目录
- lwIP 初探
- TCP/IP 协议栈是什么
- TCP/IP 协议栈架构
- TCP/IP 协议栈的封包和拆包
- lwIP 简介
- lwIP 源码下载
- lwIP 文件说明
- MAC 内核简介
- PHY 芯片介绍
- YT8512C 简介
- LAN8720A 简介
- 以太网接入MCU 方案
- lwIP 无操作系统移植
- lwIP 带操作系统移植
- ARP 协议
- ARP 协议的简介
- ARP 协议的工作流程
- ARP 缓存表的超时处理
- APR 报文的报文结构
- ARP 协议层的接收与发送原理解析
- 发送ARP 请求数据包
- 接收ARP 应答数据包
- IP 协议
- IP 协议的简介
- IP 数据报
- IP 数据报结构
- IP 数据报的分片解析
- IP 数据报的分片重装
- IP 数据报的输出
- IP 数据报的输入
- ICMP 协议
- ICMP 协议简介
- ICMP 报文类型
- ICMP 报文结构
- ICMP 的实现
- ICMP 数据结构体
- 发送ICMP 差错报文
- ICMP 报文处理
lwIP 初探
本章,先介绍计算机网络相关知识,然后对lwIP 软件库进行概述,接着介绍MAC 内核
的基本知识,最后探讨LAN8720A 和YT8512C 以太网PHY 层芯片。
TCP/IP 协议栈是什么
TCP/IP 协议栈是一系列网络协议的总和,是构成网络通信的核心骨架,它定义了电子设
备如何连入因特网,以及数据如何在它们之间进行传输。TCP/IP 协议采用4 层结构,分别是
应用层、传输层、网络层和网络接口层,每一层都呼叫它的下一层所提供的协议来完成自己的
需求。由于我们大部分时间都工作在应用层,下层的事情不用我们操心;其次网络协议体系本
身就很复杂庞大,入门门槛高,因此很难搞清楚TCP/IP 的工作原理。如果读者想深入了解
TCP/IP 协议栈的工作原理,可阅读《计算机网络书籍》。
TCP/IP 协议栈架构
网络协议有很多,如MQTT、TCP、UDP、IP 等协议,这些协议组成了TCP/IP 协议栈,
同时,这些协议具有层次性,它们分布在应用层,传输层和网络层。TCP/IP 协议栈的分层结
构和网络协议得对应关系如下图所示:
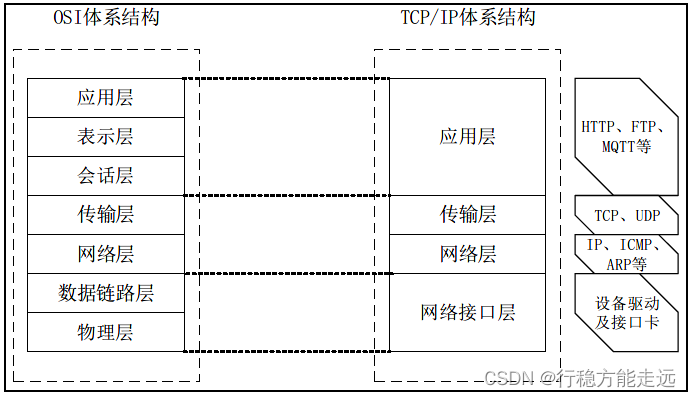
由于OSI 模型和协议比较复杂,所以并没有得到广泛的应用。而TCP/IP 模型因其开放性
和易用性在实践中得到了广泛的应用,它也成为互联网的主流协议。注意:网络技术的发展并
不是遵循严格的OSI 分层概念。实际上现在的互联网使用的是TCP/IP 体系结构有时已经演变
成为图1.1.1.2 所示那样,即某些应用程序可以直接使用IP 层,或甚至直接使用最下面的网络
接口层。
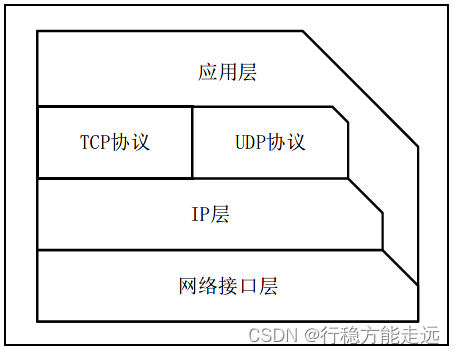
无论那种表示方法,TCP/IP 模型各个层次都分别对应于不同的协议。TCP/IP 协议栈负责
确保网络设备之间能够通信。它是一组规则,规定了信息如何在网络中传输。其中,这些协议
都分布在应用层,传输层和网络层,网络接口层是由硬件来实现。如Windows 操作系统包含
了CBISC 协议栈,该协议栈就是实现了TCP/IP 协议栈的应用层,传输层和网络层的功能,网
络接口层由网卡实现,所以CBISC 协议栈和网卡构建了网络通信的核心骨架。因此,无论哪
一款以太网产品,都必须符合TCP/IP 体系结构,才能实现网络通信。注意:路由器和交换机
等相关网络设备只实现网络层和网络接口层的功能。
TCP/IP 协议栈的封包和拆包
TCP/IP 协议栈的封包和拆包也是一个非常重要的知识,如以太网设备发送数据和接收数
据的处理流程是怎么样的?这个问题涉及到TCP/IP 协议栈对数据处理的流程,该流程称之为
“封包”和“拆包”。“封包”是对发送数据处理的流程,而“拆包”是对接收数据处理的流程,
如下图所示。
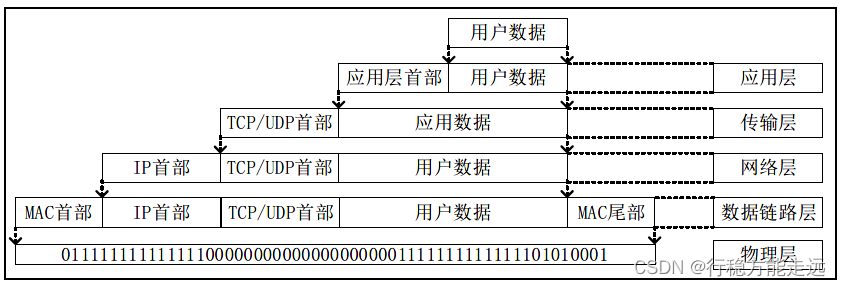
上图中,发送端发送的数据自顶向下依次传递。各层协议依次在数据前添加本层的首部且
设置本层首部的信息,最终将处理后的MAC 帧递交给物理层转成光电模拟信号发送至网络,
这个流程称之为封包流程。
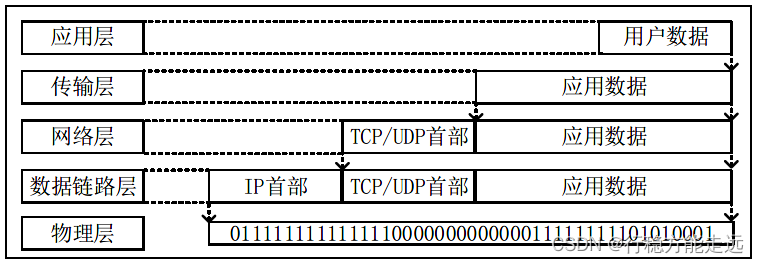
上图中,当帧数据到达目的主机时,将沿着协议栈自底向上依次传递。各层协议依次根据
帧中本层负责的头部信息以获取所需数据,最终将处理后的帧交给应用层,这个流程称之为拆
包的过程。
lwIP 简介
lwIP 是Light Weight(轻型)IP 协议,有无操作系统的支持都可以运行。lwIP 实现的重点
是在保持TCP/IP 协议主要功能的基础上减少对RAM 的占用,它只需十几KB 的RAM 和40K
左右的ROM 就可以运行,这使lwIP 协议栈适合在低端的嵌入式系统中使用。lwIP 的设计理
念下,既可以无操作系统使用,也可以带操作系统使用既可以支持多线程,也可以无线程。它
可以运行在8 位以及32 位的微处理器上,同时支持大端、小端系统。
lwIP 特性参数
lwIP 的各项特性,如下表所示:

lwIP 与TCP/IP 体系结构的对应关系
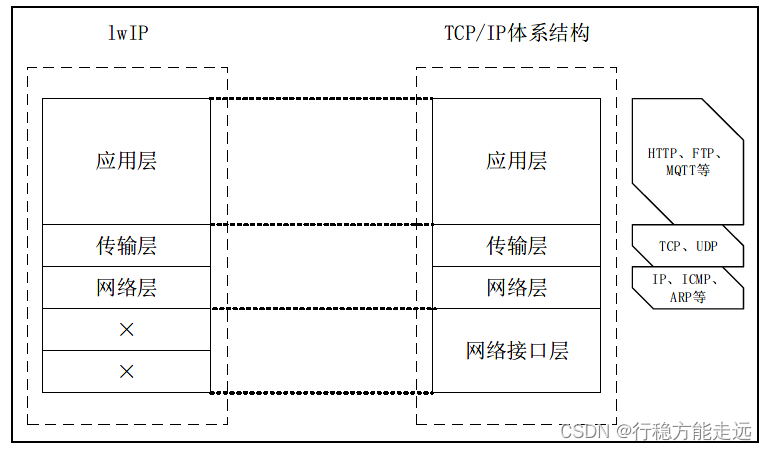
从上图可以看出,lwIP 软件库只实现了TCP/IP 体系结构的应用层、传输层和网络层的功
能,但网络接口层不能使用软件的方式实现,因为网络接口层是把数据包转成光电模拟信号,
并转发至网络,所以网络接口层只能由硬件来实现。
lwIP 源码下载
lwIP 的开发托管在Savannah 上,Savannah 是软件开发、维护和分发。每个人都可以通过
使用Savannah 的界面、Git 和邮件列表下载lwIP 源码包。lwIP 的项目主页:http://savannah.no
ngnu.org/projects/lwip/。在这个主页上,读者需要关注“project homepage”和“download area”
这两个链接地址。
打开lwIP 项目主页之后,往下找到“Quick Overview”选项,如下图所示那样。
点击上图中Project Homepage 链接地址,读者可以看到官方对于lwIP 的说明文档,包括
lwIP 更新日记、常见误解、已发现的BUG、多线程、优化提示和相关文件中的函数描述等内
容。
点击上图中的Domnload Area 链接地址,读者可以看到lwIP 源码和contrib 包的下载网页,
如下图所示那样。由于lwIP 版本居多,因此本教程选择目前最新的lwIP 版本(2.1.3)。下图
中的contrib 包是提供用户lwIP 移植文件和lwIP 相关demo 例程。注:contrib 包不属于lwIP
内核的一部分,它只是为我们提供移植文件和学习实例。
点击上图中的lwip-2.1.3.zip 和contrib-2.1.0.zip 链接,下载完成之后在本地上可以看到这
两个压缩包。
lwIP 文件说明
根据上一个小节的操作,我们已经下载了lwip-2.1.3.zip 和contrib-2.1.0.zip 这两个压缩包。
接下来,笔者带大家认识一下lwip-2.1.3 和contrib-2.1.0 文件夹内的文件。
➢ lwIP 源码包文件说明
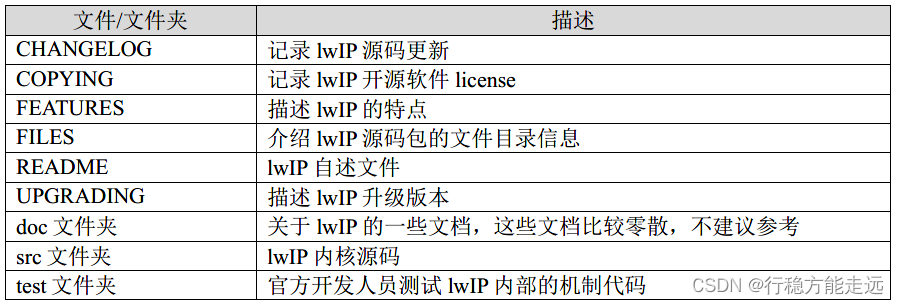
打开lwip-2.1.3 文件夹,如下图所示:

上图中,这个文件夹包含的文件和文件夹非常多,这些文件与文件夹描述如下表所示。
上表中,src 文件夹是lwIP 源码包中最重要的,它是lwIP 的内核文件,也是我们移植到
工程中的重要文件。接下来,笔者重点讲解src 文件夹下的文件与文件夹,如下表所示。

上表中,api 文件夹下的文件是实现应用层与传输层递交数据的接口实现;apps 文件夹下
的文件实现了多种应用层协议;core 文件夹下的文件是构建lwIP 内核的源文件,对应了
TCP/IP 体系架构的传输层、网络层;include 文件夹包含了lwIP 软件库的全部头文件;netif 文
件夹下的文件实现了网络层与数据链路层交互接口,以及管理不同类型的网卡。
打开core 文件夹,我们会发现,lwIP 是由一系列的模块组合而成,这些模块包括:
TCP/IP 协议栈的各种协议、内存管理、数据包管理、网卡管理、网卡接口、基础功能和API
接口模块等,每一个模块是由几个源文件和一个头文件集合,这些头文件全部放在include 文
件夹下,而源文件都是放在core 文件夹下。这些模块描述如下:

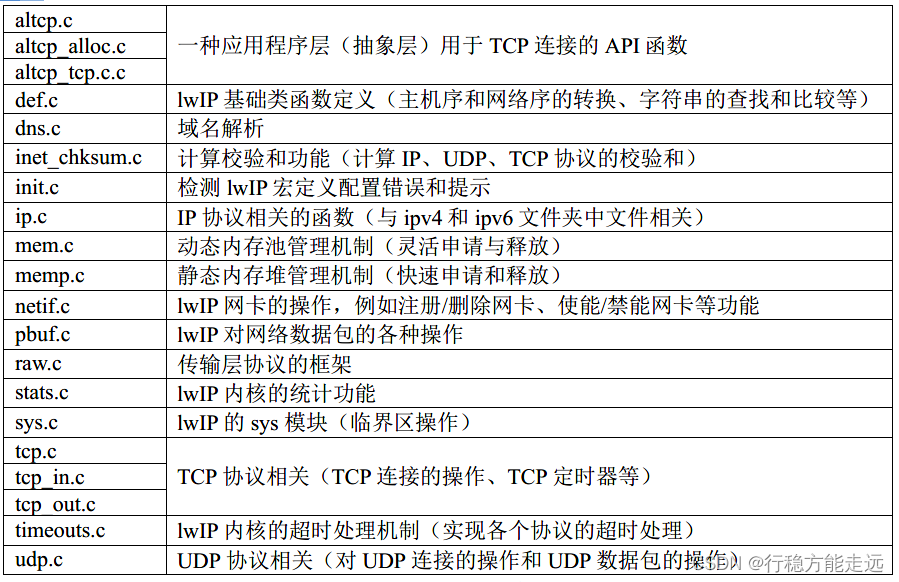
➢ lwIP 的contrib 包文件说明
contrib 包提供了lwIP 移植文件和lwIP 相关demo(应用实例),如下图所示:

上图中,ports 文件夹提供了lwIP 基于FreeRTOS 操作系统的移植文件;examples 和apps
文件夹提供读者学习lwIP 的应用实例。至此,lwIP 源码库和contrib 包介绍完毕。
MAC 内核简介
STM32 内置了一个MAC 内核,它实现了TCP/IP 体系架构的数据链路层功能。STM32 内
置以太网架构如下所示:
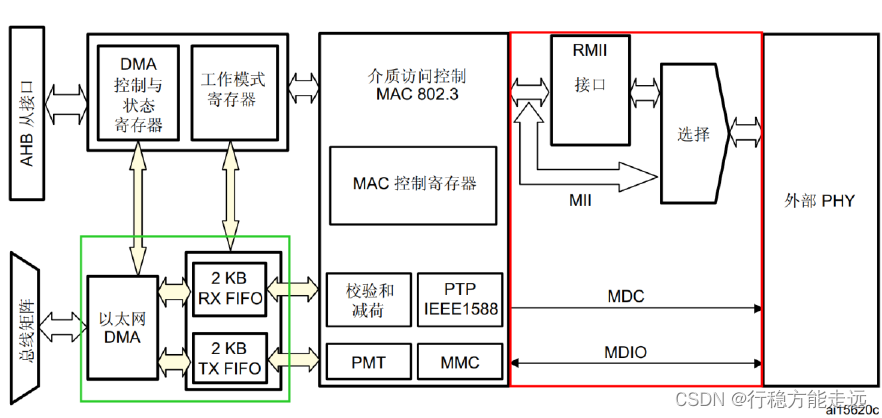
从上图可以看出,绿色框框的RX FIFO 和TX FIFO 都是2KB 的物理存储器,它们分别存
储网络层递交的以太网数据和接收的以太网数据。以太网DMA 是网络层和数据链路层的中间
桥梁,是利用存储器到存储器方式传输。红色框框的内容可分为两个部分讲解,RMII 与MII
是MAC 内核(数据链路层)与PHY 芯片(物理层)的数据交互通道,用来传输以太网数据。
MDC 和MDIO 是MAC 内核对PHY 芯片的管理和配置,是站管理接口(SMI)所需的通信引
脚。站管理接口(SMI)允许应用程序通过2 条线:时钟(MDC)和数据线(MDIO)访问任
意PHY 寄存器。该接口支持访问多达32 个PHY。应用程序可以从32 个PHY 中选择一个
PHY,然后从任意PHY 包含的32 个寄存器中选择一个寄存器,发送控制数据或接收状态信息。
任意给定时间内只能对一个PHY 中的一个寄存器进行寻址。在MAC 对PHY 进行读写操作的
时候,应用程序不能修改MII 的地址寄存器和MII 的数据寄存器。在此期间对MII 地址寄存
器或MII 数据寄存器执行的写操作将会被忽略。例如关于SMI 接口的详细介绍大家可以参考
STM32F4xx 中文参考手册的824 页。
➢ 介质独立接口:MII
MII 用于MAC 层与PHY 层进行数据传输。MCU 通过MII 与PHY 层芯片的连接图如下。
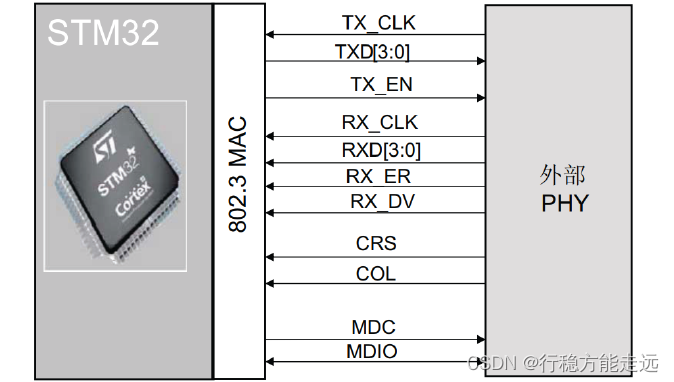
从图中可以看出,MII 介质接口使用的引脚数量是非常多的,这也反映出引脚紧缺的
MCU 不适合使用MII 介质接口来实现以太网数据传输,MII 接口引脚的作用如下所示。
MII_TX_CLK:连续时钟信号。该信号提供进行TX 数据传输时的参考时序。标称频
率为:速率为10 Mbit/s 时为2.5 MHz;速率为100 Mbit/s 时为25 MHz。
MII_RX_CLK:连续时钟信号。该信号提供进行RX 数据传输时的参考时序。标称频
率为:速率为10 Mbit/s 时为2.5 MHz;速率为100 Mbit/s 时为25 MHz。
MII_TX_EN:发送使能信号。
MII_TXD[3:0]:数据发送信号。该信号是4 个一组的数据信号。
MII_CRS:载波侦听信号。
MII_COL:冲突检测信号。
MII_RXD[3:0]:数据接收信号。该信号是4 个一组的数据信号
MII_RX_DV:接收数据有效信号。
MII_RX_ER:接收错误信号。该信号必须保持一个或多个周期(MII_RX_CLK),从而
向MAC 子层指示在帧的某处检测到错误。
➢ 精简介质独立接口:RMII
精简介质独立接口(RMII)规范降低10/100Mbit/s 下微控制器以太网外设与外部PHY 间
的引脚数。根据IEEE 802.3u 标准,MII 包括16 个数据和控制信号的引脚,而RMII 规范将引
脚数减少为7 个。
MCU 通过RMII 接口与PHY 层芯片的连接图如下图所示。因为RMII 相比MII,其发送和
接收都少了两条线。因此要达到10Mbit/s 的速度,其时钟频率应为5MHZ,同理要达到
100Mbit/s 的速度其时钟频率应为50MHz。正点原子开发板就是采用此接口连接PHY 芯片。
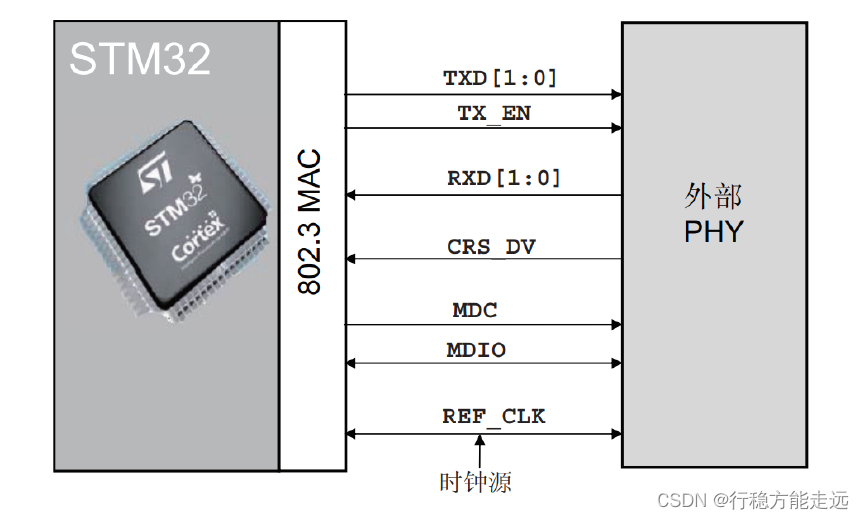
可以看出,REF_CLK 引脚需要提供50MHz 时钟频率,它分别提供MAC 内核和PHY 芯
片,确保它们时钟同步。
PHY 芯片介绍
PHY 芯片在TCP/IP 体系架构中扮演着物理层的角色,它把数据转换成光电模拟信号传输
至网络当中。本小节为读者介绍正点原子常用的PHY 芯片,它们分别为LAN8720A 和YT8512C,这两款PHY 芯片都是支持10/100BASE-T 百兆以太网传输速率,为此笔者分两个
小节来讲解这两款以太网芯片的知识。
YT8512C 简介
YT8512C 是低功耗单端口10/100Mbps 以太网PHY 芯片。它通过两条标准双绞线电缆收
发器发送和接收数据所需的所有物理层功能。另外,YT8512C 通过标准MII 和RMII 接口连接
到MAC 层。YT8512C 功能结构图如下图所示:
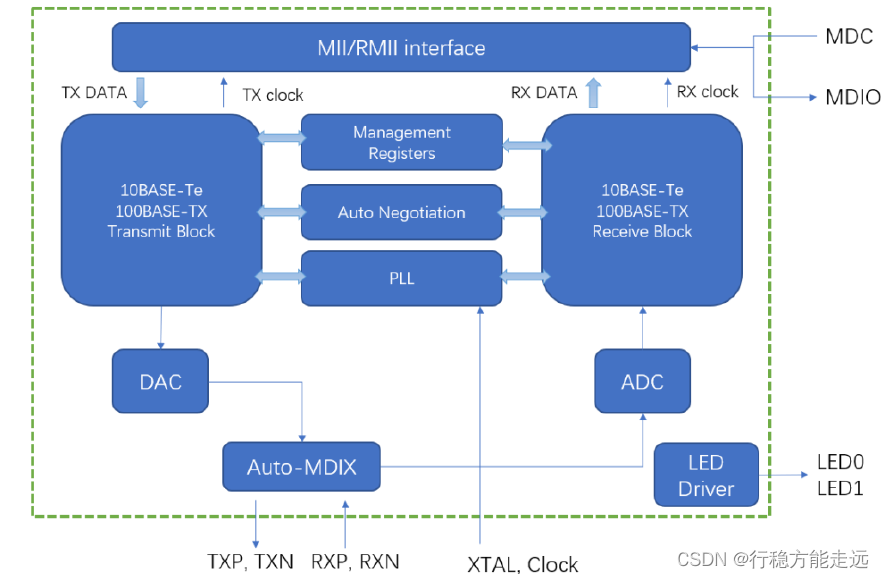
上图是YT8512C 芯片的内部总架构示意图,从图中我们大概可以看出,它通过
LED0\LED1 引脚的电平来设置PHY 地址,由XTAL,Clock 引脚提供PHY 内部时钟,同时
TXP\TXN\RXP\RXN 引脚连接到RJ45(网口)。
➢ PHY 地址设置
MAC 层通过SMI 总线对PHY 芯片进行读写操作,SMI 可以控制32 个PHY 芯片,通过
PHY 地址的不同来配置对应的PHY 芯片。YT8512C 芯片的PHY 地址设置如下表所示:

上表中,我们可通过YT8512C 芯片的LED0/PHYADD0 和LED1/PHYADD1 引脚电平来设
置PHY 地址。由于正点原子板载的PHY 芯片是把这两个引脚拉低,所以它的PHY 地址为
0x00。打开HAL 配置文件或者打开PHY 配置文件,我们在此文件下配置PHY 地址,这些文
件如下表所示:

可以看到,探索者和DMF407 开发板的PHY 地址在stm32f4xx_hal_conf.h 文件下设置的,
而阿波罗和北极星开发板的PHY 地址在ethernet_chip.h 文件下设置的。因为探索者与
DMF407 使用的HAL 库版本比阿波罗与北极星开发板所使用的HAL 库版本旧,所以它们的移
植流程存在巨大的差异。这里笔者暂且不讲解这部分的内容。
➢ YT8521C 的RMII 接口介绍
YT8521C 的RMII 接口提供了两种RMII 模式,这两种模式分别为:
RMII1 模式:这个模式下YT8521C 的TXC 引脚不会输出50MHz 时钟。该模式的连
接示意图如下图1.4.1.2 所示。
RMII2 模式:这个模式下YT8521C 的TXC 引脚会输出50MHz 时钟。该模式的连接
示意图如下图1.4.1.3 所示。
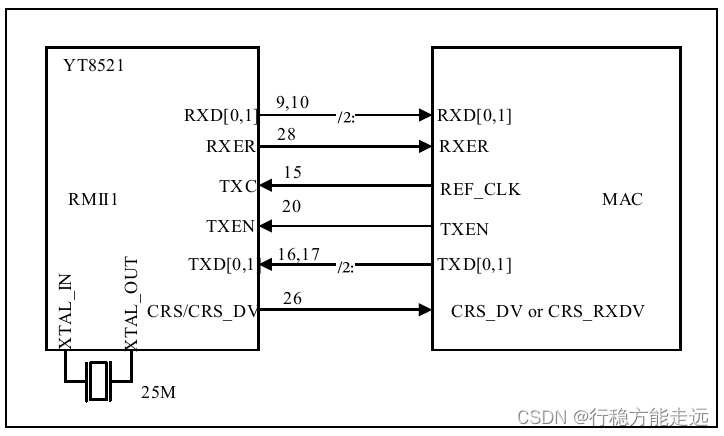
