Aerial Vision-and-Dialog Navigation
- 本次报告,包含以下部分:1摘要,2数据集/模拟器,3AVDN任务,4模型,5实验结果。重点介绍第2/3部分
- 相关主页:Aerial Vision-and-Dialog Navigation (google.com) 包含,code,paper,dataset
一,摘要
这一部分将论文中的摘要,引言,相关工作,合并介绍
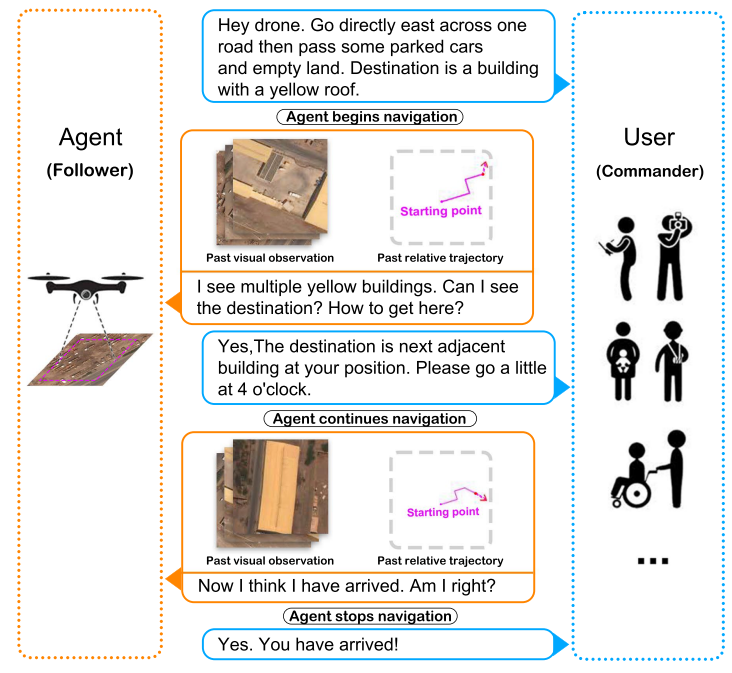
本文提出了一个空中/对话/导航任务,其目的是解放双手来控制无人机。为了完成这个任务,作者创建了一个来自真实图片的 连续场景的 无人机模拟器 和 一个具有3064条条轨迹的对话数据集。在对话的过程中,commander(用户角色)提供初始的导航指令和进一步的指导。fellower(无人机角色)在必要的时候提问。在此基础上,作者提出了两种空中导航任务,一种是ANDH,另一种是AVDN-Full,区别是AVDN-Full是直接给出所有的完整的对话历史预测到达目的地的导航轨迹,AVDN是使用逐轮对话进行子轨迹的导航,从而完成导航到最终目的地的完整任务。作者还提出了一种结合人类注意力预测的transformer-based模型来预测waypoints。
图一简单介绍了一个AVDN任务的例子
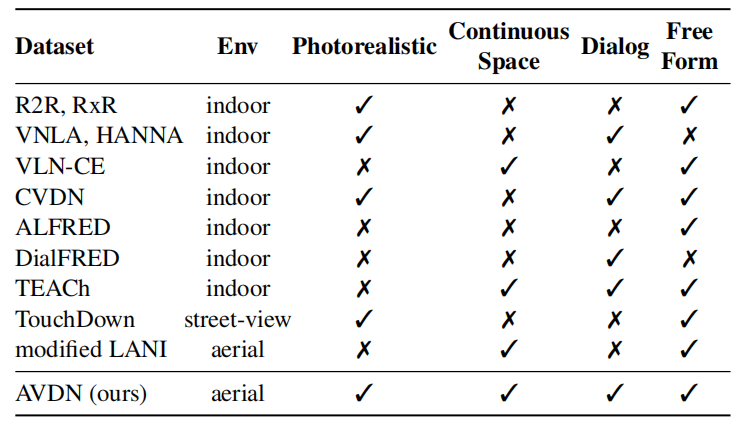
表一中,本文提出的数据集AVDN跟其他VLN数据集进行了比较:
- 后面的内容解决以下几点疑问:
- Q 1: 模拟器能提供那些功能?
- Q 2: 数据集有哪些信息?
- Q 3: 导航成功的条件?
- Q 4: 对话过程是怎么异步进行的?
- Q 5: 提出的模型方法的流程,输入输出是什么?
