1、讲一讲Kafka与RocketMQ中存储设计的异同?
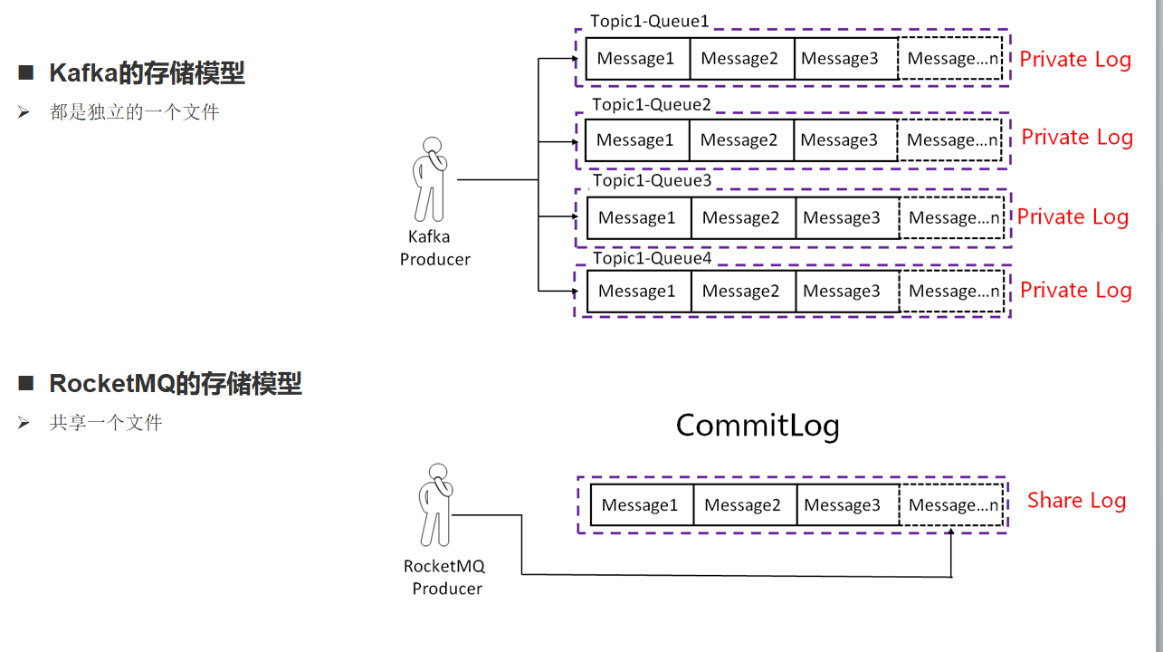
Kafka 中文件的布局是以 Topic/partition ,每一个分区一个物理文件夹,在分区文件级别实现文件顺序写,如果一个Kafka集群中拥有成百上千个主题,每一个主题拥有上百个分区,消息在高并发写入时,其IO操作就会显得零散(消息分散的落盘策略会导致磁盘IO竞争激烈成为瓶颈),其操作相当于随机IO,即 Kafka 在消息写入时的IO性能会随着 topic 、分区数量的增长,其写入性能会先上升,然后下降。
而RocketMQ在消息写入时追求极致的顺序写,所有的消息不分主题一律顺序写入 commitlog 文件,并不会随着 topic 和 分区数量的增加而影响其顺序性。
在消息发送端,消费端共存的场景下,随着Topic数的增加Kafka吞吐量会急剧下降,而RocketMQ则表现稳定。因此Kafka适合Topic和消费端都比较少的业务场景,而RocketMQ更适合多Topic,多消费端的业务场景。
2、讲一讲Kafka与RocketMQ中零拷贝技术的运用
什么是零拷贝?