对于RMII 接口而言,外部必须提供50MHz 的时钟驱动PHY 与MAC 内核,该时钟为了
使PHY 芯片与MAC 内核保持时钟同步操作,它可以来自PHY 芯片、有源晶振或者STM32
的MCO 引脚。如果我们的电路采用RMII1 模式的话,那么PHY 芯片由25MHz 晶振经过内部
PLL 倍频达到50MHz,但是MAC 内核没有被提供50MHz 与PHY 芯片保持时钟同步,所以我
们必须在此基础上使用MCO 或外部接入50MHz 晶振提供时钟给MAC 内核,以保持时钟同步。
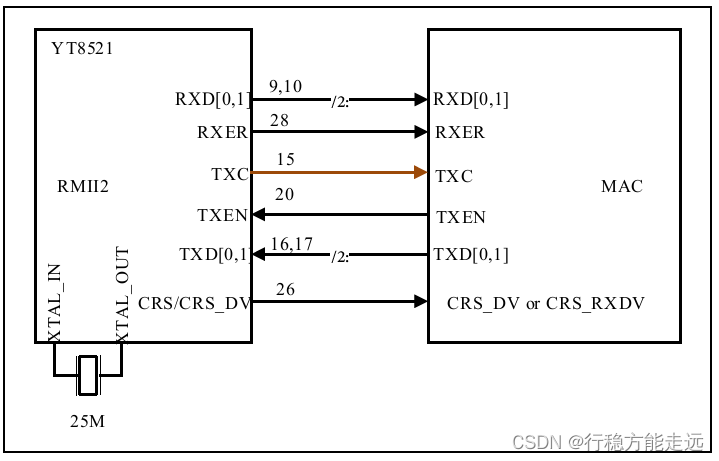
如果电路使用上图模式连接的话,那么PHY 芯片经过外接晶振25MHz 和内部PLL 倍频
操作,最终PHY 芯片内部的时钟为50MHz。接着PHY 芯片外围引脚TXC 会输出50MHz 时
钟频率,该时钟频率可输入到MAC 内核保持时钟同步,这样我们无需外接晶振或者MCO 提
供MAC 内核时钟。
注:RMII1 模式和RMII2 模式的选择是由YT8521C 的RX_DV(8)和RXD3(12)引脚
决定,具体如何选择,请读者参考“YT8512C.PDF”手册的17 到18 页的内容。
➢ YT8521C 的寄存器介绍
PHY 是由IEEE 802.3 定义的,一般通过SMI 对PHY 进行管理和控制,也就是读写PHY
内部寄存器。PHY 寄存器的地址空间为5 位,可以定义0 ~ 31 共32 个寄存器,但是,随着
PHY 芯片功能的增加,很多PHY 芯片采用分页技术来扩展地址空间,定义更多的寄存器,在
这里笔者不讨论这种情况,IEEE 802.3 定义了0~15 这16 个寄存器的功能,而16~31 寄存器由
芯片制造商自由定义的。
在YT8521C 中有很多寄存器,这里笔者只介绍几个用到的寄存器(包括寄存器地址,此
处使用十进制表示):BCR(0),BSR(1),PHY 特殊功能寄存器(17)这三个寄存器。首先
我们来看一下BCR(0)寄存器,BCR 寄存器各位介绍如下表所示。
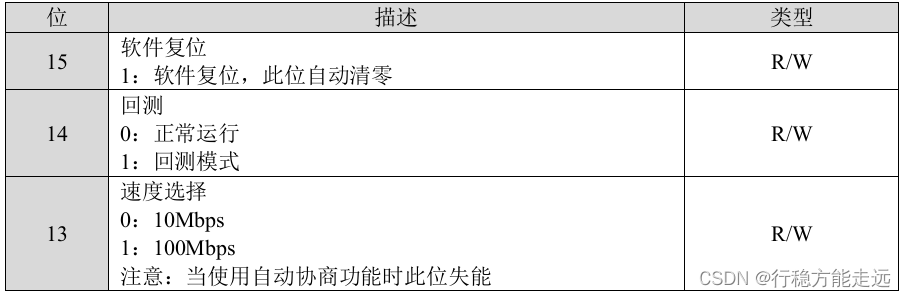
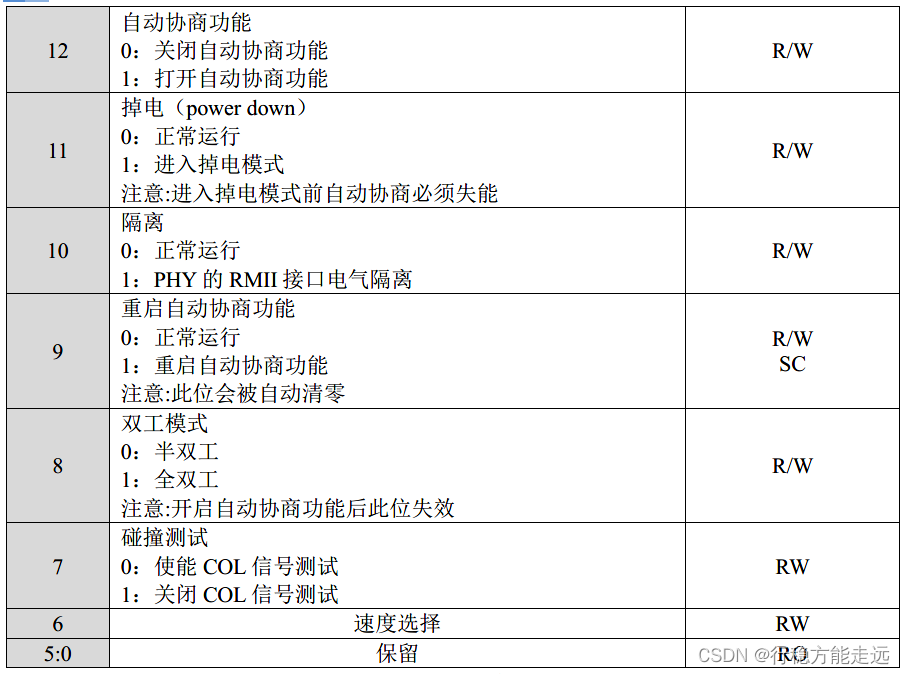
我们设置以太网速率和双工,其实就是配置PHY 芯片的BCR 寄存器。在HAL 配置文件
或者ethernet_chip.h 文件定义了BCR 和BSR 寄存器,代码如下:
探索者、DMF407 开发板(HAL 配置文件下):
#define PHY_BCR ((uint16_t)0x0000)
#define PHY_BSR ((uint16_t)0x0001)
阿波罗、北极星开发板(PHY 配置文件下):
#define ETH_CHIP_BCR ((uint16_t)0x0000U)
#define ETH_CHIP_BSR ((uint16_t)0x0001U)
由于探索者及DMF407 开发板的例程是使用V1.26 版本的HAL 库,所以这两个寄存器并
不需要读者来操作,原因就是我们调用HAL_ETH_Init 函数以后系统就会根据我们输入的参数
配置YT8521C 的相应寄存器。但是,阿波罗及北极星开发板的例程使用目前最新的HAL 版本,
它要求读者手动操作BCR 寄存器,例如自动协商、软复位等操作。
BSR 寄存器各个位介绍如下表所示:

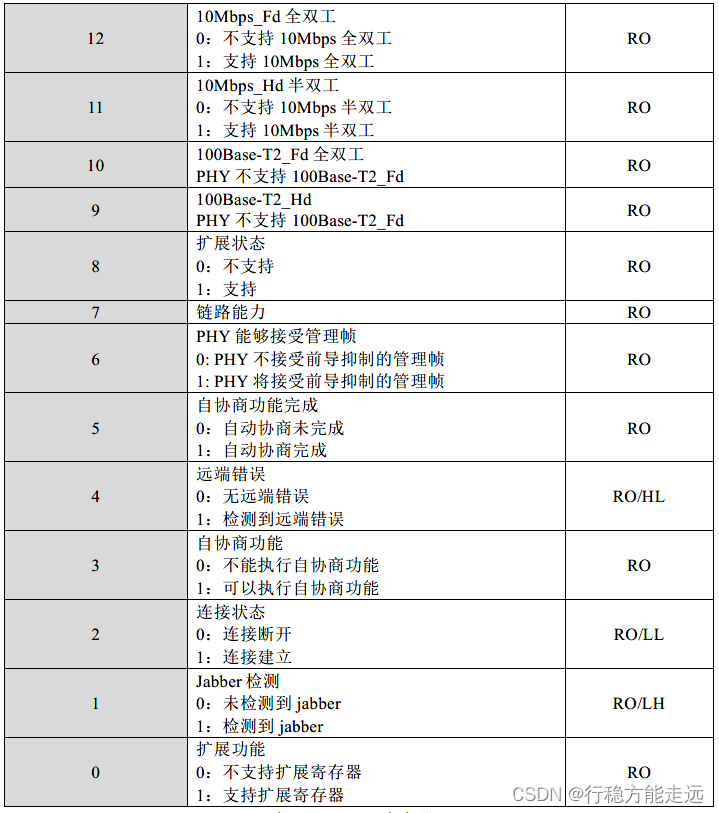
BSR 寄存器为YT8521C 的状态寄存器,通过读取该寄存器的值我们可以得到当前的连接
速度、双工状态和连接状态等信息。
接下来,笔者介绍的是YT8521C 特殊功能寄存器,此寄存器的各位如下表所示:

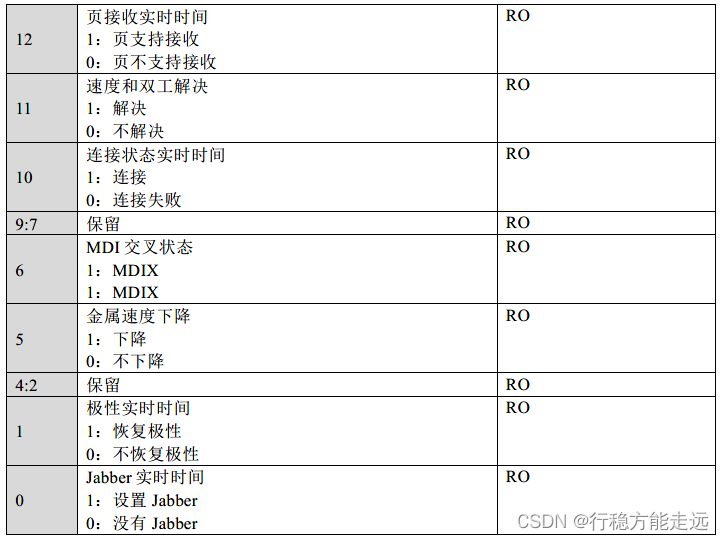
在特殊功能寄存器中我们关心的是bit13~bit15 这三位,因为系统通过读取这3 位的值来
设置BCR 寄存器的bit8 和bit13。由于特殊功能寄存器不属于IEEE802.3 规定的前16 个寄存
器,所以每个厂家的可能不同,这个需要用户根据自己实际使用的PHY 芯片去修改。
ST 提供的以太网驱动文件有三个配置项值得读者注意的,它们分别为PHY_SR、PHY_SP
EED_STATUS 和PHY_DUPLEX_STATUS 配置项,这些配置项用来描述PHY 特殊功能寄存器,
根据该寄存器的值设置BCR 寄存器的第8 位和第13 位,即双工和网速。
探索者、DMF407 开发板:
/* 网卡PHY地址设置*/
#define ETHERNET_PHY_ADDRESS 0x00
/* 选择PHY芯片*/
#define LAN8720 0
#define SR8201F 1
#define YT8512C 2
#define RTL8201 3
#define PHY_TYPE YT8512C
#if(PHY_TYPE == LAN8720)
#define PHY_SR ((uint16_t)0x1F) /* PHY状态寄存器地址*/
#define PHY_SPEED_STATUS ((uint16_t)0x0004) /* PHY速度状态*/
#define PHY_DUPLEX_STATUS ((uint16_t)0x0010) /* PHY双工状态*/
#elif(PHY_TYPE == SR8201F)
#define PHY_SR ((uint16_t)0x00) /* PHY状态寄存器地址*/
#define PHY_SPEED_STATUS ((uint16_t)0x2020) /* PHY速度状态*/
#define PHY_DUPLEX_STATUS ((uint16_t)0x0100) /* PHY双工状态*/
#elif(PHY_TYPE == YT8512C)
#define PHY_SR ((uint16_t)0x11) /* PHY状态寄存器地址*/
#define PHY_SPEED_STATUS ((uint16_t)0x4010) /* PHY速度状态*/
#define PHY_DUPLEX_STATUS ((uint16_t)0x2000) /* PHY双工状态*/
#elif(PHY_TYPE == RTL8201)
#define PHY_SR ((uint16_t)0x10) /* PHY状态寄存器地址*/
#define PHY_SPEED_STATUS ((uint16_t)0x0022) /* PHY速度状态*/
#define PHY_DUPLEX_STATUS ((uint16_t)0x0004) /* PHY双工状态*/
阿波罗、北极星开发板:
/* PHY地址*/
#define ETH_CHIP_ADDR ((uint16_t)0x0000U)
/* 选择PHY芯片*/
#define LAN8720 0
#define SR8201F 1
#define YT8512C 2
#define RTL8201 3
#define PHY_TYPE YT8512C
#if(PHY_TYPE == LAN8720)
#define ETH_CHIP_PHYSCSR ((uint16_t)0x1F)
#define ETH_CHIP_SPEED_STATUS ((uint16_t)0x0004)
#define ETH_CHIP_DUPLEX_STATUS ((uint16_t)0x0010)
#elif(PHY_TYPE == SR8201F)
#define ETH_CHIP_PHYSCSR ((uint16_t)0x00)
#define ETH_CHIP_SPEED_STATUS ((uint16_t)0x2020)
#define ETH_CHIP_DUPLEX_STATUS ((uint16_t)0x0100)
#elif(PHY_TYPE == YT8512C)
#define ETH_CHIP_PHYSCSR ((uint16_t)0x11)
#define ETH_CHIP_SPEED_STATUS ((uint16_t)0x4010)
#define ETH_CHIP_DUPLEX_STATUS ((uint16_t)0x2000)
#elif(PHY_TYPE == RTL8201)
#define ETH_CHIP_PHYSCSR ((uint16_t)0x10)
#define ETH_CHIP_SPEED_STATUS ((uint16_t)0x0022)
#define ETH_CHIP_DUPLEX_STATUS ((uint16_t)0x0004)
#endif /* PHY_TYPE */
笔者已经适配了多款PHY 芯片,根据PHY_TYPE 配置项来选择PHY_SR、PHY_SPEED_
STATUS 和PHY_DUPLEX_STATUS 配置项的数值。
LAN8720A 简介
LAN8720A 是一款低功耗的10/100M 以太网PHY 层芯片,它通过RMII/MII 介质接口与
以太网MAC 层通信,内置10-BASE-T/100BASE-TX 全双工传输模块,支持10Mbps 和
100Mbps。LAN8720A 主要特点如下:
高性能的10/100M 以太网传输模块。
支持RMII 接口以减少引脚数。
支持全双工和半双工模式。
两个状态LED 输出。
可以使用25M 晶振以降低成本。
支持自协商模式。
支持HP Auto-MDIX 自动翻转功能。
支持SMI 串行管理接口。
支持MAC 接口。
LAN8720A 功能框图如下图所示:
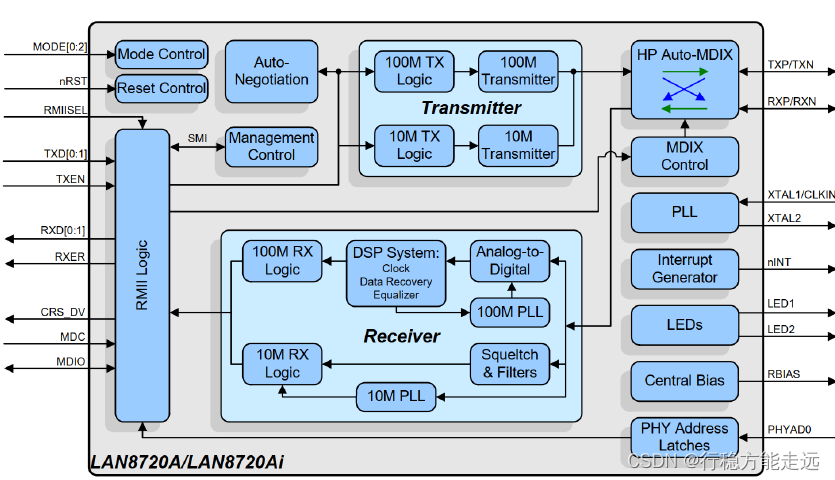
➢ LAN8720A 中断管理
LAN8720A 的器件管理接口支持非IEEE 802.3 规范的中断功能。当一个中断事件发生并且
相应事件的中断位使能,LAN8720A 就会在nINT(14 脚)产生一个低电平有效的中断信号。LA
N8720A 的中断系统提供两种中断模式:主中断模式和复用中断模式。主中断模式是默认中断
模式,LAN8720A 上电或复位后就工作在主中断模式,当模式控制/状态寄存器(十进制地址为
17)的ALTINT 为0 是LAN8720 工作在主模式,当ALTINT 为1 时工作在复用中断模式。正点
原子的STM32 系列开发板并未用到中断功能,关于中断的具体用法可以参考LAN8720A 数据
手册的29,30 页。
➢ PHY 地址设置
MAC 层通过SMI 总线对PHY 进行读写操作,SMI 可以控制32 个PHY 芯片,通过不同
的PHY 芯片地址来对不同的PHY 操作。LAN8720A 通过设置RXER/PHYAD0 引脚来设置其P
HY 地址,默认情况下为0,其地址设置如下表所示。正点原子的STM32 系列开发板使用的是
默认地址,也就是0X00。

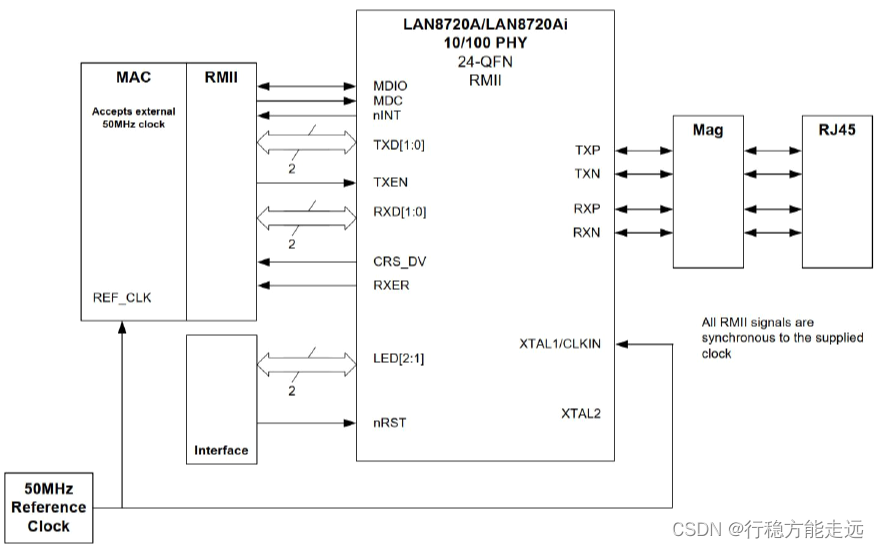
➢ nINT/REFCLKO 配置
nINTSEL 引脚(2 号引脚)用于设置nINT/REFCLKO 引脚(14 号引脚)的功能。
nINTSEL 配置如下表所示。

当工作在REF_CLK In 模式时,50MHz 的外部时钟信号应接到LAN8720 的XTAL1/CKIN
引脚(5 号引脚)和STM32 的RMII_REF_CLK(PA1)引脚上,如下图所示。
为了降低成本,LAN8720A 可以从外部的25MHz 的晶振中产生REF_CLK 时钟。到要使
用此功能时应工作在REF_CLK Out 模式。当工作在REF_CLO Out 模式时REF_CLK 的时钟源
如下图所示。
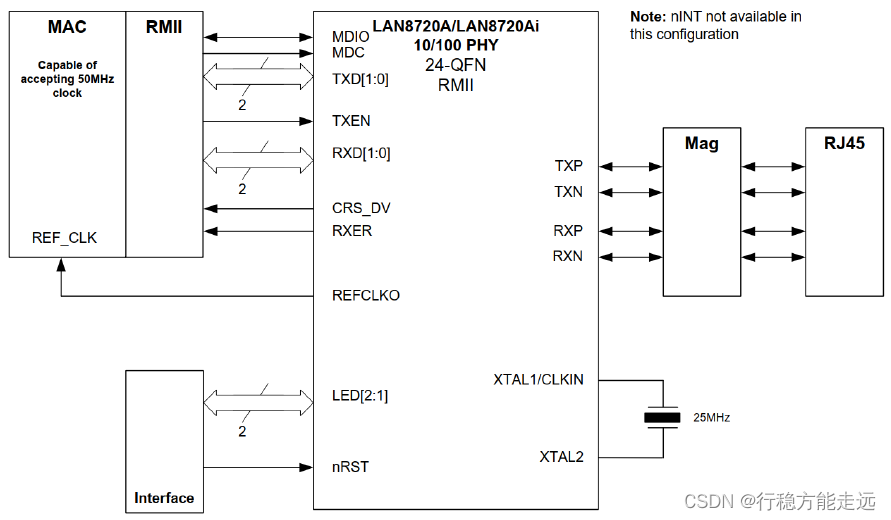
➢ LAN8720A 内部寄存器
PHY 是由IEEE 802.3 定义的,一般通过SMI 对PHY 进行管理和控制,也就是读写PHY 内
部寄存器。PHY 寄存器的地址空间为5 位,可以定义0~31 共32 个寄存器,但是随之PHY 芯
片功能的增加,很多PHY 芯片采用分页技术来扩展地址空间,定义更多的寄存器,在这里我
们不讨论这种情况。IEEE 802.3 定义了0~15 这16 个寄存器的功能,16~31 寄存器由芯片制造
商自由定义。在LAN8720A 有很多寄存器,笔者重点讲解BCR(0),BSR(1),PHY 特殊功
能寄存器(31)这三个寄存器,前面两个寄存器笔者已经在1.6.1 小节讲解了,这里笔者无需
重复讲解。接下来介绍的是LAN8720A 特殊功能寄存器,此寄存器的各个位如下表所示:
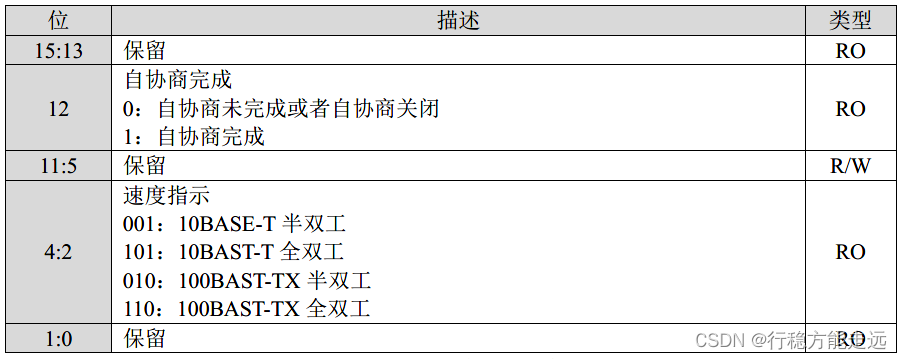
在特殊功能寄存器中我们关心的是bit2~bit4 这三位,因为系统通过读取这3 位的值来设
置BCR 寄存器的bit8 和bit13。
以太网接入MCU 方案
以太网接入方案一般分为两种,它们分别为全硬件TCP/IP 协议栈和软件TCP/IP 协议栈,
其中,软件TCP/IP 协议栈用途非常广泛,如电脑、交换机等网络设备,而全硬件TCP/IP 协议
栈是近年来比较新型的以太网接入方案。下面笔者分别来讲解这两种接入方案的差异和优缺点。
➢ 软件TCP/IP 协议栈以太网接入方案
这种方案由lwIP+ MAC 内核+PHY 层芯片实现以太网物理连接,如正点原子的探索者、
阿波罗、北极星以及电机开发板都是采用这类型的以太网接入方案,该方案的连接示意图如下
图所示:

上图中,MCU 要求内置MAC 内核,该内核相当TCP/IP 体系结构的数据链路层,而lwIP
软件库用来实现TCP/IP 体系结构的应用层、传输层和网络层,同时,板载PHY 层芯片用来实
现TCP/IP 体系结构的物理层。因此,lwIP、MAC 内核和PHY 层芯片构建了网络通信核心骨
架。至于lwIP 相关的知识,请读者观看正点原子的《lwIP 开发指南》文档。
接下来笔者带大家来了解一下软件TCP/IP 协议栈方案的优缺点,如下所示:
优点:
移植性:可在不同平台、不同编译环境的程序代码经过修改转移到自己的系统中运行。
可造性:可在TCP/IP协议栈的基础上添加和删除相关功能。
可扩展性:可扩展到其他领域的应用及开发。
缺点:
内存方面分析:传统的TCP/IP 方案是移植一个lwIP 的TCP/IP 协议(RAM 50K+,
ROM 80K+),造成主控可用内存减小。
从代码量分析:移植lwIP可能需要的代码量超过40KB,对于有些主控芯片内存匮乏
来说无疑是一个严重的问题。
从运行性能方面分析:由于软件TCP/IP协议栈方案在通信时候是不断地访问中断机
制,造成线程无法运行,如果多线程运行,会使MCU的工作效率大大降低。
从安全性方面分析:软件协议栈会很容易遭受网络攻击,造成单片机瘫痪。
➢ 硬件TCP/IP 协议栈以太网接入方案
所谓全硬件TCP/IP 协议栈是将传统的软件协议TCP/IP 协议栈用硬件化的逻辑门电路来实
现。芯片内部完成TCP、UDP、ICMP 等多种网络协议,并且实现了物理层以太网控制
(MAC+PHY)、内存管理等功能,完成了一整套硬件化的以太网解决方案。该方案的连接示
意图如下图所示:
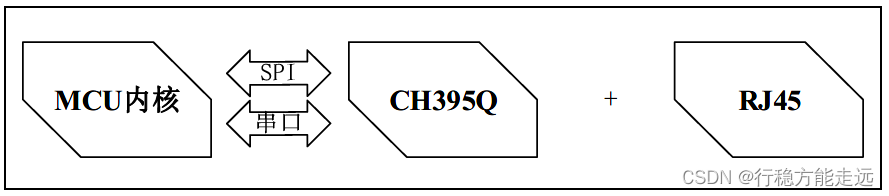
上图中,MCU 通过串口或者SPI 进行网络通讯,无需移植协议库,极大地减少程序的代
码量,甚至弥补了网络协议安全性不足的短板。硬件TCP/IP 协议栈的优缺点,如下所示:
优点:
从代码量方面来看:相比于传统的接入已经大大减少了代码量。