- Q 6: 人类注意力是怎么得到的?怎么使用的?
- Q 7: 任务的局限性?
二,数据集/模拟器
数据集/模拟器是 任务 的基础,提出的任务不能超过数据集/模拟器的能力范围
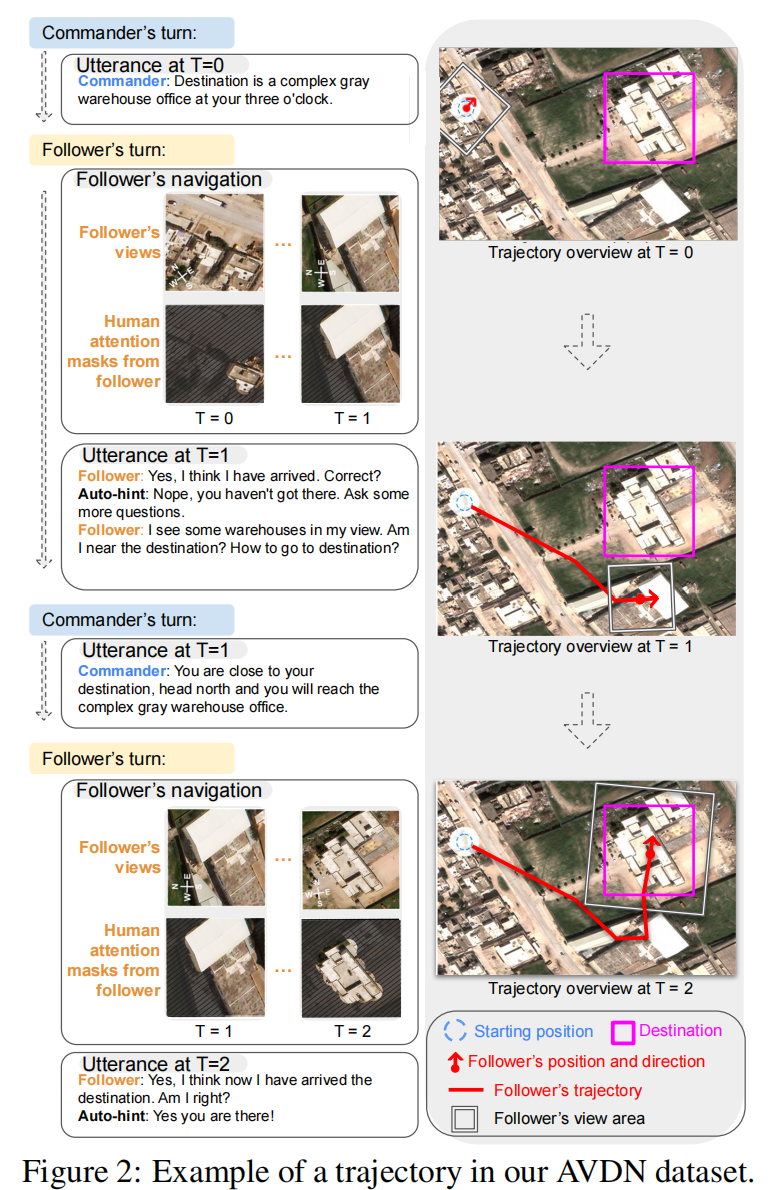
figure 2
AVDN
2.1 模拟器
和R2R任务相似,模拟器的构建需要基于一个开源的大规模3D数据集。
而AVDN任务需要的模拟器,是基于 xView数据集 构建的 (一个开源的,大规模的卫星图像目标检测数据集)
Response for Q1: 模拟器能够提供那些功能
- 模拟器提供的是一个自上而下的视角,模拟环境是一个连续的环境,无人机可以移动到环境中的任何点,所以模拟器提供的是具有丰富视觉内容的连续帧。
- 无人机还可以通过键盘控制,无人机观察到的视觉内容可以被实时展示。控制过程中,用户还可以通过点击他们关注的区域来关注界面显示的图像。
- 除此之外,如图2展示的那样,我们的模拟器能够生成commander视图,观察到起始点,目标区域,当前的视图,过去的行动轨迹。
2.2 数据集
2.2.1 数据集结构
Response for Q1: 数据集有哪些信息
数据集包含了导航轨迹 (time step(T)= 0, 1, 2……M):
- T=0时,commander提供一个初始指令。相邻的时间步之间存在对应的导航子轨迹。
- 在中间的每一个时间步(0<T<M),都有对应的(来自fellower的)问题和(来自commander)答案。
- 在T=M时,到达目标区域,由follower决定导航轨迹结束。
有T=M个fellower的视图序列, < u 0 T , u 1 T , , , , u N T T > , N T <u_0^T, u_1^T,, , ,u_{N_T}^T>,N_T <u0T,u1T,,,,uNTT>,NT是T-th序列的长度,每个视图的中心总是落在轨迹上。因此,基于每个视图,我们能检索到无人机的的位置,方向,高度( c i , d i , h i c_i,d_i,h_i ci,di,hi).
