使用Debate Dynamics在知识图谱上进行推理
- 摘要
- 介绍
- 背景与相关工作
- 我们的方法
- 状态
- action
- 环境
- policies
- Debate Dynamics
- 裁判

摘要
我们提出了一种新的基于 Debate Dynamics 的知识图谱自动推理方法。
其主要思想是将三重分类任务定义为两个强化学习主体之间的辩论游戏,这两个主体提取论点(知识图中的路径),目的是分别促进事实为真(命题)或事实为假(对立面)。基于这些论点,一个二元分类器(称为裁判)决定事实是真是假。这两个代理可以被认为是稀疏的。对抗性特征生成器(Adversarial Feature Generator),为正题或反题提供可解释的证据。与其他黑盒方法相比,这些论点允许用户了解法官的决定。
由于这项工作的重点是创建一种可解释的方法,以保持有竞争力的预测准确性,我们将我们的方法以三重分类和链接预测任务为基准。因此,我们发现我们的方法在基准数据集FB15k-237、WN18RR和Hetionet上优于几个基线。我们还进行了一项调查,发现提取的论点对用户来说是有信息的。
Debate Dynamics是一种用于推理的框架。它的主要目的是从知识图谱中自动提取和评估论点,以支持决策制定和信息检索等任务。
Debate Dynamics可以自动从知识图谱中提取论点,并将它们表示为辩论图,该图包括论点和它们之间的关系。然后,它将辩论图输入到论证框架中,该框架使用论证理论来生成反驳和评估论点的强度。最后,它可以根据论证框架的结果做出决策。
Debate Dynamics的优势在于它可以处理复杂的知识图谱,并自动提取和评估论点。它还可以支持多种论证框架,因此可以应用于各种不同的问题领域,例如自然语言处理、信息检索和决策支持系统等。
Adversarial Feature Generator(对抗特征生成器)
是一种机器学习技术,通常用于生成能够欺骗分类器的特征。它的基本思想是通过训练两个对抗的神经网络,一个生成器和一个判别器,从噪声中生成具有特定特征的样本,以欺骗判别器,使它无法准确识别样本的真实标签。
在Adversarial Feature Generator中,生成器试图生成具有与真实样本类似的特征,而判别器则试图区分生成的特征与真实样本的特征。这两个神经网络通过反复训练来提高自己的表现,直到生成器可以生成与真实样本无法区分的特征为止。
介绍
关于现实世界的各种信息可以用实体及其关系来表达。
知识图谱(KGs)以三元组(s,p,o)的形式存储关于世界的事实,其中s(主体)和o(对象)对应于图中的节点,p(谓词)表示连接两者的边类型。KG中的节点表示整个世界的实体,谓词描述实体对之间的关系。
KGs可用于不同领域的各种人工智能任务,如命名实体消除歧义、内部语言处理、视觉相关性检测或协作过滤。然而,一个主要问题是,大多数真实世界的KGs是不完整的(即,真实的事实缺失)或包含虚假的事实。为解决这一问题而设计的机器学习算法试图根据观察到的连接模式来插入缺失的三元组或检测虚假事实。此外,许多任务,如问答或协作过滤,可以在预测KG中的新链接方面进行模拟。
在KGs上进行推理的大多数机器学习方法都 将实体和谓词嵌入到低维向量空间中,然后可以基于这些嵌入来计算三元组的合理性得分。大多数基于嵌入的方法的共同点是它们的黑盒性质,因为它隐藏了用户对这个分数的贡献。当涉及到在现实世界中部署KGs时,这种缺乏透明度的情况构成了一个潜在的限制。在机器学习领域,可解释性最近引起了关注。与 一次性黑盒模型(one-way black-box) 相比,可理解的机器学习方法能够构建机器和用户交互并相互影响的系统。