零拷贝(英语: Zero-copy) 技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
➢零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率
➢零拷贝技术减少了用户进程地址空间和内核地址空间之间因为上:下文切换而带来的开销
可以看出没有说不需要拷贝,只是说减少冗余[不必要]的拷贝。
下面这些组件、框架中均使用了零拷贝技术:Kafka、Netty、Rocketmq、Nginx、Apache。
传统数据传送机制
比如:读取文件,再用socket发送出去,实际经过四次copy。
伪码实现如下:
buffer = File.read()
Socket.send(buffer)
1、第一次:将磁盘文件,读取到操作系统内核缓冲区;
2、第二次:将内核缓冲区的数据,copy到应用程序的buffer;
3、第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
4、第四次:将socket buffer的数据,copy到网卡,由网卡进行网络传输。
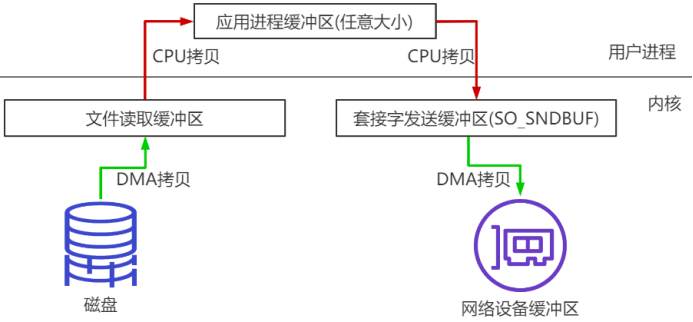
分析上述的过程,虽然引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。
显然,第二次和第三次数据copy 其实在这种场景下没有什么帮助反而带来开销(DMA拷贝速度一般比CPU拷贝速度快一个数量级),这也正是零拷贝出现的背景和意义。
打个比喻:200M的数据,读取文件,再用socket发送出去,实际经过四次copy(2次cpu拷贝每次100ms ,2次DMS拷贝每次10ms)
传统网络传输的话:合计耗时将有220ms
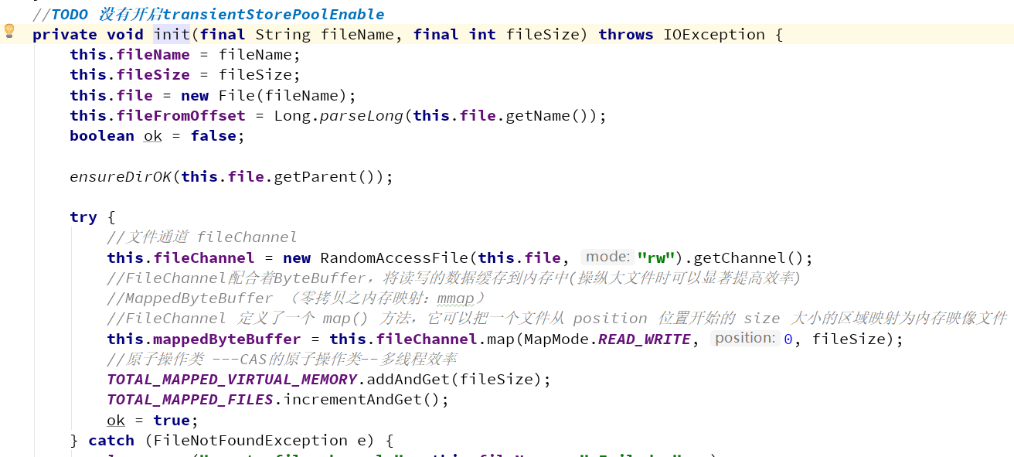
mmap内存映射(RocketMQ使用的)
硬盘上文件的位置和应用程序缓冲区(application buffers)进行映射(建立一种一一对应关系),由于mmap()将文件直接映射到用户空间,所以实际文件读取时根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝,不再有文件内容从硬盘拷贝到内核空间的一个缓冲区。