对于每个视图区域u,还有一个对应的大小相同的二进制的人类注意力的mask,fellower关注白色区域。
2.2.2 数据集收集
Response for Q 3: 导航成功的条件
导航成功的情况是,当fellower宣称到达了真正的目标区域时。如果视图中心 c i c_i ci在目标区域时候,并且到达的区域 u j u_j uj和目标区域Des 的交并比大于0.4时,认为到达了目的地。
2.2.3 数据集分析
AVDN数据集包含了3064个空中导航轨迹,每个轨迹包含多轮对话。平均来说,每个轨迹只包含两轮对话,对话的轮数和是最大的time step M是相同的。3064个完整的轨迹可以被分割成6269条子指令和对应的轨迹。
图3展示了常用词和路径长度分布,轨迹平均长度是287m。

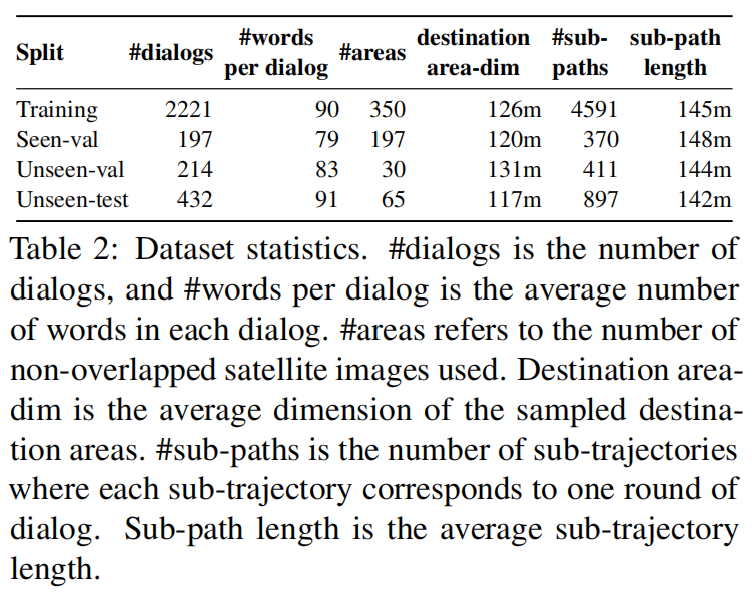
表二展示了对不同数据集分割的统计分析,平均每个数据集分割包含1.2平方千米的卫星图像区域(相当于一个大学校园那么大)。
关于指令,包含两种,一种是详细的描述目的地的指令,一种是粗略的初始指令和后面的对话进一步描述。
描述方向的方式也包含两种,一种是以自我为中心的,例如“turn right”,占82%。一种是非以自我为中心的,例如“turn south”,占30%。还有部分指令包含了这两种指令。
三,AVDN任务
本节介绍具体的任务,包含AVDN和AVDN-Full两种,两个模型都需要预测一系列的视觉区域
Respone for Q 4:对话过程是怎么异步进行的?
github的issue中的回复。

- 对于这个问题的解答可以看完第四节模型的预测过程后,再回头来看
- agent跑到不同的地方,应该提出不同的问题?
