前言
我在上一篇文章中《Chainlit集成Langchain并使用通义千问实现和数据库交互的网页对话应用(text2sql)》 利用langchain 中create_sql_agent 创建一个数据库代理智能体,但是实测中发现,使用 create_sql_agent 在对话中,响应速度太慢了,数据的表越多,对话响应就越慢,这次本篇文章langchain中和数据库对话交互的另两种方式,SQLDatabaseChain和create_sql_query_chain。
SQLDatabaseChain
使用LangChain中的SQLDatabaseChain需要安装langchain_experimental,安装依赖命令如下:
pip install langchain
pip install langchain_experimental
SQLDatabaseChain和数据库的交互响应速度 处于 create_sql_agent 和create_sql_query_chain中间,其中create_sql_agent 智能体在交互过程中和AI做了多次交互,大致流程如下:先用AI判断问题和数据中表的相关性,查看相关表的设计表结构,利用AI生成sql查询语句,利用AI对生成的sql查询语句进行检查,利用AI对sql命令查询出来结构做最终回复。过程比较多,导致响应很慢,但是相对于其他两种方式来说,更智能,更严谨。SQLDatabaseChain既保持了一定智能性又提升了回复的速度。下面我用chainilt作为一个网页对话的UI界面,利用SQLDatabaseChain实现一个和数据库对话的网页应用示例如下:
在项目根目录下,创建一个app.py文件,代码如下:
python">import os
import time
from io import BytesIOimport chainlit as cl
import dashscope
from langchain_community.llms import Tongyi
from langchain_community.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain@cl.on_chat_start
async def on_chat_start():db = SQLDatabase.from_uri("postgresql+psycopg2://username:password@ip:port/dbname")llm = Tongyi(model='qwen-plus', verbose=True)db_chain = SQLDatabaseChain.from_llm(llm, db)cl.user_session.set("db_chain", db_chain)@cl.on_message
async def on_message(message: cl.Message):start_time = time.time()db_chain = cl.user_session.get("db_chain")result = db_chain.invoke({"query": message.content})print(f"代码执行时间: {time.time() - start_time} 秒")await cl.Message(content=result['result']).send()
- 修改代码中的数据库连接信息为你自己的
- 在
env文件中配置dashscope的key,不知道的话,看我之前的文章 - 实测中把
qwen-plus改为qwen-max或者其他更智能的AI,回答数据的准确度更高
create_sql_query_chain
create_sql_query_chain 是langchain中和数据库查询最快的方式,他只是负责根据用户问题,生成查询sql查询语句一个功能。不太智能,但是足够灵活,用户可以自定义其他判断和最终回复的逻辑。下面我用create_sql_query_chain结合AI回复实现了一个简单数据库对话网页应用,速度是目前方式中最快的。
在项目根目录下创建app.py文件,代码如下:
python">import os
import time
from io import BytesIOimport chainlit as cl
import dashscope
from langchain.chains.sql_database.query import create_sql_query_chain
from langchain_community.llms import Tongyi
from langchain_community.utilities import SQLDatabase
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplatedb = SQLDatabase.from_uri("postgresql+psycopg2://username:password@ip:port/dbname")
llm = Tongyi(model='qwen-plus', verbose=True)@cl.cache
def extract_sql_query(text):# 查找 'SQLQuery:' 的位置start_index = text.find('SQLQuery:')# 如果找到了 'SQLQuery:',则从其后的位置开始截取字符串if start_index != -1:# 'SQLQuery:' 后面的第一个字符的位置start_of_query = start_index + len('SQLQuery:') + 1# 返回 'SQLQuery:' 后面的字符串return text[start_of_query:].strip()else:# 如果没有找到 'SQLQuery:',则返回空字符串return text@cl.step(type="tool", name="数据库查询")
async def db_query(message: cl.Message):db_chain = cl.user_session.get("db_chain")result = ""async for chunk in db_chain.astream({"question": message.content}):result = result.join(chunk)print("db_chain:" + result)sql = Noneif 'SELECT' in result:sql = extract_sql_query(result)print("自然语言转SQL:" + sql)res = db.run(sql)print("查询结果:", res)return sql, resif not sql:await cl.Message(content=result).send()return None, None@cl.on_chat_start
async def on_chat_start():answer_prompt = PromptTemplate.from_template("""Given the following user question, corresponding SQL query, and SQL result, answer the user question. 用中文回答最终答案Question: {question}SQL Query: {query}SQL Result: {result}Answer: """)answer_chain = answer_prompt | llm | StrOutputParser()cl.user_session.set("answer_chain", answer_chain)db_chain = create_sql_query_chain(llm=llm, db=db)cl.user_session.set("db_chain", db_chain)@cl.on_message
