Go语言从入门到实战 — 并发篇
协程
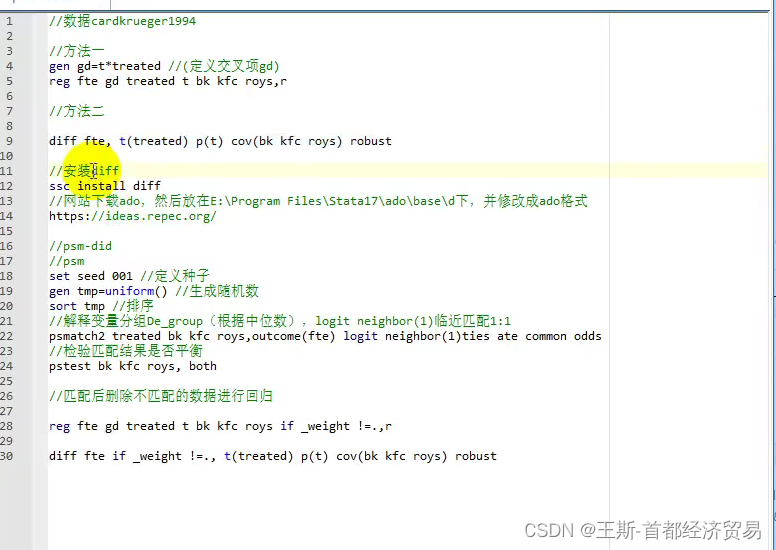
Thread vs Groutine

相比之下,协程的栈大小就小很多了,创建起来也会更快,也更节省系统资源。
一个 goroutine 的栈,和操作系统线程一样,会保存其活跃或挂起的函数调用的本地变量,但是和OS线程不太一样的是,一个 goroutine 的栈大小并不是固定的;栈的大小会根据需要动态地伸缩,初始化大小为 2KB。而 goroutine 的栈的最大值有1GB,比传统的固定大小的线程栈要大得多,尽管一般情况下,大多 goroutine 都不需要这么大的栈。

那么这种多对多的对应关系对我们程序有什么意义呢?
如果是1:1,那么我们的线程(Thread)是由我们的内核实体直接进行调度,这种方式,它的调度效率非常高,但是这里有一个问题,如果线程之间发生上下文切换时,会牵扯到内核对象的相互切换,这将是一个消耗非常大的事。
相对来说如果是多个协程由同一个内核实体来调度,那么协程之间的切换不涉及内核对象间的切换,在内部就能完成,它们之间的切换就会小非常多了,Go 也就是主打这个方面。
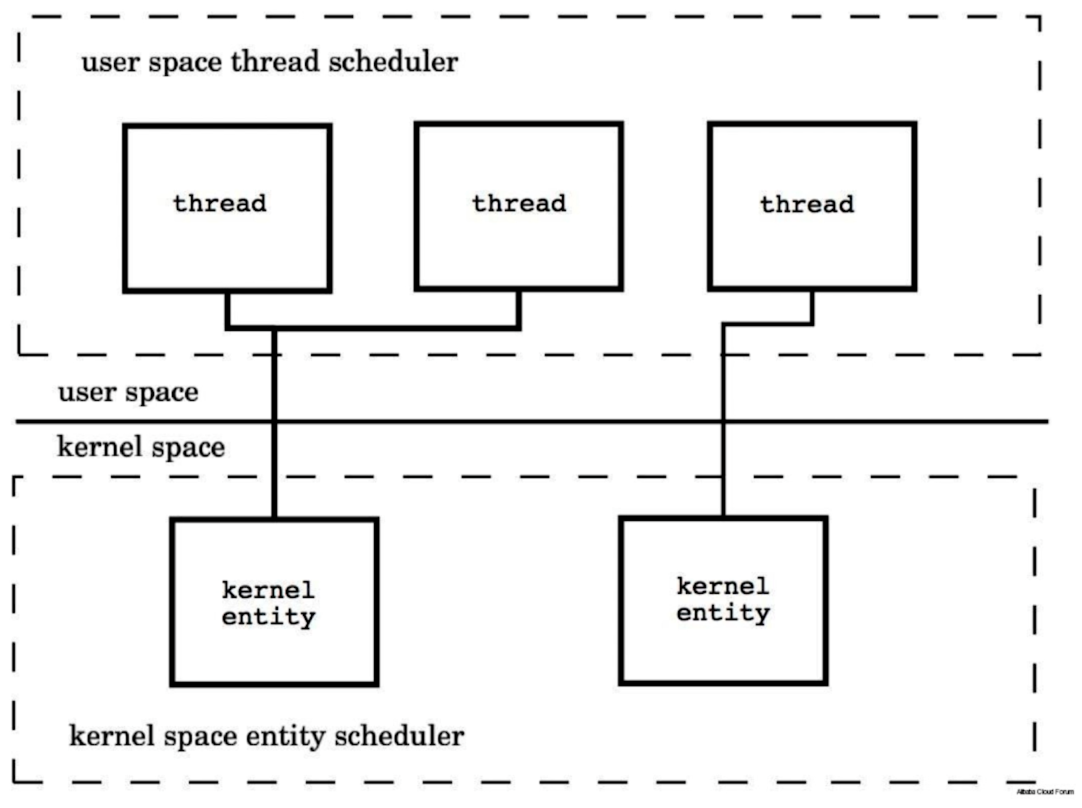
Go中的调度机制
Go 的协程处理器P(Processor)是挂在系统线程M(System thread)下面的,协程处理器P下面又挂有准备运行的协程队列(Goroutine), 每个协程队列中每次有一个协程G是是正在运行中的。
如果正在运行的协程执行时间特别长,会不会堵塞住协程队列呢?
Go 的处理机制是这样的,Go 在运行协程时,会启动一个守护线程去计数,计每个 Processor 完成的协程数量,当它发现一段时间后某个 Processor 完成的协程数量没有任何变化后,它就会往协程的任务栈里面插入一个特殊的标记,当协程运行遇到非内联函数时就会读到这个标记,就会把自己中断下来,插入到协程队列的队尾,然后切换到下一个协程继续运行。
另一个并发机制是这样的,当某个协程被系统中断了,例如 I/O 需要等待的时候,为了提高整体的并发,Processor 会把自己移动到另一个可使用的系统线程当中,继续执行它所挂的协程队列里面其它的协程。当上次中断的协程又被重新唤醒后,它会把自己加入其中一个 Processor 的等待队列,或者全局等待队列中。协程中断期间,它在寄存器中的运行状态,会保存在协程对象里,当协程再次有运行机会的时候,这些数据又会重新写入寄存器,然后继续运行。
大致我们可以知道这种协程机制与系统线程是多对多的关系,以及它是如何高效的利用系统线程,尽量多的运行并发的协程任务。
第一种:channel 阻塞或网络 I/O 情况下的调度
如果 G 被阻塞在某个 channel 操作或网络 I/O 操作上时,G 会被放置到某个等待(wait)队列中,而 M 会尝试运行 P 的下一个可运行的 G。如果这个时候 P 没有可运行的 G 供 M 运行,那么 M 将解绑 P,M 进入挂起状态。当 I/O 操作完成或 channel 操作完成,在等待队列中的 G 会被唤醒,标记为可运行(runnable),并被放入到某 P 的队列中,绑定一个 M 后继续执行。
第二种:系统调用阻塞情况下的调度
如果 G 被阻塞在某个系统调用(system call)上,那么不光 G 会阻塞,执行这个 G 的 M 也会解绑 P,M 与 G 一起进入挂起状态。如果此时有空闲的 M,那么 P 就会和它绑定,并继续执行其他 G;如果没有空闲的 M,但仍然有其他 G 要去执行,那么 Go 运行时就会创建一个新 M(线程)。
当系统调用返回后,阻塞在这个系统调用上的 G 会尝试获取一个可用的 P,如果没有可用的 P,那么 G 会被标记为 runnable(如果一直没有可用的 P,经过一定轮次后 G 会被放入到全局的 P 中),之前的那个挂起的 M 将再次进入挂起状态(M 经过一段时间后会进入空闲列表,重新获取可用的 P)。
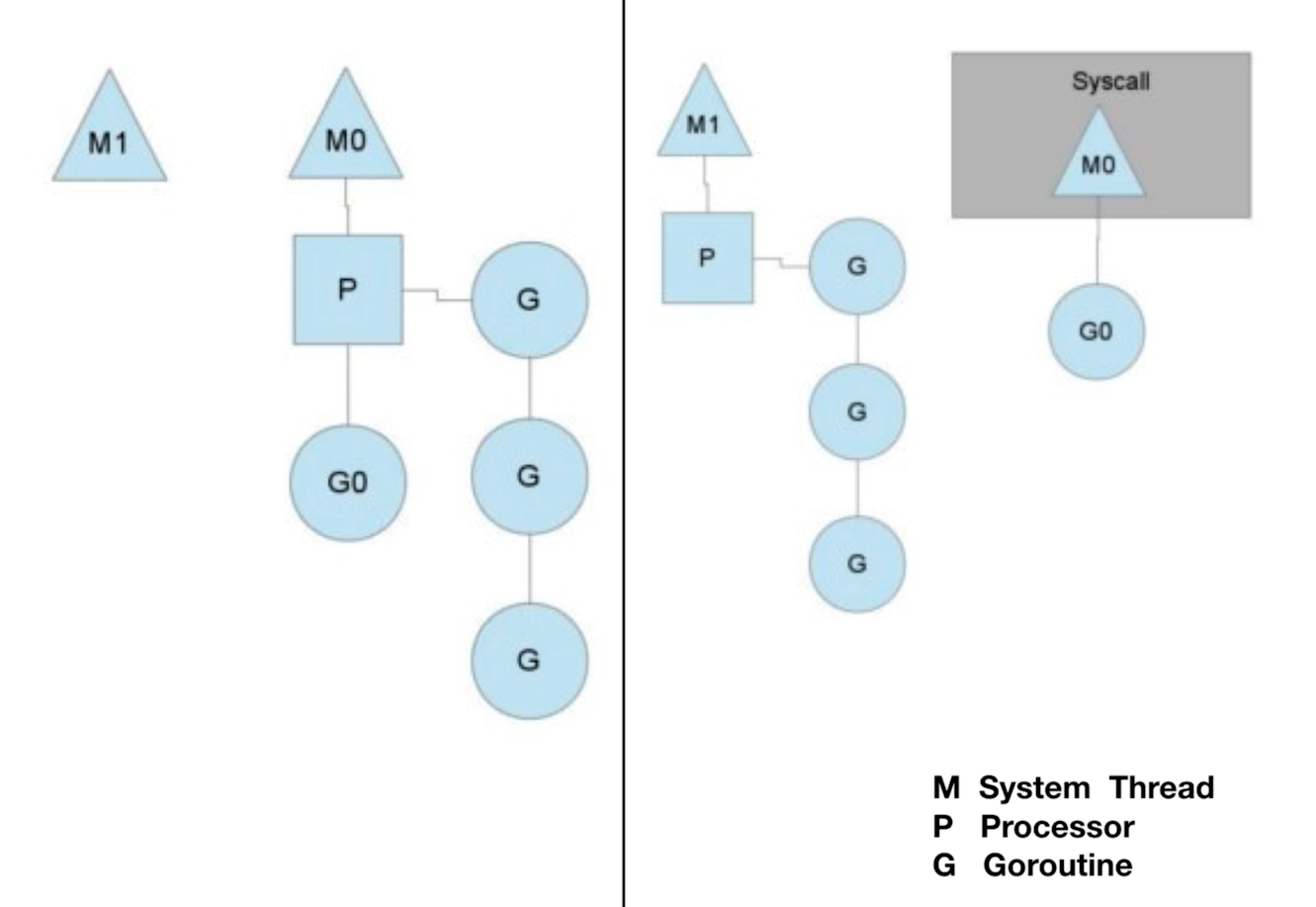
详细分析可参考该文:Go 协程(goroutine)调度原理
Go协程的使用
Go协程的使用很简单,只需要在方法前面加一个 go 关键字即可。
// Go 协程的使用
func TestGoroutine(t *testing.T) {for i := 0; i < 5; i++ {// 加到匿名函数前go func(i int) {fmt.Println(i)}(i)}time.Sleep(time.Millisecond * 50) // 让上面的程序先全部执行完
}

