李宏毅 DLHLP 深度学习人类语言处理 HW1
- 相关资料
- HW1
- 更多尝试
- 1, 加深encoder:4层LSTM
- 2, 加深encoder(4层LSTM)和加深decoder(2层LSTM)
- 3, cnn代替vgg
- 4, 再次加深decoder(4层LSTM)
- 5, 在2的基础上加上dropout
语音小白在网上没有找到这门课的作业分享,那就记录一下自己的作业吧。
相关资料
课程官网:https://speech.ee.ntu.edu.tw/~hylee/dlhlp/2020-spring.php
作业github代码1:https://github.com/Alexander-H-Liu/End-to-end-ASR-Pytorch
作业github代码2:https://github.com/DLHLP2020/hw1-speech-recognition/tree/master
其中代码1是你用来跑模型写作业的代码,代码2只是辅助,帮你eval结果和把答案转换成提交要求格式。
提交作业kaggle网站:https://www.kaggle.com/competitions/dlhlp2020spring-asr/leaderboard
目前还是可以提交的,选late submmission,不会参与打榜。
首先大家好好听课,然后按照课件说明去下载作业slide、数据、github代码,最后按照作业slide一步一步往下走就可以。作业总体思路就是尝试不同元素的LAS模型:
Listen = encoder
Attention = Attention
Spell = Decoder
在作业里,会让你尝试
1,用最基础的seq2seq
2,在训练模型时,encoder部分叠加使用CTC,别的部分保持不变,所以loss会变成CTC+seq2seq混合loss
3,CTC joint的模型,decoder只用CTC
4,decoder部分,借助LM
5,不同beam size的效果
HW1
1,Train a seq2seq attention-based ASR model. Paste the learning curve and alignment plot from tensorboard. Report the CER/WER of dev set and kaggle score of testing set. (2 points)
一开始的时候,成绩很烂啦,虽然alignment plot看起来还挺合理的,不过打不过baseline
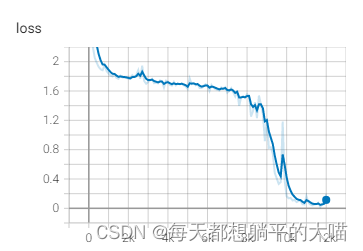

