之前开发的系统,用到了RabbitMQ和SQL Server作为总线服务的传输层和存储层,最近一直在看Kafka和PostgreSql相关的知识,想着是不是可以把服务总线的技术栈切换到这个上面。今天花了点时间试了试,过程还是比较顺利的,后续就是搭建基础服务的事情了。这里简单分享一下。
环境安装
安装Kafka
官方文档:Apache Kafka,可以直接参考,我这里简单介绍下我在本地搭建开发环境的过程,还是遇到了一个小坑。
我这里是在本地WSL 2环境下进行的安装,安装过程就参考官方文档的推荐流程即可
下载安装包
注意,这里要下载编译后的包,不嫌麻烦的话,可以下载源代码,编译后再使用。
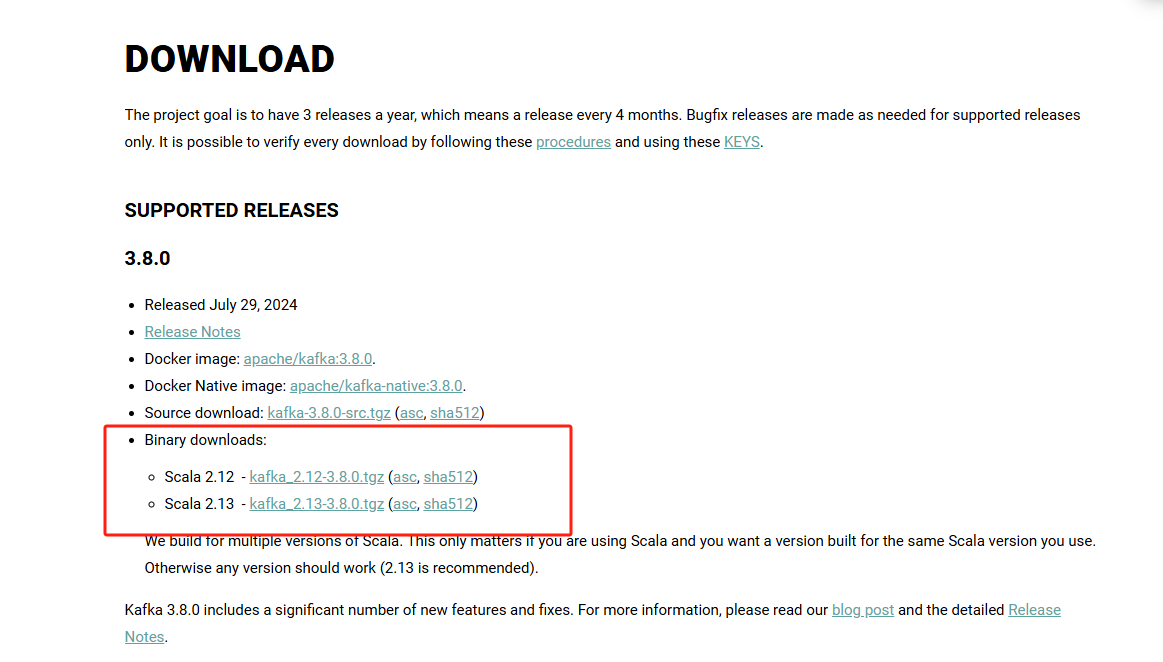
wget -c https://downloads.apache.org/kafka/3.8.0/kafka_2.12-3.8.0.tgz安装
tar -xzf kafka_2.13-3.8.0.tgz
cd kafka_2.13-3.8.0这里安装完成后的路径是这样子的
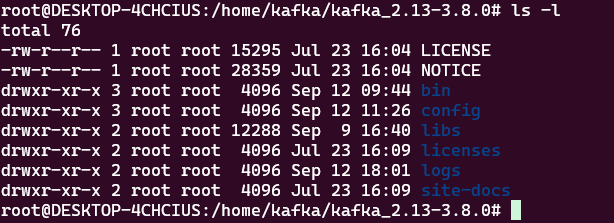
重点关注的就是bin,config和logs这3个目录。
启动服务
官方提供了2中启动策略,一个是KRaft,一个是Zookeeper,我这里用的zookeeper
先启动zookeeper服务
bin/zookeeper-server-start.sh config/zookeeper.properties在启动kafka服务
bin/kafka-server-start.sh config/server.properties后面的zookeeper.properties和server.properties是配置文件,后续有配置需求的时候可以修改,比如监听地址,brokerid等等,长这样👇
启动后控制台的输出是这样
这样,一个kafka的服务节点就启动了。
对了,kafka是依赖java环境的,安装之前本地要安装jdk,我这里使用的是openjdk,也是ok的。
*端口转发(仅WSL2环境)
在WSL2环境下,需要配置下端口转发,不然宿主机连接不到broker,
netsh interface portproxy add v4tov4 listenport=9092 listenaddress=0.0.0.0 connectport=9092 connectaddress=172.28.240.79后面那个ip地址就写宿主机给WSL环境下发的地址
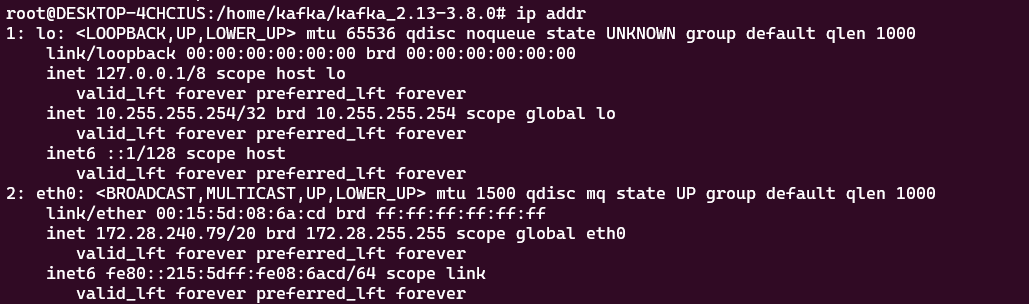
此外,宿主机和wsl环境都放开9092(或者你设置的)端口
链接测试
这里有很多客户端的ui工具或者插件可以连接Kafka,官方本身也提供了测试命令,比如官方文档里给的测试案例就是用这几个命令
本地开发的话,我这里用的vs code的tools for apache kafka@ 这个插件,在插件市场用关键字搜索完成,安装即可
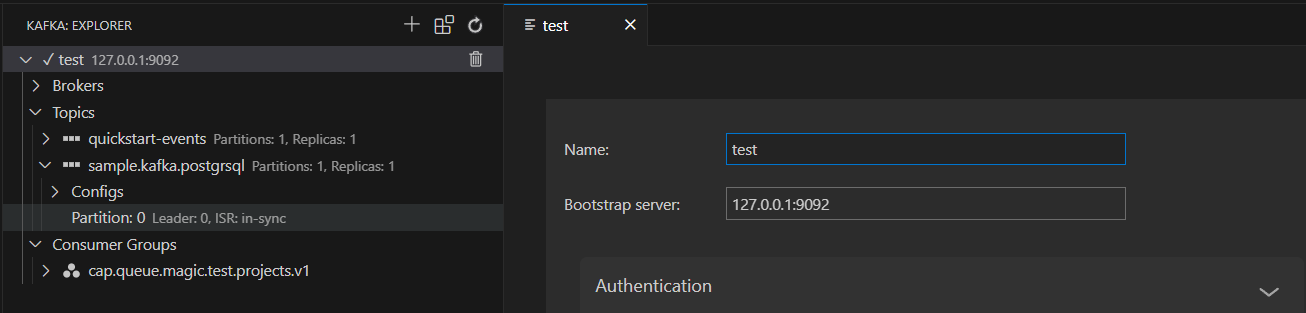
至此,一个本地的Kafka节点就基本配置完成了
安装PostgreSql
这个我老早就装好了,一些安装过程没有截图,就忽略吧,大家有需求的可以问一下各种GPT
