一、安装环境
笔者环境如下:
win10
anaconda
python3.8
二、clone代码
地址如下,可以直接使用git命令进行clone,也可以直接去网站下载
git clone https://github.com/ultralytics/ultralytics
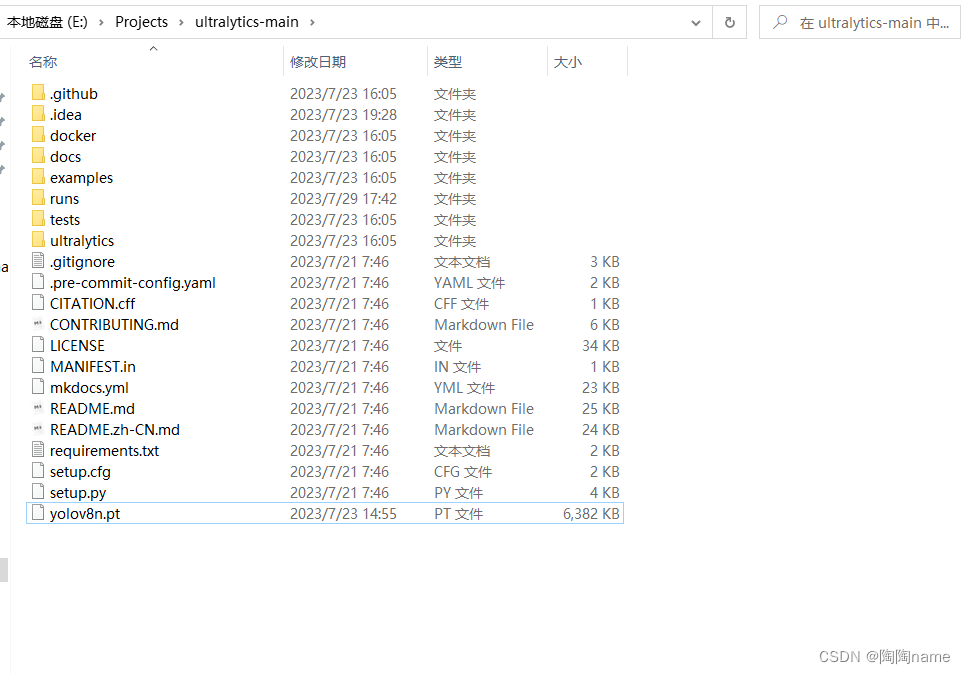
代码目录如下所示
三、安装必要的库
其实这里比较重要的是两步,第一步是安装requirement.txt中的库,然后再安装ultralytics。那么下面就是安装库的过程了
安装requirement.txt
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装ultralytics
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
