目录
齐普夫定律
相关度排序
工具
其他工具
Okapi BM25
在文档向量中,词计数是有用的,但是纯词计数,即使按照文档长度进行归一化处理,也不能告诉我们太多该词在当前文档相对于语料库中其他文档的重要度信息。如果能弄清楚这些信息,我们就能开始描述语料库中的文档了。假设我们有一个收集了所有风筝数据的语料库,那么几乎可以肯定的是“Kite”一词会在每一个文档中出现很多次,但这不能提供任何新信息,对区分文档没有任何帮助。像“construction”这样的词可能不会在整个语料库中普遍出现,但是对于这些词频繁出现的那些文档,我们会对每篇文档的本质有更多了解。为此,我们需要另一个工具。
逆文档频率(IDF),在齐普夫定律下为主题分析打开了一扇新窗户。我们从前面的词项频繁计数器开始,然后对它进行扩展。我们可以通过两种方式对词条计数并对它们装箱处理:对每篇文档进行处理或遍历整个语料库。
下面我们只按文档计数:
python">from nltk.tokenize import TreebankWordTokenizer
tokenizer=TreebankWordTokenizer()kite_txt_1="""
A kite is traditionally a tethered heavier-than-air craft with wing surfaces that react against the air to create lift and drag. A kite consists of wings, tethers, and anchors. Kites often have a bridle to guide the face of the kite at the correct angle so the wind can lift it. A kite’s wing also may be so designed so a bridle is not needed; when kiting a sailplane for launch, the tether meets the wing at a single point. A kite may have fixed or moving anchors. Untraditionally in technical kiting, a kite consists of tether-set-coupled wing sets; even in technical kiting, though, a wing in the system is still often called the kite.
The lift that sustains the kite in flight is generated when air flows around the kite’s surface, producing low pressure above and high pressure below the wings. The interaction with the wind also generates horizontal drag along the direction of the wind. The resultant force vector from the lift and drag force components is opposed by the tension of one or more of the lines or tethers to which the kite is attached. The anchor point of the kite line may be static or moving (such as the towing of a kite by a running person, boat, free-falling anchors as in paragliders and fugitive parakites or vehicle).
The same principles of fluid flow apply in liquids and kites are also used under water. A hybrid tethered craft comprising both a lighter-than-air balloon as well as a kite lifting surface is called a kytoon.
Kites have a long and varied history and many different types are flown individually and at festivals worldwide. Kites may be flown for recreation, art or other practical uses. Sport kites can be flown in aerial ballet, sometimes as part of a competition. Power kites are multi-line steerable kites designed to generate large forces which can be used to power activities such as kite surfing, kite landboarding, kite fishing, kite buggying and a new trend snow kiting. Even Man-lifting kites have been made.
"""
kite_txt_2="""
Kites were invented in China, where materials ideal for kite building were readily available: silk fabric for sail material; fine, high-tensile-strength silk for flying line; and resilient bamboo for a strong, lightweight framework.
The kite has been claimed as the invention of the 5th-century BC Chinese philosophers Mozi (also Mo Di) and Lu Ban (also Gongshu Ban). By 549 AD paper kites were certainly being flown, as it was recorded that in that year a paper kite was used as a message for a rescue mission. Ancient and medieval Chinese sources describe kites being used for measuring distances, testing the wind, lifting men, signaling, and communication for military operations. The earliest known Chinese kites were flat (not bowed) and often rectangular. Later, tailless kites incorporated a stabilizing bowline. Kites were decorated with mythological motifs and legendary figures; some were fitted with strings and whistles to make musical sounds while flying. From China, kites were introduced to Cambodia, Thailand, India, Japan, Korea and the western world.
After its introduction into India, the kite further evolved into the fighter kite, known as the patang in India, where thousands are flown every year on festivals such as Makar Sankranti.
Kites were known throughout Polynesia, as far as New Zealand, with the assumption being that the knowledge diffused from China along with the people. Anthropomorphic kites made from cloth and wood were used in religious ceremonies to send prayers to the gods. Polynesian kite traditions are used by anthropologists get an idea of early "primitive" Asian traditions that are believed to have at one time existed in Asia.
