文章目录
- 底层索引为什么使用B+树,而不用B树?
- 为什么Innodb索引建议必须建主键?
- 为什么主键推荐使用整形自增?
- Mysql底层索引只有B+树吗?
- 联合索引底层长什么样子?
- 数据库隔离级别中串行化是怎么实现的?
- 查询方法需要加事务吗?
- 大事务有什么影响?
底层索引为什么使用B+树,而不用B树?
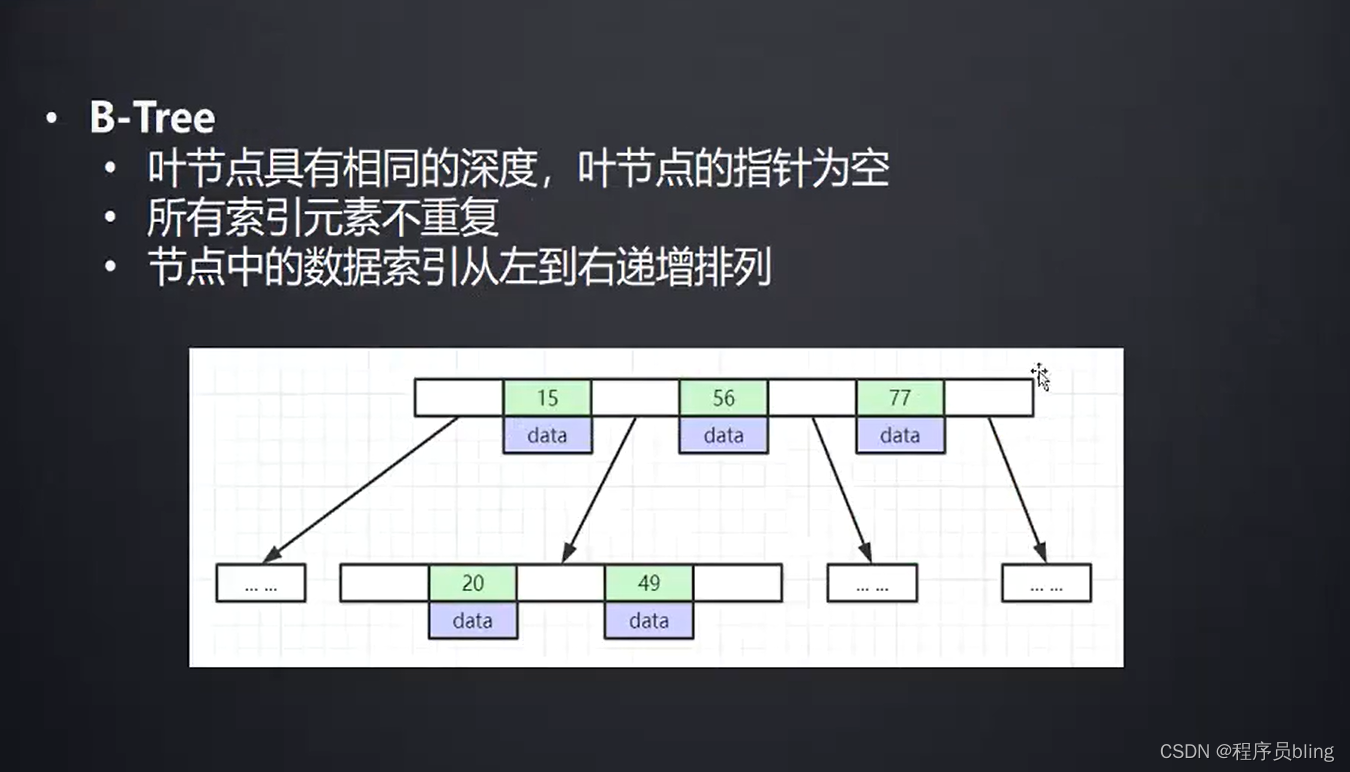
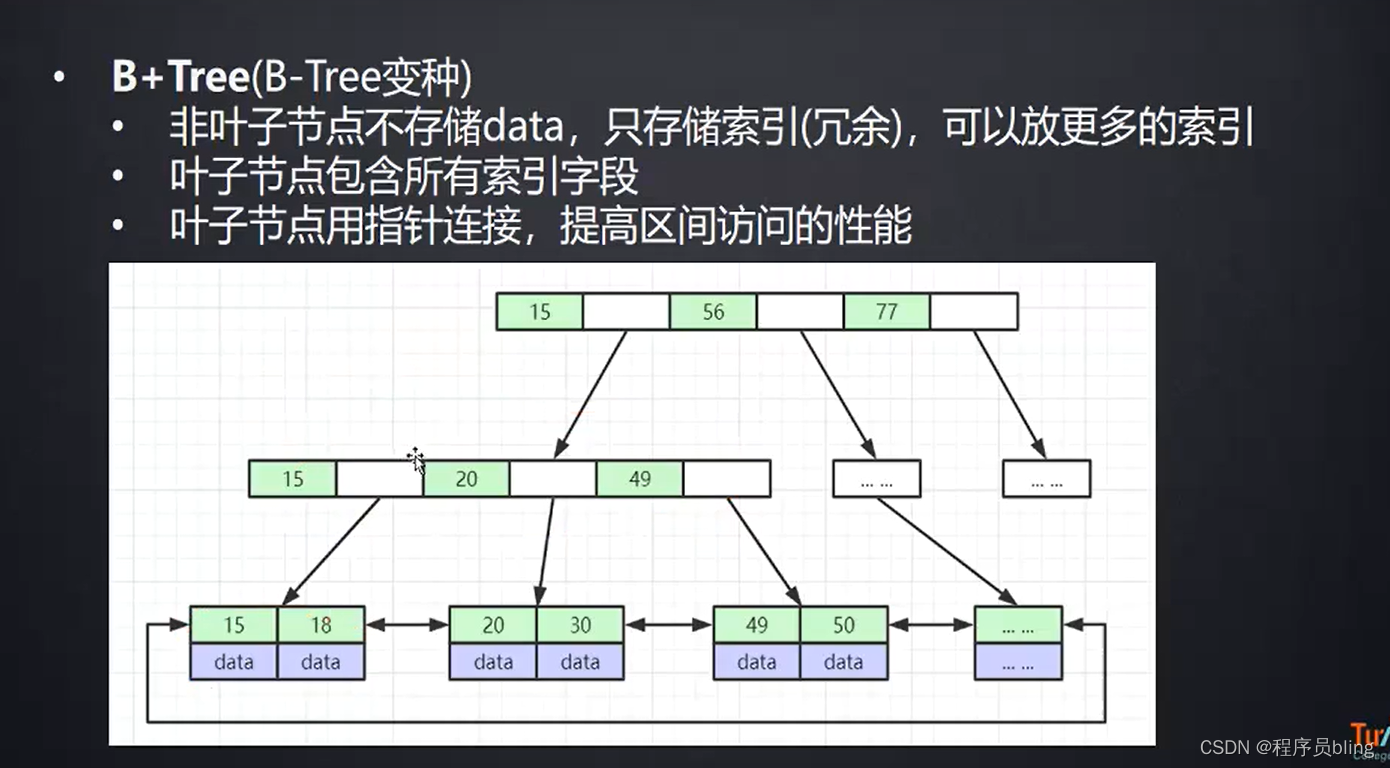
在Mysql内部,对于Innodb存储引擎, 每一个节点都会占一个磁盘页,一个磁盘页的大小默认是16kb.