如果一个模型是一种一次性黑盒模型(one-way black-box),那么它只能用于生成输出,而不能从输出推断出模型内部的实现方式或其他详细信息。这意味着我们无法通过观察输出来理解模型是如何进行决策的或者对特定输入做出响应的。
大多数可解释的Al方法可以大致分为两组:后解释性(post-hoc interpretability) 和 集成透明度(integrated transparency)。
虽然后解释性旨在解释已经训练的黑盒模型的结果,但基于集成透明度的方法要么采用 内部解释机制 ,要么由于 模型复杂性低 自然地可以被解释 (例如,线性模型)。由于低复杂性和预测准确性往往是相互冲突的目标,因此通常需要在性能和可解释性之间进行权衡。
这项工作的目标是设计一种具有集成透明度的KG推理方法,该方法既不牺牲性能,又 允许人类参与 。
后解释性(post-hoc interpretability)
指在模型已经训练好并且预测能力已经被评估之后,对模型进行解释的过程。与之相对的是先解释性(ante-hoc interpretability),它是指在训练模型时就考虑到模型可解释性的过程。
后解释性的目的是为了让用户理解模型的决策过程和结果,以便更好地理解模型的行为、检测模型的偏差和错误,并为决策提供支持和解释。
Integrated Transparency(集成透明度)
指在机器学习中,将可解释性与模型的其他性能指标集成在一起的方法。旨在实现模型的高性能和可解释性之间的平衡,从而提高模型在实际应用中的可靠性和可信度。
集成透明度方法通常包括以下几个步骤:
1.确定可解释性指标:确定与模型可解释性相关的指标,例如局部解释性、全局解释性和可视化等。
2.确定其他性能指标:确定与模型其他性能指标相关的指标,例如准确性、召回率和精确度等。
3.集成指标:将可解释性指标和其他性能指标集成在一起,以综合评估模型的性能。这可以通过加权平均、决策树或神经网络等方法实现。
4.解释性反馈:根据集成指标的结果,为用户提供解释性反馈,以帮助他们理解模型的决策过程和结果。
Internal Explanation Mechanism(内部解释机制)(集成透明度中)
指在机器学习模型中添加一种用于解释模型决策过程的机制,这种机制通常是由一系列规则、约束或者其他形式的知识表示来实现的。它可以帮助用户理解模型是如何做出决策的,以及模型内部的特征和权重是如何影响模型决策的。
内部解释机制通常包括以下几个方面:
特征重要性:确定模型中每个特征对决策的影响程度。
规则和约束:定义模型内部的规则和约束,以支持对模型决策的解释。
可视化:通过可视化方式展示模型内部的决策过程和特征影响。
解释性反馈:为用户提供有关模型决策过程的解释性反馈。
模型复杂性低是指机器学习模型的结构和参数相对简单,模型的计算和决策过程也相对容易理解和解释。这种模型通常具有较少的参数和较少的层数,可以更快地训练和预测,并且更容易被理解和解释。
允许人类参与(Allowing a human-in-the-loop)可以包括以下几个方面:
数据标注:人类可以对数据进行标注,以帮助模型更好地理解和学习数据的特征和关系。
模型训练:人类可以在模型训练的过程中提供反馈,例如调整模型参数、选择特征等,以改善模型的性能。
模型推断:人类可以对模型的推断结果进行审核和纠错,以提高模型的准确性和可靠性。
模型决策:人类可以参与到模型的决策过程中,例如提供决策依据、制定决策规则等,以保证决策的合理性和可靠性。