"""
kite_intro=kite_txt_1.lower()
intro_tokens=tokenizer.tokenize(kite_intro)
kite_history=kite_txt_2.lower()
history_tokens=tokenizer.tokenize(kite_history)
intro_total=len(intro_tokens)
print(intro_total)
history_total=len(history_tokens)
print(history_total)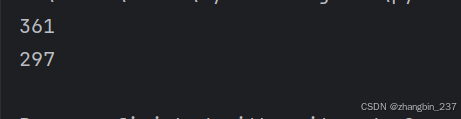
现在,由两篇分词后的kite文档,我们计算“kite”在每篇文档中的词项频率。我们将词项频率存储到两个字典中,其中每个字典对应一篇文档。
python">from collections import Counter
intro_tf={}
history_tf={}
intro_counts=Counter(intro_tokens)
intro_tf['kite']=intro_counts['kite']/intro_total
history_counts=Counter(history_tokens)
history_tf['kite']=history_counts['kite']/history_total
print(intro_tf['kite'],history_tf['kite'])
可以看到,“kite”在两篇文档中的词项频率分别是0.0388和0.0202。
进一步挖掘,看下其他词的词项频率数字:
python">intro_tf['and']=intro_counts['and']/intro_total
history_tf['and']=history_counts['and']/history_total
print(intro_tf['and'],history_tf['and'])
可以看到,这两篇文档和“and”的相关度,与它们和“kite”的相关度相差不大。这似乎没什么用。
考虑词项逆文档频率的一个好方法是:这个词条在此文档中有多稀缺?如果一个词项在某篇文档中出现很多次,但很少出现在语料库的其他文档中,那么就可以假设它对当前文档非常重要。
词项的IDF仅仅是文档总数与该词项出现的文档数之比。在当前示例中的“and”和“kite”,它们的IDF是相同的:
- 文档总数/出现“and”的文档数=2/2=1
- 文档总数/出现“kite”的文档数=2/2=1
- 文档总数/出现“China”的文档数=2/1=2
出现了一个不同的结果,下面使用这种稀缺度指标来对词项频率加权:
python">num_docs_containing_and=0
for doc in [intro_tokens,history_tokens]:if 'and' in doc:num_docs_containing_and=num_docs_containing_and+1获取“China”在两篇文档中的词项频率值:
python">intro_tf['China']=intro_counts['China']/intro_total
history_tf['China']=history_counts['China']/history_total最后,计算3个词的IDF。我们就像存储词项频率一样把IDF存储在每篇文档的字典中:
python">num_docs=2
intro_ifd={}
history_idf={}
intro_ifd['and']=num_docs/num_docs_containing_and
history_idf['and']=num_docs/num_docs_containing_and
intro_ifd['kite']=num_docs/num_docs_containing_and
history_idf['kite']=num_docs/num_docs_containing_and
intro_ifd['china']=num_docs/num_docs_containing_and
history_idf['china']=num_docs/num_docs_containing_and然后对文档intro和文档history有:
python">intro_tfidf={}
intro_tfidf['and']=intro_tf['and']*intro_ifd['and']
intro_tfidf['kite']=intro_tf['kite']*intro_ifd['kite']
intro_tfidf['china']=intro_tf['china']*intro_ifd['china']
history_tfidf={}
history_tfidf['and']=history_tf['and']*history_idf['and']
history_tfidf['kite']=history_tf['kite']*history_idf['kite']
history_tfidf['china']=history_tf['china']*history_idf['china']齐普夫定律
假设我们拥有一个包含100万篇文档的语料库,有人搜索“cat”这个词,在上述100万篇文档中,只有一篇文档包含“cat”。那么这个词的原始或源生IDF为:
1000000/1=1000000
假设有10篇文章包含“dog”,那么“dog”的IDF为:
1000000/10=100000