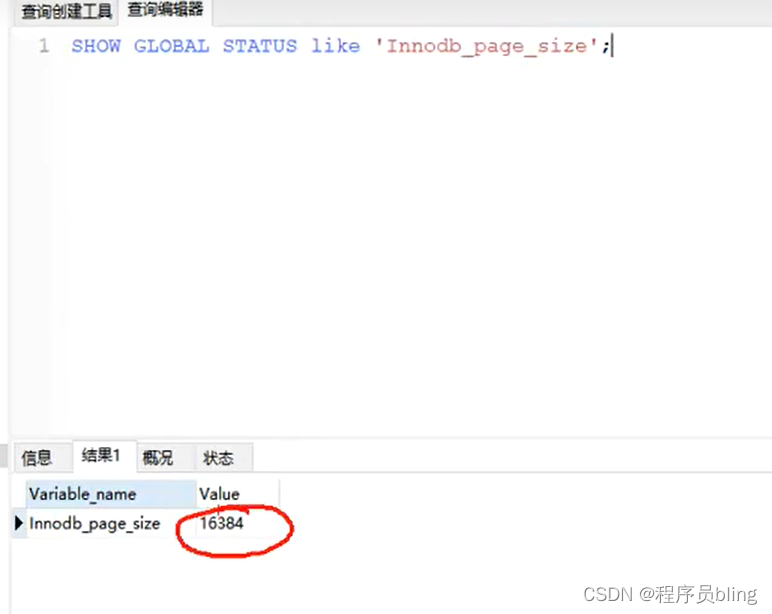
也就是说每一个节点存储的东西最多只能有16kb
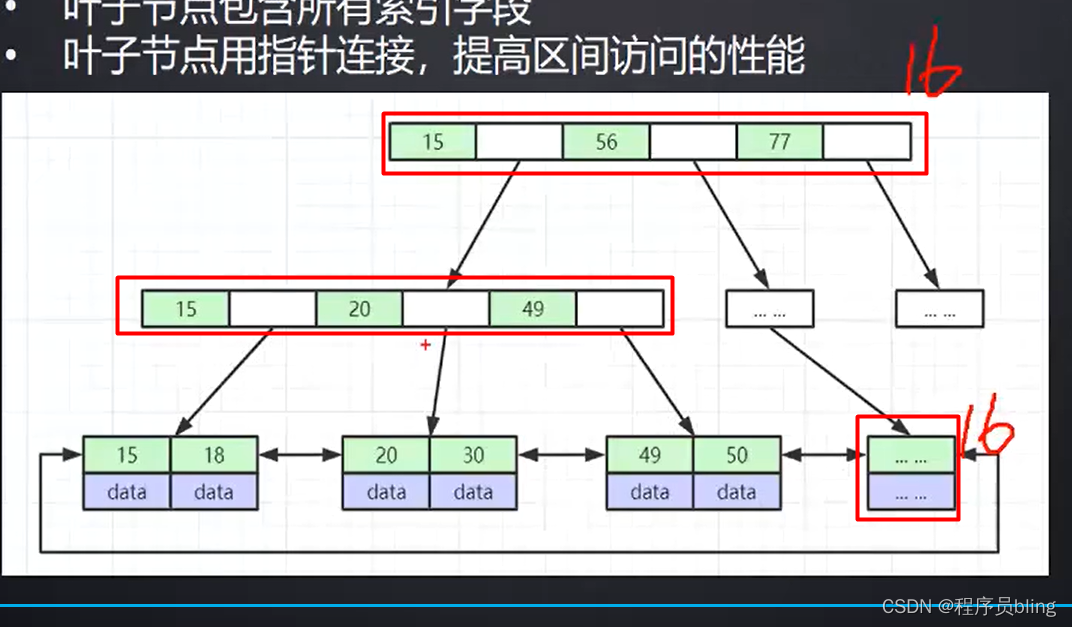
那么在b树中,这16kb及需要存储索引,又需要存储真实数据. 而在b+树中,这16kb只需要存储索引, 所以在b+树中一个节点可以存储更多的索引,从整体看, 就会比b树更加的矮胖, 从而可以减少树的深度,减少I/O次数.
为什么Innodb索引建议必须建主键?
首先明确在Innodb索引中, 是依靠B+树来组织整张表数据的, 而默认的话会用主键索引来组织.
那你现在没有主键怎么办?没有索引来组织这个B+树,怎么办呢?
其实Mysql首先会在你的数据表中找,从左往右找,找到一列可以做唯一性索引的, 把该列作为主键,用来维护整张表的数据.建一个B+树.
那如果找不到这列数据呢?Mysql其实还有一个隐藏列->rowid, 这一列对默认递增, 以此作为主键, 用来维护B+树.但其实这种方式并不好,因为我们并看不到这列, 在查询的时候也不能用该列去查询数据.
为什么主键推荐使用整形自增?
这个是两个问题.
1.为什么使用整形?
因为在使用索引查找元素的时候,会进行大量的比较,来确定位置,那如果是整形的话,会效率更高.
2.为什么要自增?