运行结果跟java创建多线程类似,协程被调用的顺序并不是按照方法的顺序来调度的。
共享内存并发机制
Lock
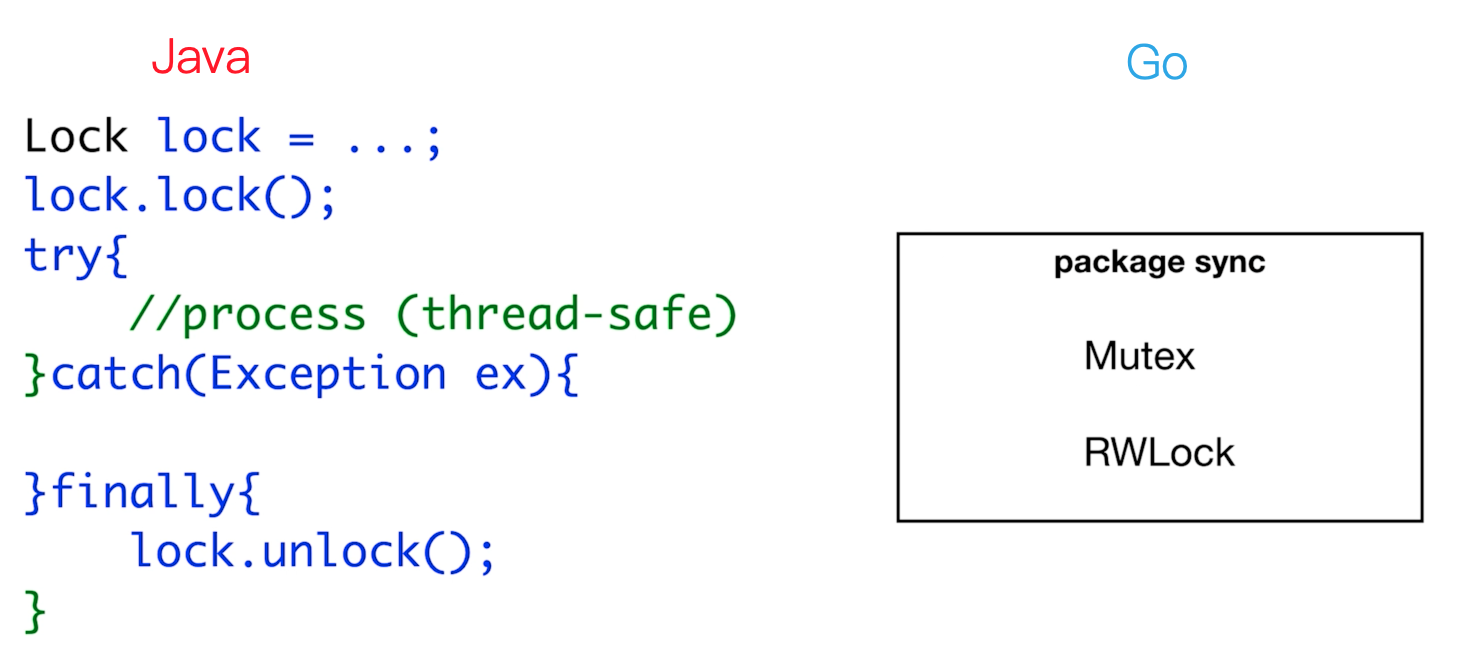
非线程安全
func TestCounter(t *testing.T) {counter := 0for i := 0; i < 5000; i++ {go func() {counter++ // 创建5000个协程,对counter自增了5000次 预期值为5000}()}time.Sleep(1 * time.Second) // 使上面的程序先执行完t.Logf("counter = %d", counter)
}
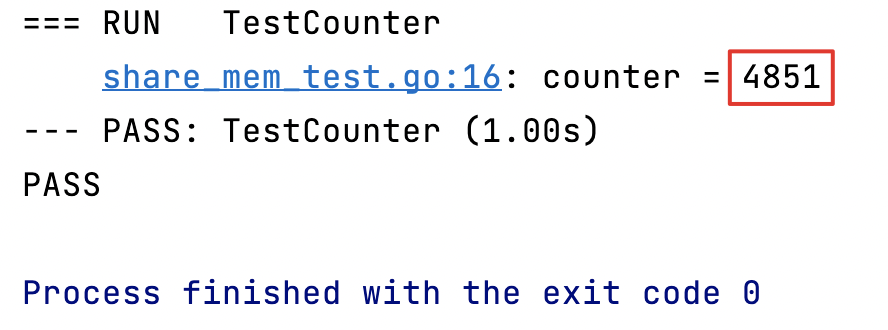
并没有达到我们5000的预期,这是因为我们使用的counter在不同的协程之间竞争,导致出现了并发竞争,也就是非线程安全的程序,出现了无效的写操作,如果我们要保证它的线程安全,就需要对这块共享内存加锁。
线程安全 sync.Mutex
func TestCounterSafe(t *testing.T) {var mut sync.Mutexcounter := 0for i := 0; i < 5000; i++ {go func() {// 锁的释放我们一般要写在defer中,类似java的finally。defer func() {mut.Unlock() // 在这个协程执行完的最后释放锁}()mut.Lock() // 加锁counter++}()}time.Sleep(1 * time.Second) // 使上面的程序先执行完t.Logf("counter = %d", counter)
}

达到了我们5000的预期。
WaitGroup
同步各个线程的方法,相当于java中的 join、CountDownLatch。
只有我 wait 的所有内容都完成后,程序才可以继续向下执行。
func TestCounterWaitGroup(t *testing.T) {var mut sync.Mutexvar wg sync.WaitGroupcounter := 0for i := 0; i < 5000; i++ {wg.Add(1) // 每启动1个协程,WaitGroup的数量就+1go func() {// 锁的释放我们一般要写在defer中,类似java的finally。defer func() {mut.Unlock() // 在这个协程执行完的最后释放锁}()mut.Lock() // 加锁counter++wg.Done() // 每执行完1个协程,WaitGroup的数量就-1}()}wg.Wait() // 如果WaitGroup中的数量不为0则一直等待t.Logf("counter = %d", counter)
}