上述两个结果显著不同。齐普夫会说上面的差距太大了,因为这种差距可能会经常出现。齐普夫定律表明,当比较两个词的词频时,即使它们出现的次数类似,更频繁出现的词的词频也将指数级地高于较不频繁出现的词的词频。因此,齐普夫定律建议使用对数log()来对词频(和文档频率)进行尺度的缩放处理。这就能够确保像“cat”和“dog”这样的词,即使它们出现的次数类似,在最后的词频计算结果上也不会出现指数级的差异。此外,这种词频的分布将确保TF-IDF分数更加符合均匀分布。因此,我们应该将IDF重新定义为词出现在某篇文档中原始概率的对数。对于词项频率,我们也会进行对数处理。
对数函数的底并不重要,因为我们只想使频率分布均匀,而不是将值限定在特定的数值范围内进行缩放。如果用一个以10为底的对数函数,我们会得到:
search:cat——idf=lg(1000000/1)=6
search:dog——idf=lg(1000000/10)=5
所以现在要根据它们在语言中总体出现的次数,对每一个TF结果进行适当的加权。
最终,对于语料库D中给定的文档d里的词项t,有:
tf(t,d)=(t在d中出现的次数)/(d的长度)
tf(t,D)=lg(文档数/包含t的文档数)
tfidf(t,d,D)=tf(t,d)*idf(t,D)
因此,一个词在文档中出现的次数越多,它在文档中的TF(进而TF-IDF)就会越高。与此同时,随着包含该词的文档数增加,该词的IDF(进而TF-IDF)将下降。现在,我们有了一个计算机可以处理的数字,它将特定词或词条与特定语料库中的特定文档关联起来,然后根据该词在整个语料库中的使用情况,为该词在给定文档中的重要度赋予了一个数值。
在一些情况下,所有的计算可以都在对数空间中进行,这样乘法就变成了加法,处罚就变成了减法:
python">log_tf=log(term_occurences_in_doc)-log(num_terms_in_doc)
log_idf=log(log(total_num_docs))-log(num_docs_containing_term)
log_tf_idf=log_tf+log_idfTF-IDF这个独立的数字,是简单搜索引擎的简陋的基础。线性代数对于全民理解自然语言处理中使用的工具并不是必需的,但是大体上熟悉公式的工作原理可以使它们的使用更加直观。
相关度排序
我们可以很容易地比较两个向量来得到它们的相似度,然而我们已经了解到,仅仅对词计数并不像使用它们的TF-IDF那样具有可描述性。因此,在每个文档向量中,我们用词的TF-IDF替换TF。现在,向量将更全面地反映文档的含义或主题,像是下面的case:
python">import copy
from nltk.tokenize import TreebankWordTokenizer
tokenizer=TreebankWordTokenizer()
from collections import Counter
from collections import OrderedDictdocs=["""
The faster Harry got to the store, the faster and faster Harry would get home.
"""]
docs.append("""
Harry is hairy and faster than Jill
""")
docs.append("""
Jill is not as hairy as Harry
""")
doc_tokens=[]
for doc in docs:doc_tokens=doc_tokens+[sorted(tokenizer.tokenize(doc.lower()))]
all_doc_tokens=sum(doc_tokens,[])
lexicon=sorted(set(all_doc_tokens))
zero_vector=OrderedDict((token,0) for token in lexicon)document_tfidf_vectors=[]
for doc in docs:vec=copy.copy(zero_vector)tokens=tokenizer.tokenize(doc.lower())token_counts=Counter(tokens)for key,value in token_counts.items():docs_containing_key=0for _doc in docs:if key in _doc:docs_containing_key=docs_containing_key+1tf=value/len(lexicon)if docs_containing_key:idf=len(docs)/docs_containing_keyelse:idf=0vec[key]=tf*idfdocument_tfidf_vectors.append(vec)
print(document_tfidf_vectors)
在上述设置下,我们就得到了语料库中每篇文档的K维向量表示。在给定的向量空间中,如果两个向量有相似的角度,可以说它们是相似的。
如果两个向量的余弦相似度很高,那么它们就被认为是相似的。因此,如果最小化余弦相似度,就可以找到两个相似的向量:
现在,我们已经有了进行基本TF-IDF搜索的所有东西,我们可以将搜索查询本身视为文档,从而获得它的基于TF-IDF的向量表示,最后一步是找到与查询余弦相似度最高的向量的文档,并将这些文档作为搜索结果返回。
下面是一个简单的case:
python">query="How long does it take to get to the store?"