从运行方面来看:极大的减少了中断次数,让单片机更好的完成其他线程的工作。
从安全性方面来看:硬件化的逻辑门电路来处理TCP/IP协议是不可被攻击的,也就
是说网络攻击和病毒对它无效,这也充分弥补了网络协议安全性不足的短板。
缺点:
从可扩展性来看:虽然该芯片内部使用逻辑门电路来实现应用层和物理层协议,但是
它具有功能局限性,例如给TCP/IP协议栈添加一个协议,这样它无法快速添加了。
从收发速率来看:全硬件TCP/IP协议栈芯片都是采用并口、SPI以及IIC等通讯接
口来收发数据,这些数据会受通信接口的速率而影响。
总的来说:全硬件TCP / IP 协议栈简化传统的软件TCP / IP 协议栈,卸载了MCU 用于处
理TCP / IP 这部分的线程,节约MCU 内部ROM 等硬件资源,工程师只需进行简单的套接字
编程和少量的寄存器操作即可方便地进行嵌入式以太网上层应用开发,减少产品开发周期,降
低开发成本。
lwIP 无操作系统移植
lwIP 带操作系统移植
ARP 协议
本章,我们了解ARP 协议,ARP 全称为Address Resolution Protocol(地址解析协议),是
根据IP 地址获取物理地址的一个TCP/IP 协议。主机发送信息时将包含目标IP 地址的ARP 请
求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息
后将该IP 地址和物理地址存入本机ARP 缓存中并保留一定时间,下次请求时直接查询ARP
缓存以节约资源。
ARP 协议的简介
ARP 协议是根据IP 地址获取物理地址的一个TCP/IP 协议。主机发送信息时将包含目标
IP 地址的ARP 请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地
址;收到返回消息后将该IP 地址和物理地址存入本机ARP 缓存中并保留一定时间,下次请求
时直接查询ARP 缓存以节约资源。地址解析协议是建立在网络中各个主机互相信任的基础上
的,局域网络上的主机可以自主发送ARP 应答消息,其他主机收到应答报文时不会检测该报
文的真实性就会将其记入本机ARP 缓存;总的来说,ARP 协议是透过目标设备的IP 地址,查
询目标设备的MAC 地址,以保证通信的顺利进行。
ARP 协议的工作流程
假设由两台主机,分别为主机A(192.168.0.10)与主机B(192.168.0.11),它们两个都是
同一网段的,如果主机A 向主机B 发送信息或者数据,ARP 的地址解析过程有以下几个步骤:
①主机A 首先查自己的ARP 表是否有包含主机B 的信息,例如主机B 的MAC 地址,如
果主机A 的ARP 表包含主机B 的MAC 地址,则主机A 直接利用ARP 表的主机B 的MAC 地
址对IP 数据包进行封装并把数据包发给主机B。
②如果主机A 的ARP 表没有包含主机B 的MAC 地址或者没有找到主机B 的MAC 地址,
则主机A 就把数据包缓存起来,然后以广播的方式发送一个ARP 包的请求报文,该ARP 包的
内容包含主机A 的IP 地址、MAC 地址、主机B 的IP 地址和主机B 的全0 的MAC 地址,由
于主机A 发送ARP 包是使用广播形式,那么同一网段的主机都可以收到该ARP 包,主机B
接收到这个ARP 包会进行处理。
③主机B 接收到主机A 的ARP 包之后,主机B 会对这个ARP 解析并比较自己的IP 地址
和ARP 包的目的IP 地址是否相同,如果相同,则主机B 将ARP 请求报文中的发送端(即主
机A)的IP 地址和MAC 地址存入自己的ARP 表中。之后以单播方式发送ARP 响应报文给主
机A,其中包含了自己的MAC 地址。
④当主机A 收到了主机B 的ARP 包也是同样的处理,首先比较ARP 包的IP 地址是否和
自己的IP 地址相同,如果IP 地址相同,则把ARP 包的信息存入自己的ARP 表中,最后对IP
数据包进行封装并把数据包发给主机B。
从上述步骤的内容,可得到ARP 包的流程图,如下图所示:
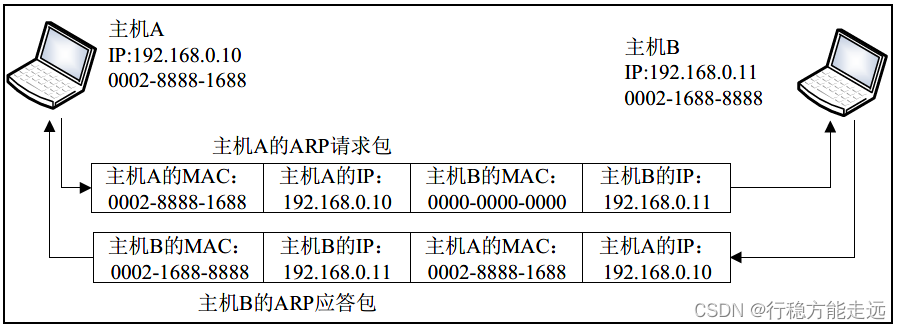
可以看到,主机A 发送数据之前先判断主机A 的ARP 缓存表是否包含主机B 的MAC 地
址,若主机A 的ARP 缓存表没有主机B 的MAC 地址,则主机A 把要发送的数据挂起并发送
一个ARP 请求包,发送完成之后等待主机B 应答,直到收到主机B 的应答包之后才把挂起的
数据包添加以太网首部发送至主机B 当中。
lwIP 描述ARP 缓存表和ARP 相关处理函数由etharp.c/h 文件定义,下面笔者重点讲解
ARP 缓存表的表项信息和挂起流程。ARP 缓存表结构如下所示:
struct etharp_entry {
#if ARP_QUEUEING/* 数据包缓存队列指针*/struct etharp_q_entry *q;
#else /* ARP_QUEUEING *//* 指向此ARP表项上的单个挂起数据包的指针*/
struct pbuf *q;
#endif /* ARP_QUEUEING */ip4_addr_t ipaddr; /* 目标IP 地址*/struct netif *netif; /* 对应网卡信息*/struct eth_addr ethaddr; /* 对应的MAC 地址*/u16_t ctime; /* 生存时间信息*/u8_t state; /* 表项的状态*/
};
static struct etharp_entry arp_table[ARP_TABLE_SIZE];
可以看出,ARP 缓存表(arp_table)最大存放10 个表项,每一个表项描述符了IP 地址映
射MAC 地址的信息和表项生存时间与状态。这个ARP 缓存表很小,lwIP 根据传入的目标IP
地址对ARP 缓存表直接采用遍历方式查找对应的MAC 地址。
注:每一个表项都有一个生存时间,若超出了自身生存时间,则lwIP 内核会把这个表项
删除,这里用到了超时处理机制。
每一个表项从创建、请求等都设置了一个状态,不同状态的表项都需要特殊的处理,这些
状态如下所示:
enum etharp_state {ETHARP_STATE_EMPTY = 0,ETHARP_STATE_PENDING,ETHARP_STATE_STABLE,ETHARP_STATE_STABLE_REREQUESTING_1,ETHARP_STATE_STABLE_REREQUESTING_2
};
下面笔者讲解一下每一个表项的作用及任务。
(1) ETHARP_STATE_EMPTY 状态
这个状态表示ARP 缓存表处于初始化的状态,所有表项初始化之后才可以被使用,如果
需要添加表项,lwIP 内核就会遍历ARP 缓存表并找到合适的表项进行添加。
(2) ETHARP_STATE_PENDING 状态
该状态表示该表项处于不稳定状态,此时该表项只记录到了IP 地址,但是还未记录到对
应的MAC 地址。很可能的情况是:lwIP 内核已经发出一个关于该IP 地址的ARP 请求到数据
链路上且lwIP 内核还未收到ARP 应答,此时ETHARP_STATE_PENDING 状态下会设定超时
时间(5 秒),当计数超时后,对应的表项将被删除,超时时间需要宏定义
ARP_MAXPENDING 来指定,默认为5 秒,如果在5 秒之前收到应答数据包,那么系统会更
新缓存表的信息,记录目标IP 地址与目标MAC 地址的映射关系并且开始记录表项的生存时
间,同时该表项的状态会变成ETHARP_STATE_STABLE 状态。
(3) ETHARP_STATE_STABLE 状态
当收到应答之前,这些数据包会暂时挂载到表项的数据包缓冲队列上,收到应答之后,系
统已经更新ARP 缓存表,那么系统发送数据就会进入该状态
(4)ETHARP_STATE_STABLE_REREQUESTING_1&&
ETHARP_STATE_STABLE_REREQUESTING_2 状态
如果系统再一次发送ARP 请求数据包,则表项状态会暂时被设置为ETHARP_STATE_ST
ABLE_REREQUESTING_1,之后设置为ETHARP_STATE_STABLE_REREQUESTING_2 状态,
其实这两个状态为过渡状态,如果5 秒之前收到ARP 应答后,表项又会被设置为ETHARP_S
TATE_STABLE 状态,这样子能保持表项的有效性。
这些状态也是和超时处理相关,在ARP 超时事件中,需要定时遍历ARP 缓存表各个表项
的状态和检测各个表项的生存时间。稍后笔者也会讲解ARP 超时事件的作用。
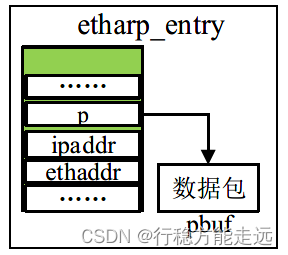
表项挂起数据包
之前讲解过,lwIP 发送数据包时需要检测ARP 缓存表是否包含对方主机的MAC 地址,
若ARP 缓存表没有包含对方主机的MAC 地址,则lwIP 内核在ARP 缓存表上创建一个表项并
且构建一个ARP 请求包,发送完成之后lwIP 内核把要发送的数据包挂载到新创建的表项当中。
在表项中包含了etharp_q_entry 结构体和pbuf 结构体指针,这两个都是用来挂载数据包的,一
般来说,lwIP 内核不使用etharp_q_entry 结构体挂载数据包,而是直接使用指针指向pbuf 数据
包,下面笔者使用一张图来描述上面的内容。
ARP 缓存表的超时处理
上一个小节写了这么多,无非就是为了ARP 表项的ctime(生存时间)这个参数准备的,
其实这个参数笔者在上面也有所涉及,因为系统以周期的形式调用函数etharp_trm。例如,5
秒之前收到ARP 的应答包就会更新ARP 缓存表,这个函数的作用就是使每个ARP 缓存表项c
time 字段加1 处理,如果某个表项的生存时间计数值大于系统规定的某个值,系统就会删除该
表项。etharp_trm 函数如下所示:
void etharp_tmr(void) {u8_t i;/* 第一步:ARP缓存表遍历,ARP_TABLE_SIZE = 10 */for (i = 0; i < ARP_TABLE_SIZE; ++i) {/* 获取表项的状态*/u8_t state = arp_table[i].state;/* 第二步:判断该状态不等于空(初始化的状态)*/if (state != ETHARP_STATE_EMPTY) {/* ARP缓存表项的生存时间+1 */arp_table[i].ctime++;/* 第三步:发送ARP请求数据包并判断ctime是否大于5秒*/if ((arp_table[i].ctime >= ARP_MAXAGE) ||((arp_table[i].state == ETHARP_STATE_PENDING) &&(arp_table[i].ctime >= ARP_MAXPENDING))) {/* 从ARP缓存表中删除该表项*/etharp_free_entry(i);} else if (arp_table[i].state == ETHARP_STATE_STABLE_REREQUESTING_1) {/* 这是一个过度形式*/arp_table[i].state = ETHARP_STATE_STABLE_REREQUESTING_2;} else if (arp_table[i].state == ETHARP_STATE_STABLE_REREQUESTING_2) {/* 将状态重置为稳定状态,使下一个传输的数据包将重新发送一个ARP请求*/arp_table[i].state = ETHARP_STATE_STABLE;} else if (arp_table[i].state == ETHARP_STATE_PENDING) {/* 仍然挂起,重新发送一个ARP查询*/etharp_request(arp_table[i].netif, & arp_table[i].ipaddr);}}}
}
此函数非常简单,这里笔者使用一个流程图来讲解这个函数的实现流程,如下图所示:
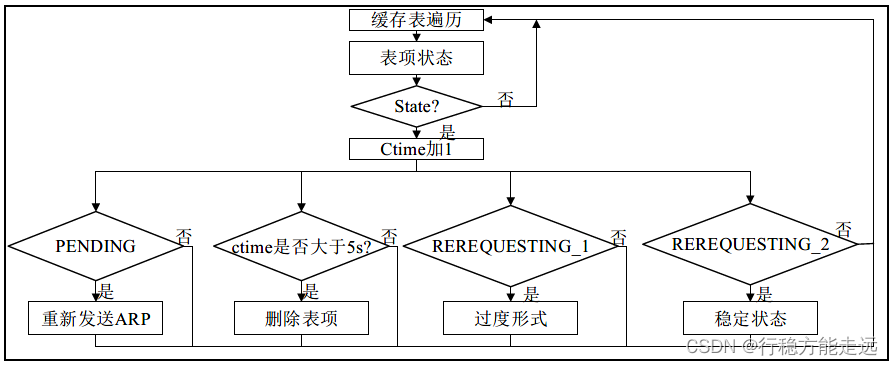
从上图可以看出,这些ARP 缓存表的表项都会定期检测,如果这些表项超时最大生存时
间,那么lwIP 内核会把这些表项统一删除。
APR 报文的报文结构
典型的ARP 报文结构,该结构如下图所示:
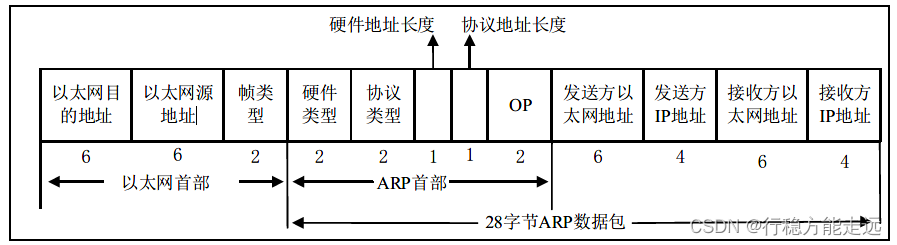
左边的是以太网首部,数据发送时必须添加以太网首部,添加完成之后才能把数据发往到
网络当中(这里解答了为什么需要对方主机的MAC 地址),而右边是ARP 报文结构,它一共
定义了5 个字段,它们分别为:
硬件类型:如果这个类型设置为1 表示以太网MAC 地址。
协议类型:表示要映射的协议地址类型,0x0800–映射为IP 地址。
硬件地址长度和协议地址长度:以太网ARP 请求和应答分别设置为6 和4,它们代表M
AC 地址长度和IP 地址长度。在ARP 协议包中留出硬件地址长度字段和协议地址长度字段可
以使得ARP 协议在任何网络中被使用,而不仅仅只在以太网中。
op:ARP 数据包的类型,ARP 请求设置为1,ARP 应答设置为2。
剩下的字段就是填入本地IP 地址与本地MAC 地址和目标IP 地址与目标MAC 地址。
关于ARP 报文结构可在ethernet.h 找到一些数据结构和宏描述,如下所示:
/**********************************ethernet.h********************************/ #
define ETH_HWADDR_LEN 6 /* 以太网地址长度*/
struct eth_addr { /* 一个以太网MAC地址*/PACK_STRUCT_FLD_8(u8_t addr[ETH_HWADDR_LEN]);
}
PACK_STRUCT_STRUCT;
struct eth_hdr { /* 以太网首部*/ #if ETH_PAD_SIZEPACK_STRUCT_FLD_8(u8_t padding[ETH_PAD_SIZE]);#endifPACK_STRUCT_FLD_S(struct eth_addr dest); /* 以太网目标地址(6字节) */PACK_STRUCT_FLD_S(struct eth_addr src); /* 以太网源MAC 地址(6字节) */PACK_STRUCT_FIELD(u16_t type); /* 帧类型(2字节) */
}
PACK_STRUCT_STRUCT;
/***********************************etharp.h**********************************/
struct etharp_hdr { /* ARP 报文*//* ARP 报文首部*/PACK_STRUCT_FIELD(u16_t hwtype); /* 硬件类型(2字节) */PACK_STRUCT_FIELD(u16_t proto); /* 协议类型(2字节) */PACK_STRUCT_FLD_8(u8_t hwlen); /* 硬件地址长度(1字节) */PACK_STRUCT_FLD_8(u8_t protolen); /* 协议地址长度(2字节) */PACK_STRUCT_FIELD(u16_t opcode); /* op 字段(2字节) */PACK_STRUCT_FLD_S(struct eth_addr shwaddr); /* 源MAC 地址(6字节) */PACK_STRUCT_FLD_S(struct ip4_addr2 sipaddr); /* 源ip 地址(4字节) */PACK_STRUCT_FLD_S(struct eth_addr dhwaddr); /* 目标MAC 地址(6字节) */PACK_STRUCT_FLD_S(struct ip4_addr2 dipaddr); /* 目标ip 地址(4字节) */