那么 WaitGroup 为什么更好呢,可以看一下最后的执行时间,如果采用 time.Sleep(),因为我们并不知道5000个协程要执行多久,这个时间不好把控,我们为了得到正确的结果,人为预估了 1 秒,但是实际上只需要 0.00 秒就能执行完毕,故用 WaitGroup 即能防止错误的预估协程的执行时间,又能保证线程安全,是上上之选。
RWLock读写锁
它把读锁和写锁进行了分离,读不互质,写互斥,比 Mutex 完全互斥的效率高一些,更建议使用读写锁。
CSP并发机制
CSP(Communicating Sequential Processes)通信顺序进程,是一种消息传递模型,通过通道 channel 在 Goroutine 之间传递数据来传递消息,而不是对数据加锁来实现对数据的同步访问。
CSP VS Actor
Actor Model

- Actor 的机制是直接进行通讯,CSP 模式则是通过 channel 进行通讯的,更松耦合一些。
- Actor、Erlang 是通过 mailbox 来进行消息存储的,mailbox 的容量是无限的,Go 的 channel 是有容量限制的。
- Actor、Erlang 的接收进程总是被动地处理消息,Go 的协程会主动去处理从 channel 里面传过来的消息。

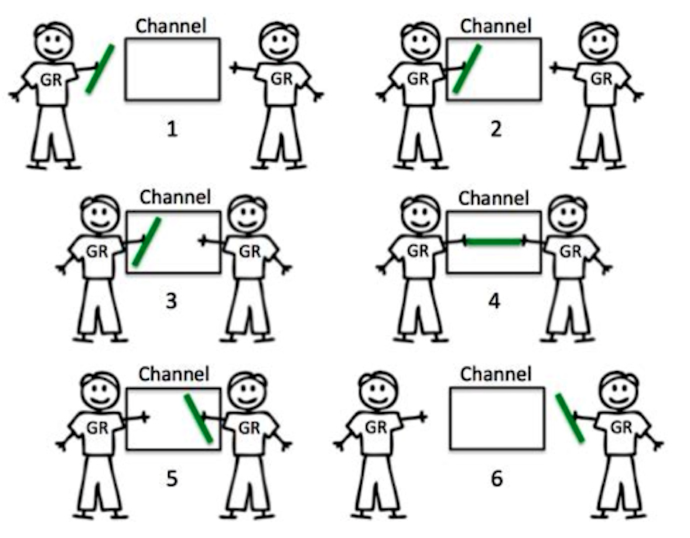
Channel
典型消息传输机制
进行通讯的发送方和接收方必须同时在 channel 上才能完成这次交互,任何一方不在都会导致另一方阻塞等待。
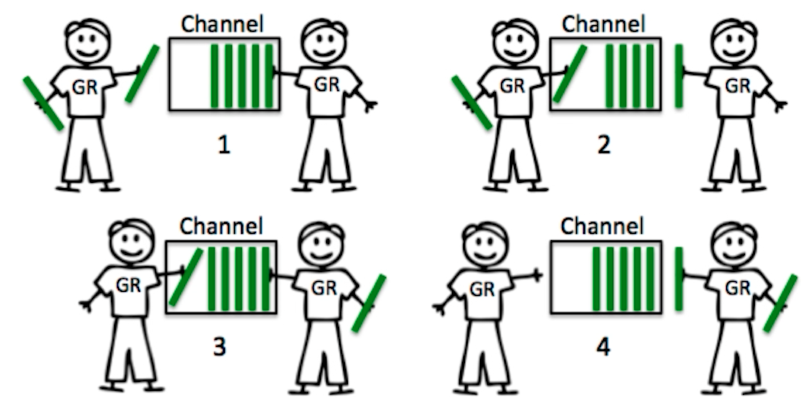
buffer channel机制
这种机制下,消息的发送方和接收方是更加松耦合的一种机制,我们可以给 channel 设定一个容量,只要在这个容量还没有满的情况下,放消息的人都是可以把消息放进去的,如果容量满了,则需要阻塞等待了,等到收消息的人拿走一个消息,放消息的人才能继续往里面放。同理,对收消息的人来说呢,只要这个 channel 里面有消息,就可以一直拿到,直到 channel 里面一个消息都没有了,就会阻塞等待,直到有新的消息进来。
异步返回
当我们调用一个任务,并不需要马上拿到它的返回结果,可以先去执行其它的逻辑,直到我们需要这个结果的时候,在去 get 这个结果。这将大大减少程序的整体运行时间,提升程序的效率。如果我们 get 这个任务的结果时,任务的结果还没有出来,就会堵塞在那里,直到拿到结果为止。
Java代码

同步(串行执行)
func service() string {time.Sleep(time.Millisecond * 50)return "service执行完成"
}func otherTask() {fmt.Println("otherTask的各种执行逻辑代码")time.Sleep(time.Millisecond * 100)fmt.Println("otherTask执行完成")
}// 测试同步执行效果, 先调用 service() 方法,在调用 otherTask() 方法,
// 理论上最后程序的执行时间为二者相加。
func TestService(t *testing.T) {fmt.Println(service())otherTask()
}
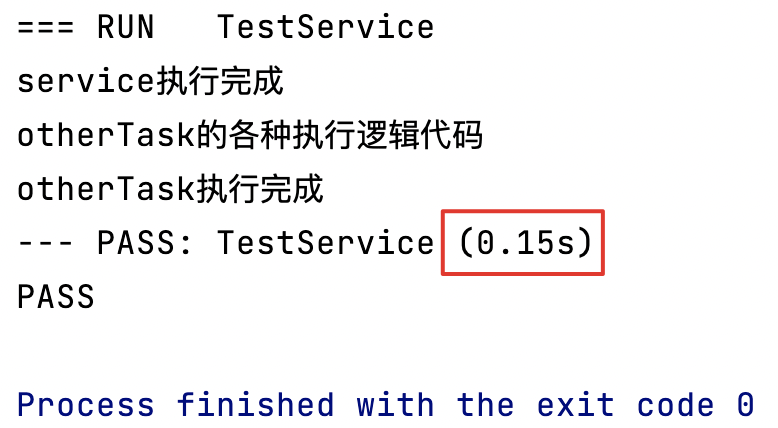
0.15s,符合预期。
典型 channel 异步返回
func service() string {time.Sleep(time.Millisecond * 50)return "service执行完成"
}func otherTask() {fmt.Println("otherTask的各种执行逻辑代码")time.Sleep(time.Millisecond * 100)fmt.Println("otherTask执行完成")
}func syncService() chan string {// 声明一个channel,数据只能存放 string 类型resCh := make(chan string)// 创建一个协程去执行service任务go func() {ret := service()fmt.Println("service 结果已返回")// 因为不是用的 buffer channel,所以,协程会被阻塞在这一步的消息传递过程中,// 只有接受者拿到了 channel 中的消息,channel 放完消息后面的逻辑才会被执行。resCh <- ret // 存数据,从 channel 里面存放数据都用这个 “<-” 符号fmt.Println("channel 放完消息后面的逻辑")}()return resCh
}// 异步返回执行结果,先调用 SyncService(),把它放入channel,用协程去执行,
// 然后主程序继续执行 otherTask(),最后把 SyncService() 的返回结果从 channel 里面取出来。
func TestSyncService(t *testing.T) {resCh := syncService()otherTask()fmt.Println(<-resCh) // 取数据,从 channel 里面存放数据都用这个 “<-” 符号
}

优化到 0.1s,说明 otherTask() 执行 0.1 秒,service() 因为只需要 0.05 秒,所以就提前执行完了,只需要在需要的地方取出结果就行,极大的减少了程序的整体执行时间。
- 从 channel 里面存放数据都用这个
“<-”符号 - 声明 channel:
make(chan string)
buffer channel 异步返回
我们会发现上面这中机制仍然有一个小问题,那就是 service() 执行完毕后,往 channel 里面放数据,此时协程就阻塞在这里了,需要等到接收者拿到消息,协程才会继续往下走,我们可不可以让协程不阻塞呢?当service() 执行完毕后,我们将消息放入 channel 中,然后继续执行其它的逻辑。答案是可以的,此时我们的 buffer channel 就派上用场了。
func service() string {time.Sleep(time.Millisecond * 50)return "service执行完成"
}func otherTask() {fmt.Println("otherTask的各种执行逻辑代码")time.Sleep(time.Millisecond * 100)fmt.Println("otherTask执行完成")
}// 异步执行 service(), 并将结果放入 buffer channel
func syncServiceBufferChannel() chan string {// 声明一个 channel,数据只能存放 string 类型// 后面的数字表示 buffer 的容量resCh := make(chan string, 1)go func() {ret := service()fmt.Println("service 结果已返回")// 此时使用的是 buffer channel,所以只要 service() 结果返回了,buffer容量未满// channel放完消息后面的逻辑就会被执行,不会被阻塞。resCh <- ret // 存数据,从 channel 里面存放数据都用这个 “<-” 符号fmt.Println("channel 放完消息后面的逻辑")}()return resCh
}// 异步返回执行结果,先调用 SyncService(),把它放入 buffer channel,用协程去执行,
// 此时协程不会被阻塞,然后主程序继续执行 otherTask(),
// 最后把 TestSyncServiceBufferChannel() 的返回结果从 channel 里面取出来。
func TestSyncServiceBufferChannel(t *testing.T) {resCh := syncServiceBufferChannel()otherTask()fmt.Println(<-resCh) // 取数据,从 channel 里面存放数据都用这个 “<-” 符号
}