本文介绍了一种基于强化学习的三重分类新方法——R2D2(Reveal Relations using Debate Dynamics)。受通过辩论增加Al的安全性的启发,我们将三重分类任务建模为两个主体之间的辩论,每个主体都提出了支持的论点(三元组为真)或相反的论点(三元组错误)。基于这些论点,一个称为裁判的二元分类器决定事实是真是假。与大多数基于 表示学习 的方法不同,论点可以显示给用户,这样他们就可以追溯法官的分类,并可能推翻判决或请求额外的论据。因此,R2D2的集成透明机制不是基于低复杂性组件,而是基于可解释特征的自动提取。
虽然深度学习使手动特征工程在很大程度上成为冗余,但这一优势是以产生难以解释的结果为代价的。我们的工作是试图通过使用深度学习技术自动选择稀疏的、可解释的特征来打破这一循环。这项工作的主要贡献如下。
- 据我们所知,R2D2构成了第一个基于辩论动力学的KGs推理模型。
- 我们在数据集FB15k-237和WN18RR上对R2D2的三重分类进行了基准测试。我们的发现表明,R2D2在准确性、PR AUC和ROC AUC方面优于所有基线方法,同时更具可解释性。
- 为了证明R2D2原则上可以用于KG完成,我们还评估了它在FB15k-237子集上的链路预测性能。为了包括现实世界的任务,我们在Hetionet上使用R2D2来寻找药物的基因-疾病关联和新的靶向疾病。R2D2在两个数据集上的标准测量
Representation learning(表示学习)
指一类机器学习方法,旨在自动学习数据的特征表示,以便更好地理解和处理数据。它通过学习数据的高层次特征表示,可以实现更好的数据压缩、分类、聚类、生成等任务,并且可以提高模型的泛化能力和鲁棒性。
表示学习可以自动从原始数据中学习特征表示,避免了手工设计特征表示的过程,并且可以适应不同的数据分布和任务需求。
表示学习通常分为两种类型:有监督和无监督学习。有监督表示学习是指在有标签数据上学习特征表示,例如卷积神经网络(CNN)在图像分类任务中学习特征表示;无监督表示学习是指在无标签数据上学习特征表示,例如自编码器(Autoencoder)在数据压缩和降维任务中学习特征表示。
背景与相关工作
为了指明三元组(s,p,o)是真还是假,我们考虑二元的特征函数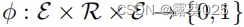 。
。
对于所有(s,p,o)∈KG,我们假设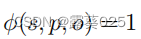 (即KG是一个为真的事实的集合)。然而,在XG中不包含三元组的情况下,它并不意味着相应的事实是假的,而是未知的(开放世界假设)。由于目前使用的大多数KG都是不完整的,因为它们不包含所有的真三元组,或者实际上包含虚假的事实,因此许多经典的机器学习任务都与KG推理有关。
(即KG是一个为真的事实的集合)。然而,在XG中不包含三元组的情况下,它并不意味着相应的事实是假的,而是未知的(开放世界假设)。由于目前使用的大多数KG都是不完整的,因为它们不包含所有的真三元组,或者实际上包含虚假的事实,因此许多经典的机器学习任务都与KG推理有关。
KG推理可以大致分为以下两个任务:
- 缺失三元组的推理(KG完成或链接预测);
- 预测三元组的真值(三元组分类);
虽然这些任务的不同表述通常在文献中找到(例如,完成任务可能涉及预测主体或对象实体以及一对实体之间的关系),但在整个工作中使用以下定义。

许多对KG的机器学习的方法可以被训练在这两种设置中操作。例如,一个三元组分类器 的形式为: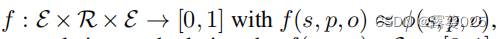