}
PACK_STRUCT_STRUCT;
/* op 字段操作*/
enum etharp_opcode {ARP_REQUEST = 1, /* 请求包*/ARP_REPLY = 2 /* 应答包*/
};
前面的eth_hdr 结构体就是定义了以太网首部字段,而etharp_hdr 结构体定义了ARP 首部
的字段信息。下面笔者使用wireshark 网络抓包工具形象地讲解报文格式和内容,如下图所示:
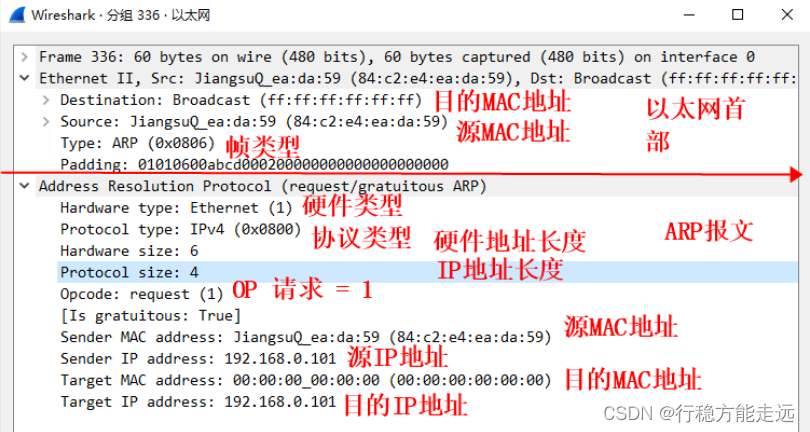
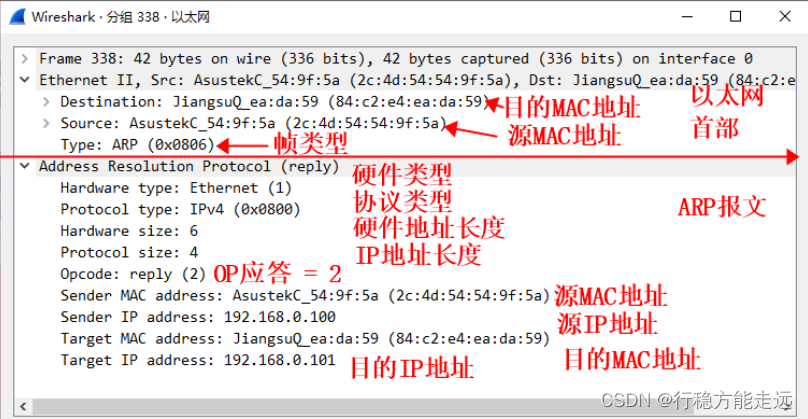
从这两张图可以看出,图一的ARP 数据包是以广播的方式发送,它的OP 字段类型为1
表示ARP 数据包为ARP 请求包。图二的ARP 数据包为ARP 应答包,因为它的OP 字段为2,
所以该包不是以广播的方式发送。
ARP 协议层的接收与发送原理解析
发送ARP 请求数据包
构建ARP 请求包函数是在etharp_raw 函数下实现,该函数如下所示:
static err_t
etharp_raw(struct netif * netif, /* 发送ARP 数据包的lwip 网络接口*/const struct eth_addr * ethsrc_addr, /* 以太网源MAC 地址*/const struct eth_addr * ethdst_addr, /* 以太网目标MAC 地址*/const struct eth_addr * hwsrc_addr, /* ARP 协议源MAC 地址*/const ip4_addr_t * ipsrc_addr, /* ARP 协议源IP 地址*/const struct eth_addr * hwdst_addr, /* ARP 协议目标MAC 地址*/const ip4_addr_t * ipdst_addr, /* ARP 协议目标IP 地址*/const u16_t opcode) /* ARP 数据包的类型:1为请求包类型、2为应答包类型*/ {struct pbuf * p;err_t result = ERR_OK;struct etharp_hdr * hdr;/* 申请ARP 报文的内存池空间*/p = pbuf_alloc(PBUF_LINK, SIZEOF_ETHARP_HDR, PBUF_RAM);/* 申请内存池是否成功*/if (p == NULL) {ETHARP_STATS_INC(etharp.memerr);return ERR_MEM;}/* ARP 报文的数据区域,并且强制将起始地址转化成ARP 报文首部*/hdr = (struct etharp_hdr * ) p - > payload;/* ARP 数据包的op 字段*/hdr - > opcode = lwip_htons(opcode);/* 源MAC地址*/SMEMCPY( & hdr - > shwaddr, hwsrc_addr, ETH_HWADDR_LEN);/* 目的MAC地址*/SMEMCPY( & hdr - > dhwaddr, hwdst_addr, ETH_HWADDR_LEN);/* 源IP地址*/IPADDR_WORDALIGNED_COPY_FROM_IP4_ADDR_T( & hdr - > sipaddr, ipsrc_addr);/* 目的IP地址*/IPADDR_WORDALIGNED_COPY_FROM_IP4_ADDR_T( & hdr - > dipaddr, ipdst_addr);/* 硬件类型*/hdr - > hwtype = PP_HTONS(HWTYPE_ETHERNET);/* 协议类型*/hdr - > proto = PP_HTONS(ETHTYPE_IP);/* 硬件地址长度*/hdr - > hwlen = ETH_HWADDR_LEN;/* 协议地址长度*/hdr - > protolen = sizeof(ip4_addr_t);#if LWIP_AUTOIPif (ip4_addr_islinklocal(ipsrc_addr)) {ethernet_output(netif, p, ethsrc_addr, & ethbroadcast, ETHTYPE_ARP);} else# endif /* LWIP_AUTOIP */ {/* 调用底层发送函数将以太网数据帧发送出去*/ethernet_output(netif, p, ethsrc_addr, ethdst_addr, ETHTYPE_ARP);}ETHARP_STATS_INC(etharp.xmit);/* 发送完成释放内存*/pbuf_free(p);p = NULL;/* 发送完成返回结果*/return result;}/* 定义以太网广播地址*/
const struct eth_addr ethbroadcast = {{0xff, 0xff, 0xff, 0xff, 0xff, 0xff}
};
/* 填写ARP请求包的接收方MAC字段*/
const struct eth_addr ethzero = {{0, 0, 0, 0, 0, 0}
};
static err_t
etharp_request_dst(struct netif * netif,const ip4_addr_t * ipaddr,const struct eth_addr * hw_dst_addr) {return etharp_raw(netif, (struct eth_addr * ) netif - > hwaddr, hw_dst_addr, (struct eth_addr * ) netif - > hwaddr,netif_ip4_addr(netif), & ethzero,ipaddr, ARP_REQUEST);}/* 发送一个要求ipaddr的ARP请求包*/
err_t
etharp_request(struct netif * netif,const ip4_addr_t * ipaddr) {return etharp_request_dst(netif, ipaddr, & ethbroadcast);
}
发送ARP 请求报文之前先申请pbuf 内存,接着由pbuf 的payload 指针指向的地址添加
ARP 首部,添加完成之后设置ARP 首部字段的信息,最后由ethernet_output 函数为pbuf 添加
以太网首部和发送,发送完成之后把要发送的数据挂载到ARP 缓存表项当中。。
接收ARP 应答数据包
虽然ARP 和IP 协议同属于网络层的协议,但是从分层的结构来看,ARP 处于网络层的最
底层,而IP 处于网络层的顶层。总的来说,ARP 最接近网卡驱动文件,发送的数据经过ARP
检测和操作发送至网卡驱动文件处理,由网卡驱动文件调用ETH 外设把数据发送至PHY 设备
当中。下面笔者来讲解网卡驱动文件的函数如何把接收的数据发送至ARP 或者IP 处理,这个
函数为ethernet_input,如下所示:
err_t
ethernet_input(struct pbuf * p, struct netif * netif) {struct eth_hdr * ethhdr;u16_t type;#if LWIP_ARP || ETHARP_SUPPORT_VLAN || LWIP_IPV6s16_t ip_hdr_offset = SIZEOF_ETH_HDR;#endif /* LWIP_ARP || ETHARP_SUPPORT_VLAN *//* 第一步:判断数据包是否小于等于以太网头部的大小如果是,则释放内存,直接返回*/if (p - > len <= SIZEOF_ETH_HDR) {ETHARP_STATS_INC(etharp.proterr);ETHARP_STATS_INC(etharp.drop);MIB2_STATS_NETIF_INC(netif, ifinerrors);goto free_and_return;}if (p - > if_idx == NETIF_NO_INDEX) {p - > if_idx = netif_get_index(netif);}/* 第二步:p->payload表示指向缓冲区中实际数据的指针相当于指向以太网的头部*/ethhdr = (struct eth_hdr * ) p - > payload;/* 第三步:获取数据包的类型*/type = ethhdr - > type;#if LWIP_ARP_FILTER_NETIFnetif = LWIP_ARP_FILTER_NETIF_FN(p, netif, lwip_htons(type));#endif /* LWIP_ARP_FILTER_NETIF*//* 第四步:判断数据包是以怎么样的类型发来的*/if (ethhdr - > dest.addr[0] & 1) {/* 这可能是一个多播或广播包*/if (ethhdr - > dest.addr[0] == LL_IP4_MULTICAST_ADDR_0) {#if LWIP_IPV4if ((ethhdr - > dest.addr[1] == LL_IP4_MULTICAST_ADDR_1) &&(ethhdr - > dest.addr[2] == LL_IP4_MULTICAST_ADDR_2)) {/* 将pbuf标记为链路层多播*/p - > flags |= PBUF_FLAG_LLMCAST;}#endif /* LWIP_IPV4 */} else if (eth_addr_cmp( & ethhdr - > dest, & ethbroadcast)) {/* 将pbuf标记为链路层广播*/p - > flags |= PBUF_FLAG_LLBCAST;}}/* 第五步:判断数据包的类型*/switch (type) {#if LWIP_IPV4 && LWIP_ARP/* IP数据包*/case PP_HTONS(ETHTYPE_IP):if (!(netif - > flags & NETIF_FLAG_ETHARP)) {goto free_and_return;}/* 去除以太网报头*/if ((p - > len < ip_hdr_offset) ||pbuf_header(p, (s16_t) - ip_hdr_offset)) { /* 去除以太网首部失败,则直接返回*/goto free_and_return;} else {/* 传递到IP 协议去处理*/ip4_input(p, netif);}break;/* 对于是ARP 包*/case PP_HTONS(ETHTYPE_ARP):if (!(netif - > flags & NETIF_FLAG_ETHARP)) {goto free_and_return;}/* 去除以太网首部*/if ((p - > len < ip_hdr_offset) ||pbuf_header(p, (s16_t) - ip_hdr_offset)) { /* 去除以太网首部失败,则直接返回*/ETHARP_STATS_INC(etharp.lenerr);ETHARP_STATS_INC(etharp.drop);goto free_and_return;} else {/* 传递到ARP 协议处理*/etharp_input(p, netif);}break;#endif /* LWIP_IPV4 && LWIP_ARP */default:#ifdef LWIP_HOOK_UNKNOWN_ETH_PROTOCOLif (LWIP_HOOK_UNKNOWN_ETH_PROTOCOL(p, netif) == ERR_OK) {break;}#endifETHARP_STATS_INC(etharp.proterr);ETHARP_STATS_INC(etharp.drop);MIB2_STATS_NETIF_INC(netif, ifinunknownprotos);goto free_and_return;}return ERR_OK;free_and_return:pbuf_free(p);return ERR_OK;
}
为了理解整个以太网的数据帧在ARP 层处理,笔者就以图形展示整个数据包递交流程,
如下图所示
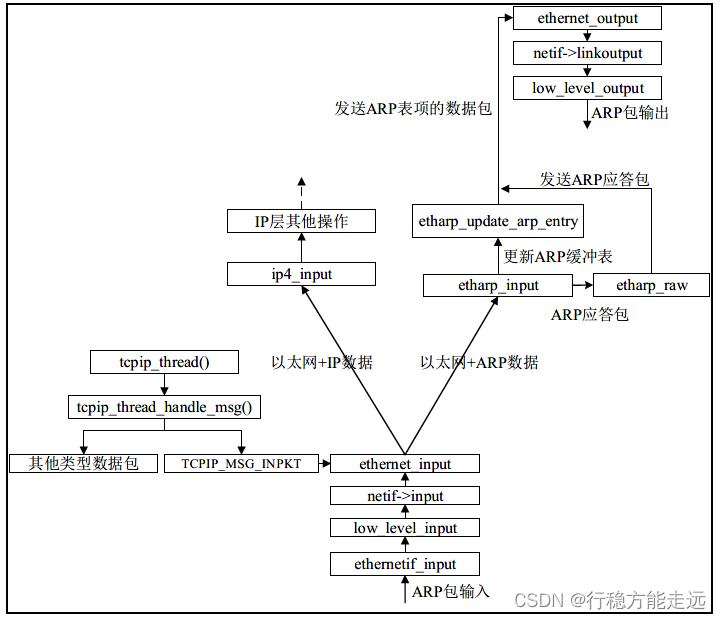
可以看出,数据包在ethernet_input 中需要判断该数据包的类型,若该数据包的类型为IP
数据包,则lwIP 内核把该数据包递交给ip4_input 函数处理。若该数据包的类型为ARP 数据
包,则lwIP 内核把该数据包递交给etharp_input 函数处理,递交完成之后该函数需要判断
ARP 数据包的类型,如果它是ARP 请求包,则lwIP 内核调用etharp_raw 函数构建ARP 应答
包并且更新ARP 缓存表;如果它是ARP 应答包,则lwip 内核更新ARP 缓存表并且把表项挂
载的数据包以ethernet_output 函数发送。
IP 协议
IP 指网际互连协议,Internet Protocol 的缩写,是TCP/IP 体系中的网络层协议。设计IP 的
目的是提高网络的可扩展性:一是解决互联网问题,实现大规模、异构网络的互联互通;二是
分割顶层网络应用和底层网络技术之间的耦合关系,以利于两者的独立发展。根据端到端的设
计原则,IP 只为主机提供一种无连接、不可靠的、尽力而为的数据包传输服务。
IP 协议的简介
IP 协议是整个TCP/IP 协议族的核心,也是构成互联网的基础。IP 位于TCP/IP 模型的网
络层(相当于OSI 模型的网络层),它可以向传输层提供各种协议的信息,例如TCP、UDP 等;
对下可将IP 信息包放到链路层,通过以太网、令牌环网络等各种技术来传送。为了能适应异
构网络,IP 强调适应性、简洁性和可操作性,并在可靠性做了一定的牺牲。这里我们不过多
深入了解IP 协议了,本章笔者重点讲解IP 数据报的分片与重组原理。
IP 数据报
IP 层数据报也叫做IP 数据报或者IP 分组,IP 数据报组装在以太网帧中发送的,它通常由
两个部分组成,即IP 首部与数据区域,其中IP 的首部是20 字节大小,数据区域理论上可以
多达65535 个字节,由于以太网网络接口的最大传输单元为1500,所以一个完整的数据包不
能超出1500 字节大小。IP 数据报结构如以下图所示:
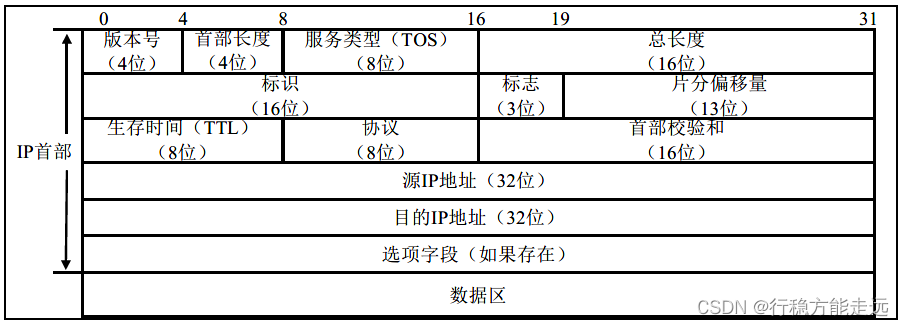
(1) 版本:占4 位指IP 协议的版本。通信双方使用的IP 协议版本必须一致。广泛使用的
IP 协议版本号为4(即IPv4)。
(2) 首部长度:占4 位可表示的最大十进制数值是15。请注意,这个字段所表示数的单位
是32 位字长(1 个32 位字长是4 字节),因此,当IP 的首部长度为1111 时(即十进制的15),