我们会发现采用了 buffer channel 后,当 service() 的返回结果放入 buffer channel 后,协程并没有阻塞,而是继续执行了 “channel 放完消息后面的逻辑”,其它的结果和典型 channel 一致。
时间虽然同样也是 0.1s,但我们要知道如果任务非常多且执行的时间较长,则优化肯定是非常明显的。
多路选择和超时控制
select多路选择机制
select 的语法和 switch 的语法很类似,它的执行顺序并不一定是按照我们代码的前后关系来决定的,而是满足哪个 case ,就执行这个 case 的结果。如果所有的 channel 都处于阻塞中,则走 default。
select {
// 从 channel 上等待一个消息
case ret := <-retCh1:t.Logf("result:%s", ret)
// 从另一个 channel 上等待一个消息
case ret := <-retCh2:t.Logf("result:%s", ret)
// 如果所有的 channel 都处于阻塞中,则走 default
default:t.Error("No more returned")
}
超时控制
利用 select 的多路选择机制,我们可以实现一个超时机制,例如当某个 channel 多久后还没有消息返回,我们就返回超时。
select {
case ret := <-retCh1:t.Logf("result:%s", ret)
case ret := <-time.After(time.Second * 5):t.Error("time out")
}
time.After() 是在一段时间后, 它特定的 channel 会返回一个消息,当没有达到设定的时间,这个 case 会被阻塞在这,当超过了我们设定的 duration 后,这个 case 就能从 channel 里面拿到一个消息,这样就可以用来做超时控制。
func service() string {time.Sleep(time.Millisecond * 50)return "service执行完成"
}func otherTask() {fmt.Println("otherTask的各种执行逻辑代码")time.Sleep(time.Millisecond * 100)fmt.Println("otherTask执行完成")
}func syncService() chan string {// 声明一个channel,数据只能存放 string 类型resCh := make(chan string)// 创建一个协程去执行service任务go func() {ret := service()fmt.Println("service 结果已返回")// 因为不是用的 buffer channel,所以,协程会被阻塞在这一步的消息传递过程中,// 只有接受者拿到了 channel 中的消息,channel 放完消息后面的逻辑才会被执行。resCh <- ret // 存数据,从 channel 里面存放数据都用这个 “<-” 符号fmt.Println("channel 放完消息后面的逻辑")}()return resCh
}// 异步返回执行结果,先调用 SyncService(), 把它放入channel,用协程去执行,
// 然后主程序继续执行 otherTask(),最后把 SyncService() 的返回结果 从 channel 里面取出来。
func TestSyncService(t *testing.T) {select {case ret := <-syncService():otherTask()t.Logf("result:%s", ret)case <-time.After(time.Millisecond * 10):t.Error("time out")}
}

因为 service() 需要执行 0.05秒,我们设置了 0.01 秒就超时,所以就走了 time out。
channel的关闭和广播
不关闭 channel 会怎么样
写一个数据生产者和数据消费者的程序,数据生产者不断生产数据,消费者不断消费生产者生产的数据,通过 channel 交互。
// 数据生产者
func dataProducer(ch chan int, wg *sync.WaitGroup) chan int {wg.Add(1)go func() {for i := 0; i < 10; i++ {ch <- i}wg.Done()}()return ch
}// 数据消费者
func dataConsumer(ch chan int, wg *sync.WaitGroup) {wg.Add(1)go func() {for i := 0; i < 10; i++ {data := <-chfmt.Println(data)}wg.Done()}()
}// 数据消费者
func dataConsumer2(ch chan int, wg *sync.WaitGroup) {wg.Add(1)go func() {for i := 0; i < 10; i++ {data := <-chfmt.Println(data)}wg.Done()}()
}// channel还未关闭的场景
func TestChannelNotClosed(t *testing.T) {ch := make(chan int)var wg sync.WaitGroupdataProducer(ch, &wg)dataConsumer(ch, &wg)wg.Wait()
}
一旦我们生产的数据和消费的数据不一致时,比如生产者可以生成 11 个数,消费者仍然只消费 10 个数,或者生产者生成 10 个数,而消费者去消费 11 个数时,就会报下面的错误:

为了解决这种问题,Go 急需 channel 具有关闭功能,且关闭后会广播所有的订阅者。
channel 的关闭

语法格式
// 关闭 channel
close(channelName)// ok=true表示正常接收,false表示通道关闭
if val, ok := <-ch; ok {// other code
}
当 channel 已正常关闭,数据接收者还继续接收数据,则接收的数据为 channel 对应数据的默认值。
// 数据生产者
func dataProducer(ch chan int, wg *sync.WaitGroup) chan int {wg.Add(1)go func() {for i := 0; i < 10; i++ {ch <- i}// 关闭 channelclose(ch)//ch <- 11 // 向关闭的 channel 发送消息,会报 panic: send on closed channelwg.Done()}()return ch
}// 数据消费者
func dataReceiver(ch chan int, wg *sync.WaitGroup) {wg.Add(1)go func() {// 我们这里多接收一个数据,看看拿到的值是什么for i := 0; i < 11; i++ {data := <-chfmt.Print(data, " ")}wg.Done()}()
}// 关闭channel
func TestCloseChannel(t *testing.T) {ch := make(chan int)var wg sync.WaitGroupdataProducer(ch, &wg)dataReceiver(ch, &wg)wg.Wait()
}
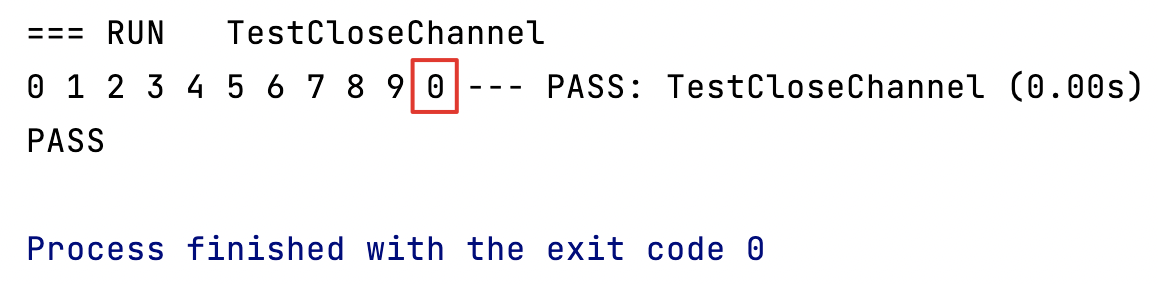
我们会发现,当 channel 已关闭后,我们多接收了一个值,由于我们 channel 定义的数据类型为 int,则拿到的数据类型将是 int 型的默认值 0。
一般我们的 1 个 channel 可能对应多个消费者,所以当这个 channel 关闭后,广播机制就会经常被使用,通知所有消费者该 channel 已经被关闭了。
任务的取消
传统的方案是,假设一段任务在执行,我们通过设置共享内存的一个变量的值为 true 或者 false 来进行判断。现在我们将利用 CSP, select 多路选择机制和 channel 的关闭与广播实现任务取消功能。
实现原理
- 通过 CSP 在 channel 上广播一个消息,告诉所有的协程,大家现在可以停了。
如何判断
- 通过 select 多路选择机制,如果从 channel 上收到一个消息,代表需要执行任务取消功能,否则不执行。
代码示例
// 任务是否已被取消
// 实现原理:
// 检查是否从 channel 收到一个消息,如果收到一个消息,我们就返回 true,代表任务已经被取消了
// 当没有收到消息,channel 会被阻塞,多路选择机制就会走到 default 分支上去。
func isCanceled(cancelChan chan struct{}) bool {select {case <-cancelChan:return truedefault:return false}
}// 执行任务取消
// 因为 close() 是一个广播机制,所以所有的协程都会收到消息
func execCancel(cancelChan chan struct{}) {// close(cancelChan)会使所有处于处于阻塞等待状态的消息接收者(<-cancelChan)收到消息close(cancelChan)
}// 利用 CSP,多路选择机制和 channel 的关闭与广播实现任务取消功能
func TestCancel(t *testing.T) {var wg sync.WaitGroupcancelChan := make(chan struct{}, 0)// 启动 5 个协程for i := 0; i < 5; i++ {wg.Add(1)go func(i int, cancelChan chan struct{}, wg *sync.WaitGroup) {// 做一个 while(true) 的循环,一直检查任务是否有被取消for {if isCanceled(cancelChan) {fmt.Println(i, "is Canceled")wg.Done()break} else {// 其它正常业务逻辑time.Sleep(time.Millisecond * 5)}}}(i, cancelChan, &wg)}// 执行任务取消execCancel(cancelChan)wg.Wait()
}

