摘要
本文使用DOConv卷积,替换YoloV8的常规卷积,轻量高效,即插即用!改进方法非常简单。
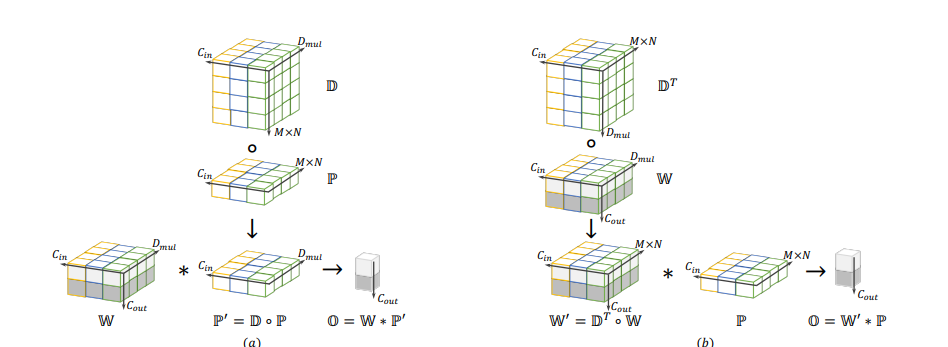
DO-Conv(Depthwise Over-parameterized Convolutional Layer)是一种深度过参数化的卷积层,用于提高卷积神经网络(CNN)的性能。它的核心思想是在训练阶段使用额外的深度卷积来增强卷积层,其中每个输入通道与不同的二维核进行卷积。这两个卷积的组合构成了一个过度参数化,因为它增加了可学习的参数,而结果的线性操作可以用单个卷积层来表示。在推理阶段,DO-Conv可以融合到常规卷积层中,使得计算量与常规卷积层的计算量完全相同。
DO-Conv可以作为一种即插即用的模块,用于替代CNN中的常规卷积层,以提高在各种计算机视觉任务(如图像分类、语义分割和对象检测)上的性能。通过实验证明,使用DO-Conv不仅可以加速网络的训练过程,还能在多种计算机视觉任务中取得比使用传统卷积层更好的结果。
论文链接:https://arxiv.org/pdf/2006.12030.pdf
代码
# coding=utf-8
import math
import torch
import numpy as np
from torch.nn import init
from itertools import repeat
from torch.nn import functional as F
from torch._jit_internal import Optional
from torch.nn.parameter import Parameter
from torch.nn.modules.module import Module
import collectionsclass DOConv2d(Module):"""DOConv2d can be used as an alternative for torch.nn.Conv2d.The interface is similar to that of Conv2d, with one exception:1. D_mul: the depth multiplier for the over-parameterization.Note that the groups parameter switchs between DO-Conv (groups=1),DO-DConv (groups=in_channels), DO-GConv (otherwise)."""__constants__ = ['stride', 'padding', 'dilation', 'groups','padding_mode', 'output_padding', 'in_channels','out_channels', 'kernel_size', 'D_mul']__annotations__ = {'bias': Optional[torch.Tensor]}def __init__(self, in_channels, out_channels, kernel_size, D_mul=None, stride=1,padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros'):super(DOConv2d, self).__init__()kernel_size = _pair(kernel_size)stride = _pair(stride)padding = _pair(padding)dilation = _pair(dilation)if in_channels % groups != 0:raise ValueError('in_channels must be divisible by groups')if out_channels % groups != 0:raise ValueError('out_channels must be divisible by groups')valid_padding_modes = {'zeros', 'reflect', 'replicate', 'circular'}if padding_mode not in valid_padding_modes:raise ValueError("padding_mode must be one of {}, but got padding_mode='{}'".format(valid_padding_modes, padding_mode))self.in_channels = in_channelsself.out_channels = out_channelsself.kernel_size = kernel_sizeself.stride = strideself.padding = paddingself.dilation = dilationself.groups = groupsself.padding_mode = padding_modeself._padding_repeated_twice = tuple(x for x in self.padding for _ in range(2))#################################### Initailization of D & W ###################################M = self.kernel_size[0]N = self.kernel_size[1]self.D_mul = M * N if D_mul is None or M * N <= 1 else D_mulself.W = Parameter(torch.Tensor(out_channels, in_channels // groups, self.D_mul))init.kaiming_uniform_(self.W, a=math.sqrt(5))if M * N > 1:self.D = Parameter(torch.Tensor(in_channels, M * N, self.D_mul))init_zero = np.zeros([in_channels, M * N, self.D_mul], dtype=np.float32)self.D.data = torch.from_numpy(init_zero)eye = torch.reshape(torch.eye(M * N, dtype=torch.float32), (1, M * N, M * N))d_diag = eye.repeat((in_channels, 1, self.D_mul // (M * N)))if self.D_mul % (M * N) != 0: # the cases when D_mul > M * Nzeros = torch.zeros([in_channels, M * N, self.D_mul % (M * N)])self.d_diag = Parameter(torch.cat([d_diag, zeros], dim=2), requires_grad=False)else: # the case when D_mul = M * Nself.d_diag = Parameter(d_diag, requires_grad=False)##################################################################################################if bias:self.bias = Parameter(torch.Tensor(out_channels))fan_in, _ = init._calculate_fan_in_and_fan_out(self.W)bound = 1 / math.sqrt(fan_in)init.uniform_(self.bias, -bound, bound)else:self.register_parameter('bias', None)def extra_repr(self):s = ('{in_channels}, {out_channels}, kernel_size={kernel_size}'', stride={stride}')if self.padding != (0,) * len(self.padding):s += ', padding={padding}'if self.dilation != (1,) * len(self.dilation):s += ', dilation={dilation}'if self.groups != 1:s += ', groups={groups}'if self.bias is None:s += ', bias=False'if self.padding_mode != 'zeros':s += ', padding_mode={padding_mode}'return s.format(**self.__dict__)def __setstate__(self, state):super(DOConv2d, self).__setstate__(state)if not hasattr(self, 'padding_mode'):self.padding_mode = 'zeros'def _conv_forward(self, input, weight):if self.padding_mode != 'zeros':return F.conv2d(F.pad(input, self._padding_repeated_twice, mode=self.padding_mode),weight, self.bias, self.stride,_pair(0), self.dilation, self.groups)return F.conv2d(input, weight, self.bias, self.stride,self.padding, self.dilation, self.groups)def forward(self, input):M = self.kernel_size[0]N = self.kernel_size[1]DoW_shape = (self.out_channels, self.in_channels // self.groups, M, N)if M * N > 1:######################### Compute DoW ################## (input_channels, D_mul, M * N)D = self.D + self.d_diagW = torch.reshape(self.W, (self.out_channels // self.groups, self.in_channels, self.D_mul))# einsum outputs (out_channels // groups, in_channels, M * N),# which is reshaped to# (out_channels, in_channels // groups, M, N)DoW = torch.reshape(torch.einsum('ims,ois->oim', D, W), DoW_shape)else:# in this case D_mul == M * N# reshape from# (out_channels, in_channels // groups, D_mul)# to# (out_channels, in_channels // groups, M, N)DoW = torch.reshape(self.W, DoW_shape)return self._conv_forward(input, DoW)def _ntuple(n):def parse(x):if isinstance(x, collections.abc.Iterable):return xreturn tuple(repeat(x, n))return parse
_pair = _ntuple(2)