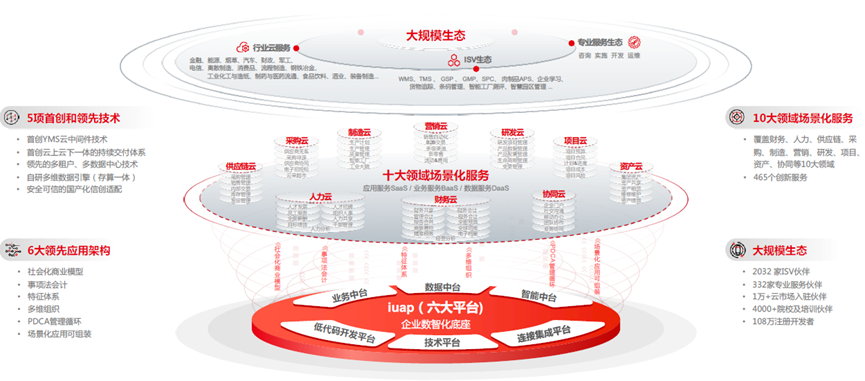
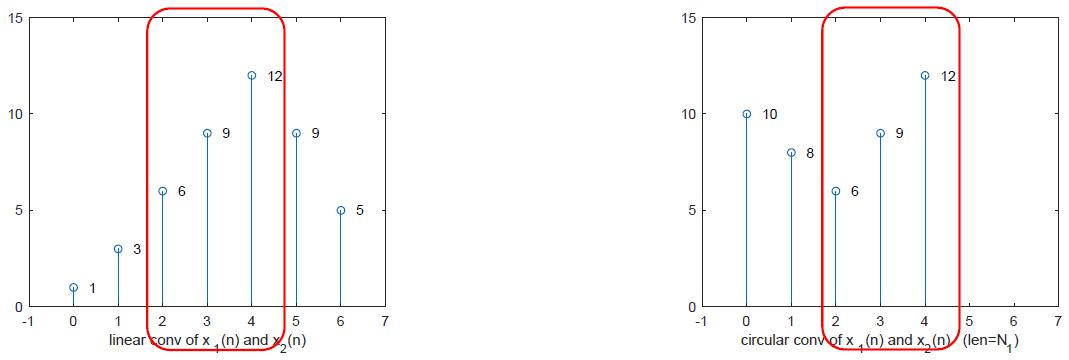
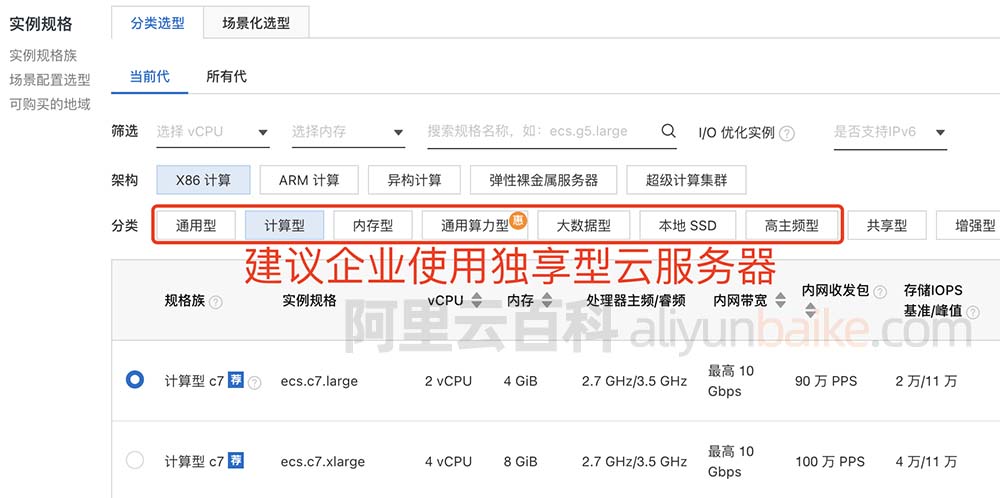
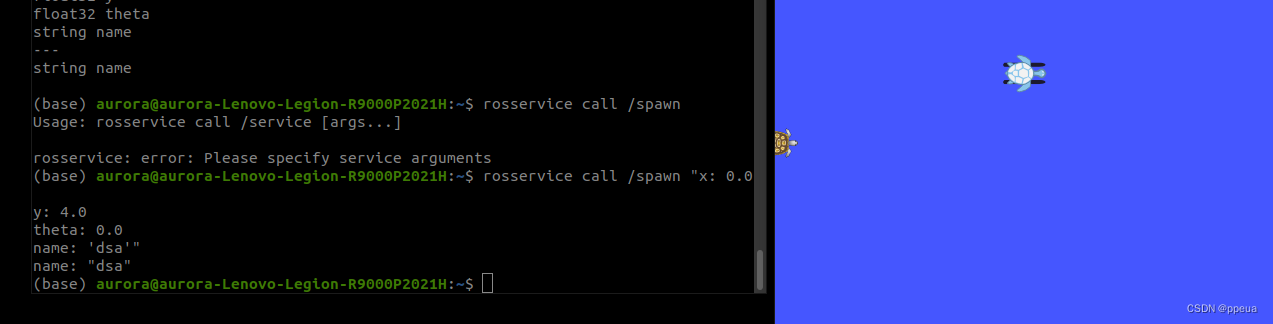
部分数据来源:ChatGPT
引用
在本教程中,我们将使用 Python 语言和 requests、lxml 库来分析和爬取教育漏洞报告平台的数据。
1. 爬取网站数据
首先,我们需要从教育漏洞报告平台上获取需要的数据。我们可以通过 requests 库向特定网址发送请求,获取响应内容。
import requestsurl = 'https://src.sjtu.edu.cn/list/?page=1'
response = requests.get(url)
html_content = response.content在代码中,requests.get() 方法用于向指定的 URL 发送 GET 请求,返回一个 Response 对象。然后,我们可以通过 response.content 属性获取响应的 HTML 内容。
2. 解析 HTML 文档
获取到 HTML 文档后,我们需要从中提取出我们需要的数据。这里我们使用 lxml 库的 etree 模块。

from lxml import htmlhtml_dom = html.fromstring(html_content)
results = html_dom.xpath('//td[@class="am-text-center"]/a/text()')</