导出了一种由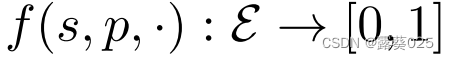 给出的完成方法,其中可以使用不同对象实体的函数值来产生排序。虽然R2D2的体系结构是为三元组分类设计的,但我们证明了它原则上也可以在KG完成设置中工作。
给出的完成方法,其中可以使用不同对象实体的函数值来产生排序。虽然R2D2的体系结构是为三元组分类设计的,但我们证明了它原则上也可以在KG完成设置中工作。
Triple Classifier(三元组分类器)
指一种用于对知识图谱中三元组进行分类的算法或模型。
Triple Classifier的目标是对给定的三元组进行分类,即判断该三元组是否正确或者是否存在错误。这种分类通常包括以下几个类别:
正确的三元组:表示该三元组在知识图谱中存在,并且与实际世界的事实相符合。
错误的三元组:表示该三元组在知识图谱中不存在,或者与实际世界的事实不符合。
不确定的三元组:表示该三元组的正确性无法确定,需要进一步的验证和确认。
表示学习是一种有效且流行的技术,是许多KG精化方法的基础。其基本思想是将实体和关系投影到低维向量空间中,然后将三元组的可能性建模为嵌入空间上的函数。
最近提出了多跳推理方法 MINERVA,这与我们的工作有很大关系,其基本思想是向代理显示查询主题和谓词,并让他们执行策略引导的遍历以找到正确的对象实体。MINERVA产生的路径也导致了某种程度的可解释性。然而,我们发现,只有积极挖掘论文和对立论点,从而暴露辩论的双方,才能让用户做出明智的决定。为这两个位置挖掘证据也可以被视为对抗性特征生成,使分类器(判断)对矛盾证据或损坏的数据具有鲁棒性。
我们的方法
我们根据两个对立主体之间的距离来制定三元组分类的任务。
因此,一个查询三元组对应于辩论的中心陈述。代理通过挖掘KG上的路径来进行,这些路径为论文或对立面提供了证据。
更准确地说,他们顺序遍历图,并根据考虑 过去转换(Past Transition) 和查询三元组的策略选择下一跳。这个转换将添加到当前路径,从而扩展参数。所有路径都由一个名为裁判的二进制分类器处理,该分类器试图根据代理提供的参数来区分真三元组和假三元组。
辩论的主要步骤可以概括如下:
- 辩论围绕着一个三元组问题向两个代理人提出。
- 两位代理人轮流从KGs中提取路径,作为论文和对立面的论据。
- 裁判将自变量与查询三元组一起处理,并估计查询三元组的真值。
当裁判的参数通过监督式学习来进行拟合的时候,两个代理(Agent)都是通过强化学习(Reinforcement Learning)算法训练来实现在图中导航的。通过下面列出的固定范围决策过程对代理的学习任务进行建模。
Past Transition(过去转化)
指在逻辑推理中,将一个谓词的过去时态转化为现在时态,以便进行推理和推导。过去时态和现在时态在语法形式上有所不同,但是它们在语义上是等价的,可以互相转化。
在知识推理中,经常需要使用过去时态描述过去的事件或状态,但是在逻辑推理中,过去时态无法直接参与推理。因此,需要使用Past Transition将过去时态转化为现在时态,以便进行推理和推导。例如,将“John was a student”(John曾经是学生)转化为“John is a student”(John是学生),以便在推理过程中使用。
Past Transition通常包括以下几个步骤:
识别谓词的过去时态:首先需要识别谓词的过去时态形式,例如“was”、“had”等。
转化为现在时态:将过去时态转化为现在时态,例如将“was”转化为“is”。
修改主语:根据需要,可能需要修改主语的人称和数,以便与现在时态一致。
