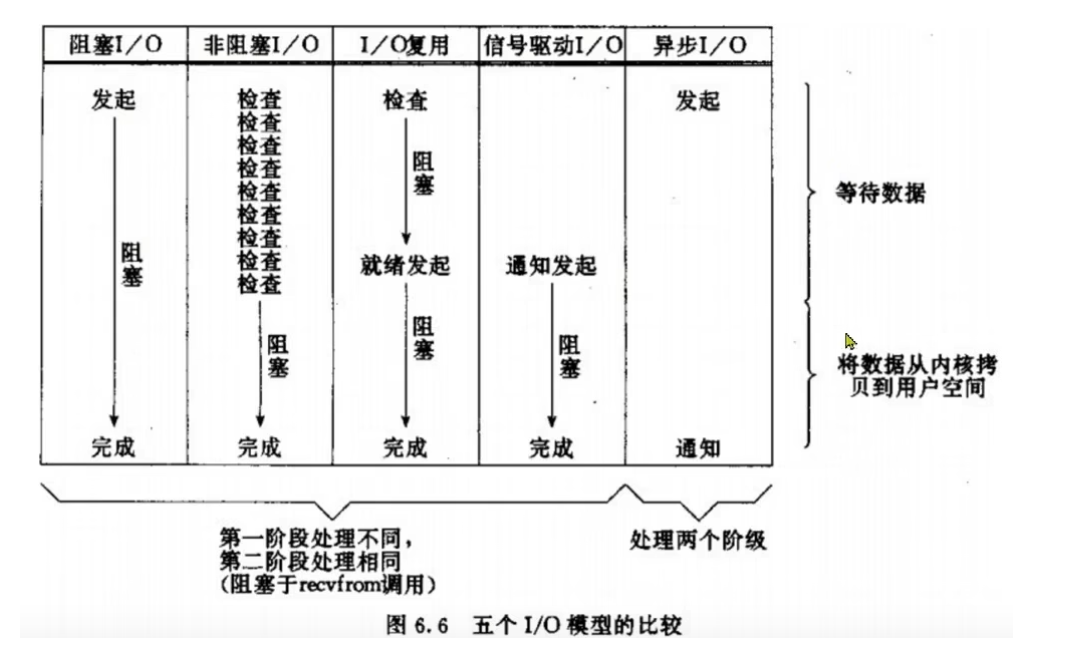
mysql中用于唯一标识表中行数据的方式有哪些?项目中如何选择?你参与的项目中为什么选用这种方式?
|
| 自增ID | UUID |
| 类型 | 整数型 | 字符串型 |
| 长度 | 固定长度(如MySQL InnoDB自动生成的ID为4字节,32位) | 32个字符(当前日期和时间、时钟序列、全局唯一的IEEE机器识别号) |
| 唯一性 | 是 | 是 |
| 生成方式 | 数据库自动生成( 可以避免手动生成ID时出现错误,提高生成ID的准确性) | 随机生成(当前时间、计数器和硬件标识等数据计算生成) |
| 唯一标识范围 | 数据库记录级别 | 全球范围 |
| 插入速度 | 快 | 慢,数据会有碎片
|
| 查询速度 | 定位和寻址很快 顺序的每一条记录都存储在一条记录的后面。新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗,减少了页分裂和碎片的产生 | IO问题 写入是乱序的,innodb不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上,由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片 |
| 性能问题
| 已经达到最大值,那么插入新数据时需要重新生成ID
| 随机生成的,所以会发生随机IO,影响插入速度,并且会造成硬盘的使用率较低
|
| 数据合并
| 数字类型,新老数据区分会出现一些冲突 新老数据合并,要是新数据主键也是数字类型,想新老数据区分会出现一些冲突 | 唯一性 |
| 适用场景 | 为了存储和查询效率选择 对于一些敏感数据,比如用户 id,订单 id 等,如果使用自增 id 作为主键的话,外部通过抓包,很容易可以知道新进用户量,成单量这些信息,所以需要谨慎考虑是否继续使用自增主键。 | 分布式系统 重复率 |