在B+树中,叶子节点是从左到右依次递增的
如果是自增,就只会在叶子节点的最右边新加一个节点即可, 而如果不是自增,就需要根据主键的索引值进行随机插入,那可能就会插入到某个叶子节点的中间位置,此时就需要移动其他数据,甚至需要从一个页面复制到另一个页面,我们将这种情况称为页分裂.页分裂会造成大量的内存碎片,导致结构不紧凑,从而影响查询效率
所以用自增的话,相比来说,效率会更高.
Mysql底层索引只有B+树吗?
其实不是,在Mysql底层,默认是B+树这种索引结构,但其实还有 Hash表,我们也可以选择这种数据结构,但大多数情况下不会使用,为什么?
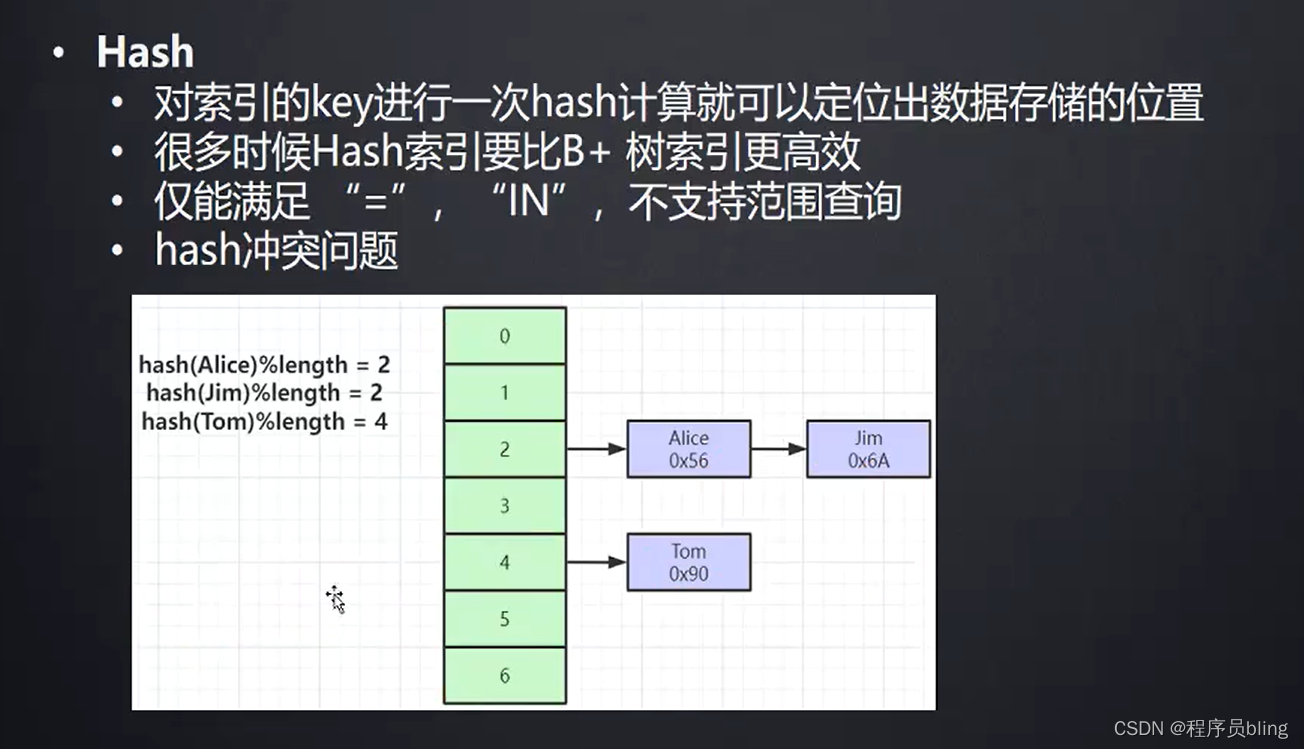
Hash结构有它的优点:
- 很多时候是比B+索引要快的,更加高效
- 只需要一次Hash计算就能定位出数据存储的位置
但是为什么不用呢?
最主要的点就是不支持范围查询, 而在我们业务中,范围查询是一个非常常见的需要, 而B+树就可以很好的范围查询.
联合索引底层长什么样子?