在机器学习中,监督式学习是一种通过给定输入和输出数据,训练模型来预测新数据的方法。在监督式学习中,通常需要定义一个模型和一组参数,然后通过训练数据来拟合这些参数,使得模型能够准确地预测输出结果。
在评判者的场景中,也需要使用模型和参数来评估和判断某个对象或行为的好坏。这些参数可以通过监督式学习的方法来进行拟合,以实现更准确的评判和判断。
状态
对于每一个代理的 完全可观察状态空间S 都被给定为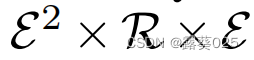 。我们就想用这种状态对代理i(i∈{1,2})在时间t和查询三元组q(q=sq,pq,oq)的 探索位置et(i) 进行编码。因此,一个状态St(i) ∈S在时间t属于N上被表示为:
。我们就想用这种状态对代理i(i∈{1,2})在时间t和查询三元组q(q=sq,pq,oq)的 探索位置et(i) 进行编码。因此,一个状态St(i) ∈S在时间t属于N上被表示为: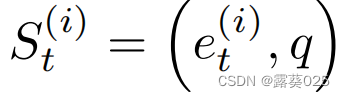 。
。
“fully observable state space”(完全可观察状态空间)
指的是一个系统或环境中,所有的状态都是可以被观察的,也就是说,我们可以得到系统或环境中所有对象的完整信息
“location of exploration”(探索位置)
通常指的是在搜索或推理过程中,需要进一步探索或评估的特定位置或节点。
在推理算法中,探索位置通常是指需要进一步评估或推理的知识点或假设。例如,在基于规则的推理系统中,探索位置通常是指需要应用规则来推导出更多结论的规则或前提条件。
action
对于代理 i i i在一个状态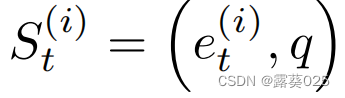 的一组可能的行为被表示成
的一组可能的行为被表示成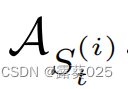 。它由来自节点et(i)出边和对应的目标节点组成。更正式地说,=
。它由来自节点et(i)出边和对应的目标节点组成。更正式地说,= 。此外,我们用
。此外,我们用 来表示代理 i i i在时间t上的操作。我们为每个节点加上 **自环(self-loop)**以便代理可以停留在当前节点。
来表示代理 i i i在时间t上的操作。我们为每个节点加上 **自环(self-loop)**以便代理可以停留在当前节点。
环境
环境通过根据覅阿里的操作更新状态(即通过更改代理的位置)来确定地发展,从而使查询事实保持不变。从形式上将,代理 i i i在时间 t t t上的的转换函数为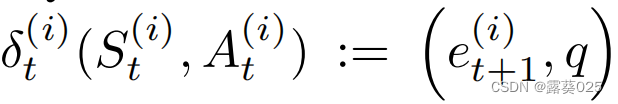 ,
,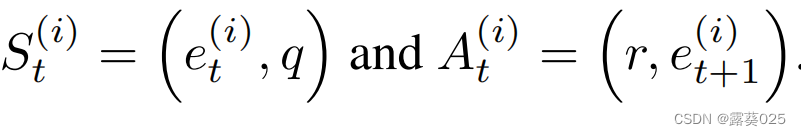 。
。
“outgoing edges”(出边)通常指的是图或有向图中一个节点指向其他节点的边。它是从一个节点指向其他节点的边,表示了节点与其他节点之间的关系或连接。
在知识表示和推理中,出边通常用于表示概念之间的关系。例如,一个基于概念网络的知识表示系统中,概念通常被表示为节点,而概念之间的关系则通过出边来表示。例如,一个表示"动物"概念的节点可能有一些出边,分别指向"狗"、“猫”、"马"等其他动物的节点。
policies
我们将代理 i i i到时间 t t t的历史用元组表示: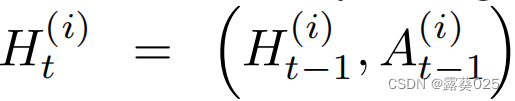 当t>=1且
当t>=1且 。代理通过LSTMs编码它们的历史:
。代理通过LSTMs编码它们的历史: 。其中