所有的协程都被取消了。
close() 是一个广播机制,会使所有处于处于阻塞等待状态的消息接收者收到消息。
Context与任务取消
关联任务的取消
场景:当我们启动了多个子任务的同时,子任务还有子任务的时,产生了关联:
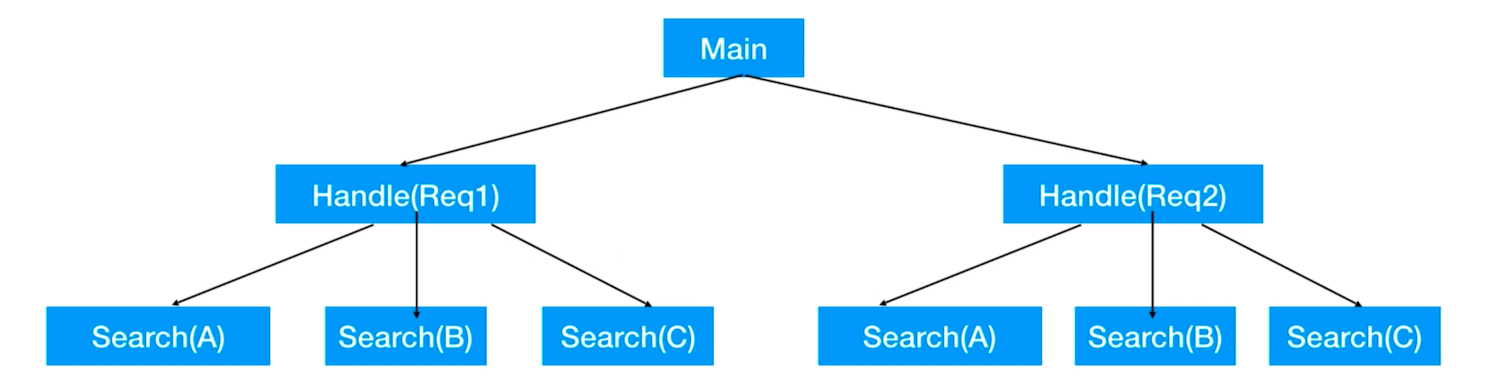
如果我们只是想要取消掉一个叶子节点的任务时,那利用 CSP,select 多路选择机制和 channel 的关闭与广播就可以实现。
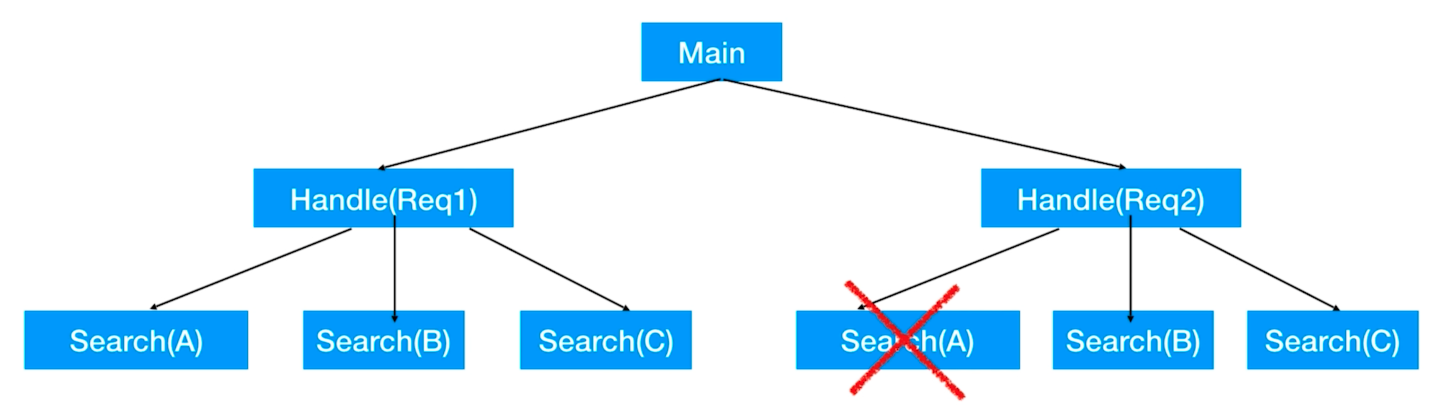
但是我们现在的场景是当我们取消掉父节点的任务时,想要把子节点的全部任务也一起取消掉,那该如何实现呢?
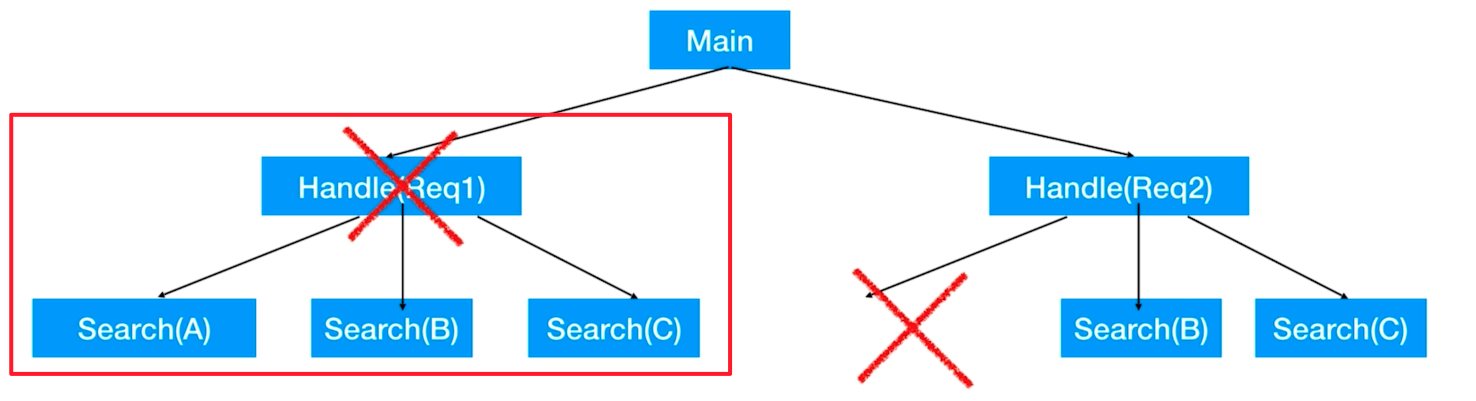
当然我们可以自己来实现,但在 Golang 的 1.9 以后就把 Context 正式并入Go的内置包里面了,它就是专门来做这件事的。
Context

ctx, cancel := context.WithCancel(context.Background())
context.WithCancel() 方法,把根节点 context.Background() 传进去之后,返回的一个是 ctx ,一个是 cancel 方法,调用 cancel 方法则执行取消功能。而 ctx 可传到子任务里面,用来取消子任务,从而实现父节点和子任务都被取消掉。取消的通知形式是通过 ctx.Done() 来获得消息,从而判断是否收到通知。这个 ctx.Done() 就类比 channel 里面 close() 之后,所有的 channel 都会收到一个通知。
代码实现
// 任务是否已被取消
// 实现原理:
// 通过 ctx.Done() 接收context的消息,如果收到消息,我们就返回 true,代表任务已经被取消了
// 当没有收到消息,多路选择机制就会走到 default 分支上去。
func isCanceled(ctx context.Context) bool {select {case <-ctx.Done():return truedefault:return false}
}// 通过context实现任务取消功能
func TestCancel(t *testing.T) {var wg sync.WaitGroup// ctx传到子节点中去,可以取消子节点,调用cancel()方法则执行取消功能ctx, cancel := context.WithCancel(context.Background())// 启动 5 个协程for i := 0; i < 5; i++ {wg.Add(1)go func(i int, ctx context.Context, wg *sync.WaitGroup) {// 做一个 while(true) 的循环,一直检查任务是否有被取消for {if isCanceled(ctx) {fmt.Println(i, "is Canceled")wg.Done()break} else {// 其它正常业务逻辑time.Sleep(time.Millisecond * 5)}}}(i, ctx, &wg)}// 执行任务取消cancel()wg.Wait()
}
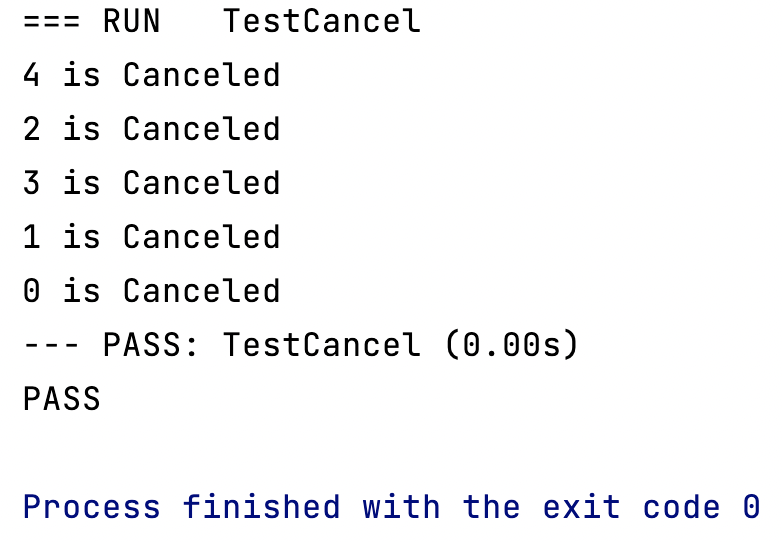
协程都被取消了,符合预期。
并发任务
只执行一次 - 单例模式
- Java代码 - 单例模式 - 懒汉式 - 线程安全(double check)

