8440.187387, 12790.576466],'RMSE': [127.056767, 89.629621, 107.333897, 178.607551, 106.031517, 91.870492, 113.095431],'MAE': [91.594728, 52.50707, 69.958685, 127.359295, 69.680043, 56.003223, 71.93024],'MAPE': [0.274717, 0.120502, 0.181123, 0.366077, 0.17959, 0.141629, 0.172588]
}# 转换为DataFrame
df_single = pd.DataFrame(single_variable)
df_multi = pd.DataFrame(multi_variable)# 创建子图
metrics = ['MSE', 'RMSE', 'MAE', 'MAPE']
bar_width = 0.4
colors = ['c', 'orange', 'g', 'tomato', 'b', 'm', 'y', 'lime', 'k', 'orange', 'pink', 'grey', 'tan']
x = np.arange(len(df_single['Model']))fig, ax = plt.subplots(2, 2, figsize=(12, 10), dpi=128)for i, metric in enumerate(metrics):ax_ = ax[i//2, i%2]ax_.bar(x - bar_width/2, df_single[metric], width=bar_width, label='Single Variable', color='skyblue')ax_.bar(x + bar_width/2, df_multi[metric], width=bar_width, label='Multi Variable', color='tomato')ax_.set_title(metric)ax_.set_xticks(x)ax_.set_xticklabels(df_single['Model'], rotation=40, ha='right')ax_.legend()plt.tight_layout()
plt.show()我这里直接把单变量跑的结果用数据直接放进去了,就不再放代码了,流程是类似的,我们直接看图就可以发现。:
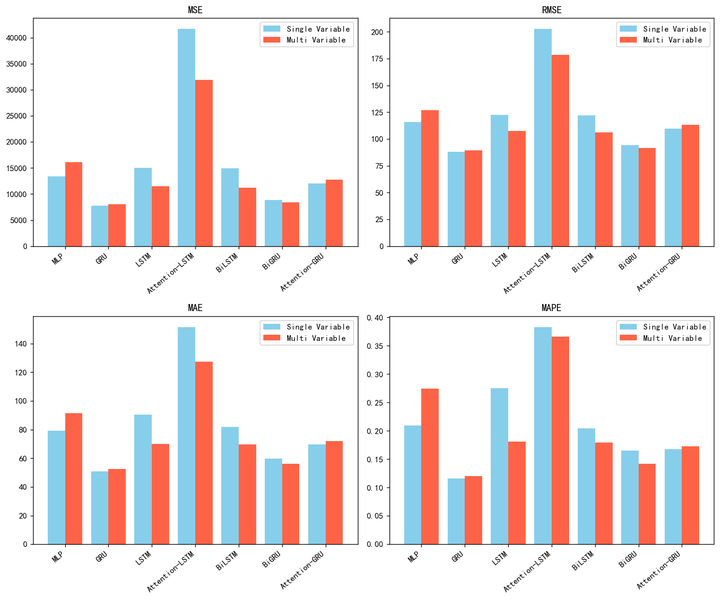
我们可以看到单变量在绝大多数情况下比多变量误差是要高一些的,但是在某些情况下,用上面那个包进行了扩展特征多变量进行预测的之后的效果反而还不如单变量的。所以两种方法有好有坏吧。。
如果效果是差不多的情况下,我也不是很建议使用,毕竟这些特征可能不能进行业务上的一些解释和含义。而且训练成本也会增加。
这只是为了时间序列特征衍生从而达到更好的效果而提供了一种可能。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)