也可以用docker,快速部署一个节点做本地的测试。
docker run --name postgres -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d postgres开发测试
新建项目
这里因为我是用的IDE做开发,所以直接创建个web项目就好,也可以用命令行来创建。
总之创建完成后,我的项目长这样
安装依赖
我这里是用的是dotnet.cap这个系列组件,然后为了测试方便,数据库的orm适用的是dapper,主要是图快,大家实际项目中可以用习惯的orm就好。
这里我的项目文件长这样
<Project Sdk="Microsoft.NET.Sdk.Web"><PropertyGroup><TargetFramework>net8.0</TargetFramework><Nullable>enable</Nullable><ImplicitUsings>enable</ImplicitUsings></PropertyGroup><ItemGroup><PackageReference Include="Dapper" Version="2.1.35" /><PackageReference Include="DotNetCore.CAP" Version="8.2.0" /><PackageReference Include="DotNetCore.CAP.Dashboard" Version="8.2.0" /><PackageReference Include="DotNetCore.CAP.Kafka" Version="8.2.0" /><PackageReference Include="DotNetCore.CAP.PostgreSql" Version="8.2.0" /></ItemGroup></Project>注入服务
这里主要注入pg和Kafka
builder.Services.AddCap(x =>
{x.UsePostgreSql("User ID={pg用户名};Password={pg密码};Host={pg地址};Port=5432;Database=maigcTestDb;");x.UseKafka("localhost:9092");x.UseDashboard();
});测试的业务代码
在常规的controller中注入服务
public class ValuesController(ICapPublisher producer) : Controller, ICapSubscribe
{/*业务代码*/
}
//上面这是最新的写法,以前那种构造函数的写法也是ok的
public class Values2Controller : Controller
{private ICapPublisher _capPublisher;public Values2Controller(ICapPublisher capPublisher){_capPublisher = capPublisher;}
}写一个生产者接口
public async Task<IActionResult> Producer()