query_vec=copy.copy(zero_vector)
tokens=tokenizer.tokenize(query.lower())
token_counts=Counter(tokens)
for key,value in token_counts.items():docs_containing_key=0for _doc in docs:if key in _doc.lower():docs_containing_key=docs_containing_key+1if docs_containing_key==0:continuetf=value/len(tokens)idf=len(docs)/docs_containing_keyquery_vec[key]=tf*idf
print(cosine_sim(query_vec,document_tfidf_vectors[0]))
print(cosine_sim(query_vec,document_tfidf_vectors[1]))
print(cosine_sim(query_vec,document_tfidf_vectors[2]))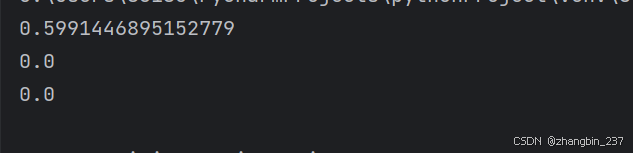
可以看到,对于当前查询,文档0的相关度最高。通过这种方式我们可以在任何语料库中寻找相关的文档,无论是维基百科的文章还是来自推特的推文。
对于每个查询而言,都必须对所有TF-IDF向量进行“索引扫描”。这是一个复杂度为O(N)的算法。由于使用了倒排索引,大多数搜索引擎可以在常数时间(O(1))内响应。
关键词搜索只是NLP流水线中的一个工具,而我们的目标是构建一个聊天机器人,大多数聊天机器人高度依赖搜索引擎。并且,一些聊天机器人完全依赖搜索引擎,将它作为生成回复的唯一算法。我们需要采用额外的步骤将简单搜索索引(TF-IDF)转换为聊天机器人。我们需要将“问题-回复”对形式的训练数据存储起来。然后,就可以使用TF-IDF搜索与用户输入的文本最相似的问题。这里我们不返回数据库中最相似的语句,而是返回与该语句关联的回复。就像任何棘手的计算机科学问题一样,我们的问题可以通过加入一个间接层来解决。
工具
很久以前搜索就已经自动化处理,有很多相关的实现代码。我们也可以使用scikit-learn包找到快速路径。
下面使用sklearn来构建TF-IDF矩阵。sklearn TF-IDF类是一个包含.fit()和.transform()方法的模型,这些方法遵循所有机器学习模型的sklearn API:
python">from sklearn.feature_extraction.text import TfidfVectorizerdocs=["""
The faster Harry got to the store, the faster and faster Harry would get home.
"""]
docs.append("""
Harry is hairy and faster than Jill
""")
docs.append("""
Jill is not as hairy as Harry
""")corpus=docs
vectorizer=TfidfVectorizer(min_df=1)
model=vectorizer.fit_transform(corpus)
print(model.todense().round(2))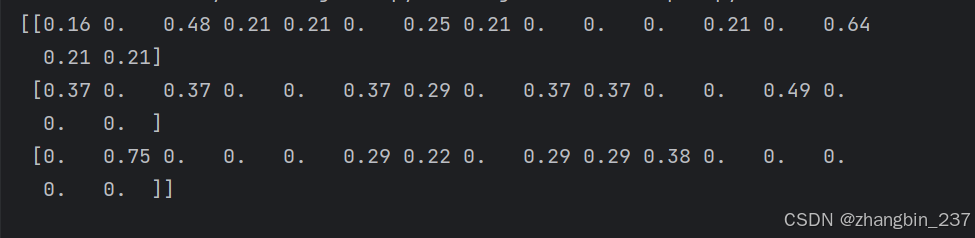
利用scikit-learn,我们在上面的代码中创建了一个由3行文档组成的矩阵,以及词库中每个词项的逆文档频率。现在有一个表示3个文档的矩阵,词库中每个词项、词条或词的TF-IDF构成矩阵的列。因为分词方式不同,而且去掉了标签符号,所以词库中只有16个词项。对大规模文本而言,这种或其他一些预优化的TF-IDF模型将为我们省去大量工作。
其他工具
TF-IDF矩阵(词项-文档矩阵)一直是信息检索(搜索)的主流。为了提高搜索结果相关性,下面是一些可以归一化和平滑词项频率权重的方案:
| 方案 | 定义 |
| None | |
| TF-IDF | |
| TF-ICF | |
| Okapi BM25 |
搜索引擎(信息检索系统)在查询和语料库中的文档之间匹配关键词(词项)。
Okapi BM25
除了计算TF-IDF余弦相似度,还可以对相似度进行归一化和平滑处理。忽略查询文档中词项的重复出现,从而可以有效地将查询向量的词频都简化为1.这里,余弦相似度的点积不是很具TF-IDF向量的模(文档和查询中的词项数)进行归一化,而是由文档长度本身的一个非线性函数进行归一化:
q_idf*dot(q_tf,d_tf[i])*1.5/(dot(q_tf,d_tf[i])+0.25+0.75*d_num_words[i]/d_num_words.mean()))
通过选择给用户提供最相关结果的权重方案,我们可以优化流水线。但是,如果所处理的语料库不是太大,可以考虑继续往下探索,对词和文档的含义进行更有用和更准确的表示。相比于TF-IDF加权、词干还原和词形归并所希望达到的目标,语义搜索会好得多。