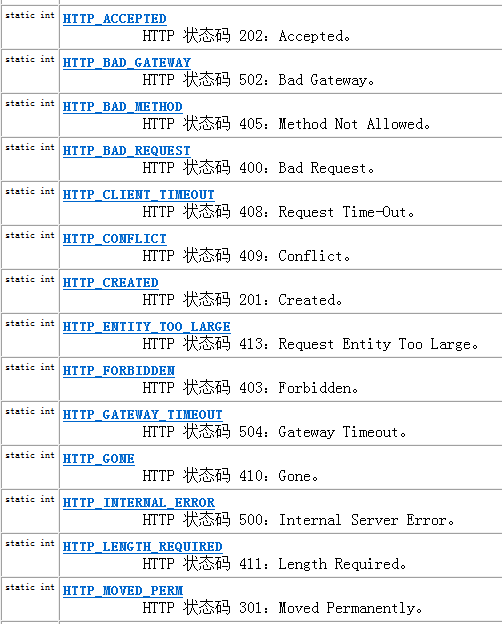
堆的建立、插入、出堆、堆化、topk问题、堆排序
- 使用数组来存储堆
- 堆顶为序号0,堆底为序号 size - 1
- 假设树为完全二叉树,当前节点和双亲节点的关系可以通过公式表达
// 小顶堆: 对 heaptifyUp 和 heaptifyDown 函数的逻辑进行一些调整。
void initHeap(float **arr, int *size) { *arr = (float *)malloc(sizeof(float) * MAX_SIZE); *size = 0; }
void peekTop(float *arr, int size, float *x) { if (size <= 0) return; *x = arr[0]; }
void getParent(int i, int *p_idx) { *p_idx = (i - 1) / 2; }
void getLeftChild(int i, int *lc_idx) { *lc_idx = 2 * i + 1; }
void getRightChild(int i, int *rc_idx) { *rc_idx = 2 * i + 2; }
void heaptifyUp(float *arr, int idx) { // 比较当前节点与其父节点的大小。如果当前节点的值小于父节点的值,则交换它们,并继续向上调整。int cur = idx;while (cur > 0) { // 只要 cur 不是根节点int par; getParent(cur, &par); if (arr[cur] >= arr[par]) break; // 如果当前节点大于等于父节点,退出循环float tmp = arr[cur]; arr[cur] = arr[par]; arr[par] = tmp; cur = par; // 交换当前节点和父节点, 更新 cur 为父节点索引}
}
void heaptifyDown(float *arr, int size, int idx) { // 比较当前节点与其左右子节点的大小。选择最小的子节点,如果当前节点大于这个子节点,则交换它们,并继续向下调整。int cur = idx;while (true) {int lc, rc, minidx = cur; getLeftChild(cur, &lc); getRightChild(cur, &rc);if (lc < size && arr[lc] < arr[minidx]) { minidx = lc; } // 找到当前节点和左子节点中的最小值if (rc < size && arr[rc] < arr[minidx]) { minidx = rc; } // 找到当前节点和右子节点中的最小值if (minidx == cur) break; // 如果当前节点是最小值,退出循环float tmp = arr[cur]; arr[cur] = arr[minidx]; arr[minidx] = tmp; cur = minidx; // 交换当前节点和最小值节点, 更新 cur 为新的索引}
}
void pushHeap(float *arr, int *size, float x) {if ((*size) >= MAX_SIZE) return; // 如果堆已满,直接返回arr[*size] = x; (*size)++; // 将新元素放在堆的最后一个位置heaptifyUp(arr, (*size) - 1); // 重新调整堆
}
void popHeap(float *arr, int *size, float *val) {if ((*size) <= 0) return; // 如果堆为空,直接返回*val = arr[0]; arr[0] = arr[(*size) - 1]; // 将堆的最后一个元素放在堆顶(*size)--; heaptifyDown(arr, *size, 0); // 重新调整堆
}
void buildHeap(float *arr, int size){// 使用heaptifyDown的原因是,如果使用 heaptifyUp从树的底部向上调整,每个节点在最坏情况下可能需要一直移到树的根部(并且底部的节点数量多)。// 这意味着可能需要执行更多的比较和交换操作。而如果我们从上往下调整,每个节点最多只需要向下移动几层(通常是树的高度),这使得整体效率非常高。for (int i = size / 2 - 1; i >= 0; i--) heaptifyDown(arr, size, i); // 从最后一个非叶子节点(size/2 - 1)开始,向上调整堆;
}
void freeHeap(float **arr) { if (*arr) { free(*arr); *arr = NULL; } }