在训练的时候,无论agent跑没跑偏,都无所谓,因为我们有ground truth导航点,我们预测一个对或错的导航点之后,下一个起始位置一定是从正确的轨迹上的点开始。推理测试的时候,没有正确的子轨迹和waypoint供参考,如果预测到一个不在数据集中的waypoint上,则必须回溯到正确的轨迹上,而测试集没有正确的轨迹,所以只能回到起始点。- 根据作者回复的最后一句话,在推理时,对话历史总是准备好的(而不是交互的),根据这一对话历史完成预测之后必须到达下一个起始位置,也就是说进行下一个预测任务。也就是说,在训练train的时候,该任务是有一定的对话的意思,但是在测试test的时候,没有ground truth轨迹,只能在测试一开始将对话历史输入进去,中间过程不再对话。
3.1 AVDN
任务目标是让agent根据对话历史中的指令预测一个引导至目标区域的导航动作(而不是直接导航到目标区域)。
具体来说,在Ti到 T i − 1 T_{i-1} Ti−1这一步,agent预测一个动作 a ^ j \hat{a}_j a^j
输入是(从T=0到T=Ti)对话和一系列的图像 u ^ 0 , u ^ 1 , , , , u ^ j − 1 > \hat{u}_0, \hat{u}_1,, , ,\hat{u}_{j-1}> u^0,u^1,,,,u^j−1>,
目标区域和当前的导航time step有关,
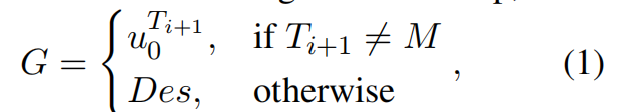
3.2 AVDN-Full
和AVDN的区别是,AVDN-Full的输入是整个导航对话和视觉内容,agent需要预测一个完整的(从起始点 u 0 0 u_0^0 u00到目标区域Des)轨迹,
所以,AVDN-Full为agent提供完整的监督,包括了更精确的目的地描述,更长的表达,更复杂的视觉grounding挑战。
3.3 评估指标
SR成功率和SPL(导航轨迹和导航路径长度加权)都是最基本的导航指标。
GOAL progress是对话导航独有的评估指标,用来评估通往目的地进展的距离,其实就是轨迹的欧拉距离减去预测中心到目标区域的距离。
四,模型
不细讲模态的编码方法,重点在于讲解模型预测的输入输出流程,阅读时请结合模型流程图

Response for Q1: 模型的流程,输入输出是什么
多模态编码
输入来自三个模态,无人机接收到的方向,图像和历史对话。
起始的时候,接收整个对话历史,包含question和指令。
在每个时间步,之前的方向和图像都被输入到模型中。其中,使用一种卫星图像的预训练模型提取图像编码,整个模型总体上和ET(21年提出的室内导航方法)类似。
多模态的总体输入输出可以表示为
{ z 1 : L l , z 1 : t v , z 1 : t x } = F M T ( { z 1 : L l , z 1 : t v , z 1 : t x } ) \{z_{1:L}^l, z_{1:t}^v, z_{1:t}^x \} = F_{MT}(\{ z_{1:L}^l, z_{1:t}^v, z_{1:t}^x\}) {z1:Ll,z1:tv,z1:tx}=FMT({z1:Ll,z1:tv,z1:tx})
这里的输出不是最终的预测结果,而是一种融合跨模态特征表示。
至于导航进度 g ^ \hat{g} g^,用于决定何时停止。如果导航进度大于阈值,无人机将结束导航,不执行预测waypoint的动作
导航预测和waypoint控制
导航输出是
( w ^ , g ^ ) = F N D ( { z 1 : L l , z 1 : t v , z 1 : t x } ) (\hat{w},\hat{g})=F_{ND}(\{z_{1:L}^l, z_{1:t}^v, z_{1:t}^x \}) (w^,g^)=FND({z1:Ll,z1:tv,z1:tx})
其中, w ^ \hat{w} w^是一个3D坐标(x,y,h)x,y表示位置,h表示高度。
预测的waypoint也控制着无人机的方向,方向朝着移动的方向。因此, w ^ \hat{w} w^也控制着无人机的移动,下一个视图中心,宽度和旋转由 w ^ \hat{w} w^决定。
人类注意力预测(human attention predication)
Q 6:人类注意力是怎么得到的?怎么使用的?