提交到kaggle上,成绩是这样的,比baseline烂不少
2,Repeat 1. by training a joint CTC-attention ASR model (decoding with seq2seq decoder). Which model converges faster? Explain why. (2 points)
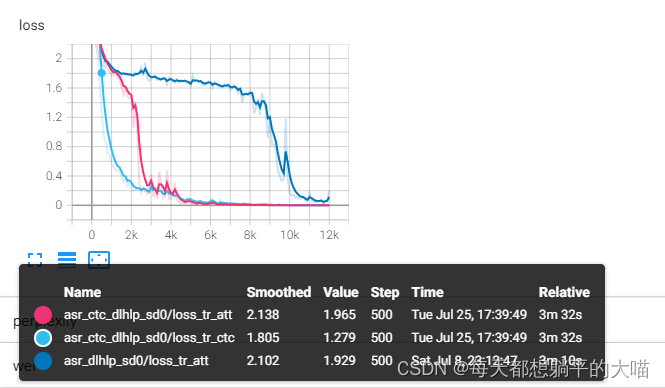
这里我用的CTC weight是0.3,可以看到joint CTC-attention ASR收敛更快,而且模型效果更好。网上搜了一下,大概原因是ASR中attention是非常非常灵活的,joint CTC-attention相当于在前期encoder部分就做了对齐,所以会更快收敛,效果也更好。
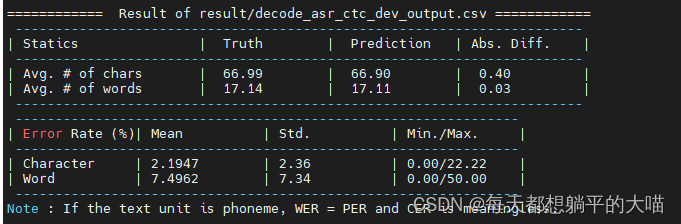
这个时候结果已经可以比baseline好了 3,Use the model in 2. to decode only in CTC (ctc_weight=1.0). Report the CER/WER of dev set and kaggle score of testing set. Which model performs better in 1. 2. 3.? Explain why. (2 points)
3,Use the model in 2. to decode only in CTC (ctc_weight=1.0). Report the CER/WER of dev set and kaggle score of testing set. Which model performs better in 1. 2. 3.? Explain why. (2 points)
1,2,3里面应该是2结果最好,因为2的decode有了CTC的帮助,但3中纯粹用CTC decode的话,就像老师在课上讲的,CTC不考虑前面的输出,效果不会特别好,往往需要后处理。
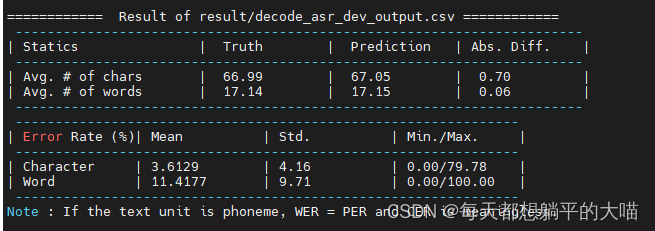
作业slide里面说CTC decode后的结果要再处理一下,但是我看结果没有什么重复和空的地方,应该是助教后期写好了吧,以下是eval的结果:
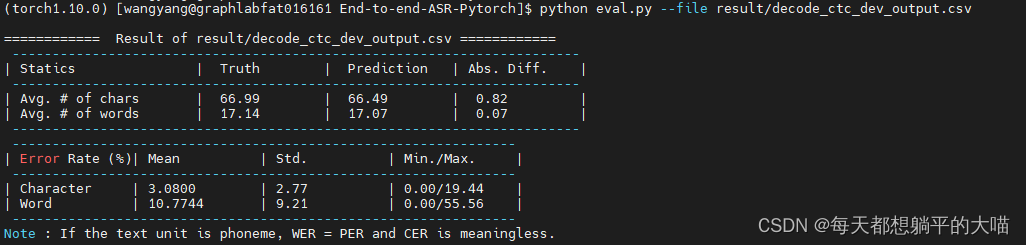
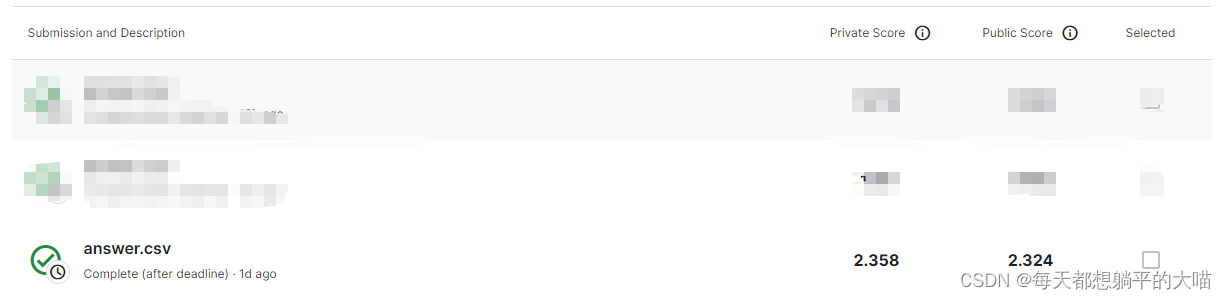
kaggle提交结果如下,还挺惊讶3的效果比1好。

4,Train an external language model. Use it to help the model in 1. to decode. Report the CER/WER of dev set and kaggle score of testing set. (2 points)
这里从libri里面copy decode example的时候,记得改一下max_step和valid_step,不然就会训练到地老天荒。我设成了 valid_step: 250,max_step: 20000,很快就训练完了。
decode的时候,我的lm weight取的0.3。最后的结果,只能说比1提升了一点吧,比不过CTC,离baseline还很远。
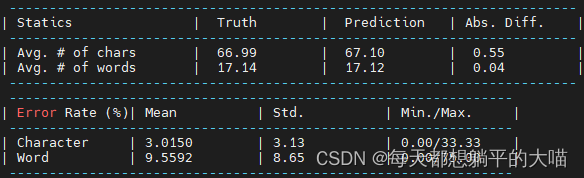

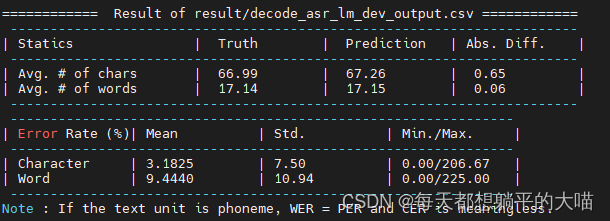
5,Try decoding the model in 4. with different beam size (e.g. 2, 5, 10, 20). Which beam size is the best? (2 points)
这里我只有beam size从2加到5的时候,private score有了一个相对明显的提升,beam size再提升的时候,效果就不再提升反而略微下降。用2中的model,尝试了beam size 5和10,不知道为什么,也没有见到模型效果的提升。
beam size 5
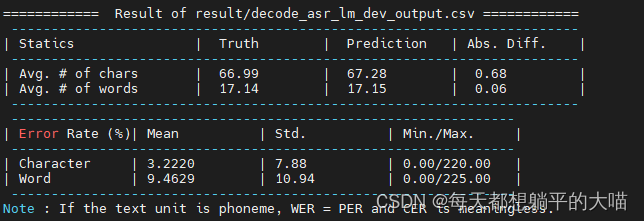