async def on_message(message: cl.Message):start_time = time.time()runnable = cl.user_session.get("answer_chain")msg = cl.Message(content="")sql, res = await db_query(message)if res:async for chunk in runnable.astream({"question": message.content, "query": sql, "result": res}):await msg.stream_token(chunk)print(f"代码执行时间: {time.time() - start_time} 秒")await msg.update()- 修改代码中的配置为你自己的数据库连接信息
- 代码中的AI模型使用的是通义千问的
qwen-plus - 大致原理使用
create_sql_query_chain根据用户问题生成查询sql,对返回的结构进行提取,获得最终sql,使用db.run方法执行最终sql。将sql执行结果、sql查询语句、和用户问题,发给AI做最终回答。 - 这种方式的弊端,当用户提问的问题和数据库无关时,报错的概率更大,需要进一步处理。对于
create_sql_query_chain生成sql命令,没有做进一步校验,默认他是正确的,虽然节省的时间,也提升了报错的概率 db = SQLDatabase.from_uri("sqlite:///demo.db")中的demo.db文件是上面sqlite_data.py文件执行后生成的llm = Tongyi(model='qwen-plus', verbose=True)中verbose意思是是否打印详细输出- 在底层,
LangChain使用SQLAlchemy连接到 SQL 数据库。因此,SQLDatabaseChain可以与SQLAlchemy支持的任何 SQL 方言一起使用,例如MS SQL、MySQL、MariaDB、PostgreSQL、Oracle SQL、Databricks和SQLite。有关连接到数据库的要求的更多信息,请参阅 SQLAlchemy 文档。
连接mysql代码示例:
python"># 连接 MySQL 数据库
db_user = "root"
db_password = "12345678"
db_host = "IP"
db_port = "3306"
db_name = "demo"
db = SQLDatabase.from_uri(f"mysql+pymysql://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}")
运行应用程序
要启动 Chainlit 应用程序,请打开终端并导航到包含的目录app.py。然后运行以下命令:
chainlit run app.py -w
- 该
-w标志告知Chainlit启用自动重新加载,因此您无需在每次更改应用程序时重新启动服务器。您的聊天机器人 UI 现在应该可以通过http://localhost:8000访问。 - 自定义端口可以追加
--port 80
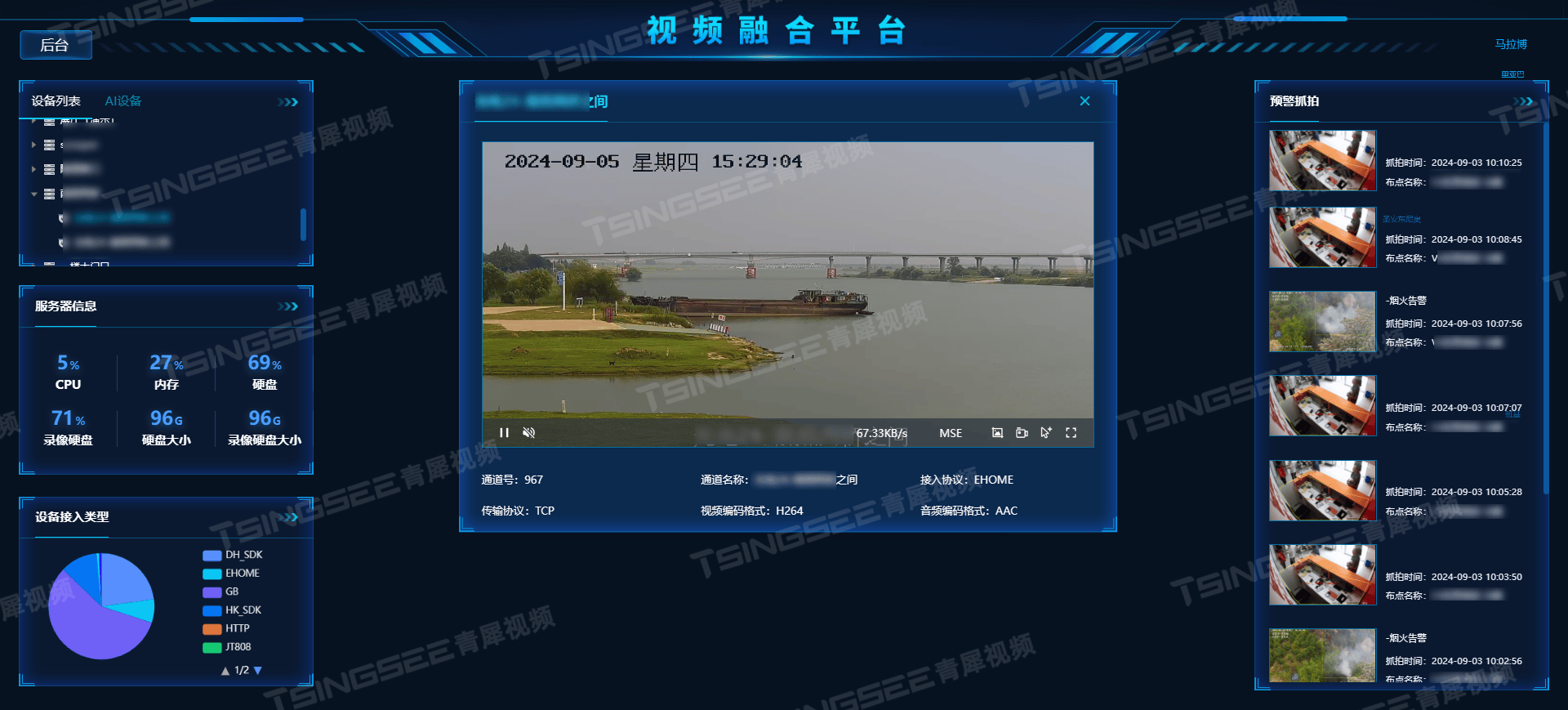
启动后界面如下:


- 目前存在问题没办法流式输出,因为流公式返回的结果是ai执行sql的过程,最终返回的结果文本是流式返回的最后一段。
- 执行时间有点长,提出问题后,一般5秒左右,才返回。
- 目前支持sql查询相关的操作,不支持数据库新增、修改、删除的操作
相关文章推荐
《Chainlit快速实现AI对话应用的界面定制化教程》
《Chainlit接入FastGpt接口快速实现自定义用户聊天界面》
《使用 Xinference 部署本地模型》
《Fastgpt接入Whisper本地模型实现语音输入》
《Fastgpt部署和接入使用重排模型bge-reranker》
《Fastgpt部署接入 M3E和chatglm2-m3e文本向量模型》
《Fastgpt 无法启动或启动后无法正常使用的讨论(启动失败、用户未注册等问题这里)》
《vllm推理服务兼容openai服务API》
《vLLM模型推理引擎参数大全》
《解决vllm推理框架内在开启多显卡时报错问题》
《Ollama 在本地快速部署大型语言模型,可进行定制并创建属于您自己的模型》