首部长度就达到60 字节。当IP 分组的首部长度不是4 字节的整数倍时,必须利用最后的填充
字段加以填充。因此数据部分永远在4 字节的整数倍开始,这样在实现IP 协议时较为方便。
首部长度限制为60 字节的缺点是有时可能不够用。但这样做是希望用户尽量减少开销。最常
用的首部长度就是20 字节(即首部长度为0101),这时不使用任何选项。
(3) 区分服务:占8 位,用来获得更好的服务。这个字段在旧标准中叫做服务类型,但实
际上一直没有被使用过。
(4) 总长度:总长度指首部和数据之和的长度,单位为字节。总长度字段为16 位,因此数
据报的最大长度为2^16-1=65534 字节。
在IP 层下面的每一种数据链路层都有自己的帧格式,其中包括帧格式中的数据字段的最
大长度,这称为最大传送单元MTU。当一个数据报封装成链路层的帧时,此数据报的总长度
(即首部加上数据部分)一定不能超过下面的数据链路层的MTU 值。
(5) 标识(identification):占16 位IP 软件在存储器中维持一个计数器,每产生一个数据
报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP 是无连接
服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU 而必须分片时,这
个标识字段的值就被复制到所有的数据报的标识字段中。相同的标识字段的值使分片后的各数
据报片最后能正确地重装成为原来的数据报。
(6) 标志(flag):占3 位但只有2 位有意义的。
- 标志字段中的最低位记为MF(More Fragment)。MF=1 即表示后面“还有分片”的数
据报。MF=0 表示这已是若干数据报片中的最后一个。 - 标志字段中间的一位记为DF(Don’t Fragment),意思是“不能分片”。只有当DF=0
时才允许分片。
(7) 片偏移:占13 位片偏移指出:较长的分组在分片后,某片在原分组中的相对位置。也
就是说,相对用户数据字段的起点,该片从何处开始。片偏移以8 个字节为偏移单位。这就是
说,除了最后一个分片,每个分片的长度一定是8 字节(64 位)的整数倍。
(8) 生存时间:占8 位生存时间字段常用的的英文缩写是TTL(Time To Live),表明是数据
报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限
制地在因特网中兜圈子,因而白白消耗网络资源。最初的设计是以秒作为TTL 的单位。每经
过一个路由器时,就把TTL 减去数据报在路由器消耗掉的一段时间。若数据报在路由器消耗
的时间小于1 秒,就把TTL 值减1。当TTL 值为0 时,就丢弃这个数据报。后来把TTL 字段
的功能改为“跳数限制”(但名称不变)。路由器在转发数据报之前就把TTL 值减1.若TTL 值
减少到零,就丢弃这个数据报,不再转发。因此,TTL 的单位不再是秒,而是跳数。TTL 的
意义是指明数据报在网络中至多可经过多少个路由器。显然,数据报在网络上经过的路由器的
最大数值是255。若把TTL 的初始值设为1,就表示这个数据报只能在本局域网中传送。
(9) 协议:占8 位协议字段指出此数据报携带的数据是使用何种协议,以便使目的主机的
IP 层知道应将数据部分上交给哪个处理过程。
(10) 首部检验和:占16 位这个字段只检验数据报的首部,但不包括数据部分。这是因为
数据报每经过一个路由器,路由器都要重新计算一下首部检验和(一些字段,如生存时间、标
志、片偏移等都可能发生变化)。不检验数据部分可减少计算的工作量。
(11) 源地址:占32 位。
(12) 目的地址:占32 位。
(13) 数据区域:这是IP 数据报的最后的一个字段,也是最重要的内容,lwIP 发送数据报
是把该层的首部封装到数据包里面,在IP 层也是把IP 首部封装在其中,因为有数据区域才会
有数据报首部的存在,在大多数情况下,IP 数据报中的数据字段包含要交付给目标IP 地址的
运输层(TCP 协议或UDP 协议),当然数据区域也可承载其他类型的报文,如ICMP 报文等。
IP 数据报结构
在lwIP 中,为了描述IP 报文结构,它在ip4.h 文件中定义了一个ip_hdr 结构体来描述IP
数据报的内容,该结构体如下所示:
struct ip_hdr {/* 版本号+首部长度+服务类型*/PACK_STRUCT_FLD_8(u8_t _v_hl);/* 服务类型*/PACK_STRUCT_FLD_8(u8_t _tos);/* 总长度(IP首部+数据区) */PACK_STRUCT_FIELD(u16_t _len);/* 数据包标识(编号) */PACK_STRUCT_FIELD(u16_t _id);/* 标志+片偏移*/PACK_STRUCT_FIELD(u16_t _offset);/* IP首部标志定义*/#define IP_RF 0x8000 U /* 保留*/ # define IP_DF 0x4000 U /* 是否允许分片*/ # define IP_MF 0x2000 U /* 后续是否还有更多分片*/ # define IP_OFFMASK 0x1fff U /* 片偏移域掩码*//* 生存时间(最大转发次数)+协议类型(IGMP:1、UDP:17、TCP:6) */PACK_STRUCT_FLD_8(u8_t _ttl);/* 协议*/PACK_STRUCT_FLD_8(u8_t _proto);/* 校验和(IP首部) */PACK_STRUCT_FIELD(u16_t _chksum);/* 源IP地址/目的IP地址*/PACK_STRUCT_FLD_S(ip4_addr_p_t src);PACK_STRUCT_FLD_S(ip4_addr_p_t dest);
}
PACK_STRUCT_STRUCT;
PACK_STRUCT_END
可以看出,此结构体的成员变量和上图9.2.1 的字段一一对应。
IP 数据报的分片解析
TCP/IP 协议栈为什么具备分片的概念,因为应用程序处理的数据是不确定的,可能超出
网络接口最大传输单元,为此TCP/IP 协议栈引入了分片概念,它是以MTU 为界限对这个大
型的数据切割成多个小型的数据包。这些小型的数据叫做IP 的分组和分片,它们在接收方进
行重组处理,这样,接收方的应用程序接收到这个大型的数据了。总的来讲,IP 数据报的分
片概念是为了解决IP 数据报数据过大的问题而诞生。注:以太网最大传输单元MTU 为1500。
现在笔者举个示例,让大家更好的理解IP 分片的原理:
假设IP 数据报整体的大小为4000 字节,IP 首部默认为20 字节,而数据区域为3980。由
于以太网最大传输单元为1500,所以lwIP 内核会把这个数据报进行分片处理。
- 第一个IP 分片:
分片数据大小:20(IP 首部)+ 1480(数据区域)。
标识:888。
标志:IP_MF = 1 后续还有分片。
片偏移量:片偏移量是0,单位是8 字节,本片偏移量相当于0 字节。 - 第二片IP 数据报:
分片数据大小:20(IP 首部)+ 1480(数据区域)。
标识:888。
标志:IP_MF = 1 后续还有分片。
片偏移量:片偏移量是185(1480/8),单位是8 字节,本片偏移量相当于1480 字节。 - 第三片IP 数据报:
分片数据大小:20(IP 首部)+ 1020(数据区域)。
标识:888。
标志:IP_MF = 0,后续没有分片。
片偏移量:片偏移量是370(185+185),单位是8 字节,本片偏移量相当于2960 字节。
注:这些分片的标识都是一致的,而IP_MF 表示后续有没有分片,若IP_MF 为0,则这
个分片为最后一个分片。
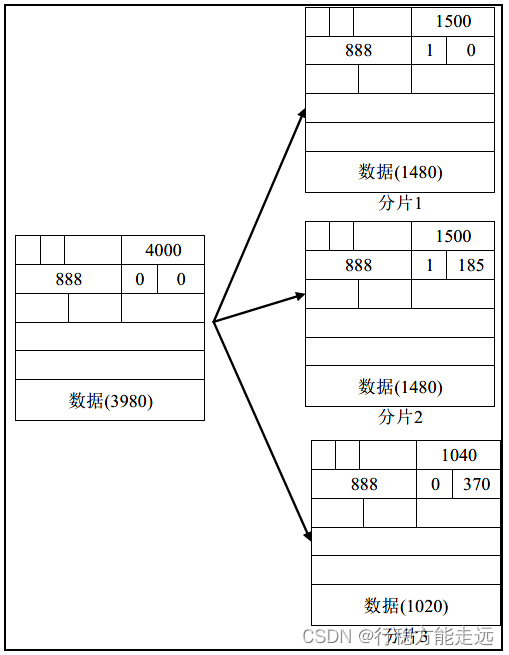
从上图可以看出,一个大型的IP 数据包经过网络层处理,它会被分成两个或者两个以上的IP 分片,这些分片的数据组合起来就是应用程序发送的数据与传输层的首部。
至此,我们已经明白了IP 分片的原理,下面笔者讲解lwIP 内核如何实现这个原理,它的
实现函数为ip4_frag,该函数如下所示:
/**
* 如果IP数据报对netif来说太大,则将其分片,
将数据报切成MTU大小的块,然后按顺序发送通过将pbuf_ref指向p
* @param p:要发送的IP数据包
* @param netif:发送的netif
* @param dest:目的IP地址
* @return ERR_OK:发送成功, err_t:其他
*/
err_t
ip4_frag(struct pbuf * p, struct netif * netif,const ip4_addr_t * dest) {struct pbuf * rambuf;#if !LWIP_NETIF_TX_SINGLE_PBUFstruct pbuf * newpbuf;u16_t newpbuflen = 0;u16_t left_to_copy;#endifstruct ip_hdr * original_iphdr;struct ip_hdr * iphdr;/* (1500 - 20)/8 = 偏移185 */const u16_t nfb = (u16_t)((netif - > mtu - IP_HLEN) / 8);u16_t left, fragsize;u16_t ofo;int last;u16_t poff = IP_HLEN; /* IP头部长度*/u16_t tmp;int mf_set;original_iphdr = (struct ip_hdr * ) p - > payload; /* 指向数据报*/iphdr = original_iphdr;/* 判断IP头部是否为20 */if (IPH_HL_BYTES(iphdr) != IP_HLEN) {return ERR_VAL;}/* tmp变量获取标志和片偏移数值*/tmp = lwip_ntohs(IPH_OFFSET(iphdr));/* ofo = 片偏移*/ofo = tmp & IP_OFFMASK;/* mf_set = 分片标志*/mf_set = tmp & IP_MF;/* left = 总长度减去IP头部等于有效数据长度,4000 - 20 = 3980 */left = (u16_t)(p - > tot_len - IP_HLEN);/* 判断left是否为有效数据*/while (left) {/* 判断有效数据和偏移数据大小,fragsize = 1480 (3980 < 1480 ? 3980 : 1480) */fragsize = LWIP_MIN(left, (u16_t)(nfb * 8));/* rambuf申请20字节大小的内存块*/rambuf = pbuf_alloc(PBUF_LINK, IP_HLEN, PBUF_RAM);if (rambuf == NULL) {goto memerr;}/* 这个rambuf有效数据指针指向original_iphdr数据报*/SMEMCPY(rambuf - > payload, original_iphdr, IP_HLEN);/* iphdr指向有效区域地址rambuf->payload */iphdr = (struct ip_hdr * ) rambuf - > payload;/* left_to_copy = 偏移数据大小(1480) */left_to_copy = fragsize;while (left_to_copy) {struct pbuf_custom_ref * pcr;/* 当前pbuf中数据的长度,plen = 3980 - 20 = 3960 */u16_t plen = (u16_t)(p - > len - poff);/* newpbuflen = 1480 (1480 < 3960 ? 1480 : 3960) */newpbuflen = LWIP_MIN(left_to_copy, plen);if (!newpbuflen) {poff = 0;p = p - > next;continue;}/* pcr申请内存*/pcr = ip_frag_alloc_pbuf_custom_ref();if (pcr == NULL) {pbuf_free(rambuf);goto memerr;}/* newpbuf申请内存1480字节,保存了这个数据区域偏移poff字节的数据(p->payload + poff) */newpbuf = pbuf_alloced_custom(PBUF_RAW, newpbuflen, PBUF_REF, & pcr - > pc, (u8_t * ) p - > payload + poff, newpbuflen);if (newpbuf == NULL) {/* 释放内存*/ip_frag_free_pbuf_custom_ref(pcr);pbuf_free(rambuf);goto memerr;}/* 增加pbuf的引用计数*/pbuf_ref(p);pcr - > original = p;pcr - > pc.custom_free_function = ipfrag_free_pbuf_custom;/* 将它添加到rambuf的链的末尾*/pbuf_cat(rambuf, newpbuf);/* left_to_copy = 0 (1480 - 1480) */left_to_copy = (u16_t)(left_to_copy - newpbuflen);if (left_to_copy) {poff = 0;p = p - > next;}}/* poff = 1500 (20 + 1480) */poff = (u16_t)(poff + newpbuflen);/* last = 0 (3980 <= (1500 - 20)) */last = (left <= netif - > mtu - IP_HLEN);/* 设置新的偏移量和MF标志*/tmp = (IP_OFFMASK & (ofo));/* 判断是否是最后一个分片*/if (!last || mf_set) {/* 最后一个片段设置了MF为0 */tmp = tmp | IP_MF;}/* 分段偏移与标志字段*/IPH_OFFSET_SET(iphdr, lwip_htons(tmp));/* 设置数据报总长度= 1500 (1480 + 20) */IPH_LEN_SET(iphdr, lwip_htons((u16_t)(fragsize + IP_HLEN)));/* 校验为0 */IPH_CHKSUM_SET(iphdr, 0);/* 发送IP数据报*/netif - > output(netif, rambuf, dest);IPFRAG_STATS_INC(ip_frag.xmit);/* rambuf释放内存*/pbuf_free(rambuf);/* left = 2500 (3980 - 1480) */left = (u16_t)(left - fragsize);/* 片偏移ofo = 185(0 + 185) */ofo = (u16_t)(ofo + nfb);}MIB2_STATS_INC(mib2.ipfragoks);return ERR_OK;memerr:MIB2_STATS_INC(mib2.ipfragfails);return ERR_MEM;
}