联合索引是一个非聚集索引.如下:
使用name、age、position三个字段建立联合索引
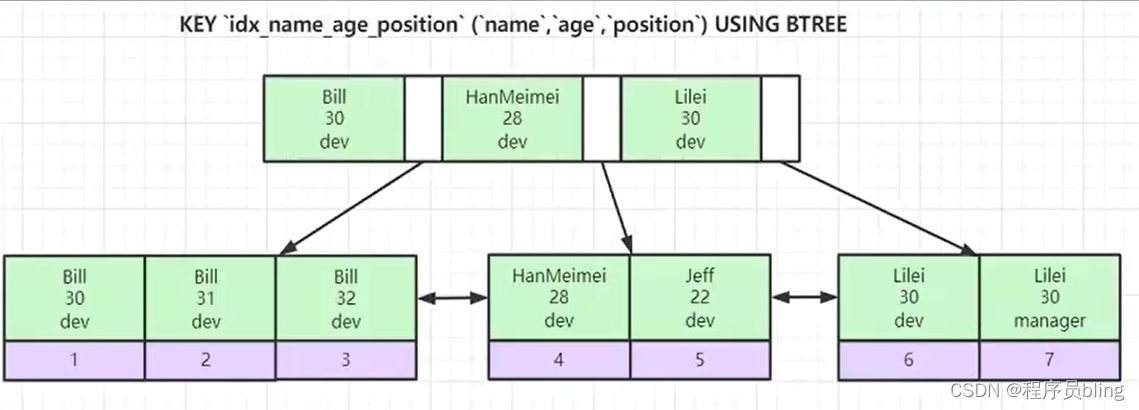
在排序的时候,先按第一个字段name排,第一个字段相同的时候才按第二个字段age排序,第二个字段相同的时候按照第三个字段position排序. 这也是为什么会有最左前缀匹配原则
数据库隔离级别中串行化是怎么实现的?
这个其实很简单,所谓串行化, 就是把所有的涉及到相同数据的读写, 写写的这些操作全部串行.读读是不影响的.
比如说A事务先读取一条数据, select * from user where id=1;但是A事务还没有提交
此时B事务去更新update user set name=‘a’ where id=1;会是什么效果?
此时B事务就会被阻塞住,直到A事务提交之后.
要实现这种效果其实非常简单,就是对所有的读操作都加上读锁, 也就是都变成当前读, select … lock in share mode;
查询方法需要加事务吗?
在我们的Java项目某个方法中,只有查询操作,这个查询可能有多个, 这个方法需要加事务吗?
要理清楚这个问题,首先要明白 加事务查询和不加事务查询的区别:
快照读:
- 不加事务: 读取的都是所有事务已经提交的数据.
- 加事务: 和事务对应的隔离级别有关系,
- 读未提交: 可能读到其他事务未提交的数据
- 读已提交: 读取到的是所有事务已经提交的数据.
- 可重复读: 可能读取到的可能是历史数据,因为在当前隔离级别中, 所有读取的数据都来自开启事务后第一次读取的快照数据.
- 串行化: 读写操作,写写操作会被阻塞.
当前读:
- 因为当前读是相当于加读锁的,所以对于当前读, 不加事务和加事务在所有情况下效果都是一样的.
我们平常大部分查询都是快照读, 事务的隔离级别大部分都是读已提交或者可重复读.接下来我们再重点说下这两种情况:
快照读-读已提交:
这种情况下其实不需要加事务读了,因为加事务读和不加事务读取到的结果都是一样的, 都会读取到其他事务已经提交的最新数据.
快照读-可重复读:
这种情况下就有区别了, 具体需要根据业务场景判断加不加,举个例子:
- 比如说需要生成报表, 那报表其实就需要的是某个时间点的数据, 也就是某个版本的快照数据, 因为要保证数据整体上的一致性.所以就需要加事务去读.
- 比如说某个场景就需要最新的数据, 那就最好不加事务,这样读取的就是所有事务已经提交的最新数据.
大事务有什么影响?
- 并发情况下, 数据库连接池容易被撑爆
- 大事务一般当前读会比较多, 容易造成大量阻塞和锁超时
- 执行时间长, 容易造成主从延迟
- 回滚需要的时间比较长
- undo log日志膨胀
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.