mmap内存映射将会经历:3次拷贝: 1次cpu copy,2次DMA copy;
打个比喻:200M的数据,读取文件,再用socket发送出去,如果是使用MMAP实际经过三次copy(1次cpu拷贝每次100ms ,2次DMS拷贝每次10ms)合计只需要120ms
从数据拷贝的角度上来看,就比传统的网络传输,性能提升了近一倍。

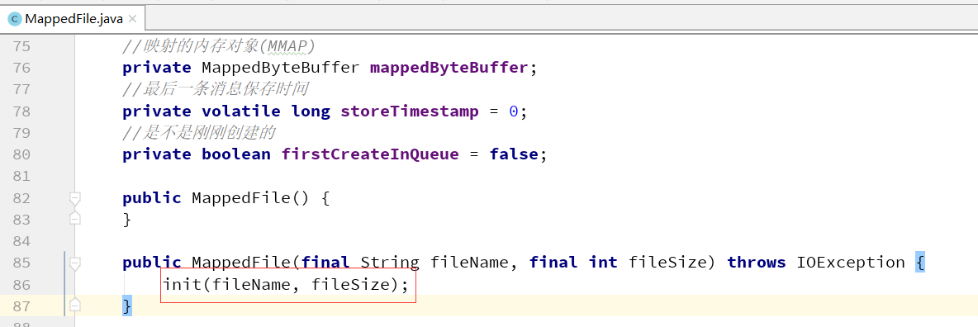
RocketMQ源码中的MMAP运用
RocketMQ源码中,使用MappedFile这个类类进行MMAP的映射
Kafka中的零拷贝
Kafka两个重要过程都使用了零拷贝技术,且都是操作系统层面的狭义零拷贝,一是Producer生产的数据存到broker,二是 Consumer从broker读取数据。
Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入;
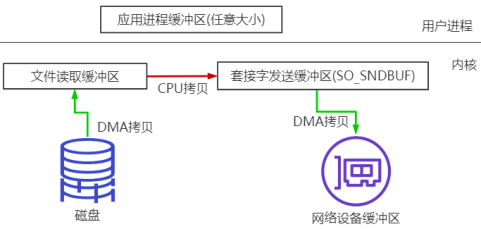
Customer从broker读取数据,采用sendfile,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
sendfile
linux 2.1支持的sendfile
当调用sendfile()时,DMA将磁盘数据复制到kernel buffer,然后将内核中的kernel buffer直接拷贝到socket buffer。在硬件支持的情况下,甚至数据都并不需要被真正复制到socket关联的缓冲区内。取而代之的是,只有记录数据位置和长度的描述符被加入到socket缓冲区中,DMA模块将数据直接从内核缓冲区传递给协议引擎,从而消除了遗留的最后一次复制。
一旦数据全都拷贝到socket buffer,sendfile()系统调用将会return、代表数据转化的完成。socket buffer里的数据就能在网络传输了。
sendfile会经历:3次拷贝,1次CPU copy ,2次DMA copy;硬件支持的情况下,则是2次拷贝,0次CPU copy, 2次DMA copy。
3、有没有读过RocketMQ源码,分享一下?