-
Go代码
sync.Once()能确保里面的Do()方法在多线程的情况下只会被执行一次。type Singleton struct { }var singleInstance *Singleton var once sync.Once// 获取一个单例对象 func GetSingletonObj() *Singleton {once.Do(func() {fmt.Println("Create a singleton Obj")singleInstance = new(Singleton)})return singleInstance }// 启动多个协程,测试我们单例对象是否只创建了一次 func TestGetSingletonObj(t *testing.T) {var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func() {obj := GetSingletonObj()fmt.Printf("%x\n", unsafe.Pointer(obj))wg.Done()}()}wg.Wait() }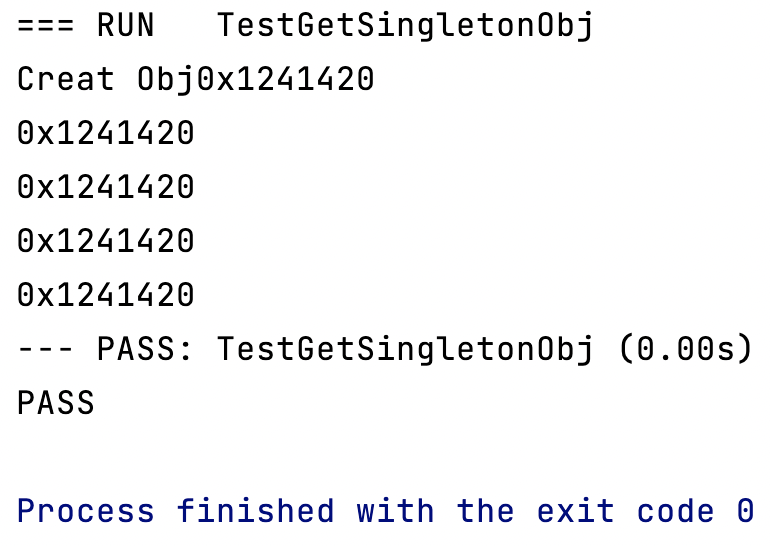
可以看到
Do()方法中输出内容只打印了一次,多个协程拿到的地址值都相同,实现单例模式。
仅需任意任务完成
当我们需要执行许多并发任务,但是只要任意一个任务执行完毕,就可以将结果返回给用户。例如我们同时向百度和 google 去搜索某一个搜索词,任何一个搜索引擎第一个返回,我们就可以把结果返回给用户了,不需要所有场景都返回。
- 这里我们利用 CSP 的机制实现这个模式
// 从网站上执行搜索功能
func searchFromWebSite(webSite string) string {time.Sleep(10 * time.Millisecond)return fmt.Sprintf("search from %s", webSite)
}// 收到第一个结果后立刻返回
func FirstResponse() string {var arr = [2]string{"baidu", "google"}// 防止协程泄露,这里用 buffer channel 很重要,否则可能导致剩下的协程会被阻塞在那里,// 当阻塞的协程达到一定量后,最终可能导致服务器资源耗尽而出现重大故障ch := make(chan string, len(arr))for _, val := range arr {go func(v string) {// 拿到所有结果放入 channelch <- searchFromWebSite(v)}(val)}// 这里没有使用 WaitGroup,因为我们的需求是当 channel 收到第一个消息后就立刻返回return <-ch
}func TestFirstResponse(t *testing.T) {t.Log("Before:", runtime.NumGoroutine()) // 输出当前系统中的协程数t.Log(FirstResponse())t.Log("After:", runtime.NumGoroutine()) // 输出当前系统中的协程数
}
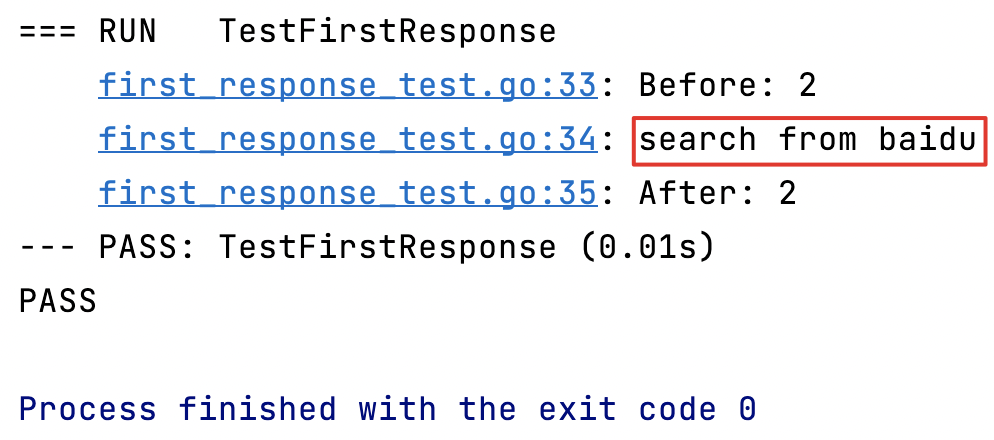
所有任务完成
有时候我们需要所有任务都完成才进入下一个环节,当我们下单成功后,只有积分和优惠券都赠送了才显示所有优惠赠送成功。
这个模式当然可以用 WaitGroup 实现,但我们这里再使用 CSP 机制实现。
// 送豪礼方法
func sendGift(gift string) string {time.Sleep(10 * time.Millisecond)return fmt.Sprintf("送%s", gift)
}// 使用 CSP 拿到所有的结果才返回
func CspAllResponse() []string {var arr = [2]string{"优惠券", "积分"}// 防止协程泄露,这里用 buffer channel 很重要,否则可能导致剩下的协程会被阻塞在那里,// 当阻塞的协程达到一定量后,最终可能导致服务器资源耗尽而出现重大故障ch := make(chan string, len(arr))for _, val := range arr {go func(v string) {// 拿到所有结果放入 channelch <- sendGift(v)}(val)}var finalRes = make([]string, len(arr), len(arr))// 等到所有的的协程都执行完毕,把结果一起返回for i := 0; i < len(arr); i++ {finalRes[i] = <-ch}return finalRes
}func TestAllResponse(t *testing.T) {t.Log("Before:", runtime.NumGoroutine())t.Log(CspAllResponse())t.Log("After:", runtime.NumGoroutine())
}