MIB2_STATS_INC(mib2.ipfragoks);
return ERR_OK;
memerr:MIB2_STATS_INC(mib2.ipfragfails);
return ERR_MEM;
}
此函数非常简单,首先判断这个大型数据包的有效区域总长度,系统根据这个总长度划分
数据区域,接着申请20+sizeof(struct pbuf)字节的rampbuf 来存储IP 首部,然后根据poff 数值
让被分片数据包的payload 指针偏移poff 大小,它所指向的地址由newpbuf 数据包的payload
指针指向,最后调用netif->output 函数发送该分片,其他分片一样操作。
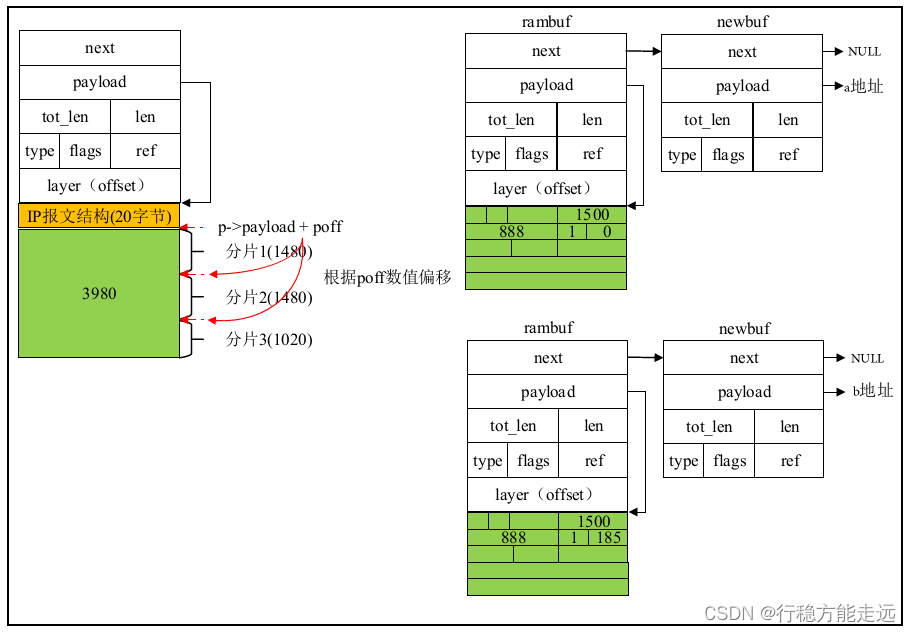
上图中,newpbuf 的payload 指针指向的地址由左边的payload 指针经过偏移得来的。
IP 数据报的分片重装
由于IP 分组在网络传输过程中到达目的地点的时间是不确定的,所以后面的分组可能比
前面的分组先达到目的地点。为此,lwIP 内核需要将接收到的分组暂存起来,等所有的分组
都接收完成之后,再将数据传递给上层。
在lwIP 中,有专门的结构体负责缓存这些分组,这个结构体为ip_reassdata 重装数据链表,
该结构体在ip4_frag.h 文件中定义,如下所示:
/* 重装数据结构体*/
struct ip_reassdata {struct ip_reassdata *next; /* 指向下一个重装节点*/struct pbuf *p; /* 指向分组的pbuf */struct ip_hdr iphdr; /* IP数据报的首部*/u16_t datagram_len; /* 已收到数据的长度*/u8_t flags; /* 标志是否最后一个分组*/u8_t timer; /* 超时间隔*/
};
这个结构体描述了同类型的IP 分组信息,同类型的IP 分组会挂载到该重装节点上,如下
图所示:
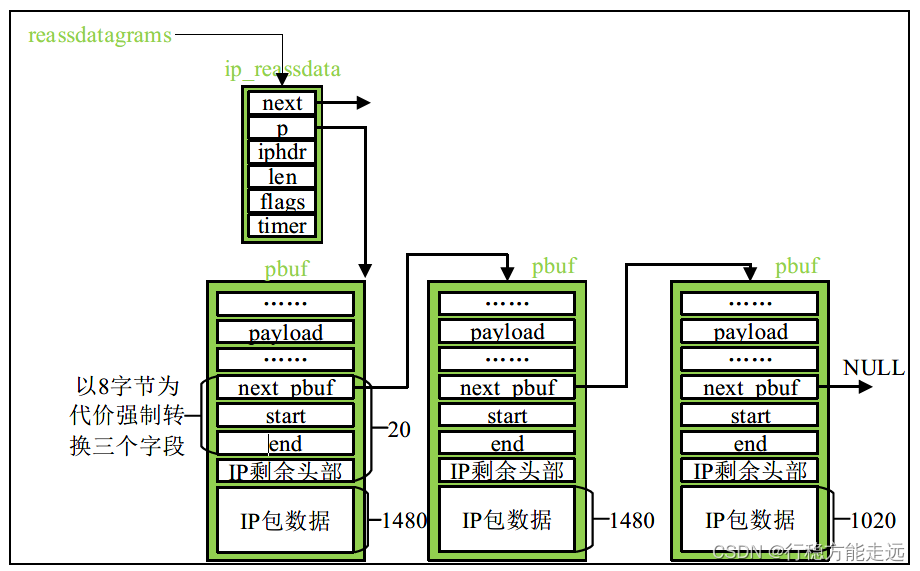
可以看到,这些分片挂载到同一个重装节点上,它们挂载之前,是把IP 首部的前8 字节
强制转换成三个字段,其中next_pbuf 指针用来链接这些IP 分组,形成了单向链表,而start
和end 字段用来描述分组的顺序,lwIP 系统根据这些数值对分组进行排序。
lwIP 内核的IP 重组功能由ip4_reass 函数实现,该函数的代码量比较长,这里笔者不深入
讲解了,我们会在视频当中讲解IP 重装流程。
IP 数据报的输出
无论是UDP 还是TCP,它们的数据段递交至网络层的接口是一致的,这个接口函数如下
所示:
err_t
ip4_output_if_src(struct pbuf * p,const ip4_addr_t * src,const ip4_addr_t * dest,u8_t ttl, u8_t tos,u8_t proto, struct netif * netif) {struct ip_hdr * iphdr;ip4_addr_t dest_addr;if (dest != LWIP_IP_HDRINCL) {u16_t ip_hlen = IP_HLEN;/* 第一步:生成IP报头*/if (pbuf_header(p, IP_HLEN)) {return ERR_BUF;}/* 第二步:iphdr 指向IP头部指针*/iphdr = (struct ip_hdr * ) p - > payload;/* 设置生存时间(最大转发次数) */IPH_TTL_SET(iphdr, ttl);/* 设置协议类型(IGMP:1、UDP:17、TCP:6) */IPH_PROTO_SET(iphdr, proto);/* 设置目的IP地址*/ip4_addr_copy(iphdr - > dest, * dest);/* 设置版本号+设置首部长度*/IPH_VHL_SET(iphdr, 4, ip_hlen / 4);/* 服务类型*/IPH_TOS_SET(iphdr, tos);/* 设置总长度(IP首部+数据区) */IPH_LEN_SET(iphdr, lwip_htons(p - > tot_len));/* 设置标志+片偏移*/IPH_OFFSET_SET(iphdr, 0);/* 设置数据包标识(编号) */IPH_ID_SET(iphdr, lwip_htons(ip_id));/* 每发送一个数据包,编号加一*/++ip_id;/* 没有指定源IP地址*/if (src == NULL) {/* 将当前网络接口IP地址设置为源IP地址*/ip4_addr_copy(iphdr - > src, * IP4_ADDR_ANY4);} else {/* 复制源IP地址*/ip4_addr_copy(iphdr - > src, * src);}} else {/* IP头部已经包含在pbuf中*/iphdr = (struct ip_hdr * ) p - > payload;ip4_addr_copy(dest_addr, iphdr - > dest);dest = & dest_addr;}IP_STATS_INC(ip.xmit);ip4_debug_print(p);/* 如果数据包总长度大于MTU,则分片发送*/if (netif - > mtu && (p - > tot_len > netif - > mtu)) {return ip4_frag(p, netif, dest);}/* 如果数据包总长度不大于MTU,则直接发送*/return netif - > output(netif, p, dest);
}
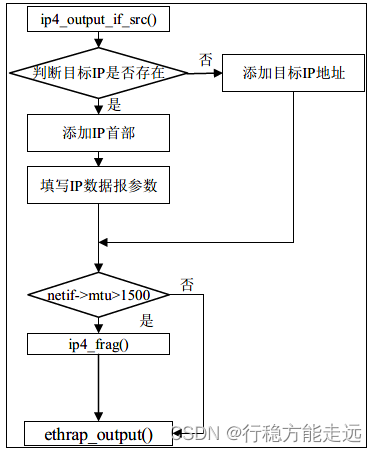
此函数非常简单,这里笔者使用一个流程图来描述该函数的实现原理,如下图所示:
此函数首先判断目标IP 地址是否为NULL,若目标IP 地址不为空,则偏移payload 指针
添加IP 首部,偏移完成之后设置IP 首部字段信息,接着判断该数据包的总长度是否大于以太
网传输单元,若大于,则调用ip4_frag 函数对这个数据包分组并且逐一发送,否则直接调用
ethrap_output 函数把数据包递交给ARP 层处理。
IP 数据报的输入
数据包提交给网络层之前,系统需要判断接收到的数据包是IP 数据包还是ARP 数据包,
若接收到的是IP 数据包,则lwIP 内核调用ip4_input 函数处理这个数据包,该函数如下所示:
err_t
ip4_input(struct pbuf * p, struct netif * inp) {struct ip_hdr * iphdr;struct netif * netif;u16_t iphdr_hlen;u16_t iphdr_len;#if IP_ACCEPT_LINK_LAYER_ADDRESSING || LWIP_IGMPint check_ip_src = 1;#endif /* IP_ACCEPT_LINK_LAYER_ADDRESSING || LWIP_IGMP */IP_STATS_INC(ip.recv);MIB2_STATS_INC(mib2.ipinreceives);/* 识别IP报头*/iphdr = (struct ip_hdr * ) p - > payload;/* 第一步:判断版本是否为IPv4 */if (IPH_V(iphdr) != 4) {ip4_debug_print(p);pbuf_free(p); /* 释放空间*/IP_STATS_INC(ip.err);IP_STATS_INC(ip.drop);MIB2_STATS_INC(mib2.ipinhdrerrors);return ERR_OK;}/* 以4字节(32位)字段获得IP头的长度*/iphdr_hlen = IPH_HL(iphdr);/* 以字节计算IP报头长度*/iphdr_hlen *= 4;/* 以字节为单位获取ip长度*/iphdr_len = lwip_ntohs(IPH_LEN(iphdr));/* 修剪pbuf。这对于< 60字节的数据包尤其需要。*/if (iphdr_len < p - > tot_len) {pbuf_realloc(p, iphdr_len);}/* 第二步:标头长度超过第一个pbuf 长度,或者ip 长度超过总pbuf 长度*/if ((iphdr_hlen > p - > len) || (iphdr_len > p - > tot_len) || (iphdr_hlen < IP_HLEN)) {if (iphdr_hlen < IP_HLEN) {}if (iphdr_hlen > p - > len) {}if (iphdr_len > p - > tot_len) {}/* 释放空间*/pbuf_free(p);IP_STATS_INC(ip.lenerr);IP_STATS_INC(ip.drop);MIB2_STATS_INC(mib2.ipindiscards);return ERR_OK;}/* 第三步:验证校验和*/#if CHECKSUM_CHECK_IP/* 省略代码*/# endif/* 将源IP 地址与目标IP 地址复制到对齐的ip_data.current_iphdr_src和ip_data.current_iphdr_dest */ip_addr_copy_from_ip4(ip_data.current_iphdr_dest, iphdr - > dest);ip_addr_copy_from_ip4(ip_data.current_iphdr_src, iphdr - > src);/* 第四步:匹配数据包和接口,即这个数据包是否发给本地*/if (ip4_addr_ismulticast(ip4_current_dest_addr())) {#if LWIP_IGMP/* 省略代码*/#else /* LWIP_IGMP *//* 如果网卡已经挂载了和IP 地址有效*/if ((netif_is_up(inp)) && (!ip4_addr_isany_val( * netif_ip4_addr(inp)))) {netif = inp;} else {netif = NULL;}#endif /* LWIP_IGMP */}/* 如果数据报不是发给本地*/else {int first = 1;netif = inp;do {/* 接口已启动并配置? */if ((netif_is_up(netif)) &&(!ip4_addr_isany_val( * netif_ip4_addr(netif)))) {/* 单播到此接口地址? */if (ip4_addr_cmp(ip4_current_dest_addr(),netif_ip4_addr(netif)) ||/* 或广播在此接口网络地址? */ip4_addr_isbroadcast(ip4_current_dest_addr(), netif)# if LWIP_NETIF_LOOPBACK && !LWIP_HAVE_LOOPIF || (ip4_addr_get_u32(ip4_current_dest_addr()) ==PP_HTONL(IPADDR_LOOPBACK))# endif /* LWIP_NETIF_LOOPBACK && !LWIP_HAVE_LOOPIF */) {break;}#if LWIP_AUTOIPif (autoip_accept_packet(netif, ip4_current_dest_addr())) {/* 跳出if循环*/break;}#endif /* LWIP_AUTOIP */}if (first) {#if !LWIP_NETIF_LOOPBACK || LWIP_HAVE_LOOPIF/* 检查一下目标IP 地址是否是环回地址*/if (ip4_addr_isloopback(ip4_current_dest_addr())) {netif = NULL;break;}#endif /* !LWIP_NETIF_LOOPBACK || LWIP_HAVE_LOOPIF */first = 0;netif = netif_list;} else {netif = netif - > next;}if (netif == inp) {netif = netif - > next;}} while (netif != NULL);}#if IP_ACCEPT_LINK_LAYER_ADDRESSINGif (netif == NULL) {/* 远程端口是DHCP服务器? */if (IPH_PROTO(iphdr) == IP_PROTO_UDP) {struct udp_hdr * udphdr = (struct udp_hdr * )((u8_t * ) iphdr + iphdr_hlen);if (IP_ACCEPT_LINK_LAYER_ADDRESSED_PORT(udphdr - > dest)) {netif = inp;check_ip_src = 0;}}}#endif /* IP_ACCEPT_LINK_LAYER_ADDRESSING */ #if LWIP_IGMP || IP_ACCEPT_LINK_LAYER_ADDRESSINGif (check_ip_src#if IP_ACCEPT_LINK_LAYER_ADDRESSING && !ip4_addr_isany_val( * ip4_current_src_addr())# endif /* IP_ACCEPT_LINK_LAYER_ADDRESSING */)# endif /* LWIP_IGMP || IP_ACCEPT_LINK_LAYER_ADDRESSING */ {/* 第五步:IP 地址,源IP 地址不能是多播或者广播地址*/if ((ip4_addr_isbroadcast(ip4_current_src_addr(), inp)) ||(ip4_addr_ismulticast(ip4_current_src_addr()))) {/* 释放空间*/pbuf_free(p);IP_STATS_INC(ip.drop);MIB2_STATS_INC(mib2.ipinaddrerrors);MIB2_STATS_INC(mib2.ipindiscards);return ERR_OK;}}/* 第六步:如果还没找到对应的网卡,数据包不是给我们的*/if (netif == NULL) {/* 路由转发或者丢弃。如果IP_FORWARD 宏定义被使能,则进行转发*/#if IP_FORWARD/* 非广播包?*/if (!ip4_addr_isbroadcast(ip4_current_dest_addr(), inp)) {/* 尝试在(其他)网卡上转发IP 数据包*/ip4_forward(p, iphdr, inp);} else# endif /* IP_FORWARD */ {IP_STATS_INC(ip.drop);MIB2_STATS_INC(mib2.ipinaddrerrors);MIB2_STATS_INC(mib2.ipindiscards);}/* 释放空间*/pbuf_free(p);return ERR_OK;}/* 第七步:如果数据报由多个片段组成(分片处理)?