使用 z 1 : t v z_{1:t}^v z1:tv作为输入,编码后预测一个和图像维度大小相同的mask,值越大表示越关注该区域。
Training
首先训练AVDN任务,再训练AVDN-Full任务
waypoint( w ^ \hat{w} w^)和导航进程( g ^ \hat{g} g^)预测使用下面公式训练
人类注意力预测使用下面公式训练:
其中,P是预测的human attention mask,Q是ground truth mask
五,实验结果
在AVDN和AVDN-Full上的预测结果
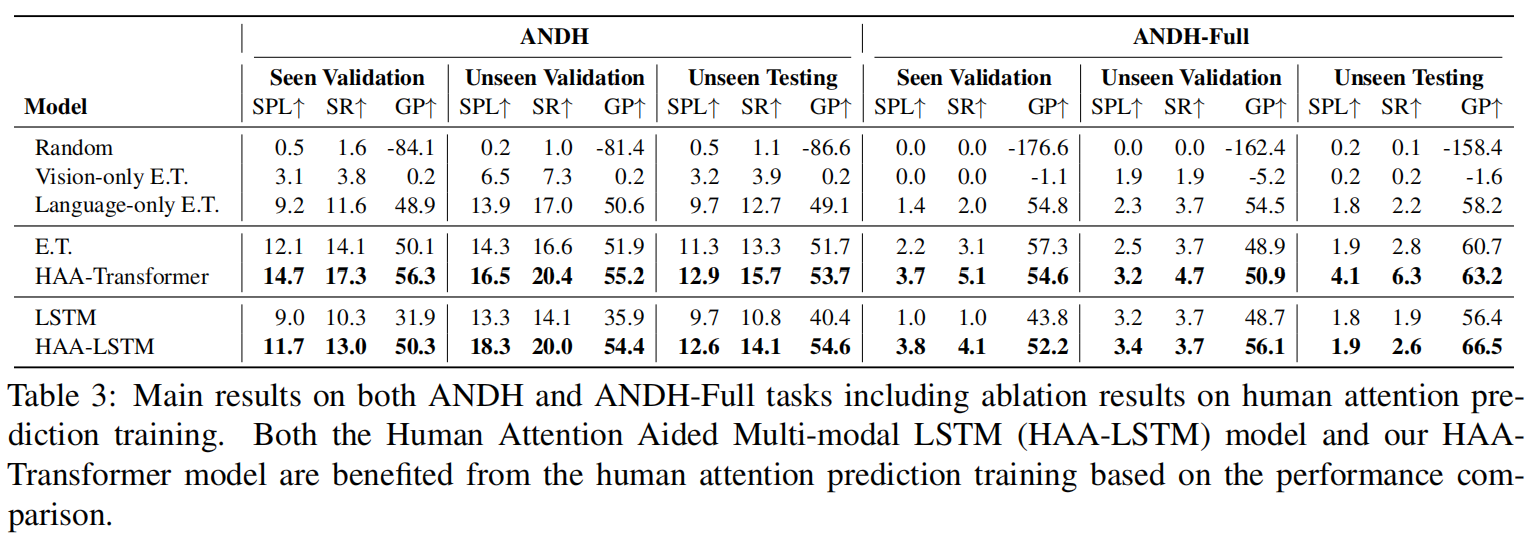
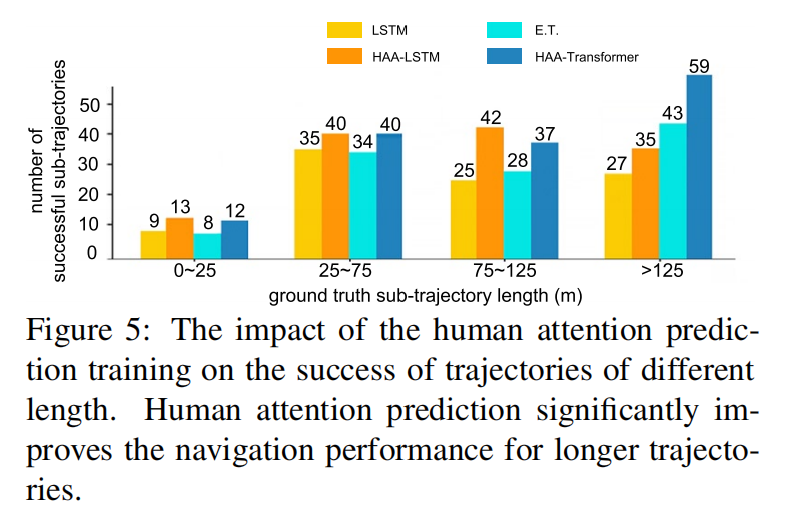
实验还证明了,注意力预测有助于最终的导航成功率
Q 6:任务的局限性是什么?
文中指出的任务局限性在于隐私泄露