RocketMQ的源码是非常的多,我们没有必要把RocketMQ所有的源码都读完,所以我们把核心、重点的源码进行解读,RocketMQ核心流程如下:
- 启动流程RocketMQ服务端由两部分组成NameServer和Broker,NameServer是服务的注册中心,Broker会把自己的地址注册到NameServer,生产者和消费者启动的时候会先从NameServer获取Broker的地址,再去从Broker发送和接受消息。
- 消息生产流程Producer将消息写入到RocketMQ集群中Broker中具体的Queue。
- 消息消费流程Comsumer从RocketMQ集群中拉取对应的消息并进行消费确认。
NameServer设计亮点
存储基于内存
NameServer存储以下信息:
topicQueueTable:Topic消息队列路由信息,消息发送时根据路由表进行负载均衡
brokerAddrTable:Broker基础信息,包括brokerName、所属集群名称、主备Broker地址
clusterAddrTable:Broker集群信息,存储集群中所有Broker名称
brokerLiveTable:Broker状态信息,NameServer每次收到心跳包是会替换该信息
filterServerTable:Broker上的FilterServer列表,用于类模式消息过滤。

NameServer的实现基于内存,NameServer并不会持久化路由信息,持久化的重任是交给Broker来完成。这样设计可以提高NameServer的处理能力。
消息写入流程
RocketMQ使用Netty处理网络,broker收到消息写入的请求就会进入SendMessageProcessor类中processRequest方法。
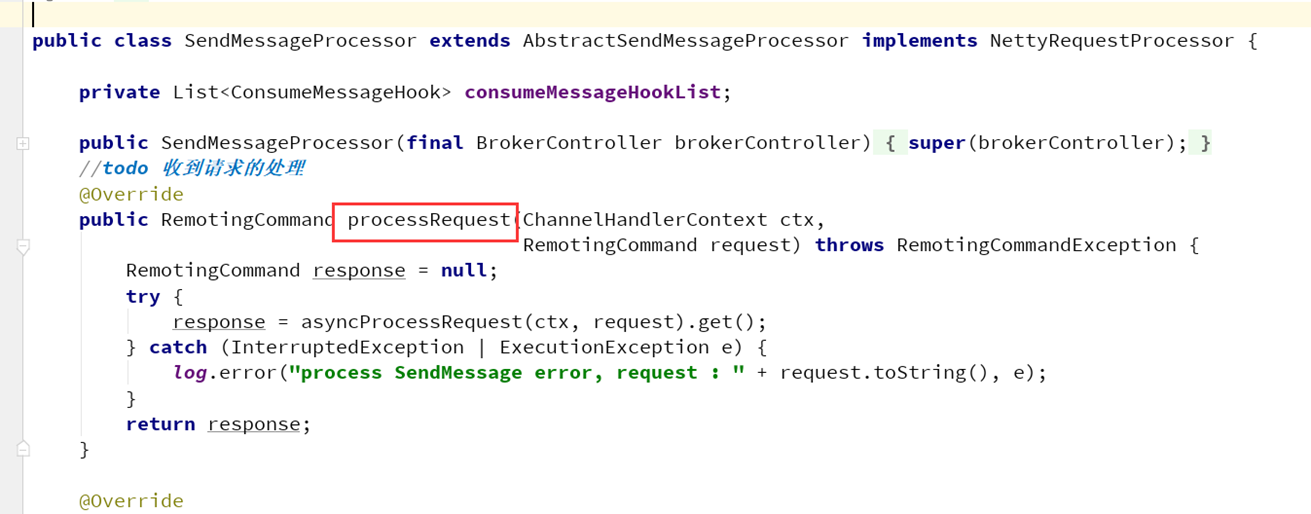
最终进入DefaultMessageStore类中asyncPutMessage方法进行消息的存储

然后消息进入commitlog类中的asyncPutMessage方法进行消息的存储
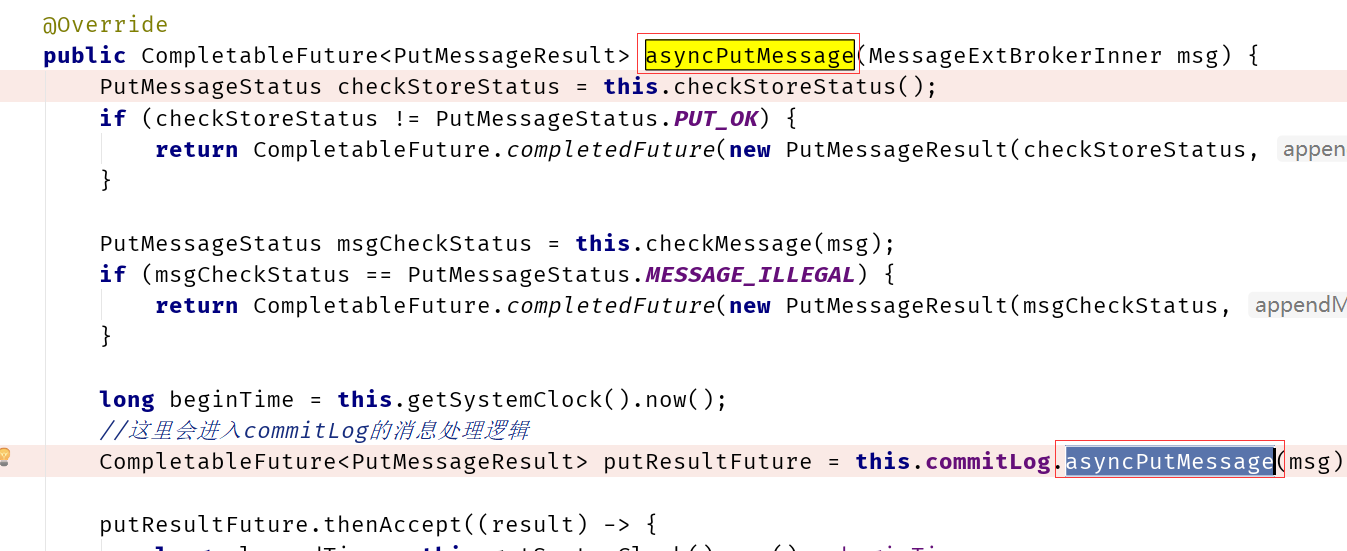
整个存储设计层次非常清晰,大致的层次如下图:
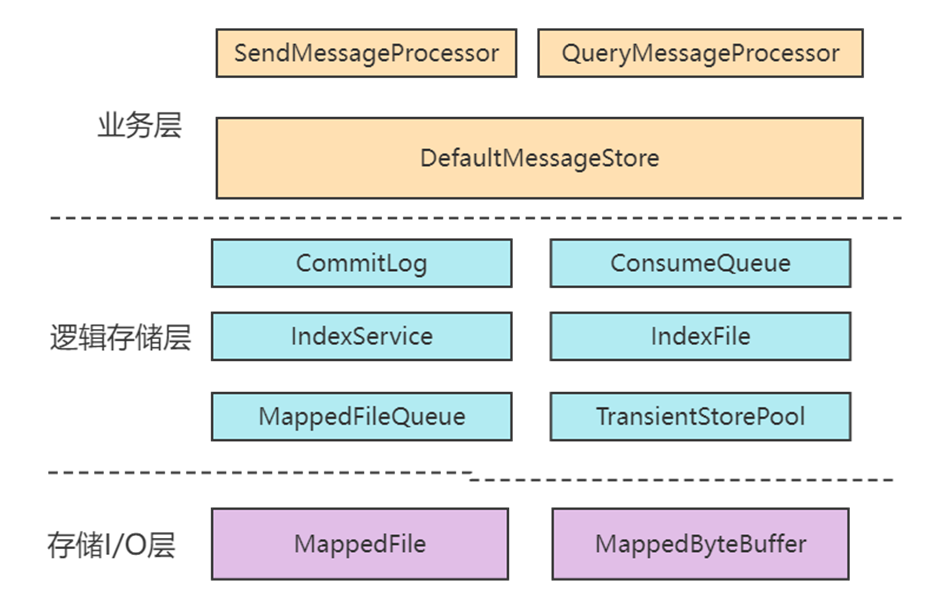