note:这个版本其实是基于torch写的,所以我们是需要安装深度学校框架库的,其实在requirement.txt的安装中就已经安装了torch,但是默认的是cpu版本的,如果你电脑有gpu,还是建议根据gpu的版本来配置对应的环境,然后安装gpu版本的torch,这样的话训练的时候速度会快一些,如果没有的话对于下面的训练也是没有关系的,可以给batch以及epoch设置小一些,也是可以执行的
四、配置自定的数据集
数据集是我提前准备好的,如果需要自定的话,是需要使用 labelImge 标注工具进行标注的,具体的可以参考下篇的这篇博文:
https://blog.csdn.net/public669/article/details/97610829?spm=1001.2014.3001.5502
准备好数据之后呢,就需要按照yolov8的格式对数据进行装载了
笔者这里是在ultralytics文件下新建了一个dataSets
然后在dataSets下新建images、labels、test、val文件夹
具体如下
images文件下放的是图片数据,具体如下,笔者这里使用的是细胞的数据集
labels文件下存放的是对应图片数据的标签信息
下面的就是就是数据的详细的信息了,这一步是需要使用代码进行装换的,具体的请参考https://blog.csdn.net/public669/article/details/98020800?spm=1001.2014.3001.5502
test文件下的格式也是一样的,需要有两个文件夹,分别是images和lables,同之前的一样,images中放的是用户测试的图片数据,labels下面放的是对应的图片label信息
val文件下的格式同上
数据装载完毕以后,就需要进行对应的yaml文件配置了,需要新建两个yaml文件,分别如下:rbc.yaml和yolov8n.yaml
rbc.yaml文件如下:
train: E:/Projects/ultralytics-main/ultralytics/dataSets/data/images
val: E:/Projects/ultralytics-main/ultralytics/dataSets/data/val/images
test: E:/Projects/ultralytics-main/ultralytics/dataSets/data/test/images# number of classes
nc: 1# class names
names: ['RBC']
yolov8n.yaml文件如下:
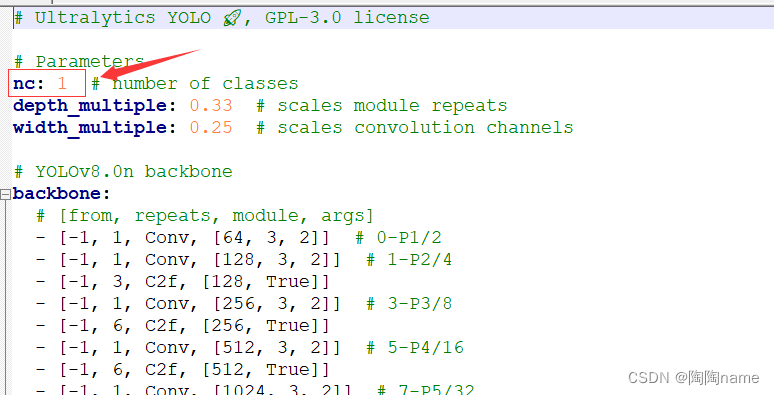
其他的地方都不需要动,只需要给nc修改为1就可以了
具体文件如下:
# Ultralytics YOLO 🚀, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.25 # scales convolution channels# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 17 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 23 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)五、训练
完成了上述的一些操作以后,就可以进行数据的训练了,需要执行cd命令
cd E:\Projects\ultralytics-main\ultralytics\dataSets
训练数据的命令如下:
yolo task=detect mode=train model=yolov8n.pt data=./data/rbc.yaml epochs=100 imgsz=640 resume=Ture
如果有GPU的话,可以对数据进行相应的配置
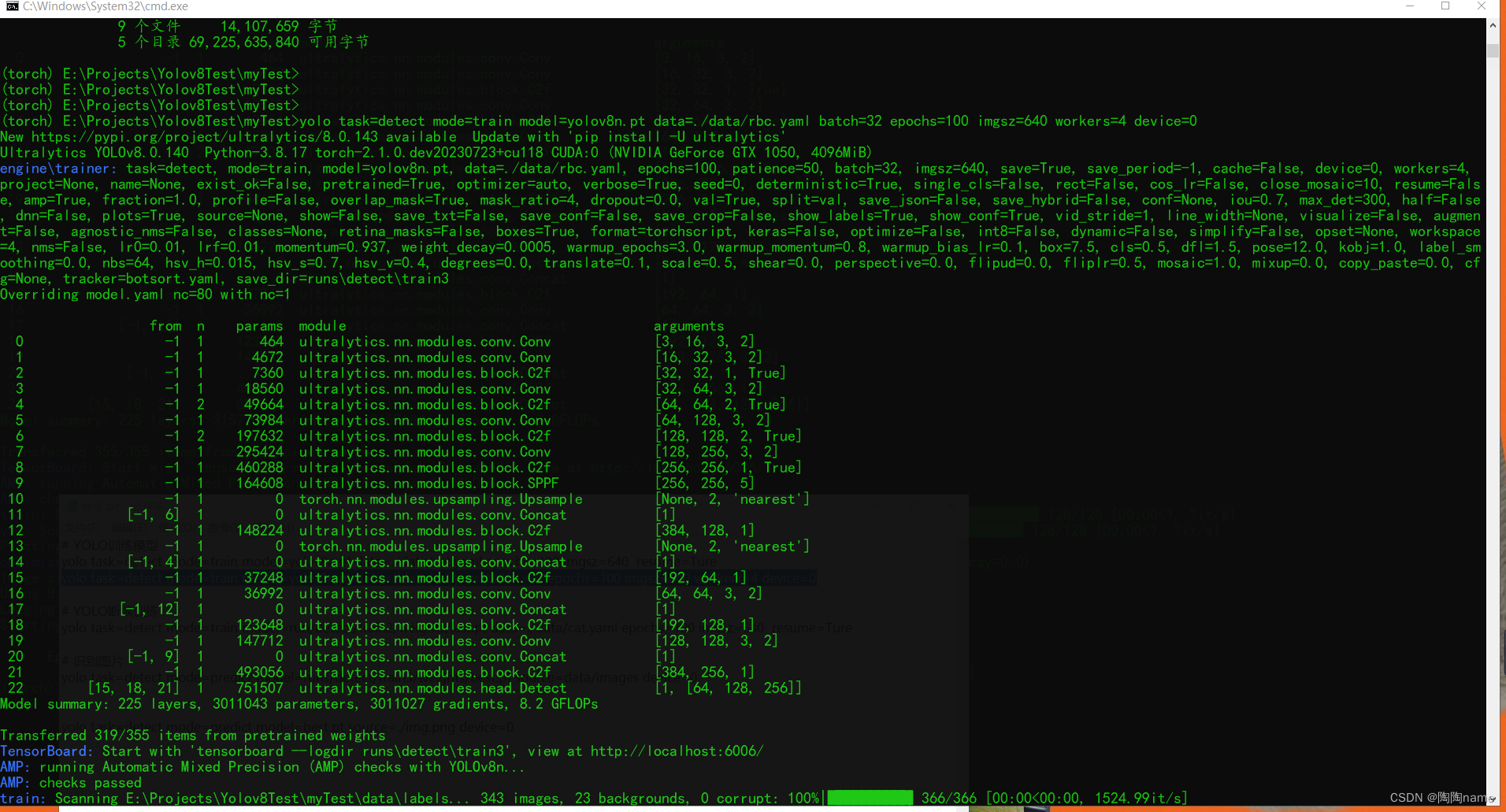
yolo task=detect mode=train model=yolov8n.pt data=./data/rbc.yaml batch=32 epochs=100 imgsz=640 workers=4 device=0
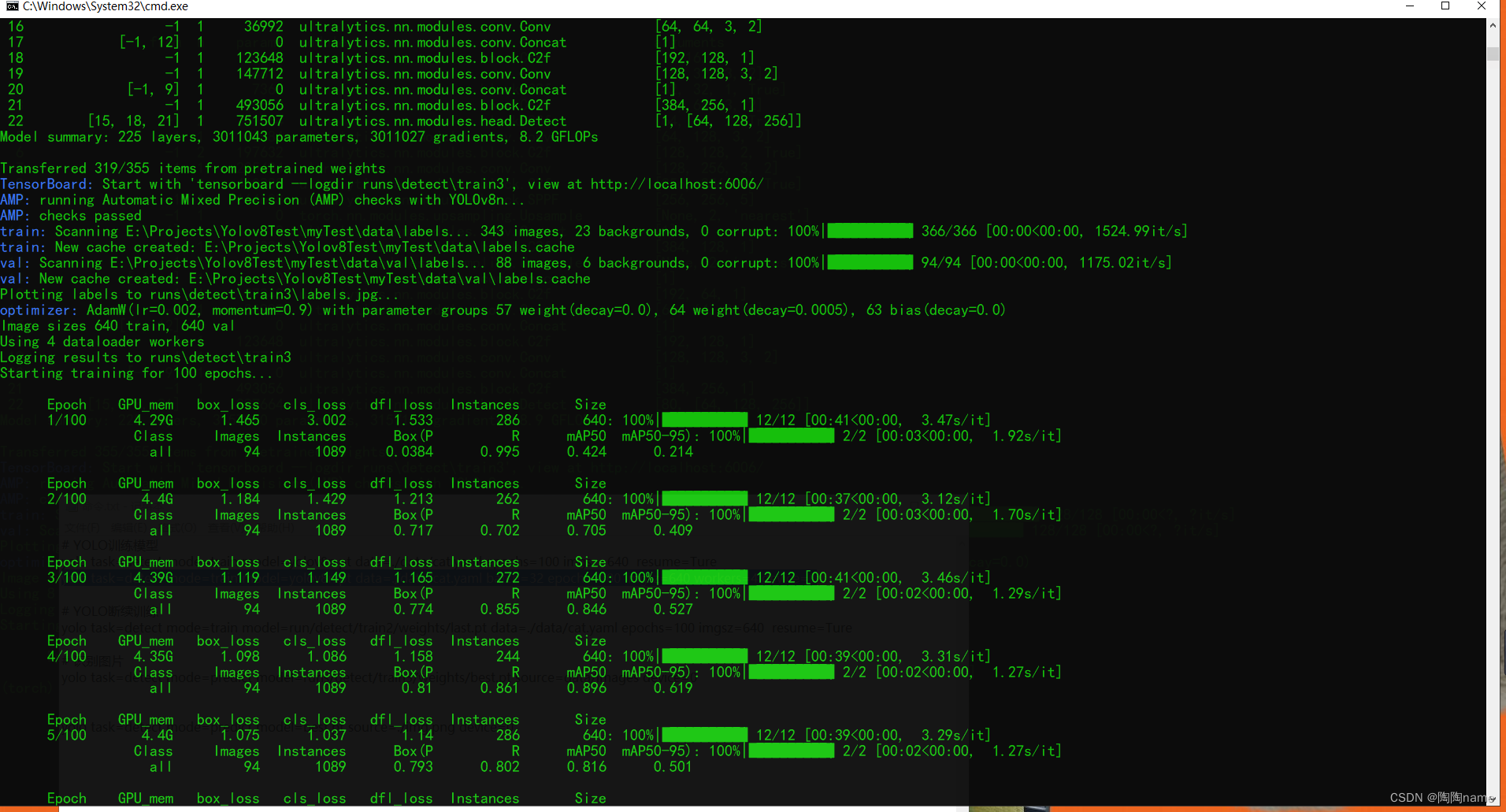
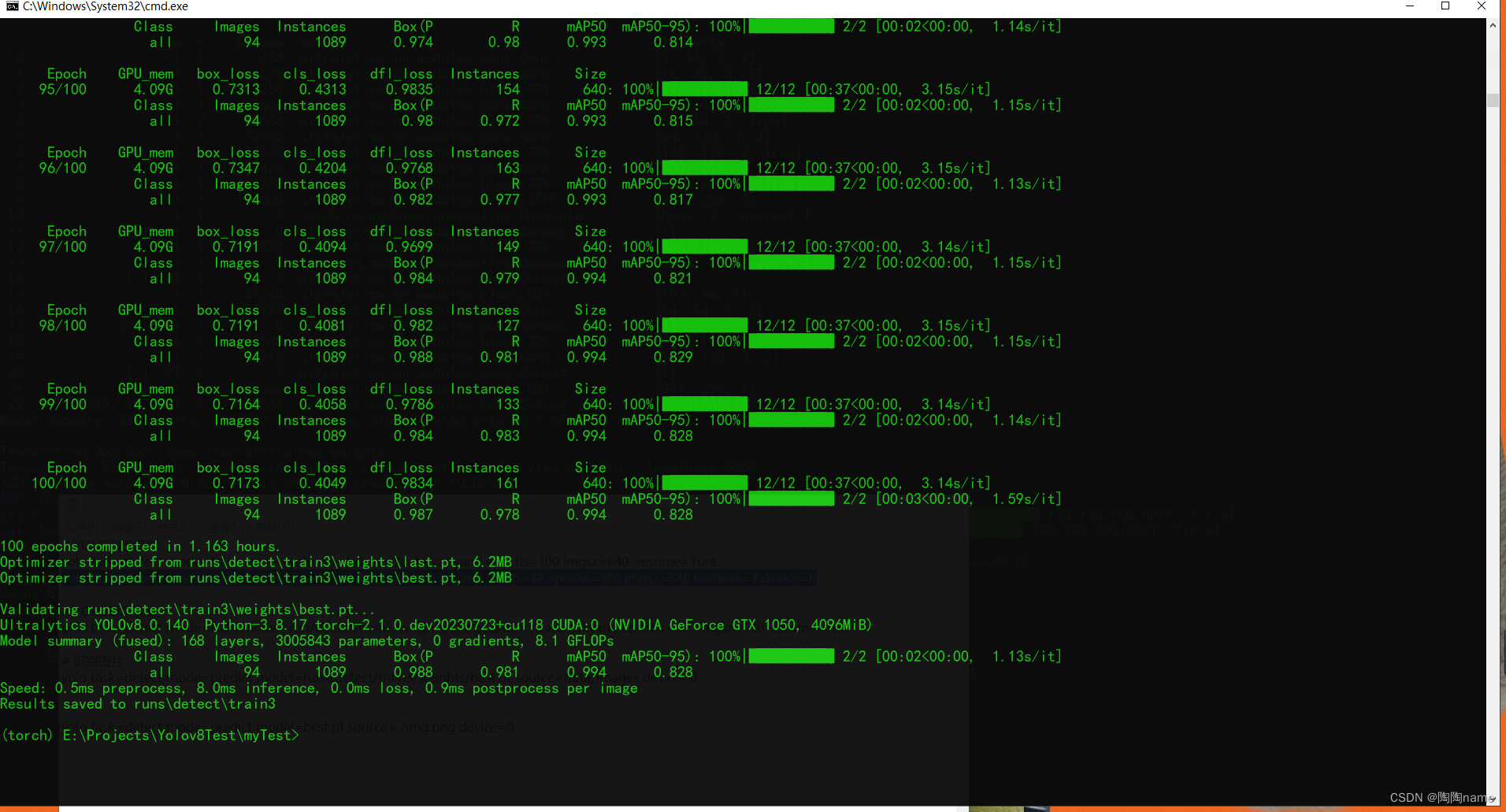
训练效果如下:
六、验证模型
训练结束以后相关的数据都放在
E:\Projects\ultralytics-main\ultralytics\dataSets\runs\detect\train下了
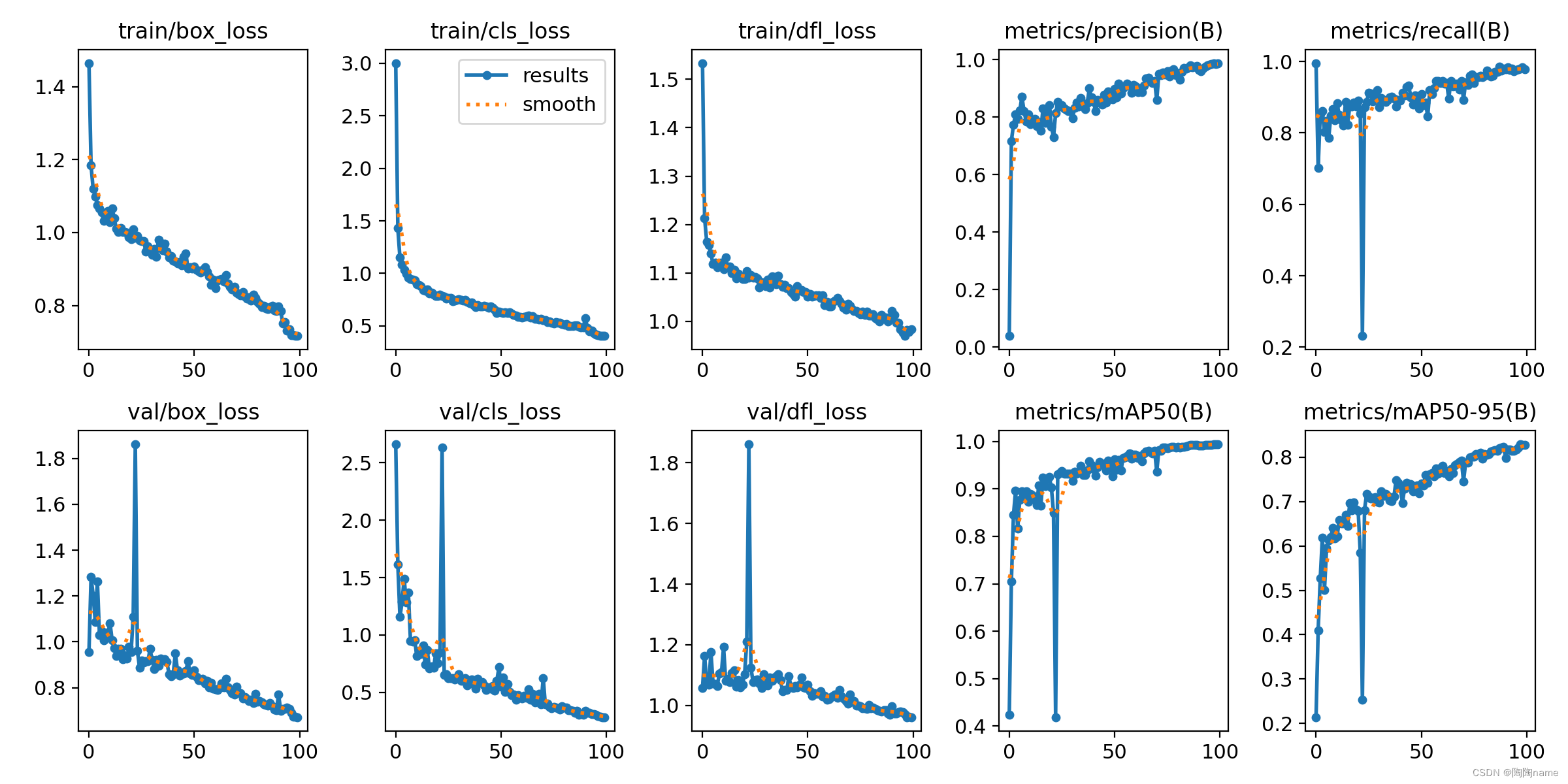
具体的模型都存放在weights下了,具体如下:
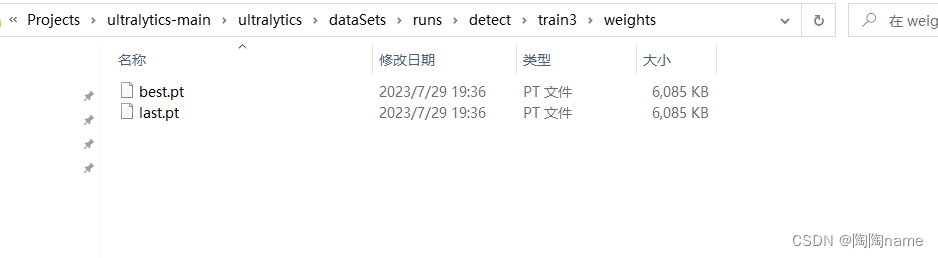
现在我们就需要对模型进行测试了
使用模型的测试命令如下:
yolo task=detect mode=predict model=runs/detect/train3/weights/best.pt source=data/images device=0
如果没有GPU的话,就给device=0给删除了
具体如下:

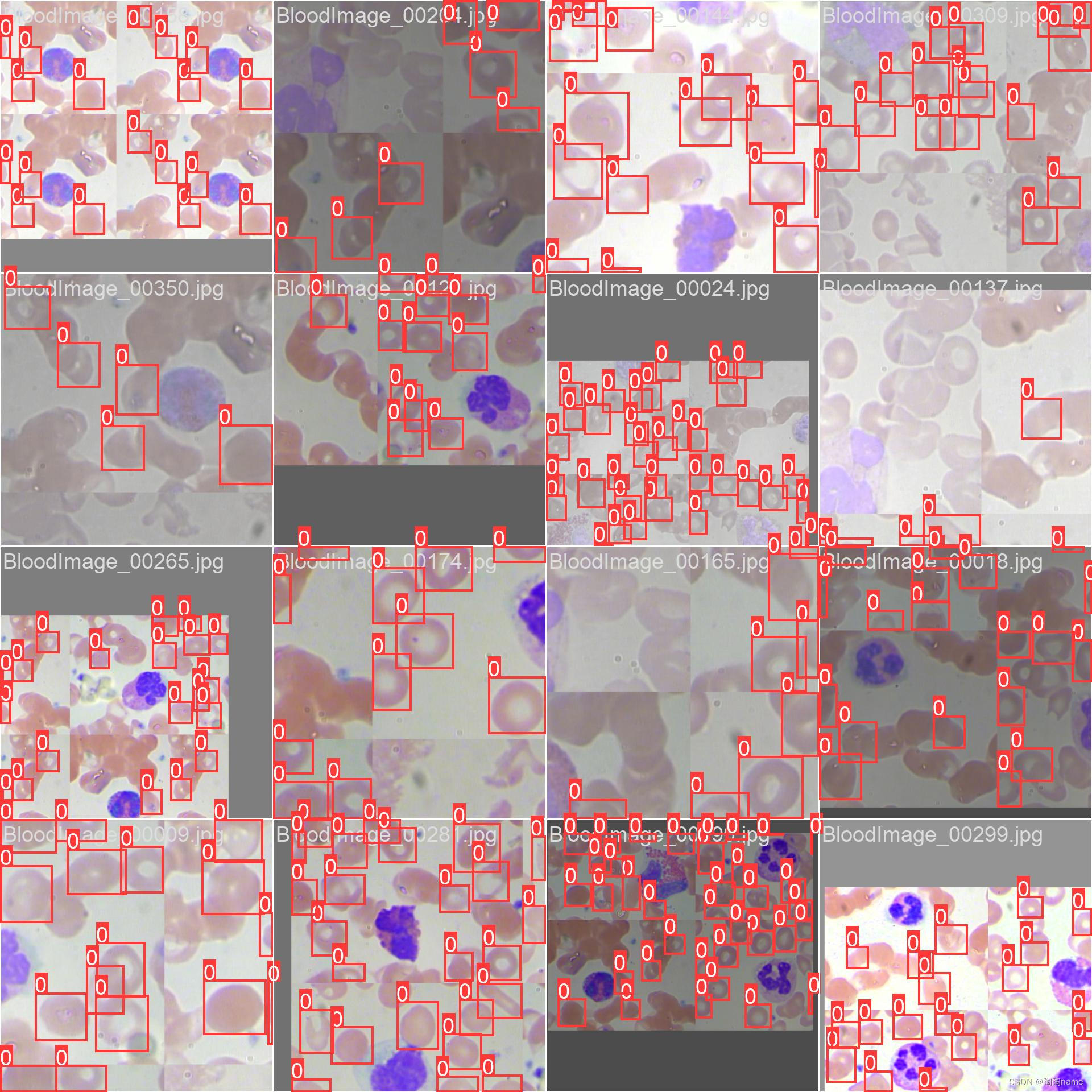
识别的结果如下:
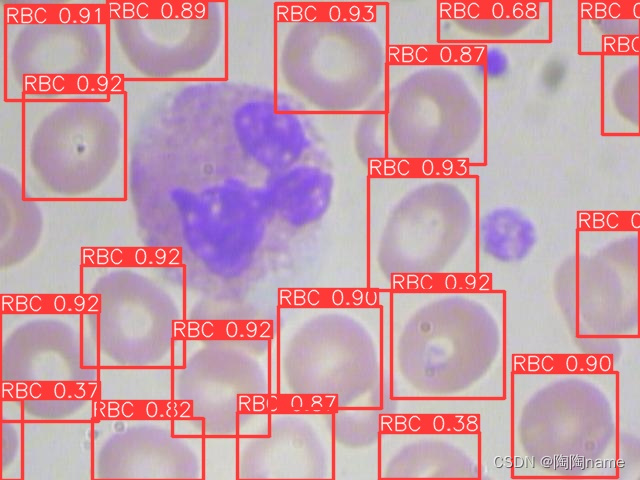
可以看出来效果还是挺好的,相比之前的yolov3效果确实好很多,同时使用步骤方面的话也是挺简洁的。
yolov8训练自己的数据集到这里就结束了,后续会持续分享关于yolov8的应用,请持续关注我,让我们一起学习进步!
由于笔者能力有限,在表达方面可能存在一些不准确的地方,还请多多包涵。