*/if ((IPH_OFFSET(iphdr) & PP_HTONS(IP_OFFMASK | IP_MF)) != 0) {/* 重装数据报*/p = ip4_reass(p);/* 如果重装没有完成*/if (p == NULL) {return ERR_OK;}/* 分片重装完成,将数据报首部强制转换为ip_hdr 类型*/iphdr = (struct ip_hdr * ) p - > payload;}#if IP_OPTIONS_ALLOWED == 0#if LWIP_IGMPif ((iphdr_hlen > IP_HLEN) && (IPH_PROTO(iphdr) != IP_PROTO_IGMP)) {#else/* 第八步:如果IP 数据报首部长度大于20 字节,就表示错误*/if (iphdr_hlen > IP_HLEN) {#endif /* LWIP_IGMP *//* 释放空间*/pbuf_free(p);IP_STATS_INC(ip.opterr);IP_STATS_INC(ip.drop);/* u不受支持的协议特性*/MIB2_STATS_INC(mib2.ipinunknownprotos);return ERR_OK;}#endif /* IP_OPTIONS_ALLOWED == 0 *//* 第九步:发送到上层协议*/ip4_debug_print(p);ip_data.current_netif = netif;ip_data.current_input_netif = inp;ip_data.current_ip4_header = iphdr;ip_data.current_ip_header_tot_len = IPH_HL(iphdr) * 4;#if LWIP_RAW/* RAW API 输入*/if (raw_input(p, inp) == 0)# endif /* LWIP_RAW */ {/* 转移到有效载荷(数据区域),不需要检查*/pbuf_header(p, -(s16_t) iphdr_hlen);/* 根据IP 数据报首部的协议的类型处理*/switch (IPH_PROTO(iphdr)) {#if LWIP_UDP/* UDP协议*/case IP_PROTO_UDP:#if LWIP_UDPLITEcase IP_PROTO_UDPLITE:#endif /* LWIP_UDPLITE */MIB2_STATS_INC(mib2.ipindelivers);/* IP层递交给网络层的函数*/udp_input(p, inp);break;#endif /* LWIP_UDP */ #if LWIP_TCP/* TCP协议*/case IP_PROTO_TCP:MIB2_STATS_INC(mib2.ipindelivers);/* IP层递交给网络层的函数*/tcp_input(p, inp);break;#endif /* LWIP_TCP */pbuf_free(p); /* 释放空间*/IP_STATS_INC(ip.proterr);IP_STATS_INC(ip.drop);MIB2_STATS_INC(mib2.ipinunknownprotos);}}/* 全局变量清零*/ip_data.current_netif = NULL;ip_data.current_input_netif = NULL;ip_data.current_ip4_header = NULL;ip_data.current_ip_header_tot_len = 0;ip4_addr_set_any(ip4_current_src_addr());ip4_addr_set_any(ip4_current_dest_addr());return ERR_OK;}
上述的源码篇幅很长,也不容易理解,下面笔者把上述的源码分成十步来讲解:
第一步:判断IP 数据报的版本是否是IPv4,如果不是,那么lwIP 会掉弃该数据报。
第二步:判断标头长度超过第一个pbuf 长度,或者ip 长度超过总pbuf 长度,如果是,那
么lwIP 会丢弃该数据报。
第三步:验证校验和,如果不正确,那么lwIP 会掉弃该数据报。
第四步:匹配数据包和接口,这个数据包是否发给本地。
第五步:判断IP 数据报是否是广播或者多播,如果是,那么lwIP 会丢弃该数据报。
第六步:如果到了这一步,没有发现网络接口,那么lwIP 会丢弃该数据报。
第七步:如果如IP 数据报不能分片处理,那么lwIP 会丢弃该数据报。
第八步:如果IP 数据报的IP 首部大于20 字节,那么lwIP 会丢弃该数据报。
第九步:把数据包递交给上层。
第十步:判断该数据报的协议为TCP/UDP/ICMP/IGMP,如果不是这四个协议,则丢弃该
数据报。
ICMP 协议
ICMP(Internet Control Message Protocol)Internet 控制报文协议。它是TCP/IP 协议簇的
一个子协议,用于在IP 主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是
否可达、路由是否可用等网络本身的消息,这些控制消息虽然并不传输到用户数据,但是对于
用户数据的传递起着重要的作用。
ICMP 协议简介
IP 协议虽然是TCP/IP 协议中的核心部分,但是它是一种无连接的不可靠数据报交付,这
个协议本身没有任何错误检验和恢复机制,为了弥补IP 协议中的缺陷,ICMP 协议登场了,
ICMP 协议是一种面向无连接的协议,用于传输出错报告控制信息。它是一个非常重要的协议,
它对于网络安全具有极其重要的意义。它属于网络层协议,主要用于在主机与路由器之间传递
控制信息,包括报告错误、交换受限控制和状态信息等。当遇到IP 数据无法访问目标、IP 路
由器无法按当前的传输速率转发数据包等情况时,会自动发送ICMP 消息。
ICMP 协议用于IP 主机、路由器之间递交控制消息,在网络中,控制消息分为很多种,例
如数据报错信息、网络状况信息和主句状况信息等,虽然这些信息不会递交给用户数据,但对
于用户来说数据报有效性得到提高。
ICMP 应用场景
IP 协议本身不提供差错报告和差错控制机制来保证数据报递交的有效性,如果在路由器
无法递交一个数据报或者数据报生存时间为0 时,那么路由器会直接掉弃这个数据报,虽然
IP 层这样处理是合理的,但是对于源主机来说,比较希望得到数据报递交过程中出现异常相
关信息,以便重新递交数据报或者其他处理。
IP 协议不能进行主机管理与查询机制,简单来说:不知道对方主机或者路由器的活跃,
对于不活跃的主机和路由器就没有必要发送数据报,所以对于主机管理员来说:更希望得到对
方主机和路由器的信息,这样可以根据相关的信息对自身配置、数据报发送控制。
为了解决上述的两个问题,TCP/IP 设计人员在协议上引入了特殊用途报文,这个报文为
网际报文控制协议简称ICMP,从TCP/IP 的协议结构来看,它是和IP’协议一样,都是处于网
络层,但是ICMP 协议有自己一套报文结构,这样数据报就变成了IP 首部+ICMP 首部+数据
区域,ICMP 协议不为任何的应用程序服务,它的目的是目的主机的网络层处理软件。
ICMP 报文类型
在没有引入ICMP 报文之前,IP 数据报一般分为IP 首部+IP 数据区域,现在添加了ICMP
协议,则IP 数据报分为IP 首部+ICMP 首部+数据区域。ICMP 报文分为两类:一类是ICMP 差
错报告报文,另一类是ICMP 查询报文,这两类报文分别解决上小节的两个问题。
①ICMP 差错报告报文主要用来向IP 数据报源主机返回一个差错报告信息,这个信息就
是判断路由器和主机对当前的数据报进行正常处理,例如无法将数据报递交给上层处理,或者
数据报因为生存时间而被删除。
②ICMP 查询报文用于一台主机向另一台主机查询特定的信息,这个类型的报文是成对出
现的,例如源主机发送查询报文,当目标主机收到该报文之后,它会根据查询报文的约定的格式为源主机放回应答报文。
ICMP 差错报告报文和ICMP 查询报文常见类型如下表所示:
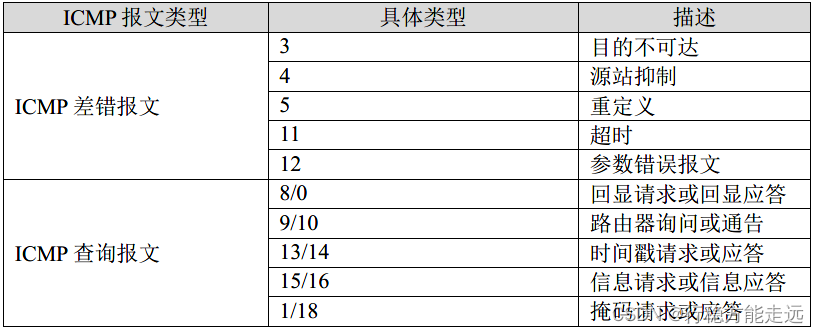
注:lwIP 只实现差错报文的类型3 和11,而查询报文只处理回显请求。
ICMP 报文结构
ICMP 报文有8 字节首部和可变长度的数据部分组成,因为ICMP 有两种类型的报文,其
中不同的报文其首部的格式也会有点差异,当然也有通用的地方,例如首部的前4 个字节是通
用的,ICMP 报文结构如下图所示:
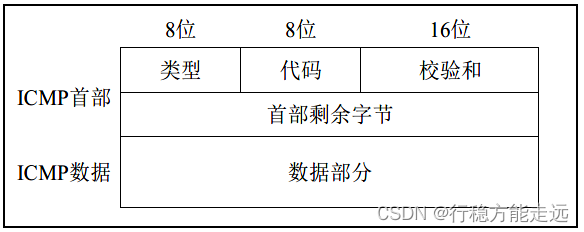
类型字段:表示使用ICMP 的两类类型中的哪一个。
代码字段:产生ICMP 报文的具体原因。
校验和字段:用于记录包括ICMP 报文数据部分在内的整个ICMP 数据报的校验和。
首部剩余的4 字节在每种类型的报文有特殊的定义,总的看来说:不同类型的报文,数据
部分长度和含义存在差异,例如差错报文会引起差错的据报的信息,而查询报文携带查询请求
和查询结果数据。
- ICMP 差错报文
(1) 目的站不可到达
当路由器发送的数据报不能发送到指定目的地时,或者说当路由器不能够给数据报找到路
由或主机不能够交付数据报时,就丢弃这个数据报,然后向发送数据报的源主机设备发回一个
终点不可达数据报文。如下图所示:
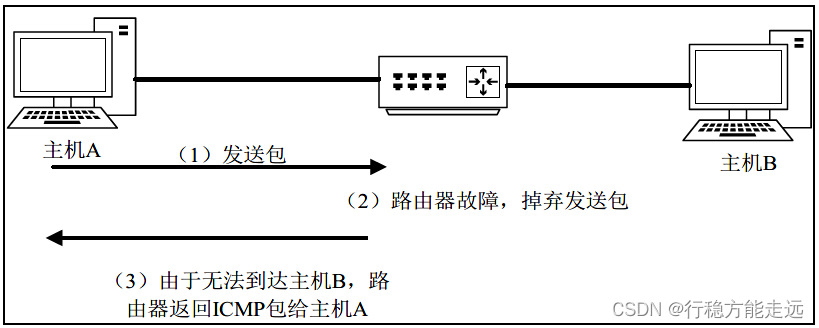
举个例子:主机A 给主机B 发送一个数据报,在网络中传输时中间可能要经过很多台路
由器,主机A 先把这个数据报发送给路由器,路由器收到这个数据报后,此时路由R1 发生了
故障,它不知道这个数据报下一步该发给哪个路由设备或者那台主机设备,也就是说这个数据
报不能发送到目的地主机B,这时路由器会把这个数据报丢弃并向主机A 发回一个终点不可
达的数据报文。
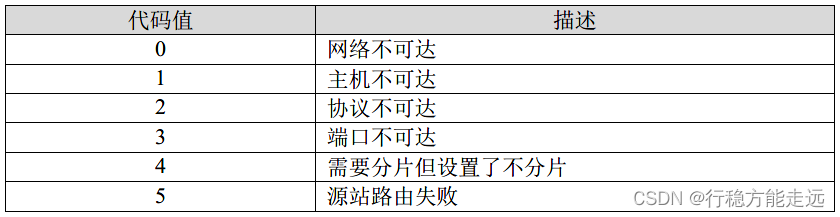
ICMP 目的不可达差错报告报文产生差错的原因有很多,如网络不可达、主机不可达、协
议不可达、端口不可达等,引起差错的原因会在ICMP 报文中的代码字段(Code)记录。对
于不同的差错代码字段的值是不一样的,但是lwIP 实现的只有前6 种,如下图所示:
当然ICMP 目的不可达报文首部剩下的4 字节是未使用,而ICMP 报文数据区装载了IP
数据报首部及IP 数据报的数据区域前8 字节,为什么需要装载IP 数据报的数据区域中前8 个
字节的数据呢?因为IP 数据报的数据区域前8 个字节刚好覆盖了传输层协议中的端口号字段,
而IP 数据报首部就拥有目标IP 地址与源IP 地址,当源主机收到这样子的ICMP 报文后,它能
根据ICMP 报文的数据区域判断出是哪个数据包出现问题,并且IP 层能够根据端口号将报文
传递给对应的上层协议处理,差错报文结构如下图所示:

可以看出:首部剩下的4 个字节是未使用的,而数据区域保存的是引起差错IP 首部和引
起差错数据包的数据区域前8 字节数据。准确来说,就是把引起差错IP 数据包的IP 部和数据
区域的前8 字节数据拷贝到差错报文的数据区域。
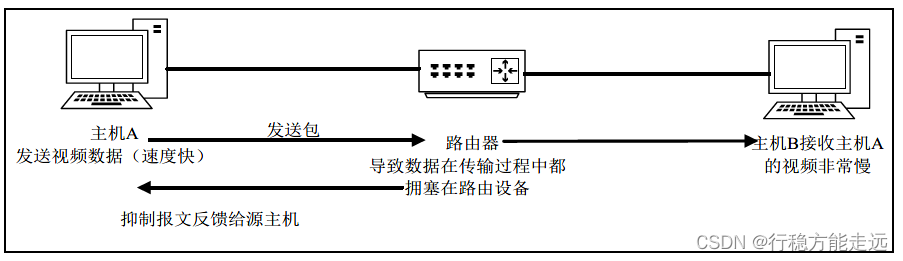
(2) 源站抑制
由于IP 协议是面向无连接的,没有流量控制机制,数据在传输过程中是非常容易造成拥
塞的现象。而ICMP 源点抑制报文就是给IP 协议提供一种流量监控的机制,因为ICMP 源点
抑制机制并不能控制流量的大小,但是能根据流量的使用情况,给源主机提供一些建议。这个
报文的作用就是通知数据报在拥塞时被丢弃了,另外还会警告源主机流量出现了拥塞的情况,
然后源主机根据反馈的ICMP 源点抑制报文信息作出处理,至于源主机怎么就不关它的事了。
如下图所示:
(3) 端口不可达
当目标系统收到一个IP 数据报的某个服务请求时,如果本地没有此服务,则本地会向源
头返回ICMP 端口不可达信息。常见的端口不可达有:主机A 向主机B 发起一个ftp 的传输请
求,从主机B 传输一个文件到主机A,由于主机B 设备没有开启ftp 服务的69 端口,因此主
机A 在请求主机B 时,会收到主机B 回复的一个ICMP 端口不可达的差错报文。
(4) 超时
ICMP 差错报告报文主要在以下几种情况中,会发送ICMP 超时报文: - 当路由器接收到的数据报的TTL 生命周期字段值为0 时,路由器会把该数据报丢弃掉,
并向源主机发回一个ICMP 超时报文。 - 另外,当目标主机在规定时间内没有收到所有的数据分片时,会把已经收到的所有数据
分片丢弃,并向源主机发回一个ICMP 超时报文。在超时报文中,代码0 只能给路由器使用,
表示生存周期字段值为0,代码1 只能给目的主机使用,它表示在规定的时间内,目的主机没
有收到所有的数据分片。
(5) 参数错误
当数据报在因特网上传送时,在其首部中出现的任何二义性或者首部字段值被修改都可能
会产生非常严重的问题。如果路由器或目的主机发现了这种二义性,或在数据报的某个字段中
缺少某个值,就丢弃这个数据报,并回送参数问题报文。 - ICMP 查询报文
ping 程序利用ICMP 回显请求报文和回显应答报文(而不用经过传输层)来测试目标主机
是否可达。它是一个检查系统连接性的基本诊断工具。
ICMP 回显请求和ICMP 回显应答报文是配合工作的。当源主机向目标主机发送了ICMP
回显请求数据包后,它期待着目标主机的回答。目标主机在收到一个ICMP 回显请求数据包后,
它会交换源、目的主机的地址,然后将收到的ICMP 回显请求数据包中的数据部分原封不动地
封装在自己的ICMP 回显应答数据包中,然后发回给发送ICMP 回显请求的一方。如果校验正
确,发送者便认为目标主机的回显服务正常,也即物理连接畅通。查询报文结构如下图所示:
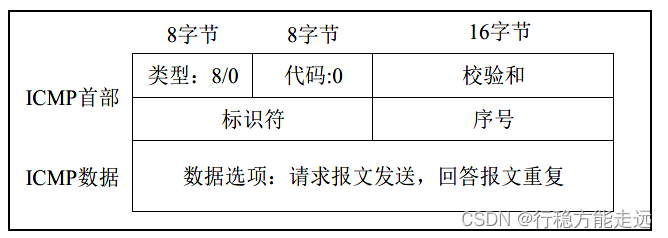
类型字段是指请求报文(8)和回答报文(0),代码段在ICMP 查询报文没有特殊取值,
其值为0,首部中的标识符和序号在ICMP 中没有正式定义该值的范围,所以发送方可以自由
定义这两个字段,可以用来记录源主机发送出去的请求报文编号。数据可选区域标识回送请求
报文包含数据和长度是可选的,发送放应该选择适合的长度和填充数据。在接收方它可以根据
这个回送请求产生一个回送回答报文,回送报文的数据与回送请求报文的数据是相同的。
ICMP 的实现
我们可以总结一下ICMP 协议的作用,ICMP 协议是IP 协议的辅助协议,为什么ICMP 协
议是IP 协议的辅助协议呢?由于IP 协议本身不提供差错报告和差错控制机制来保证数据报递
交的有效性和进行主机管理与查询机制,简单来说:ICMP 协议为了解决IP 协议的缺陷而诞生
的,ICMP 报文分为差错报文和查询报文,这两个报文分别解决IP 协议的两大缺陷,本小节主
要讲解lwIP 是怎么样实现ICMP 协议发送及处理的。
ICMP 数据结构体
在讲述IP 协议时,它是有自己的数据结构,同样ICMP 也有它自己的数据结构icmp_echo
_hdr,该数据结构在lwIP 的icmp.h 文件中定义,该结构体如下源码所示:
PACK_STRUCT_BEGIN
struct icmp_echo_hdr {PACK_STRUCT_FLD_8(u8_t type); /* ICMP类型*/PACK_STRUCT_FLD_8(u8_t code); /* ICMP代码号*/PACK_STRUCT_FIELD(u16_t chksum); /* ICMP校验和*/PACK_STRUCT_FIELD(u16_t id); /* ICMP的标识符*/PACK_STRUCT_FIELD(u16_t seqno); /* 序号*/