beam size 10
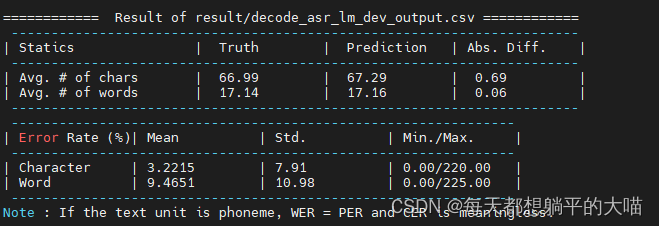
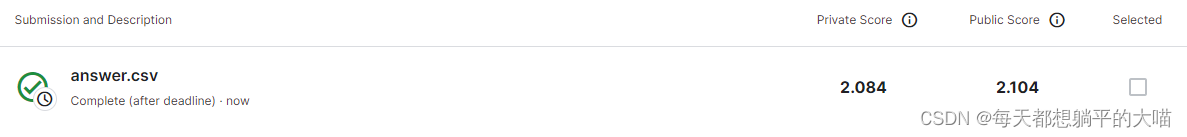
beam size 20

更多尝试
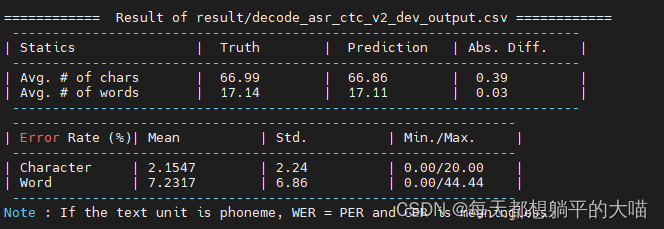
1, 加深encoder:4层LSTM
因为作业2中的模型效果最好(CTC joint 训练,decoder时只使用seq2seq,不使用CTC),首先先尝试在这个基础上加深encoder重新训练,从一开始的2层LSTM加深为4层LSTM
encoder:prenet: 'vgg' # 'vgg'/'cnn'/''# vgg: True # 4x reduction on time feature extractionmodule: 'LSTM' # 'LSTM'/'GRU'/'Transformer'bidirection: Truedim: [512,512,512,512]dropout: [0,0,0,0]layer_norm: [False,False,False,False]proj: [True,True,True,True] # Linear projection + Tanh after each rnn layersample_rate: [1,1,1,1]sample_style: 'drop' # 'drop'/'concat'
最后效果如下 (beam size = 10):
提升不明显,看Loss,训练时收敛得慢一些
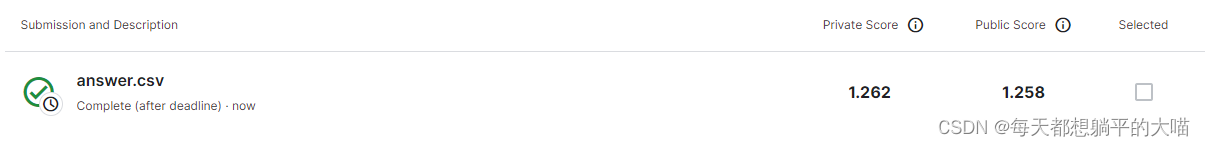
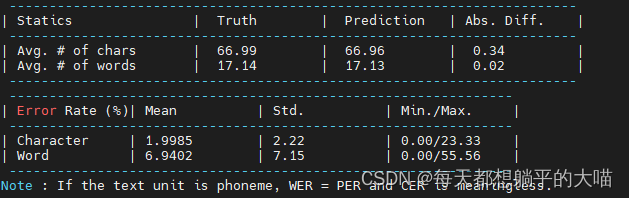
2, 加深encoder(4层LSTM)和加深decoder(2层LSTM)
在尝试1的基础上加深decoder,从原来的1层LSTM变为2层LSTM,效果有了一个明显的提升