void top_k(float *arr, int size, float *res, int k) {if (k <= 0 || k > size) return;float *heap = (float *)malloc(sizeof(float) * k); int heap_size = 0;for (int i = 0; i < k; i++){ pushHeap(heap, &heap_size, arr[i]); } // // 初始化堆,放入前 k 个元素for (int i = k; i < size; i++){ if (arr[i] > heap[0]) { float tmp; popHeap(heap, &heap_size, &tmp); pushHeap(heap, &heap_size, arr[i]); } } // 处理剩余的元素for (int i = 0; i < k; i++) { popHeap(heap, &heap_size, &res[k - 1 - i]); } // 将堆中的元素按降序输出到 res 数组freeHeap(&heap);
}
// parallel: 在构建堆时,并行化处理多个子树的下沉操作
void heap_sort(float *heap, int size){ // 堆排序,从大道小排序buildHeap( heap, size); // 构建小顶堆while (size > 1) {float tmp = heap[0]; heap[0] = heap[size - 1]; heap[size - 1] = tmp; size--; // 将堆顶元素与堆的最后一个元素交换,每次循环最小的元素被调整到末尾,堆的大小减1heaptifyDown(heap, size, 0); // 从堆顶开始重新调整堆}freeHeap(&heap);
} 大顶堆
//void initHeap(float **arr, int *size) { *arr = (float *)malloc(sizeof(float) * MAX_SIZE); *size = 0; } // 初始化堆的大小为0
//void peekTop(float *arr, int size, float *x) { if (size <= 0) return ; *x = arr[0]; }
//void getParent(int i, int *p_idx) { *p_idx = (i - 1) / 2; }
//void getLeftChild(int i, int *lc_idx) { *lc_idx = 2 * i + 1; }
//void getRightChild(int i, int *rc_idx) { *rc_idx = 2 * i + 2; }
//void heaptifyUp(float *arr, int idx){
// int cur = idx;
// while (cur > 0){ // 只要 cur 不是根节点
// int par; getParent(cur, &par); if (arr[cur] < arr[par]) break; // 如果当前节点小于父节点,退出循环
// float tmp = arr[cur]; arr[cur] = arr[par]; arr[par] = tmp; cur = par; // 交换当前节点和父节点
// }
//}
//void heaptifyDown(float *arr, int size, int idx){
// int cur = idx;
// while (true){
// int lc, rc, maxidx = cur; getLeftChild(cur, &lc); getRightChild(cur, &rc);
// if (lc < size && arr[lc] > arr[maxidx]) { maxidx = lc;} // 找到当前节点和左子节点中的最大值
// if (rc < size && arr[rc] > arr[maxidx]) { maxidx = rc;} // 找到当前节点和右子节点中的最大值
// if (maxidx == cur) break; // 如果当前节点是最大值,退出循环
// float tmp = arr[cur]; arr[cur] = arr[maxidx]; arr[maxidx] = tmp; cur = maxidx; // 交换当前节点和最大值节点
// }
//}
//void pushHeap(float *arr, int *size, float x){
// if ((*size) >= MAX_SIZE) return; // 如果堆已满,直接返回
// arr[*size] = x; (*size)++; // 将新元素放在堆的最后一个位置
// heaptifyUp(arr, (*size) - 1); // 重新调整堆
//}
//void popHeap(float *arr, int *size, float *val){
// if ((*size) <= 0) return; // 如果堆为空,直接返回
// *val = arr[0];
// arr[0] = arr[(*size) - 1]; // 将堆的最后一个元素放在堆顶
// (*size)--;
// heaptifyDown(arr, *size,0); // 重新调整堆
//}
//void freeHeap(float **arr) { if (*arr) { free(*arr); *arr = NULL; } }