{Console.WriteLine("生产者发布消息: " + DateTime.Now);await producer.PublishAsync("sample.kafka.postgrsql", DateTime.Now);return Ok();
}再写一个延时发送消息的生产者接口
public async Task<IActionResult> ProducerDelay()
{Console.WriteLine("生产者发布延时消息: " + DateTime.Now);await producer.PublishDelayAsync(TimeSpan.FromSeconds(delaySeconds), "sample.kafka.postgrsql", DateTime.Now);return Ok();
}创建消费者
[CapSubscribe("sample.kafka.postgrsql")]
public void Test2(DateTime value)
{Console.WriteLine("订阅到消息: " + value);
}我们访问下接口看下控制台的打印效果
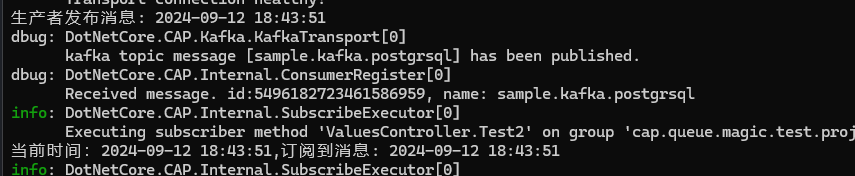
可以看到,订阅到的时间和生产者发送的实际是一致的。
再试下延时发送
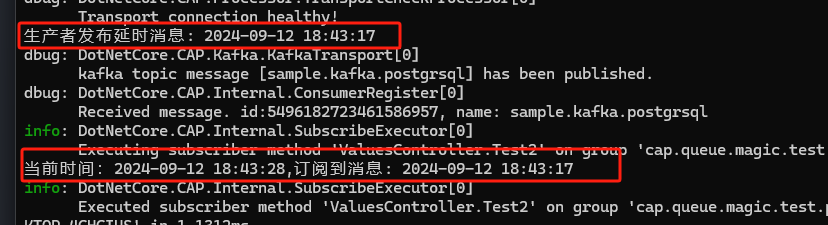
我们延时了10秒发布,这里生产者执行生产消息后,过了10秒,被消费者订阅到。
我们延时了10秒发布,这里生产者执行生产消息后,过了10秒,被消费者订阅到。
再看下PostG里保存的消息记录
这是生产记录

这是消费记录

注意,在CAP的机制里,这些持久化的消息记录是可以设置过期时间的,也就是如果我们每天的并发量很高,产生的消息非常多,可以设置一个过期时间,比如7天,一个月,到期后,这些持久化的数据就会自动清除掉。
CAP的官方文档里,还有更多案例,大家感兴趣也可以去试试,当然除了CAP还有MediatR,MassTransit这类组件,也可以轻松实现消息总线的机制。
好了,到此我们的测试就结束了,从安装Kafka,到创建这个新项目并跑通这个测试服务,也就2个小时,所以,这个迁移成本应该还是非常高效的。
小总结
实际上,我们的生产环境中,正正常运行的一套总线服务,依赖的是RabbitMQ和SQL Server,RabbitMQ还好,SQL Server在以后应该不会是做项目的首选数据库了,尤其是做一些高并发的项目,不是说它性能不够,而是成本太高,社区版的限制有太多,还是要早做规划,提前准备更加适合未来发展的方案,而PostgreSql是目前最受全球开发者欢迎的关系数据库,社区活跃度非常高,开源协议对企业也十分友好,即便是面对国内高标准的信创要求,也完全没问题,是绝佳的首选。
至于Kafka,这是目前世界上最为流行的消息队列,性能,可用性,可扩展性等各方面都比其他消息队列要好上一点。阿里后来推出的RocketMQ,也是基于Kafka的设计原理做了简化和更加适应国内环境的一些调整,根骨还是来自Kafka。而且就生态环境而言,无论国内还是国外,Kafka都是遥遥领先,对dotnet框架的支持,Kafka也远比RocketMQ更好(RocketMQ更多的还是用在java环境里),所以我们再选型的时候,优先考虑的还是Kafka。
更多关于这些内容的知识,大家感兴趣可以去搜一下或者找个AI问一下。
好了,就这些吧。