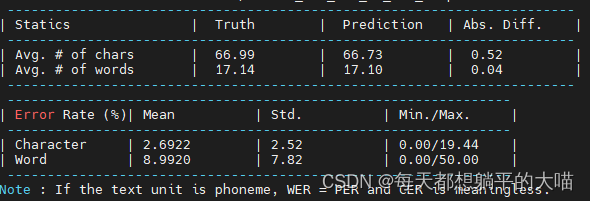
3, cnn代替vgg
encoder中的vgg使用cnn,其余与2中相同

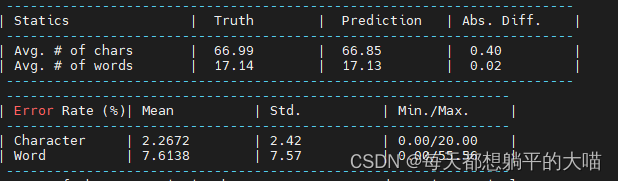
4, 再次加深decoder(4层LSTM)
在尝试2的基础上再次加深decoder,从2层LSTM变为4层LSTM,效果变差了
5, 在2的基础上加上dropout
model: # Model architecturectc_weight: 0.3 # Weight for CTC loss, set between 0.0~1.0 to jointly optimize for CTC + seq2seqencoder:prenet: 'vgg' # 'vgg'/'cnn'/''# vgg: True # 4x reduction on time feature extractionmodule: 'LSTM' # 'LSTM'/'GRU'/'Transformer'bidirection: Truedim: [512,512,512,512]dropout: [0.5,0.5,0.5,0.5]layer_norm: [False,False,False,False]proj: [True,True,True,True] # Linear projection + Tanh after each rnn layersample_rate: [1,1,1,1]sample_style: 'drop' # 'drop'/'concat'attention:mode: 'loc' # 'dot'/'loc'dim: 300num_head: 1v_proj: False # if False and num_head>1, encoder state will be duplicated for each headtemperature: 0.5 # scaling factor for attentionloc_kernel_size: 100 # just for mode=='loc'loc_kernel_num: 10 # just for mode=='loc'decoder:module: 'LSTM' # 'LSTM'/'GRU'/'Transformer'dim: 512layer: 2dropout: 0.5
首先尝试只有asr decoder,beam size =3
加上dropout后,模型效果有了一个很大的提升
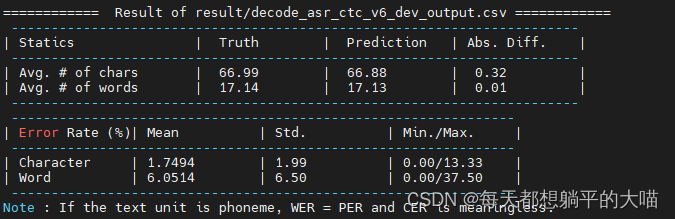

再试试decoder加上0.3的lm权重
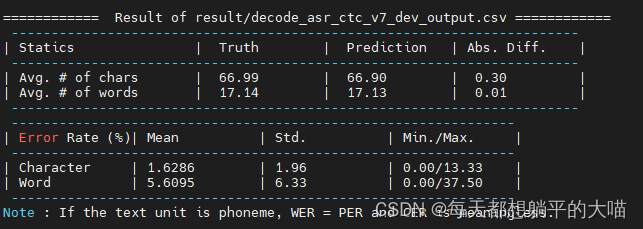

再试试beam size = 20
结果和beam size3 没什么大的区别
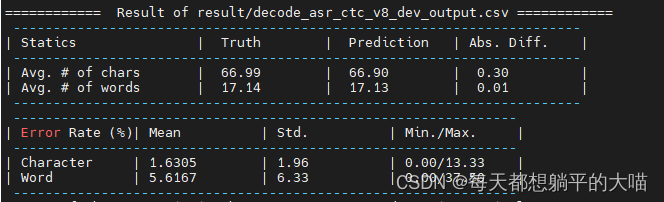
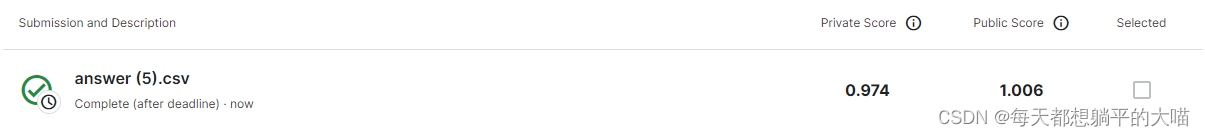
将decoder和encoder里面的dropout改成0.3,再重新训练一下:
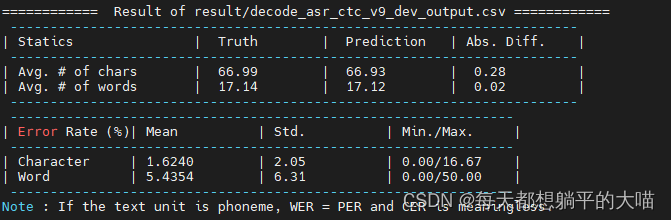

可以看到,当dropout值调小后,虽然public score变小了,但是private score变大了,所以dropout调小后,应该是存在一些过拟合。如果用之前dropout 0.5,反而private score可以拿到更好的排名。
HW1的尝试就先到这里为止吧。没有尝试而相对明确的方向有,
1,增大LM的corpus
2,使用课堂上介绍的别的decoder结构,比如RNNT