业务层:也可以称之为网络层,就是收到消息之后,一般交给SendMessageProcessor来分配(交给哪个业务来处理)。DefaultMessageStore,这个是存储层最核心的入口。
存储逻辑层:主要负责各种存储的逻辑,里面有很多跟存储同名的类。
存储I/O层:主要负责存储的具体的消息与I/O处理。
Commitlog写入时使用可重入锁还是自旋锁?
RocketMQ在写入消息到CommitLog中时,使用了锁机制,即同一时刻只有一个线程可以写CommitLog文件。CommitLog 中使用了两种锁,一个是自旋锁,另一个是重入锁。源码如下:


这里注意lock锁的标准用法是try-finally处理(防止死锁问题)
另外这里锁的类型可以自主配置。
RocketMQ 官方文档优化建议:异步刷盘建议使用自旋锁,同步刷盘建议使用重入锁,调整Broker配置项useReentrantLockWhenPutMessage,默认为false;

同步刷盘时,锁竞争激烈,会有较多的线程处于等待阻塞等待锁的状态,如果采用自旋锁会浪费很多的CPU时间,所以“同步刷盘建议使用重入锁”。
异步刷盘是间隔一定的时间刷一次盘,锁竞争不激烈,不会存在大量阻塞等待锁的线程,偶尔锁等待就自旋等待一下很短的时间,不要进行上下文切换了,所以采用自旋锁更合适。
Commitlog写入时使用可重入锁还是自旋锁?
RocketMQ在写入消息到CommitLog中时,使用了锁机制,即同一时刻只有一个线程可以写CommitLog文件。CommitLog 中使用了两种锁,一个是自旋锁,另一个是重入锁。源码如下:


这里注意lock锁的标准用法是try-finally处理(防止死锁问题)
另外这里锁的类型可以自主配置。
RocketMQ 官方文档优化建议:异步刷盘建议使用自旋锁,同步刷盘建议使用重入锁,调整Broker配置项useReentrantLockWhenPutMessage,默认为false;

同步刷盘时,锁竞争激烈,会有较多的线程处于等待阻塞等待锁的状态,如果采用自旋锁会浪费很多的CPU时间,所以“同步刷盘建议使用重入锁”。
异步刷盘是间隔一定的时间刷一次盘,锁竞争不激烈,不会存在大量阻塞等待锁的线程,偶尔锁等待就自旋等待一下很短的时间,不要进行上下文切换了,所以采用自旋锁更合适。