} PACK_STRUCT_STRUCT;
PACK_STRUCT_END
此外lwIP 还定义了很多宏与枚举类型的变量对ICMP 的类型及代码字段进行描述,如下
源码所示:
#
define ICMP_ER 0 /* 回送应答*/ # define ICMP_DUR 3 /* 目标不可达*/ # define ICMP_SQ 4 /* 源站抑制*/ # define ICMP_RD 5 /* 重定向*/ # define ICMP_ECHO 8 /* 回送*/ # define ICMP_TE 11 /* 超时*/ # define ICMP_PP 12 /* 参数问题*/ # define ICMP_TS 13 /* 时间戳*/ # define ICMP_TSR 14 /* 时间戳应答*/ # define ICMP_IRQ 15 /* 信息请求*/ # define ICMP_IR 16 /* 信息应答*/ # define ICMP_AM 17 /* 地址掩码请求*/ # define ICMP_AMR 18 /* 地址掩码应答*/
/* ICMP目标不可到达的代码*/
enum icmp_dur_type {/* 网络不可到达*/ICMP_DUR_NET = 0,/* 主机不可达*/ICMP_DUR_HOST = 1,/* 协议不可到达*/ICMP_DUR_PROTO = 2,/* 端口不可达*/ICMP_DUR_PORT = 3,/* 需要进行分片但设置不分片比特*/ICMP_DUR_FRAG = 4,/* 源路由失败*/ICMP_DUR_SR = 5
};
/* ICMP时间超时代码*/
enum icmp_te_type {/* 在运输过程中超出了生存时间*/ICMP_TE_TTL = 0,/* 分片重组时间超时*/ICMP_TE_FRAG = 1
};
可以看出,这些宏定义描述了ICMP 数据报文的类型字段,下面的icmp_dur_type 和
icmp_te_type 枚举用来描述ICMP 数据报文的代码字段,它们分别为目的不可到达和超时差错
报文。
lwIP 的作者为了快速读取和填写ICMP 报文首部,在icmp.h 文件还定义了ICMP 报文首
部的宏定义,如下源码所示:
#define ICMPH_TYPE(hdr) ((hdr)->type) /* 读取类型字段*/
#define ICMPH_CODE(hdr) ((hdr)->code) /* 读取代码字段*/
#define ICMPH_TYPE_SET(hdr, t) ((hdr)->type = (t)) /* 填写类型字段*/
#define ICMPH_CODE_SET(hdr, c) ((hdr)->code = (c)) /* 填写代码字段*/
使用这些宏定义能快速设置ICMP 各个字段的数值。
发送ICMP 差错报文
lwIP 只实现目的不可到达和超时差错报文,它们的实现函数分别为icmp_dest_unreach 和i
cmp_time_exceeded,这两个函数转入的参数与icmp_dur_type 和icmp_te_type 枚举相关。如目的不可到达报文的代码字段由icmp_dur_type 枚举描述,而超时报文的代码字段由icmp_te_typ
e 枚举描述。
好了,废话不多说,打开icmp.c 文件查看icmp_dest_unreach 和icmp_time_exceeded 这两
个函数,如下所示:
/* 发送目标不可达报文,该函数实际调用函数
icmp_send_response来发送ICMP差错报文
ICMP_DUR 为目的不可到达*/
void
icmp_dest_unreach(struct pbuf * p, enum icmp_dur_type t) {MIB2_STATS_INC(mib2.icmpoutdestunreachs);icmp_send_response(p, ICMP_DUR, t);}/* 发送超时报文,该函数实际调用函数icmp_send_response来发送ICMP差错报文ICMP_TE 为超时*/
void
icmp_time_exceeded(struct p buf * p, enum icmp_te_type t) {MIB2_STATS_INC(mib2.icmpouttimeexcds);icmp_send_response(p, ICMP_TE, t);
}
从上述源码可以看出,差错报文的类型已经固定为目的不可到达或者超时,它们唯一不同
的是差错报文的代码值,这个代码值就是由icmp_dur_type 和icmp_te_type 枚举定义的,最后
调用相同的icmp_send_response 函数发送差错报文,这个发送函数如下所示:
static void
icmp_send_response(struct pbuf * p, u8_t type, u8_t code) {struct pbuf * q;struct ip_hdr * iphdr;struct icmp_echo_hdr * icmphdr;ip4_addr_t iphdr_src;struct netif * netif;MIB2_STATS_INC(mib2.icmpoutmsgs);/* 为差错报文申请pbuf,pbuf预留以太网首部和ip首部,申请数据长度为icmp首部长度+icmp数据长度(ip首部长度+8) */q = pbuf_alloc(PBUF_IP, sizeof(struct icmp_echo_hdr) + IP_HLEN +ICMP_DEST_UNREACH_DATASIZE, PBUF_RAM);if (q == NULL) {MIB2_STATS_INC(mib2.icmpouterrors);return;}/* 指向IP 数据报首部*/iphdr = (struct ip_hdr * ) p - > payload;/* 指向带填写的icmp首部*/icmphdr = (struct icmp_echo_hdr * ) q - > payload;/* 填写类型字段*/icmphdr - > type = type;/* 填写代码字段*/icmphdr - > code = code;icmphdr - > id = 0;icmphdr - > seqno = 0;/* 从原始数据包中复制字段,IP 数据报首部+8 字节的数据区域*/SMEMCPY((u8_t * ) q - > payload + sizeof(struct icmp_echo_hdr), (u8_t * ) p - > payload,IP_HLEN + ICMP_DEST_UNREACH_DATASIZE);/* 得到源IP 地址*/ip4_addr_copy(iphdr_src, iphdr - > src);/* 判断是否同一网段*/netif = ip4_route( & iphdr_src);if (netif != NULL) {/* 计算校验和*/icmphdr - > chksum = 0;ICMP_STATS_INC(icmp.xmit);/* 发送ICMP差错报文*/ip4_output_if(q, NULL, & iphdr_src, ICMP_TTL, 0, IP_PROTO_ICMP, netif);}/* 释放icmp pbuf */pbuf_free(q);
}
可以看到,此函数申请了一个pbuf 内存,它的数据区域存储了ICMP 首部,接着对这个
首部各个字段设置数值,然后在ICMP 首部后面添加引起差错数据包的IP 首部和引起差错的
前8 字节数据区域,这样lwIP 内核构建差错报文完成,最后调用ip4_output_if 函数发送该差
错报文。
ICMP 报文处理
IP 层把数据报递交至传输层之前,lwIP 内核会判断IP 首部的上层协议字段,若这个上层
协议字段不为TCP 和UDP,则该数据报不会递交给传输层处理;若上层协议字段为ICMP,
则该数据报递交给icmp_input 函数处理,该函数如下所示:
void
icmp_input(struct pbuf * p, struct netif * inp) {u8_t type;struct icmp_echo_hdr * iecho;const struct ip_hdr * iphdr_in;u16_t hlen;const ip4_addr_t * src;ICMP_STATS_INC(icmp.recv);MIB2_STATS_INC(mib2.icmpinmsgs);iphdr_in = ip4_current_header();hlen = IPH_HL_BYTES(iphdr_in);/* 判断IP首部的大小*/if (hlen < IP_HLEN) {goto lenerr;}/* 判断pbud的大小*/if (p - > len < sizeof(u16_t) * 2) {goto lenerr;}/* 获取ICMP的类型字段*/type = * ((u8_t * ) p - > payload);switch (type) {case ICMP_ER:/* 回送应答*/MIB2_STATS_INC(mib2.icmpinechoreps);break;case ICMP_ECHO:/* 回送*/MIB2_STATS_INC(mib2.icmpinechos);src = ip4_current_dest_addr();/* 判断是否为多播*/if (ip4_addr_ismulticast(ip4_current_dest_addr())) {goto icmperr;}/* 判断是否为广播*/if (ip4_addr_isbroadcast(ip4_current_dest_addr(),ip_current_netif())) {goto icmperr;}if (p - > tot_len < sizeof(struct icmp_echo_hdr)) {goto lenerr;}if (pbuf_header(p, (s16_t)(hlen + PBUF_LINK_HLEN +PBUF_LINK_ENCAPSULATION_HLEN))) {struct pbuf * r;r = pbuf_alloc(PBUF_LINK, p - > tot_len + hlen, PBUF_RAM);if (r == NULL) {goto icmperr;}if (r - > len < hlen + sizeof(struct icmp_echo_hdr)) {pbuf_free(r);goto icmperr;}MEMCPY(r - > payload, iphdr_in, hlen);if (pbuf_header(r, (s16_t) - hlen)) {pbuf_free(r);goto icmperr;}if (pbuf_copy(r, p) != ERR_OK) {pbuf_free(r);goto icmperr;}pbuf_free(p);p = r;} else {if (pbuf_header(p, -(s16_t)(hlen + PBUF_LINK_HLEN +PBUF_LINK_ENCAPSULATION_HLEN))) {goto icmperr;}}/* 强制将数据区域转换为ICMP 报文首部*/iecho = (struct icmp_echo_hdr * ) p - > payload;if (pbuf_header(p, (s16_t) hlen)) {} else {err_t ret;struct ip_hdr * iphdr = (struct ip_hdr * ) p - > payload;/* 拷贝源IP 地址*/ip4_addr_copy(iphdr - > src, * src);/* 拷贝目标IP 地址*/ip4_addr_copy(iphdr - > dest, * ip4_current_src_addr());/* 填写报文类型*/ICMPH_TYPE_SET(iecho, ICMP_ER);iecho - > chksum = 0;/* 设置正确的TTL并重新计算头校验和。*/IPH_TTL_SET(iphdr, ICMP_TTL);IPH_CHKSUM_SET(iphdr, 0);ICMP_STATS_INC(icmp.xmit);MIB2_STATS_INC(mib2.icmpoutmsgs);MIB2_STATS_INC(mib2.icmpoutechoreps);/* 发送一个应答ICMP数据包*/ret = ip4_output_if(p, src, LWIP_IP_HDRINCL,ICMP_TTL, 0, IP_PROTO_ICMP, inp);if (ret != ERR_OK) {}}break;default:/* 对于其他类型的报文,直接丢掉*/if (type == ICMP_DUR) {MIB2_STATS_INC(mib2.icmpindestunreachs);} else if (type == ICMP_TE) {MIB2_STATS_INC(mib2.icmpintimeexcds);} else if (type == ICMP_PP) {MIB2_STATS_INC(mib2.icmpinparmprobs);} else if (type == ICMP_SQ) {MIB2_STATS_INC(mib2.icmpinsrcquenchs);} else if (type == ICMP_RD) {MIB2_STATS_INC(mib2.icmpinredirects);} else if (type == ICMP_TS) {MIB2_STATS_INC(mib2.icmpintimestamps);} else if (type == ICMP_TSR) {MIB2_STATS_INC(mib2.icmpintimestampreps);} else if (type == ICMP_AM) {MIB2_STATS_INC(mib2.icmpinaddrmasks);} else if (type == ICMP_AMR) {MIB2_STATS_INC(mib2.icmpinaddrmaskreps);}ICMP_STATS_INC(icmp.proterr);ICMP_STATS_INC(icmp.drop);}pbuf_free(p);return;lenerr:pbuf_free(p);ICMP_STATS_INC(icmp.lenerr);MIB2_STATS_INC(mib2.icmpinerrors);return;icmperr:pbuf_free(p);ICMP_STATS_INC(icmp.err);MIB2_STATS_INC(mib2.icmpinerrors);return;
}
可以看出,lwIP 接收到回显请求报文时,系统会把这个回显请求报文的ICMP 类型字段修
改为0(回显应答类型),接着偏移payload 指针添加IP 首部并设置IP 首部的各个字段,最后
调用ip4_output_if 函数发送这个回显应答报文。注:lwIP 只处理回显请求报文,而其他类型的
请求报文一律不处理。