对象池
在我们日常的开发中,经常会有像数据库连接,网络连接等,我们经常需要把它们池化,以免对象被重复创建。在 Go 语言中我们可以使用 buffered channel 实现对象池,通过设定 buffer 的大小来设定池的大小,我们可以从这个 buffer 池中拿到一个对象,用完了再还到 channel 上。
// 可重用对象,比如连接等
type Reusable struct {
}// 对象池
type ObjPool struct {bufChan chan *Reusable // 用于缓存可重用对象
}// 创建一个包含多个可重用对象的对象池
func NewObjPool(numOfObj int) *ObjPool {// 声明对象池objPool := ObjPool{}// 初始化 objPool.bufChan 为一个 channelobjPool.bufChan = make(chan *Reusable, numOfObj)// 往 objPool 对象池里面放多个可重用对象for i := 0; i < numOfObj; i++ {objPool.bufChan <- &Reusable{}}return &objPool
}// 从对象池拿到一个对象
func (objPool *ObjPool) GetObj(timeout time.Duration) (*Reusable, error) {select {case ret := <-objPool.bufChan:return ret, nilcase <-time.After(timeout): // 超时控制return nil, errors.New("time out")}
}// 将可重用对象还回对象池
func (objPool *ObjPool) ReleaseObj(ReusableObj *Reusable) error {select {case objPool.bufChan <- ReusableObj:return nildefault:return errors.New("overflow") // 超出可重用对象池容量}
}// 从对象池里面拿出对象,用完了再放回去
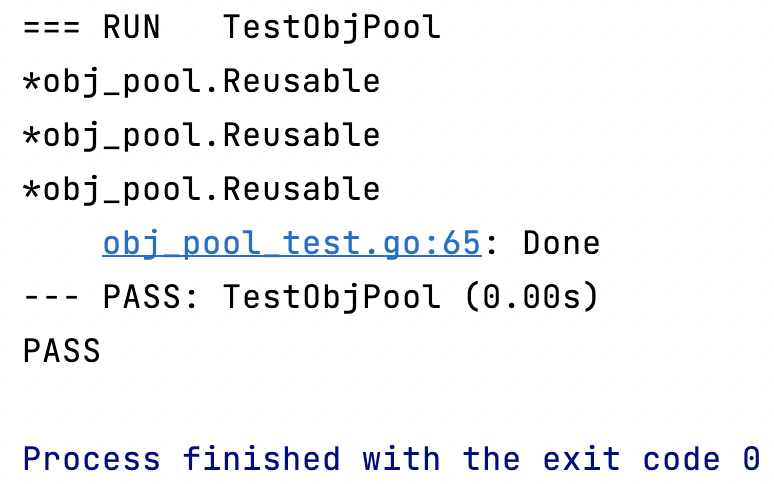
func TestObjPool(t *testing.T) {pool := NewObjPool(3)for i := 0; i < 3; i++ {if obj, err := pool.GetObj(time.Second * 1); err != nil {t.Error(err)} else {fmt.Printf("%T\n", obj)if err := pool.ReleaseObj(obj); err != nil {t.Error(err)}}}t.Log("Done")
}
sync.Pool 对象缓存
其实 sync.Pool 并不是对象池的类,而是个对象缓存,叫 sync.Cache 更贴切。
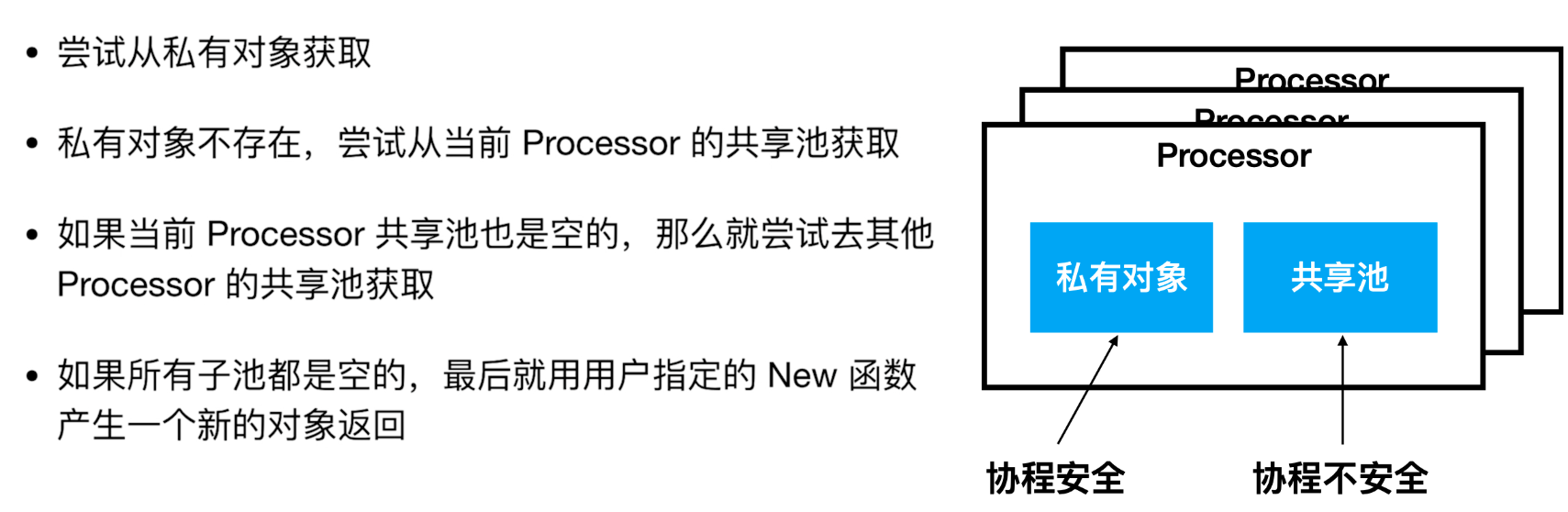
sync.Pool 有两个重要的概念,私有对象和共享池:
- 私有对象:协程安全,写入的时候不需要锁。
- 共享池:协程不安全,写入的时候需要锁。
它们两个存放在我们之前讲过的 Processor 中。
sync.Pool 对象获取
sync.Pool 对象放回

sync.Pool 的生命周期

这也就是为什么不能拿它来当对象池用。
使用 sync.Pool
伪代码
// 使用 New 关键字创建新对象
pool := &sync.Pool{New: func() interface{} {return 0},
}// 从 pool 中获取一个对象,因为返回的是空接口interface{},所以要自己做断言
array := pool.Get().(int)// 往 pool 中放入一个对象
pool.Put(10)
基本使用
// 调试 sync.Pool 对象
func TestSyncPool(t *testing.T) {pool := &sync.Pool{New: func() interface{} {fmt.Println("Create a new object")return 1},}// 第一次从池中获取对象,我们知道它一定是空的,所有肯定会调用 New 方法去创建一个新对象v := pool.Get().(int)fmt.Println(v) // 1// 放一个不存在的对象,它会优先放入私有对象pool.Put(2)// 此时私有对象已经存在了,所以会优先拿到私有对象的值v1 := pool.Get().(int)fmt.Println(v1) // 2// 模拟系统调用GC, GC会清除 sync.pool中缓存的对象//runtime.GC()
}

过程中发生一次 GC:
// 调试 sync.Pool 对象
func TestSyncPool2(t *testing.T) {pool := &sync.Pool{New: func() interface{} {fmt.Println("Create a new object")return 1},}// 第一次从池中获取对象,我们知道它一定是空的,所有肯定会调用 New 方法去创建一个新对象v := pool.Get().(int)fmt.Println(v) // 1// 放一个不存在的对象,它会优先放入私有对象pool.Put(2)// 模拟系统调用GC, GC会清除 sync.pool中缓存的对象runtime.GC()// 此时私有对象已经被GC掉了,所以这里又新建了一次对象v1 := pool.Get().(int)fmt.Println(v1) // 1
}

创建了 2 次新对象,符合预期。
注意:使用
Get()方法新创建的对象是不会放入到私有对象中的,只有Put()方法才会放到私有对象中。
在多协程中的应用
// 调试 sync.Pool 在多个协程中的应用场景
func TestSyncPoolInMultiGoroutine(t *testing.T) {pool := sync.Pool{New: func() interface{} {fmt.Println("Create a new object")return 0},}pool.Put(1)pool.Put(2)pool.Put(3)var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func() {v, _ := pool.Get().(int)fmt.Println(v)wg.Done()}()}wg.Wait()
}

sync.Pool 总结

单元测试
内置单元测试框架

func TestErrorInCode(t *testing.T) {fmt.Println("Start")t.Error("Error")fmt.Println("End")
}func TestFailInCode(t *testing.T) {fmt.Println("Start")t.Fatal("Error")fmt.Println("End")
}
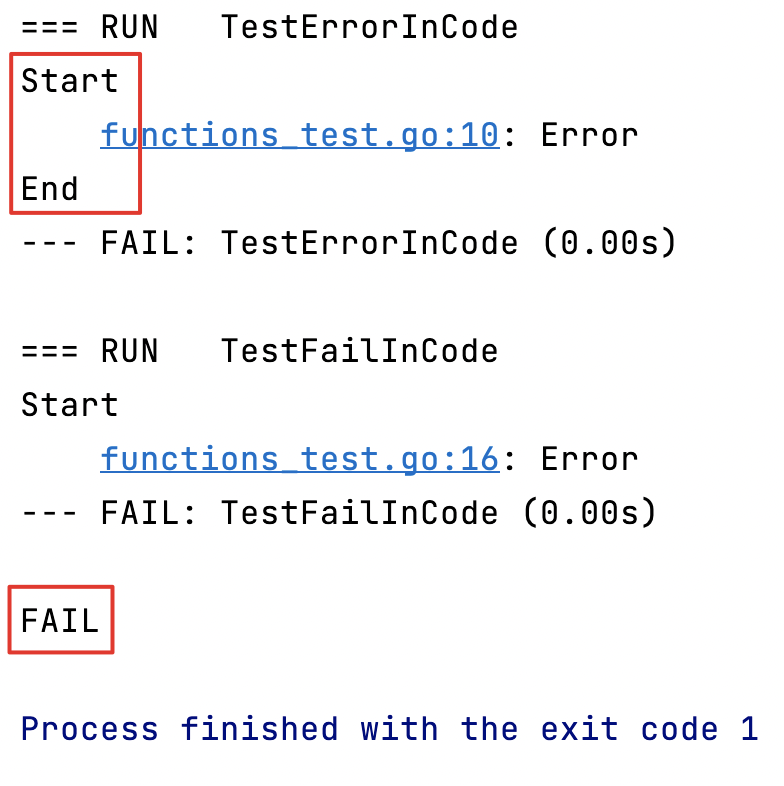
使用 Error 的测试方法,测试继续执行,使用 Fatal 的测试方法,测试中断。
显示代码覆盖率
go test -v -cover
断言
https://github.com/stretchr/testify
安装 assert:
go get -u github.com/stretchr/testify
// 平方 故意+1计算错误,使断言生效
func square(num int) int {return num * num + 1
}// 表格测试法
func TestSquare(t *testing.T) {// 输入值inputs := [...]int{1, 2, 3}// 期望值expected := [...]int{2, 4, 9}for i := 0; i< len(inputs); i++ {ret := square(inputs[i])// 调用 assert 断言包assert.Equal(t, expected[i], ret)}
}