。其中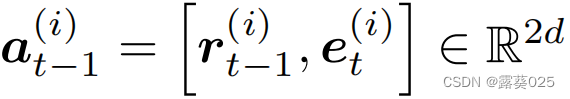 对应前一个动作的向量空间嵌入(t=0时为零向量),其中rt-1(i)和et(i)分别表示关系和目标实体嵌入R中。此外,
对应前一个动作的向量空间嵌入(t=0时为零向量),其中rt-1(i)和et(i)分别表示关系和目标实体嵌入R中。此外, 为代理 i i i编码查询三元组。实体和关系嵌入都是针对每个主体的,并且是在训练的辩论过程中学习的。
为代理 i i i编码查询三元组。实体和关系嵌入都是针对每个主体的,并且是在训练的辩论过程中学习的。
每个代理的历史相关动作分布由下式给出:

其中
Debate Dynamics
在第一步,具有真值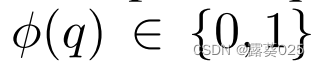 的查询三元组q=(sq,pq,oq)被表示成两个代理。代理1认为这个事实为真,尽管代理2认为这个事实为假。与大多数正式辩论类似,我们考虑固定数量的回合N,在每一个回合n=1,2,…,N中,代理程序使用固定长度T从查询主体节点sq开始,横向扫描图谱。裁判监督代理的路径并预测三元组的真值。代理1开始游戏,根据等式(1-3)生成由状态和动作组成的长度为T的序列。然后,代理2从Sq开始生成一个相似的序列。算法1在推理时包含R2D2的后代码。
的查询三元组q=(sq,pq,oq)被表示成两个代理。代理1认为这个事实为真,尽管代理2认为这个事实为假。与大多数正式辩论类似,我们考虑固定数量的回合N,在每一个回合n=1,2,…,N中,代理程序使用固定长度T从查询主体节点sq开始,横向扫描图谱。裁判监督代理的路径并预测三元组的真值。代理1开始游戏,根据等式(1-3)生成由状态和动作组成的长度为T的序列。然后,代理2从Sq开始生成一个相似的序列。算法1在推理时包含R2D2的后代码。
为了简化注释,我们枚举了所有操作,并删除了指示哪个代理执行该操作的上标。然后对应第n个序列给出代理i的论据:
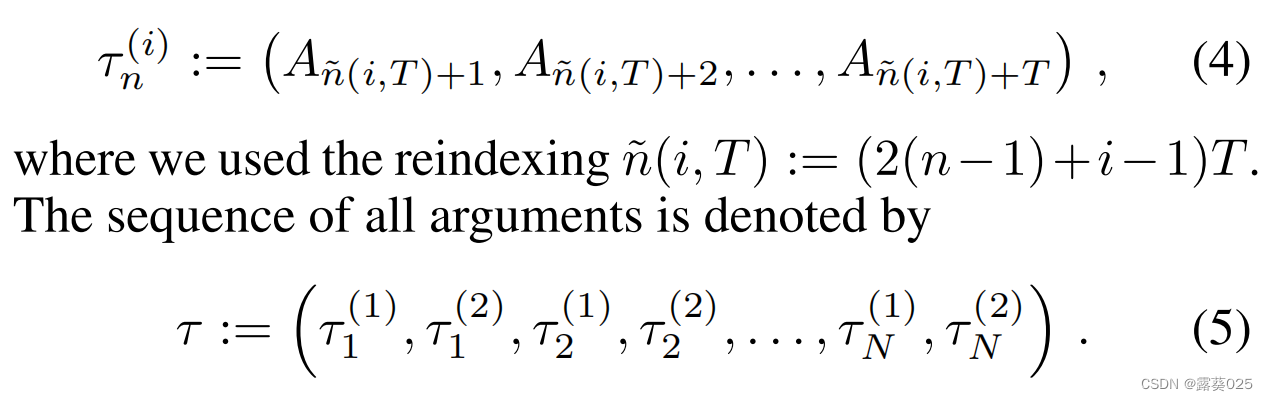
裁判
裁判在R2D2中的作用有两个:
- 裁判是一个试图区分真实和虚假事实的二元分类器。
- 裁判还评估代理人提取的论点的质量,并为他们分配奖励。
因此,裁判也扮演着批评者的角色,教导代理人提出有意义的论点。裁判通过前馈神经网络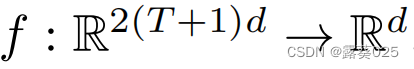 单独处理每个自变量和查询,对每个自变量的输出求和,并通过二元分类器处理结果求和。更具体地说,在单独处理每个参数后,裁判根据
单独处理每个自变量和查询,对每个自变量的输出求和,并通过二元分类器处理结果求和。更具体地说,在单独处理每个参数后,裁判根据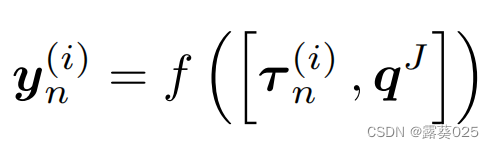 做出表述,
做出表述,
其中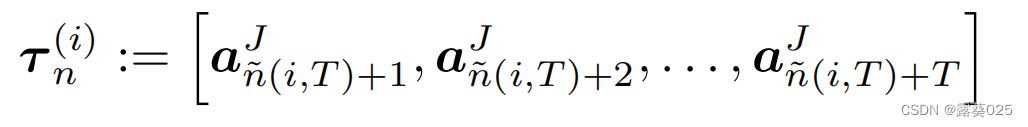
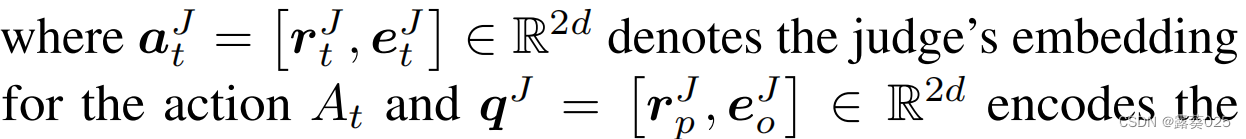
编码查询谓词和查询对象。注意,查询主体不会透露给裁判,因为我们希望裁判仅根据代理的行为而非查询主体的嵌入来做决定。处理完 τ τ τ中的所有自变量后,辩论终止,裁判根据
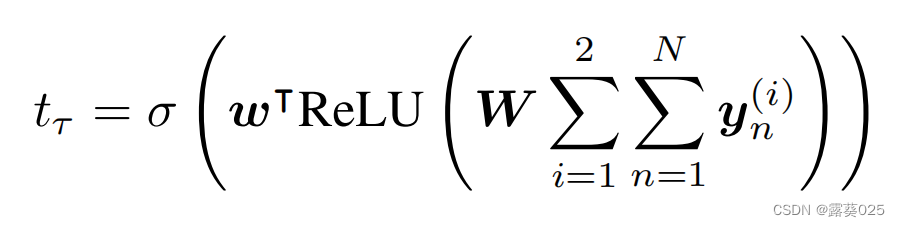 对查询三元组进行打分。其中,
对查询三元组进行打分。其中,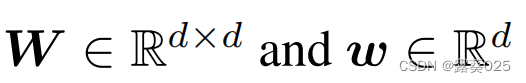 代表分类器可以训练的范式,函数是功能激活函数。
代表分类器可以训练的范式,函数是功能激活函数。