Benchmark
用途
- 对程序中某些代码片段的进行一个性能测评,比较一下哪种写法会更好一些。
- 对第三方库进行一个测评,看哪个库性能更好一些。
使用示例
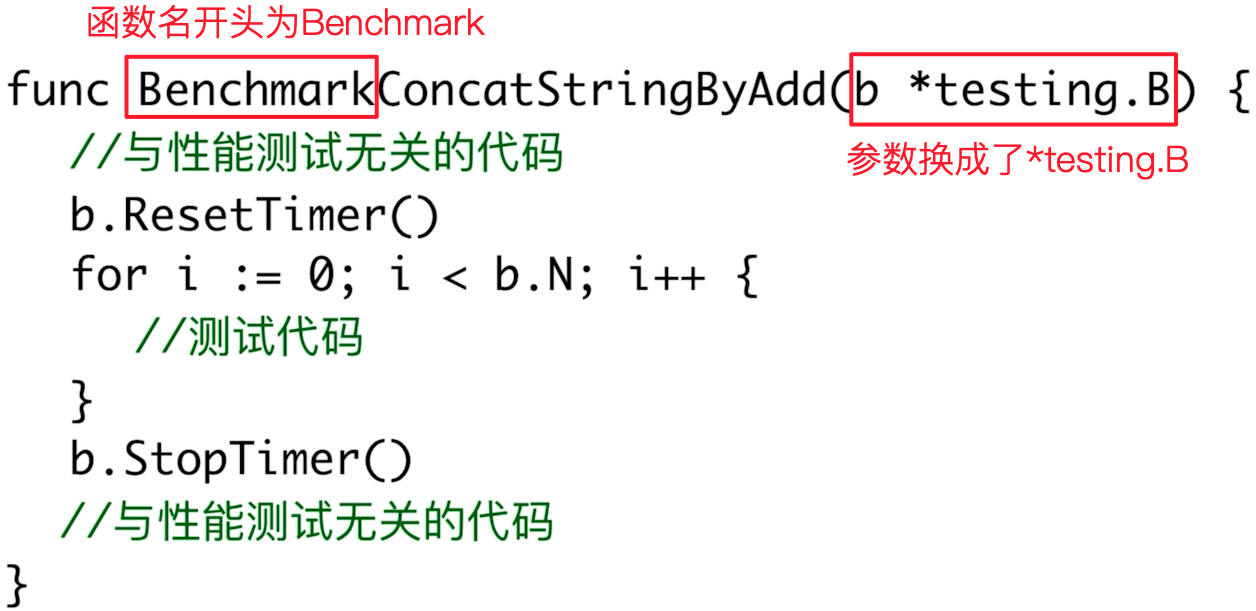
用 b.ResetTimer() 和 b.StopTimer() 来隔离与性能测试无关的代码。
代码测试:比较字符串拼接的性能
// 通过“+=”的方式拼接字符串
func ConcatStringByLink() string {elements := [...]string{"1", "2", "3", "4", "5", "6", "7", "8", "9", "10","11", "12", "13", "14", "15", "16", "17", "18", "19", "20"}str := ""for _, elem := range elements {str += elem}return str
}// 通过字节数组 bytes.buffer 拼接字符串
func ConcatStringByBytesBuffer() string {elements := [...]string{"1", "2", "3", "4", "5", "6", "7", "8", "9", "10","11", "12", "13", "14", "15", "16", "17", "18", "19", "20"}var buf bytes.Bufferfor _, elem := range elements {buf.WriteString(elem)}return buf.String()
}// 用benchmark测试字符串拼接方法的性能
func BenchmarkConcatStringWithLink(b *testing.B) {// 与性能测试无关的代码的开始位置b.ResetTimer()for i := 0; i < b.N; i++ {ConcatStringByLink()}// 与性能测试无关代码的结束为止b.StopTimer()
}// 用 benchmark 测试 bytes.buffer 连接字符串的性能
func BenchmarkConcatStringWithByteBuffer(b *testing.B) {// 与性能测试无关的代码的开始位置b.ResetTimer()for i := 0; i < b.N; i++ {ConcatStringByBytesBuffer()}// 与性能测试无关代码的结束为止b.StopTimer()
}| 方式 | 代码运行次数 | 单次运行时间 |
|---|---|---|
使用 += 拼接 | 1813815 | 649.9 ns/op |
使用 bytes.Buffer 拼接 | 6804018 | 172.6 ns/op |
这只是拼接了 20 个字符串,如果拼接的字符串更多,则差距会更加明显。
原生命令
// -bench= 后面跟方法名,如果是所有方法就写"."
go test -bench=.// 注意:windows下使用 go test 命令时, -bench=.应该写成 -bench="."// 如果想知道 代码每一次的内存分配情况,这种方案为什么快,那种方案为什么慢,可以加一个-benchmem参数
go test -bench=. -benchmem

通过 += 的方式我们总共使用 allocs 分配了 19 次空间,而通过 byte.Buffer 只分配了一次,性能提升在这里。
BDD
BDD(Behavior Driven Development),行为驱动开发。
为了让我们和客户间的沟通更加顺畅,我们会用同一种“语言”来描述一个系统,避免表达不一致的问题,当出现了什么行为,会出现什么结果。


BDD in Go
goconvey 项目网站:
https://github.com/smartystreets/goconvey/
安装
go get -u github.com/smartystreets/goconvey/convey
代码示例
package bddimport ("testing"// 前面这个"."点,表示将import进来的package的方法是在当前名字空间的,可以直接使用里面的方法// 例如使用 So()方法,就可以直接用,不用写成 convey.So(). "github.com/smartystreets/goconvey/convey"
)// BDD框架 convey的使用
func TestSpec(t *testing.T) {Convey("Given 2 even numbers", t, func() {a := 3b := 4Convey("When add the two numbers", func() {c := a + bConvey("Then the result is still even", func() {So(c%2, ShouldEqual, 0) // 判断c % 2是否为 0})})})
}

启动 WEB UI
~/go/bin/goconvey

Web 界面非常友好:
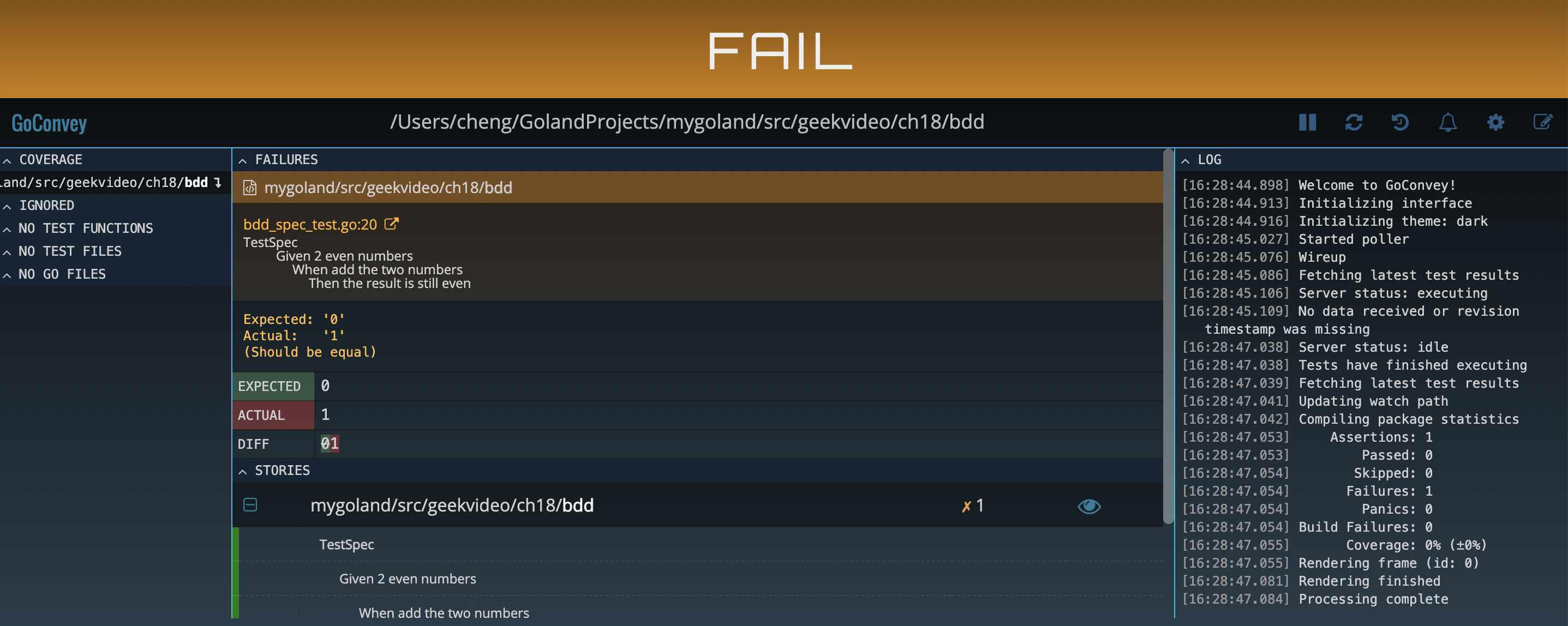
如果端口冲突了,可以这样解决
~/go/bin/goconvey -port 8081
笔记整理自极客时间视频教程:Go语言从入门到实战